


提出了一种基于词向量的两层词性标注方法,使用少量人工提取的特征,大部分特征可使用词向量和第1层标注向量自动训练得到.该方法将标注集分成两类,分别作为不同层的标注集.首先,对容易标注的类别进行标注;然后,对难以标注的动词或者名词进行第2层标注,将其标注为具体的某类动词或名词.利用该方法对中国学生写的英语文章进行词性标注的准确率可从95.23%提高到95.63%,超过了现有基于词向量词性标注器对相同语料词性标注的准确率.
A tagging algorithm about two layers part-of-speech base on word embedding was proposed. Only a few artificial features are needed in this algorithm, most features are replaced by word embedding and tagging vector that is got in the first layer. In addition, the tag set is divided into two categories, which are the tag sets of different layers. The ones which are easily to be tagged are tagged firstly in the first layer.Those tags which are hardly to be tagged as noun and verb are tagged in the second layer. Using this algorithm, the accuracy of part-of-speech tagging of essays written by Chinese English learner is improved from 95.23% to 95.63%, which outperforms the state-of-art word results of part-of-speech tagging of essays written by Chinese English learner based on vector based on word embedding.
词性标注是自然语言处理的一个基本任务,研究者对其做了许多有益的工作.传统词性标注方法使用最大熵[1]、支持向量机[2]、guided learning[3]、隐马[4]等模型进行标注,这些模型大多需要进行人工特征提取.
中国学生写的英语文章常出现泊来词、专有名词、臆造词,常伴随着各种错误[5].由于上述问题的存在,对中国学生写的英语文章进行词性标注时,特征提取变得十分困难.笔者提出了两层标注的词性标注方法.
笔者将penn TreeBank词性标注集中的NN、NNS、NNP、NNPS全部用N代替,VB、VBD、VBG、VBN、VBP、VBZ全部用V代替.将替代后的词性标注集称为标注集T1,将NN和VB等分别称为标注集T2(1) 和标注集T2(2).首先使用标注集T1对英文句子进行词性标注,完成标注后,利用标注结果对标注为N或者V的单词进行第2层标注.
1 相关工作2003年,Bengio等[6]提出了一种基于词向量的语言模型,该语言模型使用的词向量和网络参数是在无监督训练过程中得到的.考虑单词的结构,Alexandrescu等[7]提出了一种使用单词各种自身属性的方式来表示单词的方法. 2011年,Collobert[8]提出了一种基于词向量的分类方法,为了避免大量的特征提取工作,使用一组词向量代替人工提取的特征. 2013年,Mikolov等[9]提出了大型数据集中训练词向量的两种常用结构,即continuous bag-of-words和skip-gram.基于Collobert提出的方法, Santos等[10]在2014年提出了基于字母向量表示的词性标注结构模型.该方法对英文词性标注结果的准确率为97.32%.
2 两层词性标注方法基于词向量的两层词性标注过程如图 1所示,在T1上对待标句子进行词性标注,得到第1层结果后,利用该结果得到每个单词邻近词标注信息,对标注为“N”和“V”的词进行第2层标注,得到最终标注结果.

|
图 1 基于词向量的两层词性标注方法框架 |
在图 1中,对句子进行第1层标注和第2层标注过程是基于Collobert提出的网络结构而改进的.其结构如图 2所示,在句子第1层标注阶段,输入一个英文句子,结合词向量映射表,对句子中的每个单词输出一个概率向量,该向量表示目标单词标注为不同词性标注t∈T1的概率.在本结构中,以目标单词为中心,固定窗口大小的词向量串联作为神经网络的输入,经过一个3层神经网络得到目标单词的词性概率向量.通过该结构得到每个单词在T1标注集的标注概率,并结合一个标注转移概率,使用维特比算法,对整个句子进行词性标注.在得到第1层标注结果后,结合标注信息,对标注为“N”和“V”的词进行第2层标注,从而得到最终标注结果.

|
图 2 词性标注网络结构 |
在第1层标注阶段,本结构和Collobert提出的网络结构一样,将英文句子中的每个单词转换为一个含有特征信息的词向量.例如,词向量映射表为W,输入一个含有N个单词的英文句子{s1, ss, …, sN},每个单词sn可以在该表中找到一个对应的词向量un=(a1, a2, …, am),其中m为词向量维度.词到词向量的转换公式为

|
(1) |
其中:w为词向量映射表W的大小;umN由N个m维的词向量组成;VwN为N个单词在词向量映射表W中对应的位置信息矩阵,在该矩阵中,第i列向量vi表示umN中和第i个单词位置相关的向量;W∈Rw×m为词向量映射表,m为词向量维度.
本结构增加3个特征表示单词的首字母大小写情况、单词的倒数第1和第2个字母.
2.2 标注转换标注向量在第2层标注阶段,词性标注网络在Collobert提出的网络结构基础上加入了一个标注向量表.神经网络的输入层不只是词向量以及字母特征向量串联,还包括标注向量.在此阶段,本结构将目标词及其邻近词的标注转换为相应的标注向量.标注转换为标注向量过程和词转换为词向量类似,其过程如式(2) 所示.

|
(2) |
其中:r为标注向量表的大小,vrN为位置向量组成的矩阵,Wr∈RWr为不同标注对应标注向量组成的向量表.
2.3 神经网络结构及输入在第1层标注阶段,输入一个英文句子,输出英文句子的标注串.在选择合适标注串前,需求得句子中每个单词对T1中各个标注的概率向量.这个标注概率向量的求得是基于一个自然语言处理常见假设,一个单词的词性标注依赖于该单词以及其周边单词.对于第t个单词,输入层为
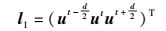
|
(3) |
其中:l1为输入层,d为窗口大小.另外,本结构使用“111”作为第1个单词前左邻近词和最后一个单词的右邻近词.接着将输入层l1输入到一个BP神经网络中.输出层计算如下:
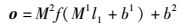
|
(4) |
其中:M1∈Rh×d×(m+3),M2∈Rh×|T1|,b1∈Rh,b2∈R|T1|,h为隐藏层数目,|T1|为标注集大小.
本结构最后判定句子词性标注串时,借助一个转移矩阵A∈R|T1|×|T1|,其中Aij表示从词性i∈T1到j∈T1的转移概率.假设输入一个英文句子[s]1N={s1, s2, …, sN},利用
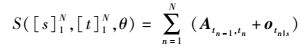
|
(5) |
其中θ为该结构中所有的训练参数.求得该输入句子标注结果为[t]1N={t1, t2, …, tN}的概率值.通过比较输入句子对应不同标注串的概率值,选择最大概率值对应的标注串作为该句子的词性标注结果.在第2层标注阶段中,将第1层标注阶段得到的目标词和它邻近词的标注,根据式(2) 生成标注向量,将其和词向量串联作为第2层网络输入.该阶段生成输入层为

|
(6) |
其中:ui为位置i处单词在第1层标注结果对应的标注向量,该向量由式(2) 得到;g为目标词窗口大小.在此阶段,由式(6) 得到输入层l1,接着将其输入至一个BP神经网络结构中.
2.4 模型训练本模型训练过程包括有监督训练和无监督训练两部分.在无监督训练过程,使用中国学生写的英文文章作为无标语料,训练得到一个词向量映射表.在有监督训练过程中,将无监督训练得到的词向量映射表作为词性标注模型中W1的初始化值,然后再利用有标训练语料,对第1层神经网络结构进行有监督训练.
2.4.1 无监督训练过程在本结构中,词向量充当单词特征的角色,并且Collobert实验证明,使用大量无标注语料对其进行无监督训练可以使结果更好[8].无监督训练词向量映射表的方法有多种:Bigram神经网络用于生成词对应的词向量[11]、训练一个基于神经网络的语言模型得到词向量[6]、使用CBOW(continuous bag-of-words model)和Skip-gram模型训练词向量[9].
2.4.2 有监督训练过程以第1层神经网络训练过程为例,首先通过在有标注训练集合D上,使用极大似然目标函数值和梯度上升算法更新模型参数.极大似然目标函数为
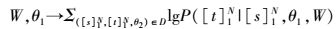
|
(7) |
其中:[s]1N表示训练集中的英文句子,[t]1N表示英文句子对应的词性标注串.定义:
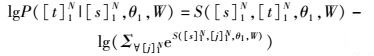
|
(8) |
其中∀[j]1N表示任意长度为N的词性标注串.
本结构采用梯度上升的方法,通过式(7),对函数中的参数值进行更新.训练时,每次迭代过程对参数θ1更新如下:

|
(9) |
其中:λ为模型参数更新的变化率;θ1为第1层神经网络参数,包括M1、b1和转移矩阵A.
3 实验3.1 实验数据本实验的有标注语料和测试语料来自于吴坤的词性标注实验语料[12].该语料也来自批改网收集的中国学生写的英语文章,选取其中9 077条作为有监督训练语料,1 346条作为测试语料.该语料中常有泊来词、专有名词、臆造词等非常见词,同时伴随着拼写错误,单复数误用,时态或语态错误,冠词、介词、代词、非谓语动词的误用等现象.针对上述问题,使用的词向量由学生作文语料训练得到,一定程度上,对含有语法错误的句子进行了拟合.另外,提取少量的人工特征,用来弥补因拼写错误、未登录词等造成的词性标注不准确的问题.
3.2 实验超参数实验超参数如表 1所示.
|
|
表 1 实验超参数表 |

面向中国学生写的英文文章的词性标注是基于词向量的词性标注,在这个标注过程中,使用词向量代替大部分的人工提取的特征.通过对比不同方法初始化词向量映射表得到的词性标注准确率,选择一种合适的无监督训练词向量的方法.笔者提出的基于词向量的词性标注是双层的标注结构,对于双层标注的有效性可通过下面的实验证明.
实验根据第2节设计的两层标注方法,首先使用学生作文进行无监督训练,得到词向量表;然后使用该词向量表,对有监督的训练中的单词进行初始化.在实验中,为验证两层方法的有效性,对不同的无监督训练词向量方法、标注方法(是否双层标注)进行组合并分别进行实验.实验结果如表 2所示,其中,S1、S2、S3、S4、S5分别表示随机值初始化词向量、Bigram神经网络生成词向量、训练一个语言模型生成词向量、使用CBOW模型生成词向量、使用Skip-gram模型生成词向量等5种不同词向量生成方式;C1表示只使用第1层标注方法进行词性标注,C2表示只使用第2层标注方法进行词性标注,C3表示基于词向量的两层词性标注结构.
|
|
表 2 不同实验组合实验结果 |
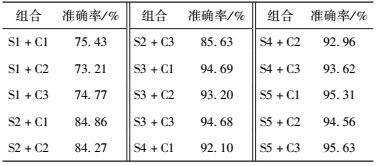
如表 2所示,两层的标注方法与一层的标注方法相比,词性标注的准确率较高,可以证明两层结构的有效性;使用CBOW或者Skip-gram来训练词向量用于标注模型相比训练语言模型生成词向量或者随机设置的方式用于标注模型,得到的标注准确率更高,证明了所提出的基于词向量的标注模型的有效性;当使用Skip-gram模型初始化词向量映射表,并且使用两层标注方法对中国学生写的英文文章词性标注时,词性标注的准确率最高.
标注器GENIA Tagger和Senna在词性标注中,都有较好的效果.通过实验比较了这两种标注器和所提出的两层标注模型S在中国学生写的英文文章上的词性标注准确率,实验结果如表 3所示. GENIA Tagger和Senna在华尔街日报语料中词性标注准确率分别达到了94.49%和95.23%,所提出的词性标注方法相对标注器GENIA Tagger和Senna都有所提高.由表 3可知,虽然Senna和S只使用了少量的人工特征,但是这两种标注效果并不比GENIA Tagger差.这说明在标注过程中,词向量确实可以代替部分人工提取的特征.除此之外,由表 3可以看出,S的标注准确率比Senna高0.4%.这说明所提出的方法比Senna更适用于对中国学生写的英文文章进行词性标注.
|
|
表 3 不同模型的标注准确率 |
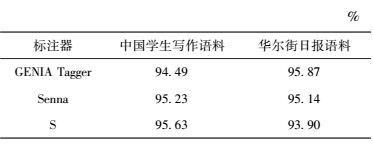
为了测试标注集对其他语料的适用性,使用华尔街日报23章语料作为测试集,利用GENIA Tagger、senna和所提模型对其标注.标注结果如表 3所示.基于词向量的两层词性标注方法对华尔街日报语料标注准确率只有93.90%,低于其他两种标注器的标注准确率,原因可能是基于词向量的两层词性标注方法受训练语料的影响较大.
4 结束语提出了一种基于词向量针对中国学生写的英语文章的词性标注方法.该方法首先对输入的句子进行第1层标注,将所有的名词和动词分别使用“N”和“V”进行标注,其他词性的单词进行直接标注;然后利用第1层标注结果对不易标注的词(第1层中标注为“N”和“V”的单词)进行第2层标注,将不易标注的词进行更加详细的标注.
笔者提出的标注结构是一种基于词向量的神经网络,利用该神经网络对中国学生写的英语文章进行词性标注,标注准确率从95.23%提高到95.63%,超过了现有的词性标注器对相同语料词性标注的准确率.
| [1] | Toutanova K, Manning C D. Enriching the knowledge sources used in a maximum entropy part-of-speech tagger[C]//Joint Sigdat Conference on Empirical Methods in Natural Language Processing and Very Large Corpora:Held in Conjunction with the, Meeting of the Association for Computational Linguistics. Hong Kong:Association for Computational Linguistics, 2000:63-70. |
| [2] | Màrquez L, Giménez J. A general pos tagger generator based on support vector machines[J].JMLR, 2004(5): 1253–1286. |
| [3] | Shen L, Satta G, Joshi A. Guided learning for bidirectional sequence classification[C]//Meeting of the Association for Computational Linguistics, Prague, Czech Republic:Association for Computational Linguistics. 2007:760-767. |
| [4] | Olutobi Owoputi, Brendan O'Connor, Chris Dyer, et al. Improved part-of-speech tagging for online conversational text with word clusters[C]//Proceedings of NAACLHLT 2013. Los Angeles, California:Association for Computational Linguistics, 2013:380-390. |
| [5] |
李红. 大学生英语写作常见错误归类分析[J]. 当代教育论坛:学科教育研究, 2006(8): 120–121.
Li Hong. The common errors analysis of college englishwriting[J].Forum on Contemporary Education, 2006(8): 120–121. |
| [6] | Bengio Y, Ducharme R, Vincent P, et al. A neural probabilistic language model[J].Journal of Machine Learning Research, 2003, 3(6): 1137–1155. |
| [7] | Alexandrescu Andrei, Kirchhoff Katrin. Factored neural language models[C]//Proceedings of the Human Language Technology Conference of the NAACL. New York City, USA:[s. n.], 2006:1-4. |
| [8] | Collobert R, Weston J, Bottou L, et al. Natural language processing (almost) from scratch[J].Journal of Machine Learning Research, 2011, 12(1): 2493–2537. |
| [9] | Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[EB/OL]. 2013-09-05. https://arxiv.org/abs/1301.3781. |
| [10] | Santos C N D, Zadrozny B. Learning character-level representations for part-of-speech tagging[C]//International Conference on Machine Learning. Beijing:ICML, 2014:1818-1826. |
| [11] | Collobert R. Deep learning for efficient discriminative parsing[C]//The 14th International Conference on Artificial Intelligence and Statistics. Fort Lauderdale, Florida:AISTATS, 2011:224-232. |
| [12] |
谭咏梅, 吴坤. 面向英语文章的词性标注算法[J]. 北京邮电大学学报, 2014, 37(6): 120–124.
Tan Yongmei, Wu Kun. A part-of-speech tagging method for English essay[J].Journal of Beijing University of Posts and Telecommunications, 2014, 37(6): 120–124. |