


为了保证数据文件的安全传输,以传统隐藏模型为基础,提出了同类型信息自适应隐藏模型.通过增加隐藏算法库和载体模板库,同时引入数据文件的等级和标签,达到自动选择合适的隐藏算法和载体文件的目的.在该模型中,通过生成混沌序列,实现了对数据文件的双置乱加密,并针对数据文件,实现了基于不同类型文件的大容量隐藏算法,改进了基于最低有效位的图像隐藏算法.最后,通过一系列实验验证了模型的正确性和安全性.
There are different types of data in big data platform, in order to ensure the secure transmission of data files, an adaptive model of information hiding based on the traditional information hiding model was proposed. By increasing the hiding algorithm library and carrier file library, the appropriate hiding algorithm and the carrier file can be chosen automatically according to the level and the tag of data files. In the model, the double scrambling of the data file with generating chaotic sequence was implemented, the large capacity hiding algorithms for different types of files was realized, and the image hiding algorithm based on the least significant bit was improved. Finally, the evaluation contrast for the different hiding algorithm was described. Experiment shows that the model can perform correctly and safely.
随着大数据的快速发展,数据平台中通常存在多种类型的数据文件,这些数据文件的重要等级也不尽相同,因此数据文件在提供和传输过程中的安全性是一个关键问题.针对这个问题,笔者提出了同类型信息自适应隐藏模型,即某类数据隐藏后类型不变,以期获得安全保障的同时又具备一定的迷惑性.目前,针对图像和文本文件的信息隐藏都得到了广泛的研究并取得了一定的成果[1-6],但都是针对某一特定类型文件从不同角度考虑算法能力的提升.笔者针对Word、PDF和图像文件,结合数据文件私密等级,构建同类型信息自适应隐藏模型,通过对不同类型隐藏算法进行优化和整合,设计并实现了相关隐藏算法,并按照信息隐藏的一般指标进行算法评估,实验结果验证了该隐藏模型的安全性.
1 隐藏模型在基本隐藏模型的基础上[2],增加隐藏算法库和载体模板库,并引入数据文件的等级,通过读取私密文件的等级系数和类型判定,从算法库中选择针对该类型合适的隐藏算法;同时对载体文件进行按类别分类,并用标签标记,根据私密文件的大小、标签和针对此类型所选用隐藏算法的嵌入容量,从载体库中动态选择合适的载体文件,对私密文件进行混沌序列加密,同时嵌入密钥,构建出同类型信息自适应隐藏模型,如图 1所示.

|
图 1 同类型信息自适应隐藏模型 |
定义1 利用八元组{C, M, K, S, A, EK, σ, t}表示自适应隐藏模型,参数说明如下.
私密文件M(message):用户输入的所有可能的私密文件.
载体文件C(cover):在平台上所储存的所有类型的可用于公开传播的文件集合.
含密载体S(stego):所有含密载体的集合.
密钥集合K(key):K是整个系统的密钥集合.
隐藏算法A(algorithm):针对3种类型文件的隐藏算法集合.
等级系数σ:σ用于表示平台上数据文件的私密等级系数.在数据平台下,对文件划分为了低级、普通、中级和高级4个等级,分别对应σ取值0、1、2、3.σ为0时,表示文件可以公开传输;σ越大,表示文件私密等级越高.
文件标签t(tag):文件所属的不同类别.引入标签,可以达到选择与私密文件相关性较大的载体文件的目的,从而增强迷惑性.
自适应隐藏算法EK:集合C、M到S的一个映射,即EK:EK(C, M, A, σ, t)→S.
在算法实现过程中,隐藏算法和载体文件都以集合的形式存在,形成隐藏算法库和载体文件库,以供文件隐藏时的自适应选择.
算法自动选择是遵从σ到隐藏算法A的映射规则σ Ai,其中σ取值为0、1、2、3,i取值为0、1、2.有如下映射规则:
σ=0,文件可公开传输;
σ=1→A0,A0代表顺序嵌入算法;
σ=2→A1,A1代表随机选择嵌入算法;
σ=3→A2,A2代表多备份嵌入算法.
当数据平台上的文件被请求时,读取文件的等级系数σ,根据映射规则,选择隐藏算法.
下面详细介绍密钥和logistic混沌序列生成,以及私密信息隐藏功能的实现.
2 自适应信息隐藏算法 2.1 自适应隐藏算法构建针对同类型信息自适应隐藏模型,给出自适应隐藏算法.
算法1 自适应隐藏算法
输入:用户所请求文件的字节流
输出:载密文件的字节流
步骤1 从字节流中提取文件头信息,判断用户所请求文件类型.
步骤2 提取此文件的等级系数σ和标签t,确定隐藏算法的选定.
步骤3 针对步骤2中所选用的隐藏算法,进行私密信息的精炼提取.
步骤4 随机生成初始值m0,调用算法2,采用位置和数值双置乱进行加密处理.
步骤5 根据私密信息大小和所选用隐藏算法的嵌入容量,选择同标签、同类型合适的载体文件.
步骤6 初始值m0作为密钥嵌入到载体图像中.
步骤7 进行信息隐藏,生成载密文件,返回载密文件字节流.
2.2 加密隐藏算法在私密文件进行隐藏之前,需要对私密文件进行初步的加密处理,采用基于混沌序列的加密方法.1998年,Baptista提出了混沌加密系统[3],logistic映射是一类被广泛研究的动力系统,定义为
| $ {{x}_{k+1}}=\mu {{x}_{k}}\left(1-{{x}_{k}} \right) $ | (1) |
其中:xk∈(0, 1),μ∈[0,4].
基于logistic映射,实现了位置和数值双置乱加密算法,用于对私密序列进行加密处理.
算法2 双置乱加密算法
输入:初始值m0、私密信息字节流
输出:双置乱加密后的私密信息字节流
步骤1 输入初始值m0,根据式(1),生成与私密信息等长的位置序列a(a0, a1, …, an)和数值序列b(b0, b1, …, bn),其中ak∈[0, n),bk∈[0, 255).
步骤2 根据位置序列a(a0, a1, …, an),将序列a中的值与私密信息序列L下标值一一对应,得到位置置乱后的私密信息序列L′={l′0, l′1, …, l′n},其中l′k=lak.
步骤3 将步骤2后的结果L′与数值序列b(b0, b1, …, bn)中的值一一进行异或加密,得到数值置乱后的序列L″={l″0, l″1, …, l″n},其中l″k=l′k⊕bk.
步骤4:返回双置乱后的私密信息字节流L″.
2.3 隐藏算法选择设计 2.3.1 基于图像隐藏算法最低有效位(LSB, least significant bit)信息隐藏算法是最早提出的图像空域信息隐藏算法.根据数据文件的重要程度不同,基于LSB信息隐藏算法实现了针对图像文件的顺序嵌入和随机嵌入大容量信息隐藏算法[4],在此基础上进行改进,设计并实现了基于LSB的多备份嵌入算法,通过在一个载体图像中嵌入多份不同序列顺序的私密信息,提高算法的鲁棒性,增强抗攻击性.
1)隐藏序列
将二进制私密信息序列分为5个子段,记为P、B、C、D、E,则可以将子段的顺序进行有规律的调换,依次可以得到下列私密信息序列:
| $ \begin{matrix} {{Q}_{0}}=\left\{ PBCDE \right\}, {{Q}_{1}}=\left\{ EDBPC \right\}, {{Q}_{2}}=\left\{ DCEBP \right\}, \\ {{Q}_{3}}=\left\{ BEPCD \right\}, {{Q}_{4}}=\left\{ CPDEB \right\} \\ \end{matrix} $ |
将这5个序列列为一个方阵,则此方阵的每一行每一列都是一份完整的私密信息序列,将其依次隐藏在载体图像中,可以保证私密信息分散在整个载体空间的同时,载体空间的不同位置都有对不同私密信息子段的隐藏.
2)隐藏位置
设载体图像I的宽度为W,高度为H,私密信息二进制序列长度为v,每一字节嵌入ε位,则嵌入容量V=WHε.
令z=V/v,则一个间隔的大小为z,将此间隔大小尽可能均匀地分为5份,长度记为d,则可以由式(2)分别得到5个序列中第k个序列的第i位私密信息在载体图像中的隐藏位置.
| $ \text{Locatio}{{\text{n}}_{k}}\left(i \right)=iz+\left(k-1 \right)d+\log \ \text{istic}\left[i \right]\bmod \ d $ | (2) |
算法3 基于图像文件的多备份随机嵌入
输入:私密信息字节流、载体图像、初始值m0
输出:载密文件字节流
步骤1:将私密信息字节流转为二进制序列.
步骤2:遍历载体图像的每个像素点,分离R(红)、G(绿)、B(蓝)的值,并存在一维数组中.
步骤3:输入初始值m0,根据式(1)生成与二进制私密信息序列等长的混沌序列.
步骤4:将二进制私密序列分成5个子段,得到5个子段处在不同位置的私密序列.
步骤5:计算间隔长度m和子段子间隔l.
步骤6:依次遍历每份二进制私密信息的每个比特,根据式(2),得到每份中此比特所要嵌入的位置,并嵌入到此位置所在数值的最后一位.
步骤7:m0作为密钥嵌入载体图像中.
步骤8:生成载密文件,返回载密文件字节流.
2.3.2 基于文本隐藏算法目前在文本信息隐藏领域,基于文本格式的隐藏算法特征是以调整文本中的某些格式信息来实现隐藏的[5].基于语义和基于语法的文本隐藏算法也得到了相应的研究[6].
将数据文件作为私密信息,结合自适应隐藏模型,针对Word文件,充分利用Word文档本身的格式冗余,实现了利用下划线和空格隐藏私密信息;针对PDF,利用其特有的文档结构,实现了基于PDF文档的隐藏算法[7].
3 实验结果 3.1 实验环境本实验是在Windows 7系统上,通过JAVA开发平台得以实现的.其中,基于开源工具Lire搭建了基于内容的图像检索,实现了选择与私密图像最相似的图像作为载体.本实验相关数据通过在如表 1所示的软硬件环境下得到.
|
|
表 1 实验环境 |
实验分别从功能验证、安全性验证和算法评估对比3个方面给出实验结果.
3.2.1 功能验证根据所请求的文件等级系数,遵从映射规则,选择相应的隐藏算法;同时进行对文件类型的判定,确定载体文件的类型.
本实验针对图像文件,建立了3种不同类别的载体图像库,基于Lire建立图像特征索引,选择同一标签下最为相似的图像作为载体.文件自适应隐藏功能性验证实验结果如表 2所示.
|
|
表 2 文件自适应隐藏功能性验证实验 |

实验的安全性从两个方面进行验证,分别是不可感知性和抗攻击性.
1)不可感知性
不可感知性从两个指标来衡量,分别是灰度直方图和峰值信噪比(PSNR,peak signal to noise ratio).通过衡量含密载体图像与原始载体图像的灰度直方图,可以很直观地看出图像的改变.采用PSNR值来衡量嵌入私密信息后的图像显示质量,在PSNR值大于39 dB时,肉眼就已无法感知变化[8].在本实验中,PSNR值达到了50 dB以上.不可感知性验证实验结果如表 3所示.
|
|
表 3 不可感知性验证实验 |



2)抗攻击性
实验中,对抗攻击性的测试主要从抗剪切的角度进行.多备份嵌入算法可以抵抗一定的从不同角度的剪切攻击.对从不同角度、不同范围的受剪切图像提取私密图像,实验结果如表 4所示.
|
|
表 4 剪切提取实验 |








针对某一个大小为10.5 KB的私密图像,分别采用3种隐藏算法,选用相同的载体图像,从PSNR、嵌入容量、执行速度、灰度直方图对比和鲁棒性5个方面进行隐藏算法的评估对比,实验结果如表 5所示.
|
|
表 5 图像隐藏算法评估对比实验 |
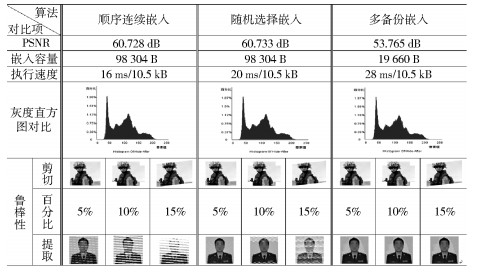
由实验结果可以看出,多备份嵌入算法在嵌入容量和执行速度上虽然不如顺序连续嵌入和随机选择嵌入两种算法,但是,多备份嵌入算法在保证高PSNR值的同时,在相同角度、同等面积的剪切程度下,仍可以很好地将私密图像提取还原,其算法的鲁棒性要远远优于其他两种算法,具有较高的安全性.
同时,针对基于文本隐藏算法,将所实现的算法与基于语法语义算法进行实验对比,实验结果如表 6所示.实验结果表明,所选用的基于文本的隐藏算法在保证一定安全性的同时,隐藏容量大大提升.
|
|
表 6 基于文本隐藏算法评估对比实验 |
结合基于不同文件类型的隐藏算法,在用户请求数据文件时,选择同类型的载体文件和合适的隐藏算法,构建出同类型信息自适应隐藏模型.对其中的一些隐藏算法结合模型本身做出了一些改进和完善.利用信息隐藏的方法增强对敌手的迷惑性,从而保证了数据文件在传输过程中的安全性.
| [1] | Ma Hengtai, Yi Xiaowei, Wu Xiaohui, et al. A capacity self-adaption information hiding algorithm based on RS code[C]//IEEE International Conference on Multisensor Fusion and Information Integration for Intelligent Systems. Beijing:IEEE, 2014:1-8. |
| [2] | Gu Chunying, Gao Xiaoli. Research on information hiding technology[C]//2012 2nd International Conference on Consumer Electronics, Communications and Networks(CECNet 2012). Yichang:IEEE, 2012:2035-2037. |
| [3] | Baptista M S. Cryptog raphy with chaos[J]. Physics Letters A , 1998 (8) :50–54. |
| [4] | Sutaone M S, Khandare M V. Image based steganography using LSB insertion technique[C]//IET International Conference on Wireless, Mobile and Multimedia Networks. Beijing:IET, 2008:146-151. |
| [5] | Young-Won Kim, Kyung-Ae Moon, Il-Seok Oh. A text watermarking algorithm based on word classification and inter-word space statistics[C]//Proceedings of the Seventh International Conference on Document Analysis and Recognition(ICDAR 2003). [S. l.]:IEEE, 2003:775-779. |
| [6] | Li Binbin, Wang Yanbo, Xu Min, et al. An information hiding method with passive detection in Word 2007[J]. Journal of Computer Research and Development , 2010, 5 (20) :154–157. |
| [7] | Huang Simin, Sun Xingming, Fu Zhangjie. A novel information hiding algorithm based on page object of PDF document[C]//2011 Tenth International Symposium on Distributed Computing and Applications to Business, Engineering and Science. Wuxi:IEEE, 2011:266-270. |
| [8] | Sajedi H, Jamzad M. Cover selection steganography method based on similarity of image blocks[C]//2008 IEEE 8th International Conference on Computer and Information Technology Workshops(CIT Workshops 2008). Sydney:IEEE, 2008:379-384. |