


2. 北京邮电大学 自动化学院, 北京 100876
针对现有面向C语言的故障注入工具功能上的不足,基于程序变异技术设计并实现了一个面向C语言的故障注入平台.平台由故障注入、故障模型、批量执行和结果分析4个模块组成,可自动完成故障注入和执行的整个流程.使用实际开源项目中的程序和其他故障注入工具进行实验对比,结果表明,该平台可支持更多实际工程中的函数,可对实际工程进行获取故障检测率的实验,整体适用范围更广.
2. Automation School, Beijing University of Posts and Telecommunications, Beijing 100876, China
To improve the accuracy and efficiency of existing fault injection tools, a C-language oriented fault injection and execution platform was presented. The platform is constructed by fault injection, fault model, batch execution and results analysis modules. Experiments show that comparing with other fault injection tool when used the open source projects, the platform can support more practical engineering functions.
软件测试领域中,基于故障的测试技术是对传统测试方法的有力补充,可发现其他测试方法难以检测的故障,具有更强的检错能力. 但现有的故障注入工具[1-2]存在故障注入成功率低、易用性和可扩展性较差等问题,难以满足工程开发的需要. 为提高故障注入的自动化程度,提高故障注入成功率,基于程序变异技术设计并实现了一个面向C语言的故障注入平台. 使用Java语言实现,使用抽象语法树作为故障注入的基础数据结构,采用了预处理和语义检测等技术,提高了故障注入的成功率.
1 设计与实现面向C语言的故障注入平台主要由4大部分组成:故障注入、故障模型、批量执行和结果分析. 整体框架如图 1所示.
1.1 故障注入模块故障注入模块的输入是待注入的C语言源代码文件,输出是一组故障文件集合,其中每个文件分别使用了相应的故障模型. 具体由5个子流程构成.
1) 预处理待注入文件
为了对实际C语言工程进行更好地支持,需要对待注入的源代码文件进行预处理. 预处理主要包括:从实际工程的make文件中提取编译选项等信息,对条件编译等语句进行处理;调用C语言编译器的预处理等命令,进行宏定义展开;生成中间文件等. 对源代码文件进行预处理,可尽量避免注入失败的情况发生.

|
图 1 故障注入平台框架 |
2) 生成抽象语法树
抽象语法树(AST,abstract syntax tree)是程序在编译过程中的一种抽象表示形式. AST可直观地表示出源程序的语法结构,且包含源程序语法分析所需的全部静态信息,是故障注入所需信息的主要来源. 建立AST是后继注入工作的基本前提. 具体流程为:首先将步骤1) 生成的预处理文件进行词法转换,生成字符序列,再进行词法分析. 剔除空白符和注释信息等,将余下代码内容进行递归向下分析,将词法符号进行语法规则匹配,最终生成语法树.
3) 选取故障模型
故障模型即源代码内容替换规则,也称为变异算子. 该平台实现了12类传统的C语言变异算子.
4) 遍历抽象语法树,确定故障注入点
使用访问者模式对抽象语法树进行遍历,逐个结点提取语法信息. 然后再根据选定的故障模型,生成对应的故障注入点. 故障注入点是程序结构信息和故障信息抽象表示的集合. 故障注入点为变异算子指定了具体的注入位置. 对于一个程序而言,故障模型和故障注入点是一对多的映射关系,即一种故障模型可对应多个故障注入点.
5) 进行语义检查,生成故障文件
生成的故障文件需要能够编译成功. 这要求在语法替换的同时,还要保证语义的正确性. 所以在注入过程中,对拟生成的故障文件进行了语义检查,排除无法通过编译的无效故障. 如除数是常量时,不将其替换为0;2个指针变量相减时,不对其进行相加的替换等. 这样会减少无效的故障文件,减少后继环节的执行成本和分析成本.
1.2 故障模型模块故障模型,也称变异算子,是人们在长期程序开发实践中总结出的模拟实际故障的一种源代码语法替换规则. 该平台具体使用程序变异技术来描述故障模型,下面以变异算子来表示故障模型.
目前主要的C变异算子集是1996年由Mathur[3]提出的,分为语句变异、操作符变异、常量变异和变量变异共4大类77种. 该平台也以该算子集为基础进行设计.
结合该平台的实际设计要求,对故障模型进行如下定义.
定义1 故障模型MOS是一个四元组,MOS={C,L,R,S}. 其中:
a) C为注入点的上下文环境信息的集合,C={Pre,Post}. Pre代表了注入点的前置信息,Post代表了注入点的后置信息,两者都是抽象语法树节点及其相关信息的集合.
b) L为源文件在注入点位置的字面信息表示.
c) R为语法替换规则函数,指明了具体由L替换为的内容.
d) S为语义检测规则集合,指定了无效语义的情况.
故障模型在与故障注入模块的交互主要为:上下文环境信息集合C和字面信息L是由抽象语法树获得;替换规则函数在确定故障注入点过程中被其调用;语义检测规则集合S,在语义检查阶段被调用.
和Milu[2]等采用C语言编写的变异工具相比,由于使用了面向对象的编程方法,该平台具有易维护和易扩展等特点. 例如,使用了设计模式中的工厂模式,避免了繁复的创建对象操作;使用了抽象类的故障层级设计,可方便地对故障模型进行扩展.
具体实现类图如图 2所示. 其中,AbstractMutation是所有故障模型的父类,其包含的属性有上下文环境信息集合Context,注入点位置的字面信息Literal,语法替换规则Substitution和语义检测规则SemanticCheck. 扩展新故障类型时,可直接继承这些子类,写入新的替换规则.

|
图 2 故障模型实现类图 |
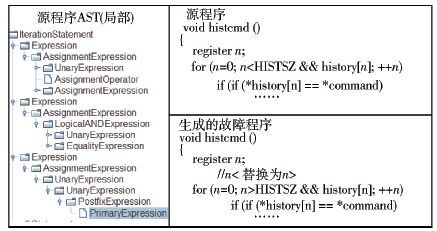
下面以实际开源工程中的程序为例说明故障注入的流程. 选取程序为deco39工程(出自http://deco.sourceforge.net)中的com.c的histcmd函数. 对其中第214行的for语句进行故障注入. 使用的是关系运算类故障,目标是将“<”替换为其他关系运算符.
首先对源程序com.c进行预处理,进行条件编译、宏定义展开等操作,再根据生成的中间文件构建抽象语法树. 对抽象语法树进行遍历分析,构建上下文环境信息集合. 此例的Pre集是for循环初始值表达式n=0代表的AssignmentExpression表达式,Post集是for循环条件递增表达式UnaryExpression. L代表的源文件在注入点位置的字面信息是关系运算符“<”. 语法替换规则R为R(<)={>,≥,≤,!=}. 按此替换规则,在这个注入点可生成4个故障文件,但其中“<”替换为“!=”为无效故障,即只改变了语法形式,但语义保持不变,没有用例可检测出这个故障. 事先在语义检测规则集合S中写入了“<”不替换为“!=”. 该注入点则只生成有效的3个故障. 表 1左侧为源程序的局部抽象语法树表示;右侧为源文件和一个故障文件的对比,该故障文件是“<”替换为“>”.
|
|
表 1 故障注入实例 |
故障注入执行完毕后,产生了大量的故障文件,下一步就要使用测试用例集在每一个故障文件上执行.
1) 执行准备
包含执行环境的构建和故障文件的预处理. 执行环境包含有main入口的执行主体程序和记录执行信息的子程序. 故障文件的预处理包含条件编译和宏定义展开等,使故障文件可被执行主体程序调用.
2) 批量执行
对步骤1) 中生成的故障文件集合逐一进行编译、汇编和链接,生成一组对应的可执行文件. 为自动化执行测试做好准备. 然后逐一选择故障文件集合中的故障文件,使用用例集中的每个用例在故障文件上执行,直到所有故障文件均执行完毕.
1.4 结果分析模块所有故障文件执行完毕后,对结果进行分析,计算故障检测率,给出测试报告. 具体输出的结果为故障检测率[4],其定义为
| $故障检测率=\frac{检测出的故障总数}{生成的故障总数-等价故障}\times 100%$ |
为验证故障注入平台的可用性和实用性,从故障文件注入成功率和对实际工程的支持能力2个方面进行实验.
以下实验的环境配置均为Ubuntu 12.04、JDK 1.6、gcc 4.6;使用的硬件配置为Intel Pentium 2.90 GHz,4 GB内存.
2.1 故障文件注入成功率为验证故障注入成功率,与开源C语言故障注入工具Milu进行了对比. 使用的程序来自经典的SIR库. 具体是从中选择10个源文件分别使用Milu进行注入和使用该平台进行注入,比较可成功注入故障的函数个数. 这10个文件大小从173行到18 664行,包含函数从18个到200个.
图 3是该平台和Milu工具的比较结果,可见该平台可支持更多函数. 主要是该平台在对源程序生成抽象语法树时,增加了对宏定义、外部变量等情况的额外处理和对指针类型故障添加了语义替换的控制规则. 而Milu对这些情况支持不好,如对部分宏定义无法正确展开,导致程序代码不完整;未排除指针相加等无效的语义替换规则,导致生成的变异体在编译时,会发生访问不存在的指针地址或访问错误的指针地址,报出段错误,致使编译失败,无法产生注入故障的文件. 从具体结果来看,对小型的程序,如173行的tcas、307行的sch和563行的prt,Milu和该平台注入成功率相近,但随着程序长度加大,如对18 664行的make和11 782行的flex等程序,宏定义和指针运算增加,该平台采用的相关策略开始起作用,注入成功率逐渐高于Milu.

|
图 3 故障文件生成结果对比 |
为验证增加的宏定义、外部变量等预处理操作的时间开销,对该平台和Milu均可成功处理的原文件进行了预处理操作的耗时分析. 共选取300个函数,合计21 652行,结果如表 2所示,可见该平台的时间开销大于Milu.
|
|
表 2 预处理性能对比结果 |
但是,在实际使用中对一个C源文件,只需进行一次对宏定义、外部变量的预处理. 首先,其结果可供后继生成多个故障文件时直接使用,无须再次处理. 其次,如果无效的故障文件进入了后继的故障检测环节,可能引发检测结果不准确. 此时需要人工涉入进行分析,将消耗更多的人工成本. 因此,预处理耗费的时间是值得的. 综上,时间开销可接受,但后续仍需加大对程序性能的优化.
2.2 对实际工程进行故障检测为验证该平台在实际工程中的可用性,对开源C工程的源程序文件注入故障,验证故障检测率. 使用的测试用例集是笔者所在实验室开发的代码自动化测试系统CTS生成,分支覆盖率达到100%. 选取的程序属性如表 3所示. 检测结果如图 4所示.
|
|
表 3 实验所用程序属性 |

|
图 4 实际工程故障检测率结果 |
分析实验结果可以看出,首先,满足分支覆盖的用例集检测效果很好. diurpx和view的故障检测率均为100%,函数diurab和annuab也均超过了95%,最低的qshici也到达了78%以上. 可见,分支覆盖准则的检测效果明显. 其次,尽管分支覆盖对 大部分故障类型有较强的检测能力,但对边界类故障检测效果不佳,如“>”替换为“>=”等. 这也是该次实验检测率未达100%的主要原因. 这要求测试人员在构造满足分支覆盖的用例集后,仍需添加满足边界值覆盖的用例.
通过该平台对来自3个实际开源C工程的10个文件进行故障检测实验,成功注入故障并分析了结果,表明该平台基本可满足对实际工程的测试需求.
3 结束语设计并实现了面向C语言的故障注入平台,可在一定程度上提高基于故障的测试方法的有效性,可对实际开源C工程进行故障检测,提高了基于故障的检测方法在实际工程中的可用性.
下一步的研究任务,一是构建新的故障模型,如模拟变量修饰符、指针操作等针对C语言自身特征的故障;二是优化执行效率,进一步提高程序性能.
| [1] |
Delamaro M E, Maldonado J C, Mathur A P. Proteum-a tool for the assessment of test adequacy for C programs[C]//Proceedings of the Conference on Performability in Computing Systems. New Jersey:New Brunswick, 1996:79-95.
( 0) 0)
|
| [2] |
Yue Jia, Harman M. Milu:a customizable, runtime-optimized higher order mutation testing tool for the full C language[C]//Academic and Industrial Conference Practice and Research Techniques. UK:IEEE Computer Society, 2008:94-98.
(0)
|
| [3] |
Kusano M, Chao Wang. Ccmutator:a mutation generator for concurrency constructs in multithreaded C/C++ applications[C]//ASE. IEEE/ACM 28th International Conference on. NJ:Piscataway, 2013:722-735.
(0)
|
| [4] |
Yue Jia, Harman M. An analysis and survey of the development of mutation testing[J]. IEEE Transactions on Software Engineering , 2011, 37 (5) :649–678.
doi:10.1109/TSE.2010.62 (0)
|