


针对无线自主网络中的信息扩散,提出了一种高效的资源分配机制.首先,使用一个传输队列来描述扩散信息的动态到达和离开过程.针对用户信息数据队列和无线传输信道的时变特性,将动态的信息扩散描述为多用户的马尔可夫决策过程,并将多用户的马尔可夫决策过程进行分解.为了降低算法的复杂度,提出了一种基于模型的在线学习方法.在用户信息数据到达率和无线信道变化的情况下,用户通过在线学习,仅需1次迭代就可确定自身具有预见性的行为决策.
An efficient resource allocation mechanism was proposed for information diffusion in wireless autonomic networks. First, the dynamic arrival and leave process of the information data is characterized by a transmission queue. To cope with the dynamic transmission queues and wireless channels, the information diffusion problem is formulated as a multi-user Markov decision process (MMDP) which can be decomposed by using the principle of dual method. To reduce the computation complexity, a model-based online learning method was proposed based on which the user can make a foresighted decision by iterating only once when the network state changes.
无线网络中的信息数据到达率和无线信道动态变化会使无线网络不能为用户信息的扩散提供完美的服务质量[1, 2].为了改善信息扩散的性能,网络中的节点应能对无线信道和信息数据到达率的动态变化做出及时的应对策略,从而有预见性地分配网络资源.
以无线自主网络为背景,对用户信息在动态分布式网络中的高效扩散进行研究.针对信息数据到达率和无线信道动态特性,将信息扩散描述为多用户的马尔可夫决策过程,并运用对偶分解原理将其分解.在信息数据到达率和无线信道动态变化的情况下,用户通过在线学习,仅通过1次迭代就可确定自身具有预见性的行为决策,从而达到传输收益长期最大化的目的.
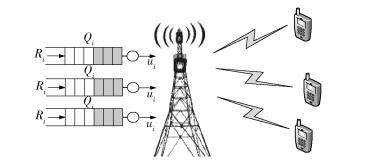
1 系统模型考虑一个时隙离散的无线网络,如图 1所示. 无线用户用i来表示,其中1≤i≤M. 在信息扩散的过程中,若基站在时隙t为用户i分配的传输功率大小为pit,则用户i的传输速率可表示为
|
图1 系统模型 |
| $ u_i^t = \log \left( {1 + p_i^t{{\left| {h_i^t} \right|}^2}} \right) $ | (1) |
在无线网络中,各无线用户的信息数据到达率Rit(1≤i≤M)相互独立且服从泊松分布. 用Qi表示基站中积压着的用户i的数据队列长度,则相邻时隙间积压的数据队列满足
| $ Q_i^{t + 1} = \max \left\{ {Q_i^t - u_i^t,0} \right\} + R_i^t $ | (2) |
| $ \phi _i^t\left( {p_i^t} \right) = {w_i}\log \left( {p_i^t + e} \right) $ | (3) |
李亚普诺夫稳定性理论可有效地分析网络中传输队列的稳定性.首先为基站中的用户数据队列定义一个李亚普诺夫能量函数为
| $ {L^t} = \frac{1}{2}\sum\limits_{i = 1}^M {{{\left( {Q_i^t} \right)}^2}} $ | (4) |
定义ΔLt=Lt+1-Lt为李亚普诺夫漂移. 根据式(2),可得队列的李亚普诺夫漂移为
| $ \Delta {L^t} \le \frac{1}{2}\sum\limits_{i = 1}^M {{{\left( {u_i^t} \right)}^2}} + \frac{1}{2}\sum\limits_{i = 1}^M {{{\left( {R_i^t} \right)}^2}} + \sum\limits_{i = 1}^M {Q_i^t\left( {R_i^t - u_i^t} \right)} $ | (5) |
在式(5)的左右2端加上惩罚项-VΦit(pit),其中V为正系数,得
| $ \Delta {L^t} - V\sum\limits_{i = 1}^M {\phi _i^t\left( {p_i^t} \right)} \le D - \sum\limits_{i = 1}^M {\left\{ {V\phi _i^t\left( {p_i^t} \right) + Q_i^tu_i^t} \right\}} $ | (6) |
| $ \bar \phi _i^t\left( {s_i^t,p_i^t} \right) = V\phi _i^t\left( {p_i^t} \right) + Q_i^tu_i^t $ | (7) |
| $ \begin{array}{l} \gamma \left( {s_i^{t + 1}|s_i^t,p_i^t} \right) = \\ \gamma \left( {h_i^{t + 1}|h_i^t} \right)\gamma \left( {Q_i^{t + 1}|Q_i^t,p_i^t} \right) \end{array} $ |
基站在t时刻观察到无线用户的状态sit,为用户分配传输功率pit且带来收益$ \bar \phi _i^t\left( {s_i^t,p_i^t} \right) $.在长时间内考虑无限范围的累积折扣收益,得优化问题为
| $ \begin{array}{l} {U^*} = \max \sum\limits_{s_1^0 \in {S_1},\cdots ,s_M^0 \in {S_M}} {\mathop \Pi \limits_{i = 1}^M v\left( {s_i^0} \right) \times } \\ E\left[{\sum\limits_{t = 0}^\infty {\sum\limits_{i = 1}^M {{\alpha ^t}\bar \phi _i^t\left( {s_i^t,p_i^t} \right)|{s^0}} } } \right]\\ {\rm{s}}{\rm{.t}}{\rm{.}}\sum\limits_{i = 1}^M {p_i^t \le {P_{\max }}} \end{array} $ | (8) |
在每一个状态st,对式(8)中的约束条件引入一个拉格朗日乘子λst,则式(8)的对偶函数为
| $ \begin{array}{l} U\left( \lambda \right) = \mathop {\max }\limits_{p_1^0 \in {P_1},\cdots ,p_M^t \in {p_M}} \sum\limits_{s_1^0 \in {S_1},\cdots ,s_M^0 \in {S_M}} {v\left( {s_i^0} \right)} \\ E\left[{\sum\limits_{t = 0}^\infty {\alpha \sum\limits_{i = 1}^M {\left( {\bar \phi _i^t\left( {s_i^t,p_i^t} \right) - {\lambda _{st}}p_i^t + \frac{{{P_{\max }}{\lambda _{st}}}}{M}} \right)|{s^0}} } } \right] \end{array} $ | (9) |
原问题的对偶规划可表示为
| $ {U^{\lambda ,*}} = \mathop {\min }\limits_{\lambda \ge 0} U\left( \lambda \right) $ | (10) |
问题为凸优化问题,所以原问题和对偶问题之间的对偶距离为0,即Uλ,*=U*. 解决式(9),相当于解决贝尔曼方程[2]为
| $ \begin{array}{l} U\left( {s,\lambda } \right) = \mathop {\max }\limits_{p_1^0 \in {P_1},\cdots ,p_M^t \in {p_M}} [\sum\limits_{i = 1}^M {\left( {\bar \phi _i^t\left( {s_i^t,p_i^t} \right) - {\lambda _{st}}p_i^t + \frac{{{P_{\max }}{\lambda _{st}}}}{M}} \right)} + \\ \alpha \sum\limits_{s'} {\mathop \Pi \limits_{i = 1}^M \gamma \left( {s{'_i}|{s_i},{p_i}} \right)U} \left( {s{'_i},\lambda } \right)] \end{array} $ | (11) |
由于资源的价格因子(即拉格朗日乘子)在各状态下不一致,所以各状态下的用户资源价格互相耦合在一起. 因此,暂时先假设1个各状态一致的价格因子,则式(9)可表示为
| $ \begin{array}{l} U\left( \lambda \right) = \mathop {\max }\limits_{p_1^0 \in {P_1},\cdots ,p_M^t \in {p_M}} \sum\limits_{s_1^0 \in {S_1},\cdots ,s_M^0 \in {S_M}} {v\left( {s_i^0} \right)} \times \\ E\left[{\sum\limits_{t = 0}^\infty {{\alpha ^t}\sum\limits_{i = 1}^M {\left( {\bar \phi _i^t\left( {s_i^t,p_i^t} \right) - {\lambda _{st}}p_i^t + \frac{{{P_{\max }}{\lambda _{st}}}}{M}} \right)|{s^0}} } } \right] \end{array} $ | (12) |
对应的对偶规划为
| $ {{\hat U}^{\lambda ,*}} = \mathop {\min }\limits_{\lambda \ge 0} U\left( \lambda \right) $ | (13) |
由于一致的价格因子,对偶规划式(13)不再和原问题存在强对偶关系. 相反,和它强对偶的问题为
| $ \begin{array}{l} {{\hat U}^*} = \max \sum\limits_{s_1^0 \in {S_1},\cdots ,s_M^0 \in {S_M}} {\mathop \Pi \limits_{i = 1}^M v\left( {s_i^0} \right) \times } \\ E\left[{\sum\limits_{t = 0}^\infty {\sum\limits_{i = 1}^M {{\alpha ^t}\bar \phi _i^t\left( {s_i^t,p_i^t} \right)|{s^0}} } } \right]\\ {\rm{s}}{\rm{.t}}{\rm{.}}\sum\limits_{t = 0}^\infty {\sum\limits_{i = 1}^M {\left( {{\alpha ^t}} \right)\left( {p_i^t - \frac{{{P_{\max }}}}{M}} \right)} \le 0} \end{array} $ | (14) |
进一步发现,式(14)和式(8)中的约束满足的关系为
| $ \left\{ {\sum\limits_{i = 1}^M {p_i^t \le P\max } } \right\} \subset \left\{ {\sum\limits_{t = 0}^\infty {\sum\limits_{i = 1}^M {\left( {p_i^t - \frac{{{P_{\max }}}}{M}} \right)} \le 0} } \right\} $ |
即式(8)中的约束为式(14)中约束的子集,因此有
| $ {{\hat U}^{\lambda ,*}} = {{\hat U}^*} \ge {U^{\lambda ,*}} = {U^*} $ | (15) |
从中可以看出,$ {{\hat U}^*} $为原问题的上界.
按文献[2]给出的策略,在设置各状态一致价格因子的情况下,式(14)的贝尔曼方程可分解为M个局部的贝尔曼方程和1个资源价格更新方程,且每一个局部的贝尔曼方程可描述为1个局部的马尔可夫决策过程(MDP,Markov decision process),即问题式(14)的贝尔曼方程可表示为
| $ U\left( \lambda \right) = \sum\limits_{i = 1}^M {\sum\limits_{s_0^i} {v\left( {s_0^i} \right){U^i}\left( {s_0^i,\lambda } \right)} } $ | (16) |
| $ \begin{array}{l} {U^i}\left( {s_0^i,\lambda } \right) = \mathop {\max }\limits_{{p_i} \in {P_i}} {{\bar \phi }_i}\left( {{s_i},{p_i}} \right) - \lambda {p_i} + \frac{{{P_{\max }}}}{M} + \\ \alpha \sum\limits_{s'} {\gamma \left( {{s_i}'|{s_i},{p_i}} \right)U\left( {{s_i}',\lambda } \right)} \end{array} $ | (17) |
对于资源价格,则按更新策略更新为
| $ {\lambda ^{k + 1}} = {[{\lambda ^k} + {\beta ^k}\left( {\sum\limits_{i = 1}^M {{Z^i} - \frac{{{P_{\max }}}}{{1 - \alpha }}} } \right)]^ + } $ | (18) |
| $ \sum\limits_k {{\beta ^k} = \infty } ,\sum\limits_k {{{\left( {{\beta ^k}} \right)}^2} < \infty } $ |
在前面的讨论中,式(12)强制使用了1个各状态一致的价格因子,且得出算法性能的上界$ {{\hat U}^*}\left( {{{\hat U}^*} \ge {U^*}} \right) $. 然而,此解有可能违反原问题中的功率约束而变得不可行.为了避免违反原问题中的功率约束,即$ \sum\limits_{i = 1}^M {p_i^t} > {P_{\max }} $,使用收缩规则对分布式MDP得到的最优解{pi*|i=1,…,M}处理为
| $ \hat p_i^* = \frac{{p_i^*}}{{\sum\limits_{i = 1}^M {p_i^*} }}{P_{\max }} $ | (19) |
经收缩后的解为资源分配机制的解.
3.2 基于模型的学习策略将无线用户在状态si下采取行为pi的值函数定义为
| $ \begin{array}{l} {G_i}\left( {{s_i},{p_i}} \right) = {{\bar \phi }_i}\left( {{s_i},{p_i}} \right) - \lambda {p_i} + \frac{{{P_{\max }}}}{M} + \\ \alpha \sum\limits_{s'} {\gamma \left( {{s_i}'|{s_i},{p_i}} \right)U\left( {{s_i}',\lambda } \right)} \end{array} $ | (20) |
在自主学习的框架中,通过值函数Gi(si,pi)来确定资源的分配策略. 由于各无线用户的学习过程基本相同,在下面的描述中省略状态和行为的下标. 在值函数更新的过程中,需要知晓用户节点的状态转移概率,但在现实情况下,状态转移概率并不能提前得知,因此需要在资源的分配过程中,对用户状态随行为变化的规律进行学习,并对状态转移概率进行估计. Ts,s′t(p)为无线用户状态转移概率的估计值,并在值函数的更新过程中随时间不断更新.在基于模型的学习策略中,采用最大似然策略来估计无线用户的状态转移概率. ns,s′t(p)为截止服务时刻t,无线用户在状态s时选择行为p并使状态从s转移到s′的次数. Nst(p)为截止服务时刻t,无线用户在状态s时选择行为p的次数. 对节点的状态转移概率估计为
| $ T_{s,s'}^t\left( p \right) = \frac{{n_{s,s'}^t\left( p \right)}}{{N_s^t\left( p \right)}} $ | (21) |
| $ \begin{array}{l} {G^{t + 1}}\left( {s,{p^t}} \right) = \left( {1 - {p^t}} \right){G^t}\left( {s,{p^t}} \right) + {p^t}\{ {{\bar \phi }_i}\left( {{s_i},{p_i}} \right) - \\ \lambda {p_i} + \frac{{{P_{\max }}}}{M} + \alpha \mathop {\max }\limits_P \sum\limits_{s'} {{T_{s,s'}}\left( p \right){G^y}\left( {{s^{t + 1}},p} \right)\} } \end{array} $ | (22) |
| $ \Omega (s,p) = \frac{{{\rm{exp}}\left( { - {G^t}\left( {s,p} \right)/\tau } \right)}}{{\sum\limits_{p'} {{\rm{exp}}\left( { - {G^t}\left( {s,p} \right)/\tau } \right)} }} $ | (23) |
采用Matlab软件对用户信息在自主无线网络中的扩散问题进行仿真,并与文献[4]中的Q学习策略进行比较. 需要指出的是,文献[4]中的Q学习策略没有对式(22)中的状态转移概率进行学习. 设α=0.75,ρ=0.5.
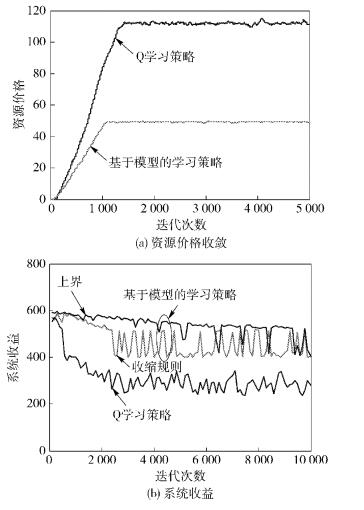
图 2(a)示出了基于模型学习策略和Q学习策略的资源价格收敛曲线. 可以看出,基于模型的学习策略可获得比Q学习策略更低的资源价格和更快的收敛速率. 这是因为在基于模型的学习策略中,用户可根据状态转移概率的估计值作出更准确的预见性决策,因此可获得更低的资源价格和更快的收敛速度.
|
图2 资源价格收敛曲线及其系统的长期收益 |
图 2(b)示出了2种学习策略下系统的长期收益.可以看出,基于模型的学习策略能获得更高的长期收益,这是因为在基于模型的学习策略中,有着更低的资源价格,所以用户可获得更多的资源来提升系统的长期收益.图 2中系统性能的上限表示不使用收缩规则时系统的长期收益,由式(15)给出.可以看出,在收缩规则下,系统的长期收益近似达到上限.
表 1所示为累积折扣因子对系统收益和系统达到稳定所需迭代次数的影响.可以看出,α越大,系统收益越高,但达到稳定所需的迭代次数越多.这是因为α越大,系统越多考虑将来时刻收益,从而产生更高的系统收益和花费更长的时间进行学习.
| 表1 累积折扣因子对系统收益和系统达到稳定 所需迭代次数的影响 |
表 2分析了学习速率ρ对系统性能的影响.从表 2可以发现,ρ越大,系统收益越低.这是因为ρ越大,系统越忽略过去的经验值(见式(22)),从而造成较低的系统收益. 从表 2还可以看出,当0.5<ρ<0.7时,系统有较好的收益和收敛速率.
| 表2 学习速率ρ对系统性能的影响 |
针对无线自主网络中的信息扩散问题,提出了一种自主的资源分配策略,并使用李亚普诺夫漂移的方法来分析网络的稳定性.随后,将问题描述为一个多用户的马尔可夫决策问题,并提出了一种对偶分解方法将问题进行分解.对于未知的信息数据到达率和无线信道状态,用户通过在线学习可确定自身具有预见性的行为决策,且能使长期传输收益最大化.
| [1] | Nie Junhong, Haykin S. A Q-learning-based dynamic channel assignment technique for mobile communication systems[J]. IEEE Trans Veh Technol, 2002, 48(5):1676-1687.[引用本文:1] |
| [2] | Fu Fangwen, Schaar M. A systematic framework for dynamically optimizing multi-user wireless video transmission[J]. IEEE J Sel Areas Commun, 2010, 28(3):308-320.[引用本文:1] |
| [3] | Bethanabhotla D, Caire G, Neely M J. Utility optimal scheduling and admission control for adaptive video streaming in small cell networks[C]//International Symposium on Information Theory. 2013:1944-1948.[引用本文:1] |
| [4] | Cui Ying, Lau V K N, Wang Rui, et al. A survey on delay-aware resource control for wireless systems-large deviation theory, stochastic Lyapunov drift, and distributed stochastic learning[J]. Information Theory, IEEE Transactions on, 2011, 58(3):1677-1701.[引用本文:1] |