


2. 北京邮电大学 可信分布式计算与服务教育部重点实验室, 北京 100876;
3. 北京市政务信息安全应急处置中心, 北京 100101;
4. 北京邮电大学 软件学院, 北京 100876
提出了一种基于自组织特征映射(SOM)神经网络和模糊c-均值(FCM)的双层聚类方法, 对Web日志中的日志数据集进行聚类.第一层是无监督SOM神经网络聚类方法, 它所产生的类的个数大大减少了原始数据集的个数, 降低了FCM对类初始中心点的依赖; 然后利用FCM聚类算法的优势对第一层中产生的类的中心点进行聚类, 从而大大减少了聚类的时间复杂度; 最后通过平行坐标技术可视化展示聚类前后的日志数据集, 方便对日志数据进行分析.
2. Key Laboratory of Trustworthy Distributed Computing and Service (BUPT), Ministry of Education, Beijing University of Posts and Telecommunications, Beijing 100876, China;
3. Beijing Government Computer Emergency Response Center, Beijing 100101, China;
4. School of Software, Beijing University of Posts and Telecommunications, Beijing 100876, China
A double clustering model to make web log data sets clustering was proposed based on the self-organizing map (SOM) neural networks and the fuzzy c-means (FCM) method. The first tier uses unsupervised clustering method—SOM neural network, so the number of classes it generates significantly reduces compared with the original data set, it also reduces the FCM method's rely on class initial centers. Using the FCM clustering algorithm to cluster the center points of classes generated by the first layer, the time complexity of clustering is greatly reduced. Meanwhile, the parallel coordinates visualization technology to demonstrate the log dataset was used, it is suitable to analyze the log data.
由于日志数据量巨大,研究如何有效的获取日志信息并对其进行分类分析变得越来越重要. Web日志聚类就是对Web日志中的用户访问模式进行分组,把具有相同或相似浏览行为的模式聚为一类.由于Web数据的特殊性,应用传统的聚类算法聚类效果并不佳.由于Web数据本身的不确定性,在聚类过程中,软计算技术及不确定理论常常被用来处理这些不确定信息.还有一些研究者认为类与类之间的边界是不清晰的,他们将类表示成一个边界不确定的粗糙集,使用粗糙的方法进行聚类[1-2].
然而Web日志数据量非常庞大,计算时间复杂度也是聚类算法需考虑的一个重要因素,因此笔者提出了一种基于自组织特征映射(SOM, self-organizing map)神经网络和模糊c-均值(FCM, fuzzy c-means)的双层聚类模型对Web日志中的用户访问模式进行聚类.
1 双层聚类模型1.1 第1层——SOM神经网络自组织特征映射是由Kohonen提出的对神经网络的数值模拟算法[3]. SOM能根据样本出现在输入空间的概率分布密度自组织地形成与这个概率分布密度相对应的神经元空间分布密度关系,是一种自组织和自学习的方法. SOM神经网络包括输入层和输出层(竞争层),如图 1所示.输入层神经元与输出层神经元为全互连方式,且输出层中的神经元按二维形式排列,它们中的每个神经元代表了一种输入样本.

|
图 1 SOM神经网络 |
SOM神经网络算法是基于竞争学习的自组织映射算法,使用迭代算法优化目标函数来获取对数据集的无监督聚类.设输入层有n个神经元,即输入层样本数据的维数为n;输出层有m个神经元,则输出层数据的维数为m.输入层和输出层的权值连接数目为n×m个.其中,输入层的输入样本数据用X=[x1(t), x2(t), …, xn(t)]表示,xi(t)为t时刻样本数据的第i维分量;输出层用Y=[y1(t), y2(t), …, ym(t)]表示.当输入层输入样本数据后,输出层上的神经元开始竞争,输入数据通过计算欧氏距离来判断,欧氏距离最小的神经元胜出,并修改胜出神经元与其他神经元的权值.权值用Wij(t)(i=1, 2, …, n,j=1, 2, …, m)表示,代表t时刻输入节点i与输出节点j之间的权值. SOM神经网络算法的步骤如下.
步骤1 初始化.初始化t=0,Wij(0) 为一个随机数.
步骤2 从输入样本数据中选择一个样本,用X=[x1(t), x2(t), …, xn(t)]表示,xi(t)为t时刻样本数据的第i维分量,计算输入样本与输出层神经元的欧氏距离dj:
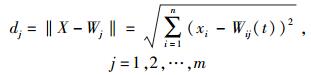
|
(1) |
步骤3 确定输出层胜出神经元.即选择出权值Wj与输入样本数据X最匹配的输出层神经元,设为c,其权值为Wc:
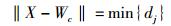
|
(2) |
步骤4 调整权值系数.
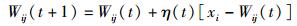
|
(3) |
其中η(t)为学习率.
步骤5 当达到最大迭代次数或目标误差时,输出结果;否则循环步骤2,直到输出结果.
1.2 第2层——FCM算法FCM聚类是用隶属度确定每个数据点属于某个聚类的程度的一种聚类算法[4]. 1973年,Bezdek提出了该算法,作为早期K-means聚类方法的一种改进.
FCM把n个向量分量xi(i=1, 2, …, n)分为c个模糊组,并求每组的聚类中心,使得非相似性指标的价值函数达到最小. FCM与K-means聚类的主要区别在于FCM用模糊划分,使得每个给定数据点用值在[0, 1]间的隶属度来确定其属于各个组的程度.与引入模糊划分相适应,隶属矩阵U允许有取值在[0, 1]间的元素.不过,加上归一化规定,一个数据集的隶属度的和总等于1,即
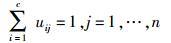
|
(4) |
那么,FCM的价值函数(或目标函数)为
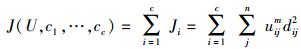
|
(5) |
其中:uij介于[0, 1]间,ci为模糊组Ⅰ的聚类中心,dij=|ci-xj|为第i个聚类中心与第j个数据点间的欧氏距离,m∈[1, ∞)是一个加权指数.
构造如式(6) 新的目标函数,可求得使式(5) 达到最小值的必要条件.
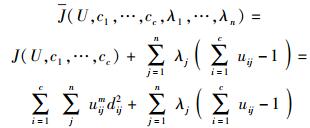
|
(6) |
其中λj(j=1, 2, …, n)为式(4) 的n个约束式的拉格朗日乘子.对所有输入参量求导,使式(5) 达到最小的必要条件为
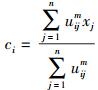
|
(7) |
和
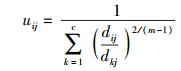
|
(8) |
由上述2个必要条件可知,FCM聚类算法是一个简单的迭代过程.在批处理方式运行时,FCM用下列步骤确定聚类中心ci和隶属矩阵U[1].
步骤1 用值在[0, 1]间的随机数初始化隶属矩阵U,使其满足式(4) 中的约束条件.
步骤2 用式(7) 计算c个聚类中心ci(i=1, 2, …, c).
步骤3 根据式(5) 计算价值函数.如果它小于某个确定的阈值,或它相对上次价值函数值的改变量小于某个阈值,则算法停止.
步骤4 用式(8) 计算新的U矩阵,返回步骤2.
1.3 算法分析FCM算法具有简单、容易理解、计算方便以及能够有效处理大型数据库的优点,但是缺点在于对初始种子点的依赖性特别强,容易陷入局部最优,依赖经验判断最优类的个数以及对“噪声”和孤立点数据比较敏感,这些缺陷大大限制了它的应用范围和效果.和FCM相比,SOM能将数据从高维空间映射到低维空间上,通过降维寻找多维数据的主要统计特征,并根据数据间的相似性自动将数据分成不同的类别,降低噪声的影响.两者相比,SOM网络不能提供分类后精确的聚类信息,而FCM在已知聚类数目和中心点的情况下有着较高的精确性.
在第1层的SOM神经网络聚类过程中,将N条Web日志数据记录聚类划分为n类,因此整个第1层的聚类时间复杂度为O(nN),n≪N.在第2层的聚类过程中,再将已经聚类过后的n类划分为最终的c类,所需的时间复杂度为O(cn2),c≪n.而单独使用FCM聚类方法所需的时间复杂度为O(cN2),由于n≪N,它要远大于双层的聚类方法的时间复杂度.
因此使用这种双层的聚类算法对于具有大量网络信息的数据而言能较好地保证聚类的效果.
2 实验过程与结果分析2.1 实验环境构建日志分析系统包括日志处理、日志检索和聚类分析三部分.日志分析系统的物理拓扑图中,主要由两种类型的节点,一种为管理节点,一种为数据节点.管理节点上同时部署了元数据管理服务,加载机的功能,查询机、检索机的功能,日志模块相应的部署在管理节点上;数据节点负责存放真实数据,以及提供并行计算能力、分析能力.
日志预处理模块负责将监控网站的日志文件进行提取和分析,存入到数据节点上;日志检索和聚类分析模块负责对数据节点的数据字段进行检索和聚类分析,形成报表.
由日志预处理模块分析入库的日志内容表格式如表 1所示.
|
|
表 1 日志内容格式表 |

从日志分析系统中日志预处理模块提取某一天的Web日志数据9万余条,从中选择IP地址、访问时间、请求方式、状态码和流量5个属性,首先对Web日志数据进行用户识别、会话识别和事务识别等,然后再对日志数据进行清洗.经过清洗后的用户访问模式为92 035条记录,假定把它们聚成4类,根据以上算法可得聚类结果如表 2所示.
|
|
表 2 聚类结果表 |

使用Davies-Bouldin指标(DBI, Davies-Bouldin index)来衡量聚类的效果[4]:
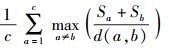
|
(9) |
其中:Sa为第a类的类内模式距离和,即表示第a类中数据点的分散程度,计算方法为式(10);d(a, b)为第a类与第b类的类间距,计算方法为式(11).
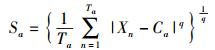
|
(10) |
其中:Ta为第a类的个数;Xn为第a类中第n个数据点;Ca为第a类的中心;q取1表示各点到中心距离的均值,q取2表示各点到中心距离的标准差.
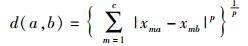
|
(11) |
其中xma为第a类的中心点的第m个属性的值.
聚类个数的不同可以导致不同的DBI值,DBI值越小,分类效果越好.
使用相同数据分别用FCM方法,SOM算法以及双层聚类算法进行聚类后计算DBI值,聚类结果为4类时的比较结果如表 3所示.
|
|
表 3 聚类结果比较 |

由表 3可看出,双层聚类模型的聚类效果更佳,同时测试日志数据加大为70万条后,随着数据量的增加、用户浏览行为的多样性,双层聚类方法的聚类效果变化不大,而FCM方法和SOM神经网络聚类法的聚类效果在下降.因而对于大量的Web日志数据处理来说,双层聚类模型可以保障快速准确地聚类.
3 可视化分析平行坐标技术[5],用于表示多维信息或数据,将多维信息映射到一组平行的等距离坐标轴上.将处理过的日志数据采用平行坐标技术可视化,对比图 2和图 3所示.

|
图 2 原始数据的可视化 |

|
图 3 双层聚类后可视化 |
加入了交互操作——刷,为方便分析聚类结果.刷是一种突显数据子集的可视化交互技术.在相邻的平行坐标轴的折线中根据特定的趋势或属性选择或设置一个焦点突显一部分折线而使其他折线不明显,可更清晰地了解局部数据的变化规律,以及更直观地观察感兴趣的数据,如图 4所示.

|
图 4 可视化交互 |
Web用户访问模式的聚类由于其海量的数据以及很多不确定因素的存在使之成为一个极具挑战的工作. 笔者提出了基于SOM神经网络与FCM相结合的方法对用户的访问模式进行聚类. 这种双层的聚类方法结合了2种算法的优点,SOM网络首先找出日志数据集类别数目和各中心点,作为FCM的初始输入,可快速有效地对Web日志中的用户访问模式进行聚类,并根据聚类结果进行可视化,采用平行坐标技术将聚类前后的日志数据展示对比,交互式选取重要信息进行查看,方便进行分析.
| [1] | Lingras P, West C. Interval set clustering of web users with rough k-means[J].Journal of Intelligent Information Systems, 2004, 23(1): 5–16. doi: 10.1023/B:JIIS.0000029668.88665.1a |
| [2] | De S, Krishna P. Clustering web transactions using rough approximation[J].Fuzzy Sets and Systems, 2004, 148(1): 131–138. doi: 10.1016/j.fss.2004.03.010 |
| [3] | Kohonen T. Self-organizing maps[M]. 2nd ed. Berlin: Springer-Verlag, 1997. |
| [4] | Bezdek J, Pal N. Some new indexes for cluster validity[J].IEEE Transactions on Systems, Manand Cybernetics: Part B, 1998, 28(3): 301–315. doi: 10.1109/3477.678624 |
| [5] | Inselberg A, Dimsdale B. Parallel coordinates: a tool for visualizing multi-dimensional geometry[C]//The 1st IEEE Conf on Visualization. San Francisco: IEEE, 1990: 361-378. |