


2. 南京大学 工程管理学院, 南京 210093;
3. 浙江省信息化与经济社会发展研究中心, 杭州 310018
提出了基于语义和语法的服务检索方法. 采用语义相似度的方法对服务进行管理,以达到提高检索效率的目的;采用语法结构的方式,利用命题库模式对服务建模并提出检索算法,以提高服务检索的精确率. 以响应时间、召回率、精确率、综合评价指标为衡量指标,通过实验说明了结合语义和语法的检索方法的有效性.
2. School of Management and Engineering, Nanjing University, Nanjing 210093, China;
3. The Research Center of Information Technology & Economic and Social Development, Hangzhou 310018, China
A web service retrieval method based on semantic and syntactic was provided. Firstly, semantic similarity was employed to establish relationship among web services to raise retrieval efficiency; then, the retrieval precision was developed, this article applied propbank to model web service description and presented a clever retrieval algorithm. Experiments show that the new method offers higher efficiency and precision.
近年来,Web服务因其自描述、可重用、平台无关等特点,受到了很多学者及研究机构的关注. 面向服务的体系架构(SOA,service-oriented architecture),其实现模式是服务提供者与服务请求者之间通过服务注册中心建立连接. 服务请求者通过注册中心的目录获悉服务的基本信息并查找所需的服务,通用描述、发现与集成(UDDI,universal description,discovery and integration)为服务注册、发现等提供技术规范. 笔者主要针对在服务库中建立索引并发现满足功能需求的服务,提出了一种服务检索方法以提高检索的精确率与效率.
对服务检索的研究,将信息检索的方法作为基础,学者们做了许多的工作[1, 2, 3, 4].
以服务描述语言(WSDL,web service description language)作为检索对象,其包含的元素有名称、操作、输入、输出、文本描述等. 提出的检索方法有:基于关键字的检索,关键字与服务名称匹配,其最大的缺陷是检索精确率极低,究其原因是无法捕捉语义;基于概念的检索[2],是建立服务的概念本体,对被检索内容语义标注,与基于关键字相比提高了检索精确率,但建立本体的工作量过大,且本体建立的准确与否直接影响检索结果[3],抽取概念的模糊语义构建动态库以查找服务,语义库的规模、复杂度直接影响匹配结果;基于结构、过程模型的检索[4],根据WSDL的结构建立过程模型,优势是可挖掘到存在于过程模型中的语义,不足之处是在发布服务时对提供者增加了负担;基于逻辑、推理的检索,需要有后台规则库的支持,规则库的建立需要人工完成[5],在建立的本体基础上推理以实现检索需求的匹配,提高精确率的同时也降低了效率.
如上所述的检索的各种缺陷可分为两类:检索效率不高;检索精确率不高. 为了满足用户的功能需求并提高检索精确率与效率,从语法、语义两方面对服务管理、检索语句、服务存储予以关注. 将服务检索过程划分为2个阶段:建立合理的服务管理模型;设计高效的检索算法[6]. 提出了相应的解决办法:1) 根据服务间的语义相似性在同一服务类别中建立服务间的关联,以减少检索的步长;2) 建立新型的服务存储方式,设计检索算法以提高检索精确率.
1 基于语义相似的服务管理UDDI定义了服务的统一注册机制,但其内部的服务管理定义却不明确,由此造成了服务检索的难度,每次检索需遍历整个服务库,检索效率并不高. 针对这一问题,提出了服务管理方法,在语义相近的服务之间建立连接.
为了减少检索的路径,对同一分类类别的服务,计算服务之间的距离以在服务间建立联系,通过优先检索与目标服务距离较近的服务以提高检索效率. 服务描述的主要部分,操作op=〈opn,in,out〉,包含操作的名称、输入、输出. 服务之间的距离通过操作间的相似度计算.
在计算服务操作间的相似度时,分析操作表述中包含的词语的重要性及词语的语义表达,分别采用tf-idf算法和基于WordNet的语义相似度LIN算法衡量. 操作名称之间的相似度如下式,Simti,Simwd分别表示根据tf-idf与WordNet计算得到的相似度.
Sim(opni,opnj)=ε1Simti+ε2Simwd ,
ε1+ε2=1 ,0<ε1,ε2<1
1) 运用tf-idf算法计算两个服务的操作名称之间的相似度. 将2个服务的操作名称看作是2个执行预处理工作后的文档.
${w_{ij}} = {\rm{tf}} - {\rm{id}}{{\rm{f}}_{ij}} = {\rm{tf}} - {\rm{rd}}{{\rm{f}}_{ij}}{\rm{ = }}\frac{{{n_{ij}}}}{{\sum\limits_k {{n_{kj}}} }}\ln \frac{{\left| D \right|}}{{N\left( {{t_i},D} \right)}}$
其中wij为词语i在文档j中的重要程度. 因此,2个文档转换为2个向量表示. 它们间的相似度为两向量的乘积:
$S{\rm{i}}{{\rm{m}}_{{\rm{ti}}}}\left( {{\rm{op}}{{\rm{n}}_i},{\rm{op}}{{\rm{n}}_j}} \right) = \sum\limits_{k = 1}^t {{w_{ki}}{w_{kj}}} $
2) LIN算法,是由Resnik算法演变而来,并发展成基于WordNet的算法,现已成为被广泛接受与使用的语义相似度计算方法. LIN的算法模型为
$S{\rm{i}}{{\rm{m}}_{L{\rm{in}}}}\left( {{c_1},{c_2}} \right) = \frac{{2 \times IC\left( {{\rm{lcs}}\left( {{c_1},{c_2}} \right)} \right)}}{{IC\left( {{c_1}} \right) + IC\left( {{c_2}} \right)}}$
其中:lcs(c1,c2)表示概念c1与c2的最近公共父节点,IC为概念所包含的信息内容,基于WordNet的思想为结点越多的概念所包含的信息量越少,而叶子结点包含的信息量最大,其计算为
${\rm{IC}}\left( c \right) = - \lg p\left( c \right) = 1 - \frac{{\lg \left( {{\rm{hypo}}\left( c \right) + 1} \right)}}{{\lg \left( N \right)}}$
其中:hypo(c)表示概念c的所有子节点数,N表示概念c的总数.
3) ε1、ε2分别为2种计算方法的权重,可根据经验给出.
4) 同时,这2种计算方法还满足如下性质:
Simti关于操作名称满足对称性:Simti(opni,opnj)=Simti(opnj,opni);Simwd是基于WordNet计算得出的相似度,满足对称性:Simwd(opni,opnj)=Simwd(opnj,opni).
可得出结论:Sim(opni,opnj)=Sim(opnj,opni). Sim(ini,inj),Sim(outi,outj)与名称间的相似度计算类似.
由上述方法得到的服务管理索引,如图 1所示.
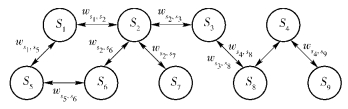
|
图1 基于操作相似的服务间关系模型 |
用三元组表示Rk(Si,Sj,w
在计算操作间的相似度之前,还有一些预处理工作:包括删除停用词、分割组合词、词形还原等.
算法1 服务检索的过程,对于w
服务库检索(查询语句,T)
Input: T={Rk(Si,Sj,w
Output:检索后返回的服务
n←T包含的连接数;
m←服务数量;
for i from 0 to m
Res ←∅;
if Matching (Query,Documentation of Si)//
算法2
Res←Res∪Si
if Si$\subset $T continue;
Endfor
for k from 0 to n
While (w
if Matching (Query,Documentation of Sj)
//算法2
Res←Res∪Sj;
Endfor
return Res;
第一个for循环为根据算法2查找匹配的服务,找到即终止循环. 最坏的情况是遍历完所有的服务,其算法时间复杂度为O((m+n)max1max2),O(max1max2)是算法2的时间复杂度. 由于m≥n,所以算法1的时间复杂度≤O(mmax1max2). 从第1条记录到最后一条记录逐条遍历,每次查找服务的时间复杂度为O(mmax1max2). 显然,此方法的检索效率要高.
2 基于命题库的服务存储与检索建立了服务管理的索引后,设计服务的存储及检索算法是本部分的关注重点. 服务描述元素〈documentation〉作为检索的匹配对象,明确此服务可以做什么,以搜索满足查询条件的服务. 实现服务检索,首先对〈documentation〉建立模型. 由于它的内容是一段文本,所以对服务的检索就转换为以文本为对象的检索. 对此文本建立基于命题库的语法结构模型. 其次是查询语句与已建立的存储模型间的匹配算法设计. 通过语义和已建立语法结构的服务匹配,检索结果不仅是与查询语句的语义相同,而且与查询语句的语法结构也相同的服务.
2.1 基于命题库的服务描述建模命题库(PropBank) 是在宾州树库之上,增加了语义信息,主要内容是:词性的标注;使用括号与标签集为语法标注;谓词-论元结构标注等. 根据命题库中语法结构的定义对服务的〈documentation〉建立语法结构模型,使机器以更好地理解描述内容. 如下为一个服务实例,来源于xmethods.com.
Service Name: Countries web service
Documentation: Mobilefish.com is pleased to announce a program that allows you to access the countries and regions information from our server and include it on your website.
它的语法结构为:(ROOT (S (NP (NN Mobilefish.com)) (VP (VBZ is) (VP (VBN pleased) (S (VP (TO to) (VP (VB announce) (NP (NP (DT a) (NN program)) (SBAR (WHNP (WDT that)) (S (VP (VBZ allows) (S (NP (PRP you)) (VP (TO to) (VP (VP (VB access) (NP (DT the) (ADJP (NNS countries) (CC and) (NNS regions)) (NN information)) (PP (IN from) (NP (PRP$ our) (NN server)))) (CC and) (VP (VB include) (NP (PRP it)) (PP (IN on) (NP (PRP$ your) (NN website))))))))))))))))))
将其以树形结构存储于数据库中. 每个结点存储为1条记录,包含3个元组Si(ID,Content,ParentID),分别为ID,结点的内容及其父亲结点的ID、NP、VP等词性暂不作考虑. ID的最大值即为这棵树的叶子结点数,反映树的规模.
将属于同一类别的服务存储于一张表中以便于检索,即一张表中包含多棵树,其结构采用五元组表示S(treeID,treeName,ID,Content,ParentID),后三个元组与树的存储结点描述相同,treeID与treeName分别指树的ID与名称,用于标记一棵树,treeID的最大值即为服务库中这一类别的服务数量.
执行服务检索算法前,对查询语句的定义也由语法结构描述,存储模式为Q(ID,Content,ParentID),其元组的含义与服务的表述相同.
2.2 服务检索算法服务检索算法的核心思想是:查询语句的词语(或语义相似的词语)包含于服务的描述中;查询语句中词之间的语法结构与服务描述的语法结构(即树形逻辑结构)匹配,满足以上2个条件则作为服务检索的返回结果,否则继续检索下一个服务.
输入为查询语句的树形表达与服务描述的树形表达,输出为检索的返回结果. 遍历检索语句中的每个结点,如果此结点与服务的树形结构中某结点匹配,并检查此结点的父结点ID是否已包含于rec,是则将此结点的ID也存储于rec,…,继续遍历查询语句的结点,遍历结束并符合条件时则返回true,表示此服务符合检索条件. 此算法的时间复杂度为:O(max1max2). 在执行服务检索算法之前,还有一些预处理工作,如删除空元素、删除停用词等.
服务的检索算法如下所示.
算法2 Matching (查询语句,Documentation of Si)
Input: 查询语句Q(ID,Content,ParentID);
documentation tree Si(ID,Content,ParentID);
Output:返回true 或 false,表示Si是否与查询语句匹配
max1 ←Q的长度;
max2 ← Si的长度;
for Q.ID from 0 to max1
if ParentID==∅
rec ←ID;
root ←Content;
for Si.ID from 0 to max2
if SimMatch(Q.Content,Si.Content)
while (Q.ParentID$ \subseteq $rec)
rec ←Q.ID;
root ←Q.Content;
Endfor
Endfor
if rec$\supseteq $max1
return true;
else
return false;
3 实验 3.1 测量指标信息检索中的2个衡量指标为:召回率R与精确率P.
P=检索出的相关服务数/所有被检索到的服务数的百分比;R=检索出的相关服务数/服务库中所有相关服务数的百分比. 综合评价指标F1兼顾R与P两者,其值越接近1,表示检索结果越理想.
$F1 = \frac{{2PR}}{{P + R}}100\% $
responseTime为检索并返回结果花费的时间.
3.2 实验步骤与数据从网站XMethods及WEbservicex.net下载了149个、67个WSDL文件,共216个服务作为真实数据源并合成部分数据,共1 000个WSDL文件. 实验环境为CPUCore Duo T2250,主频1.73 Hz,内存2 G,操作系统Windows XP的PC机上,数据库为Microsoft Access 2010,开发工具为eclipse-SDK-3.6.1. 实验结果,图 2为服务检索的响应时间,横坐标为服务数量,两条线分别为未进行服务管理与进行语义相似度管理的检索时间. 图 3分别表示在3个不同的查询语句下衡量指标P、R与F1的值.

|
图2 服务检索的响应时间/ms |

|
图3 服务检索的 P、R、F1 值 |
由图 2所示,未进行服务管理的部分,随着被检索服务数量的增加响应时间呈递增趋势,而提出的基于相似度的方法,响应时间只在小范围内波动,并未由于检索资源的增加而呈现明显的变化,说明提出的方法有助于提高服务的检索效率.
基于第1节所述得出检索精确率排序为:逻辑>结构>概念>关键字,检索效率为:关键字>概念>结构>逻辑. 基于逻辑的检索虽然精确率高但其效率也最低下,对于用户来说等待的时间是最难以忍受的,因此排除基于逻辑的检索. 对于服务检索算法的分析,分别从P、R、F1进行衡量,将提出的方法与文献[7]中基于关键字、文献[2]中基于概念、文献[4]中基于结构的检索方法进行比较. 可得出基于提出的方法,P、R、F1都有不同程度的提高,如图 3所示.
语句Q1的检索关键字为“IP”和“location”,它们之间的语法结构为:…(IP,location (…)),通过IP地址找到PC的登录地点所在国家或地区;Q2的关键字为“send”和“text”,其结构:send(…,text(…)),发送短信的服务;Q3的检索关键字为“pay” “inform”和“online”,结构为:pay(…,…(inform(…,…))) and“online”,支持在线支付的服务,付款后,通知用户支付行为.
Q1中通过IP找到所在位置的查询,与Q2和Q3相比,其在衡量指标上提高的幅度较小,原因在于IP与location间并没有如Q3般多层次的谓词逻辑关系. Q2与Q1相比,其增长程度要明显得多,在于send与text之间的谓词关系. 最能体现提出方法有效性的是Q3,因为只用关键字检索,机器完全无法理解其内在的含义. 以及Q3包含的双层谓词逻辑表达,应用提出的检索模式,能消除部分歧义的影响(歧义指与查询词只是语义上匹配,但词之间的结构不同,查询目的也不同的服务作为检索结果的情况),说明如下.
Q3以树形结构存储,inform的深度要大于pay.
服务1: Documentation: update my credit card information during initial purchase of my current license with the Auto-Renewal Service for Kaspersky Internet Security 2013. 语法逻辑为:…(…,information(purchase(…),(Internet))),且Sim(purchase,pay)=0.612 5. 但purchase的深度要大于information.根据本文的方法,此服务不会作为查询的返回结果. 事实上,此服务的功能为更新信用卡信息.
服务2: Documentation: A convenience fee charge of $ 4.00 per transaction will be informed you when you use this online service. 语法逻辑为:…(…transaction,… (informed(…))),…(…,online),且Sim(transaction,payment)=0.702 8. informed的深度要大于transaction,符合Q3的需求,因此作为返回结果. 事实上,此服务的功能为在线支付.
Q2基于概念的精确率会如此之低,是由于它包含了与text同属一个概念的所有词语,如“topic”等,而用户期望的是表达短信语义的词语检索结果,因此基于概念的检索精确率反而低于基于关键字的检索. 基于结构的检索,它的查询结构是属性name包含“IP”且documentation包含“IP”和“location”,因此其检索精确率高于基于关键字和概念的检索,但用户需学习这种查询语言增加了用户的负担. 提出的方法,检索语句的解析是可以自动完成的.
4 结束语为了满足服务检索的需求,提出了一种基于语法与语义的服务检索方法. 对同类别的服务之间建立语义连接以减少服务的搜索空间;基于语法结构的检索模式能避免那些语义匹配但语法结构不匹配的服务作为检索结果,通过实验说明服务检索的效率与精确率都有所提高. 对于下一步的工作,考虑到对检索结果的选择问题,将最能符合用户需求的服务推送到首位,以供用户选择.
| [1] | Sangers J, Frasincar F, Hogenboom F, et al. Semantic web service discovery using natural language processing techniques[J]. Expert Systems with Applications, 2013, 40(11): 4660-4671.[引用本文:1] |
| [2] | Egozi O, Markovitch S, Gabrilovich E. Concept-based information retrieval using explicit semantic analysis [J]. ACM Transactions on Information Systems, 2011, 29(2): 1-38.[引用本文:3] |
| [3] | 李沛杰, 张兴明, 沈剑良. 基于动态信任语义库的 Web 服务匹配算法[J]. 计算机工程与设计, 2015, 36(3): 652-657. Li Peijie, Zhang Xingming, Shen Jianliang. Web service matching algorithm based on dynamic trust-based semantic library [J]. Computer Engineering and Design, 2015, 36(3): 652-657.[引用本文:2] |
| [4] | Klein M, Bernstein A. Toward high precision service retrieval [J]. IEEE Internet Computing, 2004, 8(1): 30-36.[引用本文:3] |
| [5] | Narock T, Yoon V, March S. A provenance-based approach to semantic web service description and discovery [J]. Decision Support Systems, 2014, 64(3): 90-99.[引用本文:1] |
| [6] | Atkinson C, Bostan P, Hummel O, et al. A practical approach to web service discovery and retrieval[C]//IEEE International Conference on Web services, Piscataway, NJ: IEEE, 2007: 241-248.[引用本文:1] |
| [7] | Magnini B. Use of a lexical knowledge base for information access systems[J]. Terminology, 1998, 5(2): 203-228.[引用本文:1] |