


2. 北京信息科技大学 网络文化与数字传播北京市重点实验室, 北京 100101
为了有效改善位置社交网络的用户体验,提出了一种个性化位置推荐服务模型.综合考虑了用户的签到行为特点、用户特征及位置兴趣点的语义特征,并将蚁群算法与改进的混合协同过滤算法有效结合起来进行个性化位置推荐,以此提高个性化位置推荐的质量和效率.实验结果表明,提出的位置推荐模型的召回率、准确率和平均绝对误差值都明显优于已有方法.
2. Beijing Key Laboratory of Internet Culture and Digital Dissemination Research, Beijing 100101, China
In order to effectively improve the users' experience for location social networks, a model of personalized location recommendation service was proposed. Considering the users' check-in behavior features, the users' characteristics and semantic features of interested location point, this model combines the ant colony algorithm with the improved hybrid collaborative filtering algorithm to improve the quality and efficiency of the individual location recommendation. Experiments show that, the recall, accuracy and average absolute error value of the location recommendation model proposed in this article is superior to the existing methods.
在位置社交网络(LBSN,location-based social network)中,用户不仅可以与自己的朋友分享博客、照片、视频等,而且还可以随时随地分享自己的位置信息,发表对某一位置点的评论,从而为其他用户提供相应的建议.近年来,位置社交网络得到了快速发展.国外的Foursquare已经拥有大量的用户,国内的陌陌、街旁虽在起步阶段,但发展势头很猛.
位置推荐服务就是把一些位置兴趣点(LPOI,location point of interest)推荐给最有可能去这些地方的用户.但是目前需要用户主动提出查询请求,而且平台返回的结果对任何用户都是一样的,不能提供个性化推荐服务,即不能为目标用户推荐符合其个人偏好的潜在位置兴趣点.
1 相关工作Zhang等[1]通过用户与位置兴趣点之间的联系建立转移概率模型,为用户预测下一个位置兴趣点.Sattari等[2]和Xie等[3]都是利用用户访问位置兴趣点所处的上下文信息进行位置推荐.Li等[4]通过矩阵分解的方法降低数据维度,但是算法复杂度较高.Hu等[5]通过上下文信息挖掘用户的位置分享隐私偏好,减轻了泄露用户隐私的风险,还能预测用户的分享行为.Wang等[6]将信任度引入到推荐模型,为用户推荐他们所期望或信任的服务.Yuan等[7]主要是建立位置兴趣点的主题分布,根据位置所属的主题分布进行位置预测.Noulas等[8]综合考虑了用户的签到历史记录和用户相似度等相关因素,改善了推荐性能.Ying等[9]将时间因素应用到位置推荐中,其时间单位是小时,但没有考虑其他时间单位,如日、星期、月、年等,同时也没有考虑其他影响位置兴趣点推荐的因素.Berjani等[10]根据用户的移动特性预测用户的下一个位置兴趣点,并综合利用线性回归和M5模型树建立预测模型,提高了预测精度.Berjani等[10]提出基于回归树的预测方法为用户进行位置兴趣点推荐,但只关注用户的签到记录.Liu等[11]直接根据“用户-地点”矩阵来进行偏好研究.
综上所述,现有的方法在进行位置聚类时只是单纯的使用位置兴趣点的距离特征,并未考虑到位置兴趣点的语义特征,这样容易将一些相距不是最近,但语义很接近的位置兴趣点分开,无法找到同义位置兴趣点,从而影响推荐效果.
为此,在进行位置兴趣点聚类时,需要综合考虑位置兴趣点的距离特征和语义特征,解决无法找到同义位置兴趣点的问题,以此提高聚类效果.
通过对传统的协同过滤算法进行改进,采用基于用户协同过滤与基于项目协同过滤相结合的混合协同过滤算法进行个性化位置推荐,以此改善推荐质量;在预测未评分位置兴趣点时,还引入了时间遗忘函数,以此表示时间因素对用户兴趣变化的影响,这样就突出了用户最新兴趣的权重,降低了先前兴趣的权重,从而实现了更加准确的推荐.
2 位置推荐模型 2.1 位置兴趣点聚类在位置社交网络中,用户会在自己感兴趣的地方进行签到,每一个用户签到的地理位置都可称为LPOI[14].LPOI中包含位置的唯一标识号、经纬度和名称,即LPOI=(LcationID,Latitude,Longitude,Name).如果只是简单的通过判断用户是否访问同一个LPOI来计算用户之间的行为相似度,不仅准确率会下降,而且缺乏广泛性,无法将位置与位置之间的联系、人与位置之间的联系体现出来,会造成以偏概全的效果.因此,笔者将具有一定相似度的位置兴趣点聚类为位置兴趣区域(RPIP,regional points of interest position),然后再根据用户访问各个位置兴趣区域的相似度来度量用户之间的相似度.这样不仅可以解决上述问题,而且也可以解决新位置得不到用户关注的问题.
2.1.1 位置兴趣点相似度由于位置社交网络主要反映的是位置信息,因而现有的LPOI聚类方法也普遍聚焦于位置信息,而忽略了LPOI本身的语义信息.语义信息和LPOI是完全不同的2类信息,如何将两者融合是一个难题.只是简单地按LPOI的距离远近进行聚类,并不能很好地反映LPOI之间的语义相关性.因此,LPOI聚类算法不仅要考虑LPOI的距离特征,还要考虑LPOI的语义特征.LPOI的相似度由LPOI的距离特征相似度与LPOI的语义特征相似度加权求和计算得到,见式(1).LPOI的距离特征相似度用LPOI间的实际距离的倒数表示为
| ${\text{Si}}{{\text{m}}_l}\left( {i,j} \right) = a{\text{Si}}{{\text{m}}_d}\left( {i,j} \right) + \left( {1 - a} \right){\text{Si}}{{\text{m}}_c}\left( {i,j} \right)$ | (1) |
| ${\text{Si}}{{\text{m}}_d}\left( {i,j} \right) = \frac{1}{{1 + d{{\left( {i,j} \right)}^\theta }}}$ | (2) |
由于LPOI的分类清晰,能从全局上明确表示LPOI的语义特征.因此可以利用位置兴趣点之间的类别相似度度量LPOI的语义特征相似度.具体方法是将所有LPOI按其类别建立成一棵倒立的LPOI类别树,每2个节点连成的边是具有权值的,用类别树中节点之间的距离表示类别的相似度,其计算方法为
| ${\text{Si}}{{\text{m}}_c}\left( {i,j} \right) = 1/\left( {1 + {d_c}} \right)$ | (3) |
位置兴趣点聚类算法采用蚁群觅食聚类算法,把待处理的位置兴趣点看成含有不同属性的蚂蚁个体,“食物源”则是蚂蚁要寻找的聚类中心,那么蚂蚁搜寻“食物源”的过程就可以认为是数据聚类的过程[12].
LPOI聚类算法如下:
1) 将所有位置兴趣点视为整个蚁群,首先对蚁群进行初始化.选取相距最远且均处于高密度区域的M个位置兴趣点.其中:位置兴趣点集合L={L1,L2,…,Ln},聚类中心集合C={ C1,C2,…,CM};
2) 取不同于Cj且未被标识过的Li,计算Li归为Cj的概率为
| ${P_{ij}} = \frac{{\tau _{ij}^\alpha }}{{\sum\limits_{s \in {S_j}} {\tau _{sj}^\alpha } }} = \frac{{Sim_l^\alpha \left( {i,j} \right)}}{{\sum\limits_{s \in {S_j}} {Sim_l^\alpha \left( {i,j} \right)} }}$ | (4) |
3) 重新计算Cj类的聚类中心(Cj采用类中最优的聚类中心,即聚类中心到类内各个点的距离最小值);
4) 计算每个类内数据对象之间的相异度数值εj,其计算方法为
| ${\varepsilon _j} = \sum\limits_{k \in {S_j}} {\frac{1}{{{\tau _{ij}}}}} $ | (5) |
5) 如果所有类的相异度之和εj小于ε0时,聚类完成;如果相异度数值εj不小于ε0时,返回步骤2),重新迭代.
2.2 用户相似度计算在传统的协同过滤算法中,用户相似度计算只考虑用户的行为相似度,但并没有考虑用户的特征相似度.因此,传统协同过滤算法在用户签到记录很稀疏的情况下,很难准确找到用户的最近邻集合,从而影响推荐效果.基于上述原因,在计算用户相似度时引入用户特征相似度,用户相似度为用户行为相似度与用户特征相似度的加权和,表示为
| $Si{m_U}\left( {i,j} \right) = bSi{m_L}\left( {i,j} \right) + \left( {1 - b} \right)Si{m_f}\left( {i,j} \right)$ | (6) |
位置社交网络的签到数据包含签到位置的经纬度,记录了用户访问的关键地点,形成了用户的碎片化行为轨迹,其更能体现用户强烈的目的性.每一个签到位置对于用户来说都有一定的意义,能够表现出用户的兴趣爱好等,因而当用户访问相近或相同的位置时,他们可能有相似或相同的行为目的.因此,可以根据用户之间的位置相似度计算用户的行为相似度.笔者利用改进的余弦相似度计算方法计算用户之间的位置相似度.
用向量Li表示用户在各个RPIP的位置权重向量,其中Li=[wi1,wi2,…,wij],wij表示用户i在位置兴趣区域j的位置权重,其值为用户i在位置兴趣区域j签到次数占其全部签到的比例,即wij=Nij/Ni.将所有用户访问的位置兴趣区域的位置权重构成用户位置权重矩阵为
| $V\left( {m \times n} \right) = \left[ \begin{gathered} {w_{1,1}}{w_{1,2}} \cdots {w_{1,n - 1}}{w_{1,n}} \hfill \\ {w_{2,1}}{w_{2,2}} \cdots {w_{2,n - 1}}{w_{2,n}} \hfill \\ {\text{ }} \vdots {\text{ }} \vdots {\text{ }} \vdots {\text{ }} \vdots \hfill \\ {w_{m,1}}{w_{m,2}} \cdots {w_{m,n - 1}}{w_{m,n}} \hfill \\ \end{gathered} \right]$ | (7) |
把用户在各个位置兴趣区域的位置权重看成n维向量空间上的向量.在计算用户相似度时需要先将用户的n维向量降维,新的维度(用S表示)取2个用户所访问的位置兴趣区域的并集个数.将用户X、用户Y的位置权重向量在S维向量空间中表示为WX、WY,用户之间的相似度为
| ${\text{Si}}{{\text{m}}_L}\left( {X,Y} \right) = \cos \left( {{W_X},{W_Y}} \right)\frac{{{G_{XY}}}}{S}$ | (8) |
| $\cos \left( {{W}_{X}},{{W}_{Y}} \right)=\frac{\sum\limits_{i\in {{L}_{XY}}}{{{w}_{{{X}_{i}}}}{{w}_{{{Y}_{i}}}}}}{\sqrt{\sum\limits_{i\in {{L}_{{{X}_{i}}}}}{w_{_{{{X}_{i}}}}^{2}}}\sqrt{\sum\limits_{i\in {{L}_{{{Y}_{i}}}}}{w_{_{{{Y}_{i}}}}^{2}}}}$ | (9) |
在计算用户相似度时需要将用户的特征考虑在内,以便精确的计算用户之间的相似度.用户的特征包括年龄、性别、职业、经济条件、学历、工作经验等.其相似度为
| ${\text{Si}}{{\text{m}}_f}\left( {i,j} \right) = \frac{{N\left( {{f_{ai}} - {f_{aj}}} \right)}}{{N{\text{Sum}}}}$ | (10) |
基于用户的协同过滤算法[13]虽然具有较高的推荐精度,但是数据的稀疏性和冷启动问题(后面2.4节将做专门介绍)严重影响了该算法的效率;基于项目协同过滤算法[14]在数据稀疏的情况下比前者表现更优,但只是简单地挖掘用户信息,很难向用户推荐新项目,因此采用将2种算法混合的协同过滤算法,以提高算法的推荐精度和推荐效率.首先利用基于用户的算法填充用户位置兴趣区域评分矩阵,从而降低数据的稀疏性,再根据评分大小选出前N个位置兴趣区域,然后利用基于项目的算法预测目标用户在N个位置兴趣区域中未评分位置兴趣点的评分,最后根据评分大小进行排序产生Top-K推荐集.同时,由于传统协同过滤只是考虑项目的评分,并未考虑用户对位置兴趣点的兴趣会随着时间的推移而变化,因此需要引入兴趣变化因素.
2.3.1 数据表示对位置兴趣点采用隐性评分的方法.如果用户在某一位置兴趣点签到,可以说明该用户对此位置兴趣点感兴趣;如果在此位置兴趣点签到次数越多,则表示用户对此位置兴趣点的感兴趣程度越高.因此可以用位置兴趣点的位置权重表示位置兴趣点的隐性评分为
| ${R_{a,i}} = \gamma \frac{{{N_{a,i}}}}{{\sum\limits_{j \in {L_a}} {{N_{a,j}}} }}$ | (11) |
如果只是通过判断用户是否访问同一个LPOI来计算用户之间的相似度,那么所计算得结果是不准确的.同时,随着位置社交网络用户和签到数据的增长,计算单个位置兴趣点相似度的效率会越来越低.因此,可以将相似度较高的位置兴趣点聚为一类,这样进行位置兴趣点最近邻查询时,只要在与目标位置兴趣点相似度较高的聚类组的候选集中查询就可以找到大部分的最近邻居,而不必遍历所有位置兴趣点.
按照2.1节介绍的LPOI聚类算法对位置兴趣点进行聚类,可以得到若干位置兴趣区域.进一步计算用户对各个位置兴趣区域的评分,组成用户-位置兴趣区域的评分矩阵Rm×n,并以此作为协同过滤算法的输入数据.
2.3.2 最近邻集合利用2.2节介绍的相似度计算方法计算与目标用户最为相似的最近邻集合,然后利用基于用户的算法预测目标用户对未评分位置兴趣区域的评分,最后按照评分的大小选出前N个位置兴趣区域,构成邻近位置兴趣区域集合L(此处所获得的位置兴趣区域也包含用户已评分的位置兴趣区域).计算目标用户对未评分位置兴趣区域的评分为
| ${R_{u,j}} = {\bar R_u}\frac{{\sum\limits_{k \in {U_k}} {{\text{Sim}}\left( {{R_{k,j}} - {{\bar R}_u}} \right)} }}{{\sum\limits_{k \in {U_k}} {{\text{Si}}{{\text{m}}_{u,k}}} }}$ | (12) |
在获得邻近位置兴趣区域集合L之后,即可通过基于项目的算法对集合L包含的各个位置兴趣区域中未评分的LPOI进行预测评分.但是,传统的协同过滤算法并未考虑到用户访问某一位置兴趣点的兴趣会随着时间的推移而变化的问题,因此,在算法中引入时间遗忘因子Wu,i,用来度量用户u对于位置兴趣点i的兴趣变化.计算时间遗忘因子为
| ${W_{u,i}} = \frac{1}{{1 + {e^{ - \left( {t - {t_{u,i}}} \right)}}}}$ | (13) |
基于项目的算法对未评分的位置兴趣点进行预测评分为
| ${R_{u,i}} = \frac{{\sum\limits_{n \in {I_i}} {{\text{Si}}{{\text{m}}_i}_{,n}{w_{u,n}}{C_{u,n}}} }}{{\sum\limits_{n \in {I_i}} {{\text{Si}}{{\text{m}}_{i,n}}} }}$ | (14) |
首先通过式(14)对用户未评分的位置兴趣点进行评分,再将其根据分值大小进行排序,然后选取其中的前K项,即产生Top-K推荐集合,最后推送给用户.
2.4 冷启动问题冷启动问题即新用户问题和新项目问题[15],由于新用户或新项目没有任何历史记录(即新用户和新项目的评分矩阵为空),推荐系统无法为新用户和新项目找到相似邻居,也就无法为目标用户推荐相应的项目,从而导致推荐系统的准确率降低.笔者采用项目聚类的方法解决新项目问题,同时利用用户的属性特征相似度和位置兴趣点流行度来解决新用户问题,其过程如下:
步骤1 判断用户是否填写用户信息,如果没有填写则进入步骤2;如果有则进入步骤3;
步骤2 将所有位置兴趣点按流行度(根据签到次数和签到用户数量来计算)排序,从中选取前Q个位置兴趣点,然后在Q个位置兴趣点中按照与用户的距离远近选取K个不同类别的位置兴趣点作为推荐列表推送给新用户,最后进入步骤4;
步骤3 根据用户间的属性相似度找出与新用户最为相似的用户组,将相似用户组中用户签到的对应位置兴趣点推荐给新用户,然后进入步骤4;
步骤4 实时更新位置兴趣点类别组、新用户的历史记录,当历史记录达到一定阈值后,就可以切换为笔者的混合协同过滤算法.
3 实验分析 3.1 实验数据集笔者所用数据集是通过调用新浪微博的位置服务API得到的.其中包含1万多个用户的69万条签到记录,含有15万多个LPOI.
将数据集中用户的签到记录的80%作为训练集,20%作为测试集.训练集用于建立个性化位置推荐模型,测试集用于对个性化位置推荐模型的验证.
3.2 实验过程与实验结果在LPOI聚类算法中,位置兴趣点的距离特征相似度与语义特征相似度之间的比重a以及聚类个数M时需要人为给定,其值的大小会影响推荐模型的推荐效果,因此进行了多组对比实验.实验结果表明,当a取值为0.8和M取值为50 000时,精确度和召回率为最佳.图 1为对应的聚类效果图.
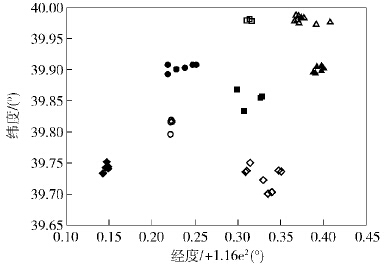
|
图1 M为50 000的聚类效果 |
为了验证笔者模型的正确性和性能,将笔者算法(用ours表示)与基于用户协同过滤推荐(用user_based表示)、基于项目协同过滤推荐(用item_based表示)进行对比试验.推荐过程中的评分预测与目标用户的相邻用户的个数有关,选取的相邻用户的个数不同,预测的评分准确度也是不同的.
图 2为3种算法选取不同相邻用户个数的平均绝对误差(MAE,mean absolute error)值.可以看出,笔者算法的MAE比其他2种算法的MAE值都要小,并且随着相邻用户个数的增加,其值逐渐趋于稳定.因此笔者算法的性能要优于后者.
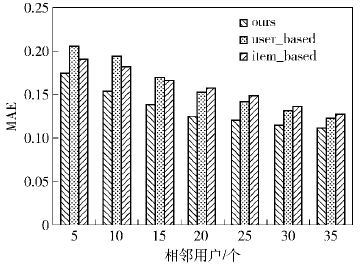
|
图2 MAE比较结果 |
图 3、图 4为k取不同值时3种算法的精确度和召回率的比较结果.通过实验结果可以看出,笔者算法的精确度和召回率都比user_based算法、item_based算法要高.在k取值小于10时,笔者算法的精确度与其他算法相比优势并不明显,但随着k值逐渐增大其优势也逐渐显现.尤其是k取15时,效果最好.由此证明,笔者推荐方法比其他2种算法具有较好的性能.
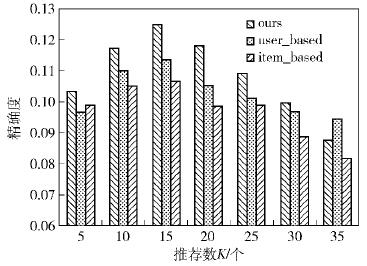
|
图3 精确度结果 |
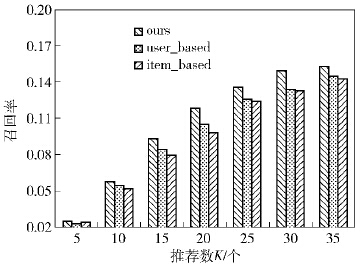
|
图4 召回率结果 |
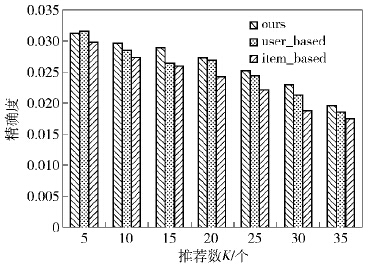
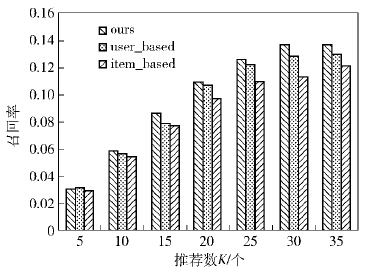
为了验证笔者推荐模型在冷启动场景中的性能,将数据集中一些用户的大多数签到记录删除,将这些用户作为测试用户.在训练集中,测试用户的签到数据被清除;在测试集中保留测试用户少量的签到数据,以此数据验证笔者推荐性能的好坏.图 5、图 6为k取不同值时3种算法的精确度和召回率的比较结果.
|
图5 冷启动环境下的精确度结果 |
|
图6 冷启动环境下的召回率结果 |
可以看出,笔者推荐模型在冷启动环境下的召回率和精确度仍然高于其他2种推荐算法,对冷启动问题起到一定的改善作用.
4 结束语个性化位置推荐可以根据用户的个人偏好为用户推荐最感兴趣和最可能被接受的位置兴趣点,具有潜在的商业价值,因而成为位置服务的发展方向.
提出的个性化位置推荐模型综合考虑了用户的签到行为特点、用户特征和位置兴趣点的语义特征.
通过真实数据集对提出的个性化位置推荐模型与基于用户协同推荐方法和基于项目的协同推荐方法进行了对比实验的结果表明,笔者提出的个性化推荐模型的召回率、准确率和平均绝对误差值都明显优于传统的基于用户协同推荐方法和基于项目协同推荐方法,因而在一定程度上提高了推荐的性能和效果.
| [1] | Zhang J, Chow C, Li Y. iGeoRec: a personalized and efficient geographical location recommendation framework[J]. IEEE Transactions on Services Computing, 2014(99):1-14.[引用本文:1] |
| [2] | Sattari M, Toroslu I H, Karagoz P, et al. Extended feature combination model for recommendations in location-based mobile services[J]. Knowledge and Information Systems, 2014,39(2):279-313.[引用本文:1] |
| [3] | Xie J, Knijnenburg B P, Jin H. Location sharing privacy preference: analysis and personalized recommendation[C]//Proceedings of the 19th International Conference on Intelligent User Interfaces. New York: ACM, 2014: 189-198.[引用本文:1] |
| [4] | Li W, Yao M, Zhou X, et al. Recommendation of location-based services based on composite measures of trust degree[J]. The Journal of Supercomputing, 2014,69(3): 1154-1165.[引用本文:1] |
| [5] | Hu B, Ester M. Spatial topic modeling in online social media for location recommendation[C]//Proceedings of the 7th ACM Conference on Recommender Systems. New York: ACM, 2013: 25-32.[引用本文:1] |
| [6] | Wang H, Terrovitis M, Mamoulis N. Location recommendation in location-based social networks using user check-in data[C]//Proceedings of the 21st ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. New York: ACM, 2013: 364-373.[引用本文:1] |
| [7] | Yuan Q, Cong G. Time-aware point-of-interest recommendation[C]//Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2013: 363-372.[引用本文:1] |
| [8] | Noulas A, Scellato S, Lathia N, et al. Mining user mobility features for next place prediction in location-based services[C]//Data Mining(ICDM), 2012 IEEE 12th International Conference on. Washington: IEEE, 2012:1038-1043.[引用本文:1] |
| [9] | Ying J J C, Lu E H C. Urban point-of-interest recommendation by mining user check-in behaviors[C]//Proceedings of the ACM SIGKDD International Workshop on Urban Computing. New York: ACM, 2012: 63-70.[引用本文:1] |
| [10] | Berjani B, Strufe T. A recommendation system for spots in location-based online social networks[C]//Proceedings of the 4th Workshop on Social Network Systems. New York: ACM, 2011: 4.[引用本文:1] |
| [11] | Liu B, Xiong H. Point-of-interest recommendation in location based social networks with topic and location awareness[C]//Proceedings of the 2013 SIAM International Conference on Data Mining. Philadelphia: SDM, 2013: 396-404.[引用本文:1] |
| [12] | Dhurandher S K, Misra S, Obaidat M S, et al. An energy-aware routing protocol for Ad-hoc networks based on the foraging behavior in ant swarms[C]//Communications, 2009. ICC'09. IEEE International Conference on. Washington: IEEE, 2009: 1-5.[引用本文:1] |
| [13] | Shi Y, Larson M, Hanjalic A. Collaborative filtering beyond the user-item matrix: a survey of the state of the art and future challenges[J]. ACM Computing Surveys(CSUR), 2014, 47(1): 3.[引用本文:1] |
| [14] | Charlin L, Zemel R S, Larochelle H. Leveraging user libraries to bootstrap collaborative filtering[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 173-182.[引用本文:2] |
| [15] | Gao H, Tang J, Liu H. Addressing the cold-start problem in location recommendation using geo-social correlations[J]. Data Mining and Knowledge Discovery, 2014: 1-25.[引用本文:1] |