


2. 国家数字交换系统工程技术研究中心, 郑州 450001
提出一种在可重构网络体系下的聚合组播机制. 采用网络编码技术可提高组播通信的传输性能,在保障聚合组播能减少路由状态、提高可扩展性的前提下,减少聚合组播的带宽浪费. 利用可重构网络的逻辑上集中控制和全局网络拓扑视角,优化网络编码与聚合组播算法. 通过随机网络拓扑模型下的性能仿真实验分析,与传统的聚合组播相比,该机制可在组播状态和带宽浪费之间达到较好的均衡.
2. China National Digital Switching System Engineering and Technological Research Center, Zhengzhou, 450001, China
An aggregated multicast scheme in the reconfigurable networks was presented. The aggregated multicast can reduce the states effectively and improve the scalability, but it brings out the waste of the bandwidth. The network coding can improve the transmission performance of multicast. In order to combine the advantages of both technologies, a multicast aggregation algorithm was proposed based on network coding in the reconfigurable. Benefited from centralized control logic and global network view in reconfigurable networks, it can reduce multicast states and waste of the bandwidth. Simulation for the random network topology model shows that, compared with the traditional multicast aggregation algorithm, it can achieve a better balance between the state and the multicast bandwidth waste.
随着下一代网络体系架构的发展,研究在新的体系结构下满足组播应用的需求日益增多,如日本的AKARI[1]项目、欧洲的FIND项目、国家“973计划”项目“可重构信息通信基础网络体系研究”[2]均对组播可扩展性问题提出了要求.
针对组播可扩展性问题,加州大学洛杉矶分校网络实验室提出了聚合组播方案[3]、AQoSM[4]和mQMA[5]协议,但因为采用树的形式进行组播通信,聚合组播虽可减少组播状态,也产生了带宽浪费[6, 7, 8, 9]. Ahlswede R等[10]提出的网络编码,可有效提高网络吞吐量,提高带宽利用率和网络性能[11, 12, 13]. 为解决聚合组播的带宽浪费提供了新的思路.
在多种新型网络体系结构中,如可重构网络、软件定义网络[14]、可重构路由[15, 16]、OpenRouter[17]以及软件集群路由器结构[18],都提供了逻辑上的集中管理和全局的网络拓扑视角,为聚合组播与网络编码提供了更好的实现架构,可以构建更优的聚合和编码方案.
笔者结合网络编码技术,充分考虑聚合组播的特性,研究了可重构网络结构下的聚合组播机制,提出一种基于网络编码的聚合算法,在减少组播状态的前提下,将多余的带宽转变为提供安全性的保障进而减少带宽的浪费. 详细描述了网络模型,介绍了基于网络编码的聚合算法,最后对所提出的算法进行了实验分析和总结.
1 网络模型与问题描述基于TCP/IP体系结构的传统互联网功能单一、服务能力有限,难以满足组播技术的实现需求. 近年来,为了应对传统的网络体系结构存在的问题,国内外都展开了未来网络的研究. 国家“973计划”项目“可重构信息通信基础网络体系结构研究”提出了一种可重构机制的网络体系结构——可重构网络. 该网络提出了数据面、控制面和管理面3平面模型,通过控制转发分离、资源虚拟化等机制,实现对多样化业务的服务承载能力. 其中,管理面通过多维状态感知和实时资源认知操作,可以根据业务需求和网络资源信息,完成重构决策,并向控制面下达重构操作命令. 而控制面主要负责网络拓扑和状态信息的维护、路由计算、寻址等,并根据管理面的命令进行具体的重构操作. 数据面则根据控制面的操作指令,具体实施数据的转发和传输.
在可重构网络体系架构下使用聚合组播和网络编码技术具有很多优势,首先对于聚合组播,树管理节点的功能可以直接交付于管理面,由存储资源丰富和数据处理能力更强的管理面进行聚合的策略计算,由控制层与数据层进行分发树的建立和数据的实际传输. 对于网络编码来说,由于可以通过控制层获取整个网络的拓扑结构,能够使用集中式的线性编码方案. 同样,所有的策略决策都交付于管理面,具体路径建立与数据传输交付于控制面与数据面.
通常网络使用有向无环图G(V,E)来表示,其中V表示节点集,E表示边集. 信源节点通常用S表示,信宿节点集用T表示. 每条边(i,j)被赋予1个正的代价值cij=cji,度量使用这条边传输数据的代价. 已知组播组集合Sg={g1,g2,…,gn},对于某个组播组g使用网络编码算法A1,如Jaggi-Sanders[13]算法来进行线性多播的码构造,生成对应的传输路径p(包含于编码方案中),为了便于对带宽浪费进行定量分析,对于给定的传输路径p,数据在其上传输的总代价为 $ C\left( p \right) = \sum {{c_{ij,}}link\left( {i,j} \right) \in p.} $
因此,带宽浪费可定义为,给定一个组播组g,pA是由网络编码算法A1计算出的原始的传输路径. 如果这个组可以被聚合路径p(gn)覆盖,那么它的带宽浪费率可定义为
| $ \delta \left( {{p^A},{g_n}} \right) = \frac{{C\left( {p\left( {{g_n}} \right)} \right) - C\left( {{p^A}\left( {{g_n}} \right)} \right)}}{{C\left( {p\left( {{g_n}} \right)} \right)}} $ |
在很多聚合算法研究文献中,为了简化问题,通常假设所有链路的代价均相同,所以C(p)=|p|为路径p的链路数目. 可简化为
| $ \delta \left( {{p^A},{g_n}} \right) = \frac{{\left| {p\left( {{g_n}} \right)} \right| - \left| {{p^A}\left( {{g_n}} \right)} \right|}}{{\left| {p\left( {{g_n}} \right)} \right|}} $ |
其中|pA(gn)|、|p(gn)|分别为聚合路径或原始路径的链路数目.
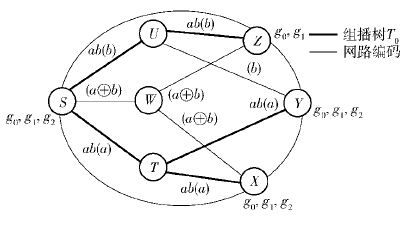
在传统组播中,每个组播组根据1棵组播树进行组播通信. 但在聚合组播中,多个组播组共享同1棵聚合树,因此在实施聚合组播时需要进行组树匹配. 如图1所示,在网络中有3个组播组g0,g1,g2共享1棵聚合树T0,如果组播树中所有叶子对应于组播组中的成员,那么树和组称为完美匹配,如果树中的某些叶子不对应组中的成员,那么树和组称为漏匹配. 在图1中,g0和g1是完美匹配,g2是漏匹配. 当根据聚合树进行数据传输,出现漏匹配时,非某个组的成员,如Z路由器就会接收到本不会接收的组播组g2的流量,从而产生了带宽浪费. 所以,聚合组播需要权衡带宽和状态的可扩展性,这也是聚合组播优化的核心问题.
|
图1 网络编码与聚合算法示意图 |
但是如果在原来的拓扑结构下使用网络编码,在节点S上进行编码a⊕b. 当源节点S向成员发送数据包a、b时,若各条链路的容量均为1,在聚合组播情况下,需要用到连接S-U,U-Z,S-T,T-Y,T-X,但需要分别发送2次,若网络各个链路的容量均为2,在聚合组播情况下,每条边上都发送消息a、b,当使用网络编码时,S-U,U-Z,U-Y传输b,S-T,T-Y,T-X传输b,而S-W,W-Z,W-X传输a⊕b,共用到了9条链路,比传统的路由方式利用了更多的通信链路,从而均衡了网络负载,并且可以看到,每个目的节点为了同时获得2bit信息量,共使用了5条链路,每条链路的容量为2,因此在整个网络中一共传输了10bit数据. 若采用网络编码多播方式,共使用了9条链路,每条链路的容量为1,在整个网络中一共传输了9 bit数据,通过网络编码技术,可以节省10%的带宽,从而提高网络带宽利用率. 在路由状态可扩展性上,网络编码也具有一定的优势. 如图1所示,共有3个组,至少需要保存2×6+4=16个状态,而聚合后只需要6个,使用网络编码则需要7个状态. 可以看出,使用网络编码进行聚合通信可以有效减少带宽浪费,带来的状态增加也是可以接受的.
在基于组播树的聚合算法中,聚合程度越高(即减少的状态越多),浪费的带宽越多(即带宽浪费率δ越大). 所以,笔者通过结合聚合组播与网络编码2种技术的优势,达到在减少相同状态的能力下,需要的带宽浪费率更小的目的,从而最小化带宽开销.
2 基于网络编码的聚合组播算法首先利用网络编码算法A1为组播组集合Sg中的每一个组播组构建原始传输路径,得到原始路径集合PS={p1,p2,…,pn}.
定义1 ω为源节点S发送的消息的维数,如图1中ω=2.
定义2 分离路径,从源节点S到接收节点ti的任意2条路径之间不具备任何共享链路,则2条路径被称为分离路径.
网络编码算法A1首先计算出源节点S到达接收节点ti(1<i<n,n为组播g中的接收节点的数量)的ω个分离路径,在求分离路径时进行路由计算可以采用传统路由算法如最短路径算法. 在聚合算法A2之前计算出源节点S到达组播组集合Sg中所有的组播组的接收节点ti的所有分离路径. 然后使用网络编码算法A1,计算出原始传输路径pi. 在网络编码路由中,组成员的相似度会对组播传输路径的相似度产生影响. 而原始传输路径越相似,则进行聚合时,聚合路径越能满足带宽浪费门限,可以减少计算不满足带宽浪费门限聚合路径的次数,即可避免不必要的计算,并缩小聚合的搜索空间.
算法: 基于网络编码的组播聚合算法.
输入: 原始组播路径集合PS={p1,p2,…,pn}.
输出: 聚合路径集合.
步骤1 初始化,聚合路径PAS←∅,聚合路径对应的组播组SAg←∅;
步骤2 随机取出PS={p1,p2,…,pn}中的一个原始路径pi,1≤i≤n,取出后,PS←PS-{pi};
若PAS为空,执行步骤3;
若PAS不为空,取pi对应的组播组gi,依次与SAg中的gAj进行比较,若gi∩gAj≠∅,说明2个组播组有相同的部分,具有一定聚合价值,判断带宽浪费率δ的绝对值是否大于阈值B,不大于则执行步骤4,否则执行步骤3;若gi∩gAj=∅,说明两者没有共同路径,执行步骤3;
步骤3 将pi加到PAS中,pi成为一个聚合路径,PAS=PAS∪{pi},记为pAj,对应的组播SAg=SAg∪{gi},记为gAj;
步骤4 选择带宽浪费最小的聚合路径pAj与pi进行聚合,在聚合时,需要合并相同的传输路径,将pi与pAj中不同的链路添加到pAj_new中,同时,更改pi对应的组播组gi的组树映射,将gi映射到新的pAj_new中;
步骤5 PAS={PAS-{pAj}}∪pAj_new;
步骤6 重复步骤2,直到PS为空,算法结束.
3 实验与分析为了验证基于网络编码的聚合算法的实际效果,笔者对算法进行了仿真验证. 用Salama模型生成了随机网络拓扑,其中α=0.2,β=0.15. 平均节点度数为4,网络节点数为120.
3.1 算法复杂度分析在计算传输路径时使用的是网络编码算法A1. 该算法的复杂度取决于选择的算法,如笔者采用的Jaggi-Sanders算法的时间复杂度为O(|E|n). 其中,n为有向无环网络中满足最大流maxflow(T)≥ω的节点的总个数. 在基于网络编码的聚合算法中,主要分为两部分:一是在生成聚合路径时,最多比较∑(N(N-1))/2次,时间复杂度为O(N2);二是比较传输路径pi与聚合路径的冗余度. 因为路径最多有k条边,所以时间冗余度为O(k2),算法时间复杂度为O(N2k2).
3.2 仿真结果为了验证笔者提出算法的有效性,首先实现了文献[3]中由UCLA网络实验室提出的一种动态聚合组播算法,该算法是基于组播树进行聚合的. 在仿真实现时,在相同的网络拓扑结构下,运行UCLA的聚合算法与笔者提出的基于网络编码的聚合算法,为了便于分析,设每个组播组在每条链路上占用的带宽都为1,带宽浪费阈值都为0.5,每个组播组的成员个数在[5, 20]之间随机分布.
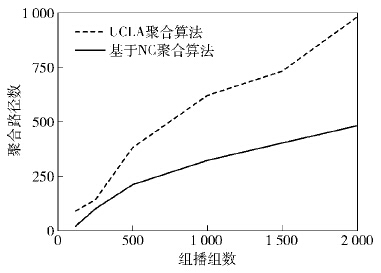
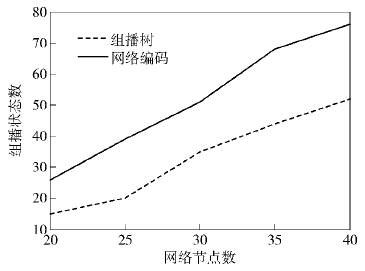
图2显示了组播树数目与最后聚合出的组播路径数目的情况. 明显地,随着组播数的增加,基于网络编码的聚合组播具有更好的聚合效果. 因为基于网络编码的组播利用的路径多,不同组播组之间重合的路径较多,而且在计算带宽浪费率时得到的值较小. 所以,相较基于组播树的组播聚合情况出现得较多. 虽然聚合出的组播路径数目减少了,但是对于某个组播组来说,网络编码组播的状态可能会远多于基于组播树的组播状态. 如图3所示,在每个组播源节点发送消息维数为2时,随着网络规模的扩大,基于网络编码的组播路由几乎采用了网络中一半以上的链路来构建路由,它的转发状态明显多于基于组播树的状态.
|
图2 组播数目与聚合算法对比 |
|
图3 组播树与网路编码组播状态对比 |
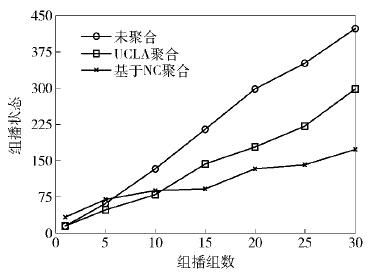
如图4所示,在网络规模较小时,基于网络编码的聚合组播在减少状态上并不占优势,只有当随着组播组数目增加,凸显出聚合的优势时,才能在减少状态上具有更好的优势. 可以看出,在相同的带宽浪费率下,随着组播组数目的增加,基于NC的集合算法相较于基于组播树的聚合算法,能更好减少组播状态,有效地减少了带宽开销.
|
图4 聚合算法与组播状态对比 |
结合网络编码与聚合组播两种技术的优势,重点解决组播可扩展问题中的状态问题,通过使用网络编码的传输方式,来降低网络带宽的浪费,通过聚合来降低组播状态. 通过性能分析,证明该方法比传统IP组播与聚合组播,可以更加有效地兼顾状态的减少与带宽的浪费,达到最小化带宽开销的目的. 但是,不同的网络编码路由方式得到的聚合效果也不同,在下一步的工作中,将致力于找到一种更好支持聚合思想的网络编码路由与优化方案. 同时,笔者的算法只解决了静态的问题,当新的组播加入,由于网络编码的编码复杂性,如何减少管理层的决策时间,即动态的基于网络编码的聚合组播的算法研究,也是下一步重要的研究方向.
| [1] | Hirabaru M, Inoue M, Harai H. New generation network architecture AKARI conceptual design (ver1.1)[R]. AKARI Architecture Design Project, October 2008.[引用本文:1] |
| [2] | Lan Julong. Research on the architecture of the reconfigurable fundamental information communication network[R]. Report of the National Basic Research Program of China(973 Program), 2012.[引用本文:1] |
| [3] | Fei Aiguo, Cui Jinhong, Gerla M, et al. Aggregated multicast: an approach to reduce multicast state[C]//Proc of the 6th Global Internet Symposium. San Antonio, Texas, USA: [s.n.], 2001.[引用本文:2] |
| [4] | Lao Li, Cui Junhong, Gerla M. Tackling group-to-tree matching in large scale group communications[J]. Computer Networks, 2007, 51(11): 3069-3089.[引用本文:1] |
| [5] | Moulierac J, Guitton A, Molnár M. Multicast tree aggregation in large domains[M]. [S.l.]: Springer Berlin Heidelberg, 2006: 691-702.[引用本文:1] |
| [6] | Sun Baolin, Ying Song, Gui Chao, et al. Multiple constraints QoS multicast routing optimization algorithm in MANET based on GA[J]. Progress in Natural Science, 2008, 18(3): 331-336.[引用本文:1] |
| [7] | Hao Junrui, Yu Shaohua. Scalable group-tree matching algorithm in aggregated multicast[J]. Journal of Chinese Computer Systems, 2008, 29(10): 1781-1785.[引用本文:1] |
| [8] | Zhu Fangjin. Research on optimization model and algorithm for aggregated multicast[D]. Jinan: Shandong University, 2011.[引用本文:1] |
| [9] | Mo Han. Research on scalable multicast scheme[D]. Zhengzhou: PLA Information Engineering University, 2013.[引用本文:1] |
| [10] | Ahlswede R, Cai Ning, Li Shuoyan, et al. Network information flow[C]//IEEE Transactions on Information Theory. 2000: 1204-1216.[引用本文:1] |
| [11] | Koetter R, Medard M. An algebraic approach to network coding[C]//IEEE/ACM Trans on Networking. 2003: 782-795.[引用本文:1] |
| [12] | Jaggi S, Sanders P, Chou Philip A, et al. Polynomial time algorithms for multicast network code construction[C]//IEEE Trans on Information Theory. 2005: 1973-1982.[引用本文:1] |
| [13] | Ho T, Medard M, Koetter R, et al. On randomized network coding[J]. Proc of the 41st Annual Allerton Conf on Communication, Control, and Computing, 2003.[引用本文:2] |
| [14] | Thomas D N, Gray K. SDN: software defined networks[M]. [S.l.]: O'Reilly Media, Inc, 2013.[引用本文:1] |
| [15] | Xu Ke, Chen Wenlong, Lin Chuang, et al. Toward a practical reconfigurable router: a software component development approach[J]. Network, IEEE, 2014, 28(5): 74-80.[引用本文:1] |
| [16] | Zhang Xiaoping, Liu Zhenhua, Zhao Youjian, et al. Scalable router[J]. Journal of Software, Software, 2008, 19(2): 1452-1464.[引用本文:1] |
| [17] | Wang Baosheng. Research and implementation on a new router architecture[D]. Changsha: National University of Defense Technology, 2005.[引用本文:1] |
| [18] | Gong Zhenghu, Fu Bin, Lu Zexin. Research on the architecture of software-based cluster routers[J]. Journal of National University of Defense Technology, 2006, 28(3): 40-43.[引用本文:1] |