


为解决英语命名实体链接问题,提出了一种基于上下文信息和排序学习的实体链接方法. 首先使用上下文信息对实体指称进行扩充,并在维基百科中检索候选实体列表;然后通过抽取实体指称与候选实体之间的各类特征,利用ListNet排序算法对候选实体列表进行排序,选出Top1的候选实体作为链接结果;最后对未找到候选的实体指称即NIL实体,通过实体聚类算法进行关联链接. 实验结果表明,该方法在KBP 2013实体链接数据集上的F值为0.660,比KBP 2013实体链接评测中所有参赛队伍的平均F值高0.092,比系统BUPTTeam2013的F值高0.162.
English entity linking tasks play an important role in construction of semantic network and big knowledge base. An entity linking method based on local information and learning to rank algorithm was proposed. Firstly, the context information is well used for expanding mentions' name and retrieving candidate entities from Wikipedia. Secondly, kinds of features are extracted between mentions and candidates and also the ListNet algorithm was used to rank the candidate entities to choose the most related entity as the linked objects. Finally, the NIL entities was clustered by clustering method. The method achieved 0.660 F value on KBP 2013 Entity Linking dataset, it performs 0.092 better than the median F value of all participated teams in KBP 2013 entity linking task and also performs 0.162 better than BUPTTeam 2013, which is the baseline comparison system in the experiment.
实体链接任务是一种从文本到概念的过程[1]. 该任务需要将给定的实体指称链接到维基百科(Wikipedia)中的相同实体概念上[2].
目前较为普遍的实体链接方法是,首先形成候选实体列表,接下来对该列表进行排序[3] ,最后再进行链接. 通常上述流程尚需进一步的研究和细化. 因此,笔者提出一种基于上下文信息和排序学习的实体链接方法. 该方法的优点如下:
1) 采用合理的策略生成候选实体列表;
2) 对候选实体列表进行高精度的排序;
3) NIL实体聚类中,将规则与传统的聚类算法相结合.
1 相关工作 1.1 实体链接实体链接从最初的基于规则的方法,到基于统计的方法,近年来,基于多方法融合的框架成为了普遍被研究者所接受的系统框架. 该框架首先为实体指称生成候选实体列表,再对候选实体列表进行排序[3].
研究者在生成候选实体列表前加入了扩充步骤. Cucerzan[4]使用与实体指称具有同指关系且最长的表面字符串代替实体指称. 谭咏梅等[5]提出了一种首字母缩写词的扩充策略,使用了一个滑动窗口在指称所在上下文中利用表面字符串匹配的方式查找扩充名并统计词频.
排序学习是将机器学习应用于信息检索领域的新算法,已有相关学者在实体链接中使用. Monahan等[6]使用Ranking SVM算法解决实体链接中候选实体列表排序问题.
1.2 排序学习算法排序学习算法主要分为3种:基于数据点的方法(Pointwise)、基于数据对的方法(Pairwise)和列表方式(Listwise).
将列表方法中的ListNet算法[7]应用于实体排序时,候选实体(j1,j2,…,jk)的Top-K概率表示这些候选实体在n个候选实体中排在前K个的概率.
Top-K子群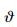 k(j1,j2,…,jk)是包含下面的所有的排序:Top-K个候选实体正是(j1,j2,…,jk).
k(j1,j2,…,jk)是包含下面的所有的排序:Top-K个候选实体正是(j1,j2,…,jk).
| \[{\vartheta _k}({j_1},{j_2}, \ldots ,{j_k}) = \left\{ {\pi \in {\Omega _n}{\rm{|}}\pi (t) = {j_t},\forall t = 1,2, \ldots ,k} \right\}\] | (1) |
其中:π为候选实体的一个排序结果,Ωn为n个候选实体所有可能排序结果集合.
候选实体(j1,j2,…,jk)的Top-K概率为子群的概率
| \[{P_s}({\vartheta _k}({j_1},{j_2}, \ldots ,{j_k})) = \sum\limits_{\pi \in {\vartheta _k}({j_1},{j_2}, \ldots ,{j_k})} {{P_s}} (\pi ) = \prod\limits_{t = 1}^k {\frac{{\Phi ({s_{jt}})}}{{\sum\limits_{l = t}^n {\Phi ({s_{jt}})} }}} \] | (2) |
其中:Ps(π)是给定s排序结果π的概率,s为分值列表,φ()是一个递增的严格的非负函数.
利用模型得到实体排序的概率分布之后,ListNet采用交叉熵来计算模型预测的实体排序概率分布和实际的实体排序概率分布之间的差异.
2个概率分布p和q之间的交叉熵定义为
| \[H(p,q) = - \sum\limits_x {p(x)} \lg q(x)\] | (3) |
在ListNet中,假设Py(i)(g)表示实际的实体排序g的概率,而Pz(i)(g)表示模型预测的排序g的概率,则2个实体排序概率分布之间的交叉熵为
| \[H({y_i},{z_i}) = - \sum\limits_{\forall g \in {\vartheta _k}} {p({y_i})} (g)\lg ({P_{{z_{(i)}}}}(g))\] | (4) |
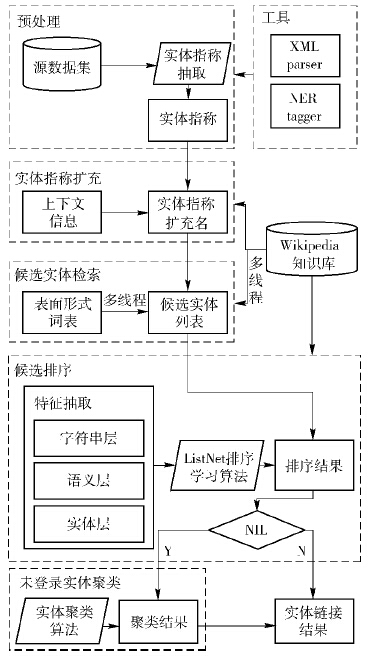
基于上下文信息和排序学习的实体链接方法总共包含5个部分:预处理、实体指称扩充、候选实体检索、候选排序及未登录实体聚类,如图 1所示.
|
图1 基于上下文信息和排序学习的实体链接方法 |
其中,预处理主要从TAC KBP官方发布的源数据集中提取实体指称信息和实体指称的上下文.
实体指称扩充利用指称上下文中的同指关系以及从Wikipedia中抽取的词表和从爬虫获取的网络知识对实体指称进行扩充.
候选实体检索中,对于每个实体指称,从Wikipedia知识库中检索出对应的候选实体列表.
候选排序共分为2部分:特征抽取和排序学习算法. 通过排序学习算法,得到每个候选实体的分数,将得分最高的知识库实体作为链接结果.
另一些情况下,实体指称生成的候选集合的大小为0,则称这样的实体指称为“NIL(未登录)”实体. 使用实体聚类算法对所有NIL实体进行关联链接.
文中所使用的一些标记名及含义如表1所示.
| 表1 标记名及其含义 |
预处理部分主要从源数据集的语料中提取实体指称信息和实体指称的上下文.
实体指称扩充的目的是将实体指称扩充为一个更正式的名字,主要对英语中常见的缩写、简称、缩略情况进行扩充:首字母缩写,使用首字母匹配的方法在上下文中匹配全称;词组的简称,在上下文中找出一个命名实体,该实体能够完全包含实体指称;缩略词,从缩略词词表中找出缩略词对应的全称.
2.2 候选实体检索为了提高检索效率,使用3种能够有效增加检索性能的方式.
1) 对知识库进行过滤. 保留知识库中的4种资源页面:entity pages、redirect pages、 disambiguation pages、hyperlinks.
2) 建立表面形式词表. 其包括各种名字的变体、缩写、混淆名、拼写变体、昵称等.
3) 使用线程池.
2.3 候选排序候选排序部分共包括特征抽取和排序学习2个关键步骤. 特征抽取将指称m与e∈Em构建特征向量Fm(e);排序学习算法通过使用训练集优化损失函数,得到训练后的模型,测试集输入到训练好的模型中得出最终的排序结果. 从排序结果中选取Top1实体作为最终的链接结果.
特征抽取部分研究了实体指称m和e∈Em之间的关系,并参考了杨雪[8]、Zhang等[9]的特征抽取方式,如表2所示.
| 表2 特征抽取 |
使用了规则和K-means聚类相结合的算法:预先使用严格的规则对满足要求的未登录实体进行聚类,再使用传统划分式聚类算法K-means对余下的实体指称进行聚类.
对于使用规则无法聚类导致余下的实体指称,将实体指称的上下文表示成词向量空间,再通过线性判别分析对词向量空间降维,接着使用K-means对词向量聚类得出最终的关联聚类结果.
3 实验 3.1 实验数据文本在实体链接中所使用的维基百科知识库为2009年10月版本,总计包含81万余条实体条目,包括地理政治实体、组织机构实体、人称实体和未知实体.
3.2 评测指标实体链接任务以F值作为重要的衡量指标. TAC KBP英语实体链接任务中的F值是使用B-Cubed算法进行计算的.
3.3 实验结果在TAC KBP 2013实体链接评测任务中,队伍BUPTTeam2013使用了一个包括扩充、生成候选、排序和聚类的方法框架[10]. 笔者实现了一个具有类似框架的实体链接系统Improve2014,但是在每一步骤中又与BUPTTeam2013有所不同,为了验证所改进的实体链接方法优于BUPTTeam2013,Improve2014使用了和BUPTTeam2013相同的测试集(KBP 2013评测数据). 实体链接性能对比如表3所示.
| 表3 实体链接性能对比 |
表3中的Median是KBP 2013所有参赛队伍的平均F值. 结果显示,Improve2014的B-Cubed F值为0.66,较BUPTTeam2013的F值提高了0.162,较2013年KBP所有参赛队伍的平均F值提高了0.092. 实验结果表明,所提出的方法具有一定的优越性.
4 结束语为解决英语命名实体链接问题,提出了一种基于上下文信息和排序学习的实体链接方法. 首先对实体指称进行扩充,在维基百科中检索候选实体列表;然后通过查询的方式获得实体指称与候选实体名之间的相似度,利用ListNet排序算法对候选实体名进行排序,选出在知识库候选实体列表中出现并且与实体相关度最高的实体名作为链接实体;最后对NIL未登录实体通过实体聚类方式进行关联链接. 该方法所实现的系统在KBP 2013英语实体链接测试数据上实验F值为0.660,比对照系统BUPTTeam2013的F值高0.162,比2013年KBP所有参赛队伍的平均F值高0.092. 另外,该方法中仍然存在一些问题,如精准度和构建成本之间的权衡、同名实体出现在同一上下文中的情况.
| [1] | 张苇如, 孙乐,韩先培. 基于维基百科和模式聚类的实体关系抽取方法[J]. 中文信息学报,2012,26(2): 76-81. Zhang Weiru, Sun Le, Han Xianpei. A entity relation extraction method based on Wikipedia and pattern clustering[J]. Journal of Chinese Information, 2012, 26(2): 76-81.[引用本文:1] |
| [2] | Tan Yongmei, Wang Zhichao, Yang Xue, et al. BUPTTeam participation at TAC 2012 knowledge base pupulation[C]//Proceedings of the TAC. Gaithersburg: NIST, 2012.[引用本文:1] |
| [3] | Ji Heng, Nothman J, Hachey B. Overview of TAC KBP 2014 entity discovery and linking tasks[C]//Proceedings of NIST TAC 2014. Gaithersburg: NIST, 2014.[引用本文:3] |
| [4] | Cucerzan S. TAC entity linking by performing full-document entity extraction and disambiguation[C]//Proceedings of the TAC. Gaithersburg: NIST, 2011.[引用本文:1] |
| [5] | 谭咏梅,杨雪. 结合实体链接与实体聚类的命名实体消歧[J]. 北京邮电大学学报,2014,37(5): 36-40. Tan Yongmei, Yang Xue. An named entity disambiguation algorithm combining entity linking and entity clustering[J]. Journal of Beijing University of Posts and Telecommunications, 2014, 37(5): 36-40.[引用本文:1] |
| [6] | Monahan S, Lehmann J, Nyberg T, et al. Cross-lingual cross document coreference with entity linking[C]//Proceedings of the TAC. Gaithersburg: NIST, 2011.[引用本文:1] |
| [7] | Cao Zhe, Li Hang. Learning to rank: from pairwise approach to listwise approach[C]//Proceedings of the 24th ICML. Oregon: ACM, 2007: 129-136.[引用本文:1] |
| [8] | 杨雪. 基于维基百科的命名实体消歧的研究与实现[D]. 北京:北京邮电大学,2013.[引用本文:1] |
| [9] | Zhang Wei, Su Jian, Chen Bin, et al. I2R-NUS-MSRA at TAC 2011: entity linking[C]//Proceedings of the TAC. Gaithersburg: NIST, 2011.[引用本文:1] |
| [10] | Yang Xue, Wang Rui, Li Maolin, et al. BUPTTeam participation at TAC 2013 entity linking[C]//Proceedings of the TAC. Gaithersburg: NIST, 2013.[引用本文:1] |