


2. 湖南涉外经济学院 信息科学与工程学院, 长沙 410205
识别用户客户端的上下文特征的差异性, 有助于为新用户预测Web服务的服务质量(QoS), 但现有研究缺乏对影响用户QoS体验的上下文特征的系统分析.对此, 提出了一种客户端上下文感知的Web服务QoS预测方法, 该方法通过量化分析客户端的上下文特征, 应用模糊层次分析法计算历史用户与当前用户的上下文相似度, 并以该相似度结果为指导, 结合协同过滤技术, 以特征加权合成方法预测Web服务的QoS值.通过实验对比和分析可知, 该方法能有效解决"新用户问题", 并提高Web服务QoS预测的精度.
2. School of Information Science and Engineering, Hunan International Economics University, Changsha 410205, China
The identification of client context features between different users is helpful to predict quality of service (QoS) accurately. However, these context features affecting the experience quality of user have not been analyzed systematically in current studies. A client context-aware prediction approach of QoS for Web services was proposed, in which the client context features were analyzed quantitatively. The fuzzy analytic hierarchy process method was applied to calculate context similarity between current user and history users. From that, the similarity weights fusion method was employed to predict the QoS, integrating the collaborative filtering technology. Experiment analysis indicates that this approach can solve the new user problem and improve the accuracy of QoS prediction of Web services effectively.
近年来,随着越来越多功能相似的Web服务发布到Internet,服务质量(QoS,quality of service)已成为用户选择Web服务时关注的重要因素.由于Internet的不可预测性和用户环境的异构性,用户在不同客户端上下文度量同一个Web服务得到的QoS往往存在较大差异[1].为帮助用户准确了解Web服务的QoS,客户端的Web服务QoS预测方法已成为当前服务选择研究的主要热点之一.
历史用户反馈的评价数据可提供Web服务QoS预测的重要依据.由此,学者们提出了多种基于协同过滤技术的预测方法[2-4].但是,在数据稀疏情况下,协同过滤效果并不理想.尤其在处理新用户问题时,传统的用户平均法或项目平均法、概率统计法均无法保证预测精度.识别用户客户端上下文的差异性,有助于提高面向新用户的QoS预测精度.现有研究分别从设备类型[1]、基于经纬度的地理位置[3]、基于自治系统(AS,autonomous system)的网络位置[4]、基于IP的地理位置特征[5]、响应时间特征[6]等侧面研究了不同客户端上下文环境下QoS的预测问题,但对可能影响用户的QoS体验的客户端上下文特征缺乏系统的分析.尤其在对地理位置特征的研究方面,现有文献主要考虑了国家的差异性,但笔者认为,建立一个包含多级行政单位的描述机制,应更有利于提高Web服务QoS的预测精度.
为此,笔者在Web服务QoS预测研究中,全面分析客户端的上下文特征,并利用其识别用户差异性,通过量化分析当前用户和历史用户的客户端上下文获取两者的相似度数据,并应用模糊层次分析法综合特征相似度以识别特征共同体,进而为当前用户,尤其是新用户,在协同过滤算法基础上,以上下文特征加权合成方法预测Web服务的QoS值.
1 客户端上下文1.1 客户端上下文的定义结合Web服务特点,客户端上下文主要包括6个特征.
1) 地理位置特征. G=(country, state or province, city, county or district, subdistrict),这个使用多级行政单位表示的五元组可准确描述用户的位置.它决定了用户所在区域的本地Internet服务提供商的服务水平和政府的网络管控状况.可根据实际情况选择位置特征的描述精度,并非必须使用完整的五元组. gji表示用户i的第j项位置信息.
2) AS特征. AS决定了用户所在网络的网络路由状况和通信质量.同一AS内的用户可能体验相似的网络状况.令ac和ah分别表示当前用户和历史用户的AS号,0≤ac, ah≤232-1.
3) 接入设备特征.常用的客户端接入设备包括服务器、PC、笔记本电脑、平板电脑、智能手机等,不同类型的设备在远程访问Web服务时体验到的QoS存在明显差异.
4) 集成框架特征.常用的客户端集成框架包括AXIS、SOAP、ESB、CXF、XFire、Ksoap2等,因使用的通信协议和实现方法不同,不同类型的集成框架将影响到Web服务的QoS表现.
5) 集成操作系统特征.常用的客户端操作系统包括Windows、Linux、UNIX、Android、iOS等.
6) 集成编程语言特征.常用的客户端集成编程语言包括Java、C#、Delphi、PHP和Python等.
具有相似上下文的用户,更可能体验到相似的QoS.因此,预测过程中以当前用户为依据,匹配历史用户的上下文,识别高相似性的历史用户,它们提供的QoS数据对当前用户具有更高的参考价值.
1.2 客户端上下文的相似度度量方法各个上下文特征的相似度度量方法如下.
1) 地理位置特征的相似度.设计了一种二进制特征编码方法描述地理位置信息:L= b1b2…bn. b1代表最大的行政单位,即国家;bn为最小行政单位.当前用户的位置编码为Lc=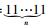
① 按式(1) 对历史用户的位置信息编码.
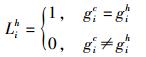
|
(1) |
其中:gic和gih分别为当前用户和历史用户的第i项位置特征值.
② 如果Lih=0,则满足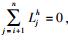
③ 特别地,如果L1h=0,则Lh=0.为便于评估历史用户与当前用户的位置相似度值,按式(2) 对历史用户的二进制位置编码规范化.

|
(2) |
其中:(b1b2…bn-1bn)2=(2n-1b1+…+21bn-1+20bn);α为常量,因不同国家之间存在明显差异,令0≤α≤2n-1. L的性质可知,0≤Sg≤1.
2) AS相似度. AS相似度的计算方法为

|
3) 接入设备相似度.定义接入设备特征集为D={d1, d2, …, dn-1, dn}.不同接入设备di与dj间的特征相似性可使用相关性矩阵进行评价
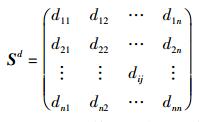
|
其中:0≤dij, dji≤1,dij为第i项接入设备与第j项接入设备的相似度,显然dij=dji.建议采用五级制,即D={服务器,PC,笔记本式计算机,平板式计算机,智能手机}.笔者给出的5级制相关性矩阵为

|
4) 集成框架相似度.定义客户端集成框架特征集为F={f1, f2, …, fn-1, fn}.不同集成框架fi与fj的特征相似性可使用相关性矩阵进行评价.
5) 操作系统相似度.定义客户端操作系统特征集为O={o1, o2, …, on-1, on},oi与oj间的相似性可用相关性矩阵评价.
6) 集成编程语言相似度.定义客户端集成编程语言特征集为P={p1, p2, …, pn-1, pn}.不同集成编程语言的特征相似性由相关性矩阵确定.
2 客户端上下文感知的QoS预测方法2.1 基于FAHP法计算上下文特征权重模糊层次分析(FAHP,fuzzy analytic hierarchy process)法[9]结合模糊逻辑,适用于多指标以及多层次的决策问题.笔者采用FAHP法确定上下文特征权重以识别与当前用户相似的历史用户.
设有模糊判断矩阵E=(eij)n×n,满足0≤eij≤1,n为上下文特征个数,eij为特征i与j的重要性之比,可采用0.1~0.9的5级互补标度度量.模糊判断矩阵E=(eij)n×n中eij+eji=1,eii=0.5,E为模糊互补判断矩阵.若E和任意整数k满足eij=eik-ejk+0.5,则称E为模糊一致性矩阵.为将E转换为模糊一致性矩阵,按式(3) 计算模糊互补矩阵中每一行之和,并按式(4) 进行数学变换.
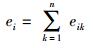
|
(3) |
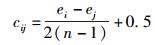
|
(4) |
这样得到的新矩阵C=(cij)n×n是一个模糊一致性矩阵.计算C中每行的和,并进行标准化,得到权重向量w=(w1, w2, …, wn),其计算公式为
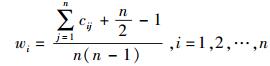
|
(5) |
k个历史用户与当前用户的特征相似度矩阵为

|
其中:Sloc、Sas、Sdevice、Sframe、Sos、Slang为6个上下文特征相似度行矩阵,sij为用户i的第j项特征相似度值.按式(6) 计算用户i的上下文特征综合相似度.
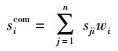
|
(6) |
定义相似度阈值为sth,如果sicom < sth,说明该用户的QoS体验值对当前用户无参考价值.这样得到一个“特征共同体”,U={u1, u2, …, ui, …, uz},表示可参考的用户集合,ui的sicom大于sth.
2.3 Web服务的QoS值预测算法1) 提取当前用户的上下文特征,与系统中历史用户进行上下文特征的比对,应用FAHP法计算得到特征权重,根据设定的sth,生成U集合.
2) 如果当前用户i是新用户,即系统中无该用户的历史数据时,应用上下文特征加权合成方法预测Web服务QoS值,计算公式为

|
(7) |
其中:vj为历史用户j反馈的QoS值;Qi为特征相关系数,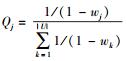
3) 如果当前用户不是新用户且|U| < nth,即特征共同体中相似用户数量小于特定阈值nth时,根据系统中存储的当前用户和其他用户的历史反馈数据,使用皮尔逊相关系数(PCC,Pearson correlation coefficient)计算用户相似度,即
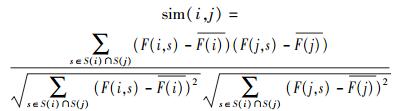
|
其中:F(i, s)为用户i对服务j的评价值,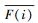
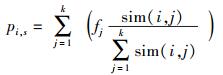
|
(8) |
4) 如果当前用户不是新用户且|U| > nth,即系统中有足够数量的历史用户具有与当前用户相似的上下文特征时,采用提出的上下文特征加权合成方法预测Web服务的QoS值,如式(7) 所示.
所提方法的时间复杂度可分2种情况分析.
① 如果当前用户不是新用户且|U| < nth,所提方法退化为传统的协同过滤算法,其时间复杂度与之相同.
② 在当前用户是新用户的情况下,或者虽然当前用户不是新用户但满足|U| > nth的情况下,此时所提算法开销主要分为4个部分:第1部分为客户端上下文特征的相似度计算,复杂度为O(m),m为历史用户的数目;第2部分为上下文特征权重的计算,复杂度为O(n2),n为上下文特征个数,由于n通常取值为6,故此项复杂度近似为O(1);第3部分为特征综合相似度的计算,时间复杂度为O(z),z为特征共同体中的用户个数;第4部分为特征加权合成QoS值的计算,时间复杂度为O(z).
3 实验为验证方法的有效性,进行了实验分析.使用文献[4]提供的真实数据集.因该数据集缺乏对客户端上下文特征的分析,笔者对其进行了部分扩充,扩展后的主要用户信息如表 1所示.其中,AS号、所在城市、网络描述(所在区域)为扩展的真实信息.经统计,339个用户分属138个AS,其中AS680有28个用户.用户来自31个国家和地区的153个城市,其中Berkeley和Los Angeles用户最多,各有8个,另有46个城市只有1个用户.
|
|
表 1 数据集扩展后的用户信息 |

根据数据集中的用户信息,实验构建了“国家—城市—区域”3级位置编码.考虑到数据集的实际情况,可认为接入设备、集成框架、集成操作系统和集成编程语言均相似,应用FAHP计算权重时,这4个特征设置较小重要性.这样,基于FAHP方法定义客户端上下文特征模糊互补判断矩阵为

|
数据集提供了Web服务的响应时间和吞吐量实测数据,本实验主要以响应时间为依据.为便于计算各个服务的响应时间标准差(SD,standard deviation),针对数据集中超时计为-1的特点,使用式(9) 将其转换为一个由惩罚系数转换得到的正数.
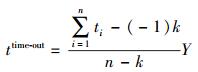
|
(9) |
其中:n为用户总数;k为反馈响应时间为-1即超时的用户数;ti为用户i反馈的响应时间;ttime-out为计算SD时所有超时响应时间的计算数值;Y为惩罚系数,通常Y≥10,本实验中Y=10.
设定当前用户的客户端上下文特征为{(Germany, Berlin, Technical University of Berlin), AS680, PC, SOAP, Linux, Java}.根据上下文特征相似度计算方法和FAHP确定特征权重,计算各历史用户与潜在用户的上下文相似度数据.
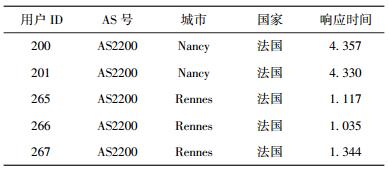
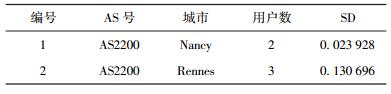
为说明AS特征的作用,以8#服务为例分析.全体用户的响应时间SD为0.8831.抽取18个至少包含4个以上用户的AS,按AS分组分别计算后得到的响应时间SD分布如图 1所示.可见, SD大大降低,除1个AS外,其他AS分组均低于0.02.但也可观察到拥有最大的SD是AS2200,其SD值为1.5603,其内部数据如表 2所示. AS2200内含位于2个不同城市的5个用户,由于不同城市的用户间测试结果差异较大,导致AS2200内的SD偏大.若在上下文特征分析过程中加入“城市”特征后,对原AS进一步分组细化,得到结果如表 3所示.可见,综合更多客户端上下文特征有利于大幅度降低SD,从而使得预测结果更准确.

|
图 1 部分AS的响应时间SD分析 |
|
|
表 2 AS2200的响应时间分析 |
|
|
表 3 更新后的响应时间SD |
为验证方法的有效性,选取2种方法比较,方法1为文献[2]的混合预测方法,方法2为用户位置感知的预测方法[4],所提方法记为方法3.对实验数据集中服务的响应时间的SD进行了分析.
考虑到SD在[0, 1.5) 的服务QoS差异过小,而[10, ∞)区段内的服务QoS波动过大,为获得更有效的对比数据,实验重点对SD范围在1.5~10的服务进行测试.实验设定sth=0.70.
为评估预测方法的准确性,使用平均绝对误差(MAE,mean absolute error)指标度量.平均绝对误差值越小,预测准确度越高.平均绝对误差定义为
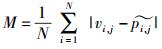
|
其中:vi, j为用户i观测到的服务j的真实QoS值,
首先,设定当前用户为新用户,在不同SD范围内,分12批次(每批递增500个服务)对数据集中全部5825个服务应用3种不同方法预测QoS,得到M的对比结果,如图 2所示.

|
图 2 不同方法的平均绝对误差 |
由图 2可知,因方法1为新用户预测Web服务QoS时采用用户平均和项目平均混合的方法,当历史用户反馈的QoS差异较大时,预测结果与真实值偏差较大;方法2在预测过程中主要参考同一个AS中的历史用户的反馈数据,为提高实验中方法2的预测准确度,特选取至少包含4个用户的AS测试;方法3(所提方法)不仅考虑了客户端的AS特征,还综合了用户的“国家—城市—区域”3级位置特征等,从而获得最佳的预测精度.
为验证方法3的综合预测效果,接下来测试方法3在sth取不同值时获得的预测结果与其他方法的对比,sth取值为0.7时的实验结果如图 3所示.由图 3可知,当sth取值0.7时,在多数情况下可获得足够数量的与当前用户具有相似上下文特征的历史用户,由于这些用户提供的数据的参考价值更高,方法3的综合预测效果要优于其他2种方法.而当sth取值为0.8甚至更高时,由于相似历史用户数量不足,方法3退化为使用协同过滤算法预测QoS.因此,方法3的预测效果与方法1类似.

|
图 3 sth取值为0.7时的平均绝对误差 |
为验证历史数据矩阵在不同稀疏度情况下的预测效果,以响应时间SD在[1.5, 3) 范围内的2007个服务为实验对象,设定稀疏度由2%逐步升至20%,对比3种方法的预测结果,如图 4所示.由图 4可知,在矩阵密度较低时,各方法的预测精度均不理想.因缺乏足够的训练数据,方法1的预测准确度最低.随着更多用户反馈QoS数据,达到20%的密度时获得的预测结果才较为理想.由于方法2和方法3分别从AS特征和上下文综合特征的角度提取高价值的参考数据,因而它们获得的预测精度明显高于方法1.但与其他应用协同过滤的QoS预测方法类似,为进一步提高预测精度,方法3也需要激励更多历史用户反馈其体验到的QoS值.

|
图 4 不同矩阵密度情况下的平均绝对误差 |
提出了一种客户端上下文感知的Web服务QoS预测方法,该方法从用户的上下文特征分析入手,基于相似度结果识别可为当前用户提供高价值参考数据的特征共同体.当相似用户数量不足时,结合协同过滤技术预测QoS.在相似用户数量足够情况下,以上下文特征加权融合方法预测Web服务的QoS.基于真实数据集的实验对比分析表明,所提方法可有效解决“新用户问题”,并有效提高Web服务QoS预测的精度.
| [1] | Rosaci D, Sarne G M L. Recommending multimedia web services in a multi-device environment[J].Information Systems, 2013, 38(6): 198–212. |
| [2] | Zheng Zibin, Lyu M R. Collaborative reliability prediction for service-oriented systems[C]// 2010 ACM/IEEE 32nd International Conference on Software Engineering (ICSE 2010). Cape Town: IEEE Press, 2010: 35-44. |
| [3] | Yin Jianwei, Lo Wei, Deng Shuiguang, et al. Colbar: a collaborative location-based regularization framework for QoS prediction[J].Information Sciences, 2014, 265: 68–84. doi: 10.1016/j.ins.2013.12.007 |
| [4] |
唐明董, 姜叶春, 刘建勋. 用户位置感知的Web服务QoS预测方法[J]. 小型微型计算机系统, 2012, 33(12): 2664–2668.
Tang Mingdong, Jiang Yechun, Liu Jianxun. User location-aware web services QoS prediction[J].Journal of Chinese Computer Systems, 2012, 33(12): 2664–2668. doi: 10.3969/j.issn.1000-1220.2012.12.019 |
| [5] | Chen Xi, Liu Xudong, Huang Zicheng, et al. RegionKNN: a scalable hybrid collaborative filtering algorithm for personalized web service recommendation[C]// 2010 IEEE 8th International Conference on Web Services (ICWS 2010). Miami: IEEE Press, 2010: 9-16. |
| [6] | Ahmed W, Wu Yongwei, Zheng Weimin. Response time based optimal web service selection[J].IEEE Transactions on Parallel and Distributed Systems, 2015, 26(2): 551–561. doi: 10.1109/TPDS.2013.310 |
| [7] | Mikhailov L, Tsvetinov P. Evaluation of services using a fuzzy analytic hierarchy process[J].Applied Soft Computing, 2004, 5(1): 23–33. doi: 10.1016/j.asoc.2004.04.001 |