


2. 湖州师范学院 工学院, 浙江 湖州 313000
在低速率声码器中, 对激励信号的描述直接影响重建语音的质量.为了改善音质, 提出一种基于语音截止频率的声码器激励模型.该模型编码时通过语音截止频率将激励谱分成谐波和噪声2个子带, 谐波子带的激励谱幅度引入离散余弦变换变维模型进行描述, 语音截止频率进行4 bit非线性量化.解码时将恢复出的谐波子带激励谱幅度进行傅里叶反变换, 噪声子带则由白噪声进行以语音截止频率为阻带截止频率的高通滤波, 最后由谐波子带和噪声子带叠加出激励.实验结果表明, 该模型提高了全带激励谱幅度和谐波噪声成分的描述精度, 可使重建语音的音质得以明显改善, 主客观指标更优, 对男声更为突出.
2. School of Engineering, Huzhou University, Zhejiang Huzhou 313000, China
A vocoder excitation model based on voicing cut-off frequency(VCO) was presented. In encoding part, the excitation spectrum was divided into two distinct spectral bands by VCO: harmonic sub-band and noise sub-band, the model of variable dimension through discrete cosine transform was used to express the excitation spectral parameter of harmonic sub-band, and VCO was quantized through 4bits nonlinear scalar quantization. In decoding part, the recovered excitation spectral parameter of harmonic sub-band was inversely Fourier transformed, the noise sub-band was obtained by the white noise pass through a high pass filter which used the VCO as the stop-band cut-off frequency, harmonic sub-band and noise sub-band were superimposed to get the excitation. The model greatly improves the description precision of the entire spectral envelope and harmonic plus noise components. With better subjective and objective indicators, especially for male's speech, the reconstructed speech shows more natural.
低速率声码器的基础是线性预测技术,通过求解线性预测方程可以获取声道参数和激励参数,其中激励参数的描述很大程度上影响合成语音的自然度.最简单的激励参数描述模型是将语音分成清浊2种,分别以脉冲串和高斯白噪声作为激励.该激励模型在浊音段有很强的周期性,听感上有很强的机器声.针对该缺点,Mccree等[1]提出了多带混合激励的建模方法.通过该方法建立的模型具有较好的自然度和容忍环境噪声的能力.前10阶模型在多带混合模型的基础上对激励谱幅度进行描述,进一步改善了语音在低频部分的音质.两级模型[2]补偿了激励谱幅度原始值与前10阶模型之间的误差,但其在补偿误差时对全带误差进行维数转换的方法过于粗糙,并未完全解决全带谱幅度形状差异过大问题.离散余弦变换(DCT, discrete cosine transform)变维(DCT_M)模型[3]采用DCT将变长矢量转化为固定的M维,很好地解决了维数转换的过于粗糙问题,但激励部分编码比特增加过多并存在信息冗余.
通过大量语谱图观察可知,一般语音具有从低频谐波逐渐过渡为高频噪声的特性.在语音谐波/噪声模型中,通过语音截止频率(VCO, voicing cut-off frequency)将语音分为低频谐波和高频噪声2个子带,其中高频噪声子带谱幅度包络趋于平坦,不需要描述[4]. Wen等[5]提出将VCO的思想应用于低速率声码器中,取得了较好的合成音质,但缺少进一步的机理分析.
针对DCT_M模型的不足,结合基于VCO的谐波/噪声模型思想,笔者提出基于VCO和DCT_M(VDCT_M)声码器激励模型.首先通过残差信号提取出VCO值并平滑,然后在谐波数目概率分布分析的基础上对VCO值进行4 bit非线性量化,最后给出声码器激励模型.实验结果表明,在编码比特减少的情况下,该模型仍可以较好地保持激励谱幅度包络的形状和激励谱谐波/噪声成分特性,描述精度明显改善,主客观指标均明显优于其他模型.
1 基于残差信号的VCO轮廓估计由于语音谐波部分过渡为噪声部分往往是一个较为平缓的渐变过程,其受到基音周期和声道模型的影响而使过渡部分的频谱模糊不清,从而很难确定VCO值.为了减少基音周期的影响,基音周期采用Praat软件对原始语音信号s(n)进行分析,获得各帧基音频率p0,在基音周期估计过程中,定义帧长为320点,帧移为180点.为了减少声道模型的影响,对语音进行线性预测分析,通过残差信号进行VCO轮廓估计.
首先将语音信号s(n)通过一个线性预测滤波器,该滤波器的传递函数为
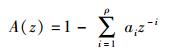
|
(1) |
其中:ρ为预测器阶数,ai(i=1, 2, …, ρ)为滤波器参数.得到其预测后的残差信号为
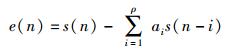
|
(2) |
通过残差信号e(n)进行VCO估计过程中,为了VCO估计的准确性,定义残差信号帧长为2倍当前基音周期长度,帧移为180点;并定义各帧VCO的估计值为hp0Hz,其中h为通过算法获得的该帧估计出的谐波数目.假设e(i)(i=1, 2, …, 2N)为当前帧的语音预测的残差信号,其中N为该帧的基音长度(N取整数),则e(i)的功率谱P(k)和归一化功率谱Pn(k)分别为[6-7]
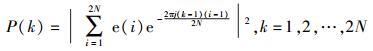
|
(3) |
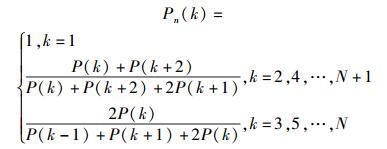
|
(4) |
由式(4) 可知,对于直流分量功率P(1) 的归一化函数恒设为1,即认为噪声能量为零,而对k≥2的谐波和噪声功率成分的归一化功率函数为一个关于谐波和平均噪声功率的比值.
Eh(j)定义为第j次谐波时累积谐波能量函数,即对功率谱的0~jp0Hz的谐波程度的测量:
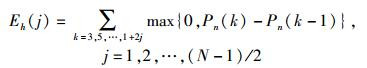
|
(5) |
Ea(j)定义为第j次谐波时累积噪声能量函数,即对功率谱的jp0Hz至结束的噪声程度的测量:
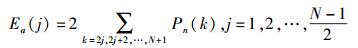
|
(6) |
E(j)定义为累积谐波和噪声能量函数,由累积谐波能量函数和累积噪声能量函数组成:
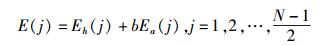
|
(7) |
其中:b为Ea(j)的贡献系数,一般设在0.2~0.6之间,文中取0.2. VCO值fvco则定义为E(j)取得全局最大值时所对应的第j次谐波的频率:
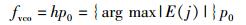
|
(8) |
语音具有短时平稳性,VCO曲线应该具有平滑的特性,因此必须对各帧VCO进行平滑操作,采用文献[7]的形态滤波算法对VCO曲线进行平滑.
2 VCO量化基于残差信号的VCO轮廓估计DCT_M模型和低速率声码器均采用多带激励,全带激励谱被划分为5个子带,用4 bit描述第2至第5子带的谐波/噪声成分.引入VCO思想,通过VCO将全带激励谱分为2个子带,为了实验公平性,也用4 bit描述2个子带的谐波/噪声成分,即用4 bit对VCO进行量化.
VCO的动态范围为60~4 000 Hz,4 bit直接量化将产生严重失真,而已知谐波数目h等于VCO除以p0,其中p0的动态范围为50~500 Hz, 故可知h理论上的动态范围为1~80.为了进一步减少量化失真,对h值进行了统计,实验数据来源于PKU-SRSC语音数据库.男声文件10个,女声文件10个,每个文件时长210 s.
图 1所示为h的概率分布情况,分男声、女声和全体(不区分男女声)3种情况.男声h的动态范围在1~30的概率达到98.92%,女声h的动态范围在1~20的概率达到99.17%,全体h的动态范围在1~30的概率达到99.53%.根据统计结果,对全体h分成16个近似等概率组合. 表 1为全体谐波数目的量化表,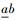
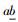

|
图 1 谐波数目概率分类 |
|
|
表 1 谐波数目量化表(全体) |

编码时,一方面通过残差信号估计出VCO轮廓,然后对VCO进行4 bit非线性量化;另一方面,依据残差信号和VCO轮廓值,进行DCT,即将残差信号进行傅里叶变换,得到全带激励谱.依据VCO将全带激励谱分成谐波和噪声2个子带,谐波子带的激励谱幅度通过DCT将变长的谱幅度矢量转为固定长度.最后再对M维矢量进行12 bit矢量量化.
解码时,一方面对定M维矢量进行DCT反变换恢复出谐波子带激励谱幅度,然后进行傅里叶反变换;另一方面,反量化恢复出VCO值,噪声子带则由白噪声进行以VCO为阻带截止频率的高通滤波.最后由谐波子带和噪声子带叠加出激励.
3.1 编码模型设e(i)(i=1, 2, …, 2N)为一帧的语音预测的残差信号,其中N为该帧的基音长度(N取整数).对e(i)进行傅里叶变换得

|
图 2 VDCT_M声码器模型流程 |
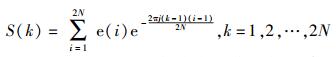
|
(9) |
由此得到S(k)对应谐波子带的激励谱幅度矢量x,其维数即为h,随语音帧的不同而变化.编码时用DCT将x转为固定M维矢量xM,再经12 bit矢量量化后传输.设Ah×M为DCT用到的维数转换矩阵.据xM=ATx可以得到定长矢量xM, A为
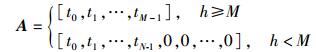
|
(10) |
其中tk为DCT正交变换的基:
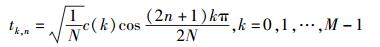
|
(11) |
其中:k=0时,c(k)=2;k为其他值时,c(k)=1[3].
3.2 解码模型反变换时,则通过解码得到VCO的谐波数目h,恢复出转换矩阵Bh×M.如果VCO传输无误的话,就有Bh×M=Ah×M,可以恢复出谐波子带激励谱幅度[3].
4 实验与分析4.1 3种模型的分析比较实验中采用帧长320点,帧移180点对语音进行分帧处理,设定VDCT_M模型和DCT_M模型的固定维数为M=15,通过对不同的种类的浊音全带激励谱幅度和谐波/噪声成分进行统计分析,实验结果能取得同样的效果,本实验中选择的是元音/a/的二帧.
1) 单帧全带激励谱幅度描述分析
图 3所示为前10阶、DCT_M和VDCT_M模型对全带激励谱幅度参数的描述比较,为了摒除不同量化措施带来的差异,归一化谱幅度全部采用模型值,不经过量化.

|
图 3 前10阶、DCT_M和VDCT_M模型的比较 |
图 3(a)所示为总谐波数N=25,提取的谐波数目h=14的一帧语音.从图 3(a)中可以看出,① DCT_M模型,由于需要将25维谐波幅度矢量DCT为15维矢量,压缩比过高而产生明显失真. ② VDCT_M模型,前14次谐波无任何失真,这是由于h≤15,由变长矢量定长化中的模式缩减引入的模型误差为0,可无损恢复;15~25次谐波幅度值围绕1上下小幅波动,VDCT_M模型用单位值1直接描述也优于DCT_M模型.
图 3(b)所示为N=30,h=17的一帧语音.从图 3(b)中可以看出,① VDCT_M模型,由于h>15,需要将17维谐波幅度矢量DCT为15维矢量,存在一定的模型误差,但仍能高精度恢复激励谱幅度包络;② DCT_M模型,将30维矢量DCT为15维,压缩比远远大于VDCT_M模型,恢复激励谱幅度包络存在较大失真.
2) 单帧恢复的激励谱幅度和谐波/噪声成分分析
为了分析3种模型的全带激励谱幅度和谐波/噪声成分的描述精确程度,取一帧残差信号(图 3(a)为同一帧),基音频率p0=146 Hz, 谐波数目h=14,子带强度V=[1 1 1 1 0],10阶谐波频率为1 460 Hz,fvco=2 044 Hz. 图 4所示为残差信号和3种模型合成的激励谱的比较.对于图 4可以从2个维度进行观察:① 从全带激励谱幅度的描述上看,VDCT_M的谱幅度包络描述与残差信号最接近;② 从谐波/噪声成分的描述上看,VDCT_M模型中,在第15次谐波,fvco=2 044 Hz之前频谱是明显的谐波成分,2 044~4 000 Hz则是明显的噪声成分,这和残差信号的谐波/噪声成分高度一致.总体上看,VDCT_M模型全带激励谱幅度和谐波/噪声成分的描述精确程度均优于DCT_M模型和前10阶模型.

|
图 4 合成的激励谱比较 |
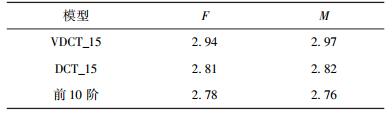
从PKU-SRSC和CASIA语音数据库随机抽取,总计250 MB语音文件.对依据VCO提取出来的激励谱幅度变长矢量进行DCT_M变换,转化为M=15的定长矢量后,采用LBG算法进行码本训练得到一级码本.采用该码本作为MELP2.4 kbit/s声码器中的激励谱幅度参数的码本,并对重建语音进行语音质量感知评价[8]测试,测试语音来源于PKU-SRSC数据库,形成女声(F)和男声(M)2组语音文件,持续时间各为420 s.
为了保证测试的公平性,对3种模型均采用一级矢量量化,谱幅度参数均用12 bit量化,其中VCO量化采用全体表,3种模型量化精度一致,结果如表 2所示.
|
|
表 2 语音质量感知评价比较 |
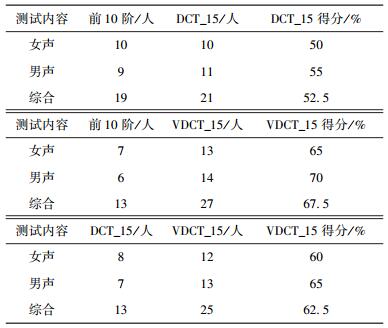
测试语句来自PKU-SRSC语音数据库的随机抽取,长度处理为20 s,包含男声和女声.选取20位测试者进行A/B听音测试,结果如表 3所示. 52.5%的测试者认为采用了DCT_15模型的声码器优于前10阶模型的合成语音,67.5%的测试者认为采用了VDCT_15模型的声码器优于前10阶模型的合成语音,65%的测试者认为采用了VDCT_15模型的声码器优于DCT_15模型的合成语音, 可见本模型能提升合成语音的主观听觉质量.
|
|
表 3 主观自然度A/B测试结果 |
1) 给出了基于残差信号的VCO轮廓估计算法.在此基础上通过VCO的谐波数目的统计分析表明,男声、女声和全体(不区分男女声)3种情况的谐波数目动态范围明显不同且均远小于理论上的动态范围,利用该结果可以提高VCO的4 bit非线性量化精度.
2) 提出用VDCT_M模型对全带激励谱进行描述.实验结果表明,VDCT_M模型对全带激励谱幅度和谐波/噪声成分的描述精度优于前10阶模型和DCT_M模型.在MELP2.4 kbit/s声码器中的主客观测试表明,VDCT_M声码器激励模型可改善合成语音的自然度,主客观指标均优于前10阶模型和DCT_M模型.
| [1] | Mccree A V, Barnwell Ⅲ T P. A mixed excitation LPC vocoder model for low bit rate speech coding[J].IEEE Transactions on Speech and Audio Processing, 1995, 3(4): 242–250. doi: 10.1109/89.397089 |
| [2] |
贺天宏, 张建伟, 崔慧娟, 等. 声码器激励参数的描述模型[J]. 电声技术, 2003(4): 52–55.
He Tianhong, Zhang Jianwei, Cui Huijuan, et al. The model for excitation parameter in low bit rate vocoders[J].Communication Electro Acoustics, 2003(4): 52–55. |
| [3] |
党晓妍, 唐昆. 低速率声码器激励参数的DCT_M模型[J]. 清华大学学报:自然科学版, 2007, 47(4): 578–580.
Dang Xiaoyan, Tang Kun. DCT_M model for the excitation parameter in low bit rate vocoders[J].Journal of Tsinghua University: Science and Technology, 2007, 47(4): 578–580. |
| [4] | Stylianou Y. Applying the harmonic plus noise model in concatenative speech synthesis[J].IEEE Transactions on Speech Audio Processing, 2001, 9(1): 21–29. doi: 10.1109/89.890068 |
| [5] | Wen Zhengqi, Tao Jianhua. Inverse filtering based harmonic plus noise excitation model for HMM-based speech synthesis[C]//12th Annual Conference of the International Speech Communication Association(ISCA). Florence, Itality: [s.n.], 2011: 1805-1808. |
| [6] | Hermus K, Hamme H V, Irhimeh S. Estimation of the voicing cut-off frequency contour based on a cumulative harmonicity score[J].IEEE Signal Processing Letters, 2007, 14(11): 820–823. doi: 10.1109/LSP.2007.898854 |
| [7] |
汤一彬, 张索非, 吴镇扬. 基于谐波和噪声能量改进的语音截止频率轮廓估计[J]. 声学学报, 2010, 35(3): 375–384.
Tang Yibin, Zhang Suofei, Wu Zhengyang. Improved estimation of the voicing cut-off frequency contour based on harmonic and aperiodic energies[J].Acta Acustica, 2010, 35(3): 375–384. |
| [8] |
张伟伟, 常永宇, 刘奕彤, 等. 中文环境下PESQ评价语音编解码器的性能研究[J]. 北京邮电大学学报, 2014, 37(3): 115–119.
Zhang Weiwei, Chang Yongyu, Liu Yitong, et al. Performance study of PESQ for speech codecs[J].Journal of Beijing University of Posts and Telecommunications, 2014, 37(3): 115–119. |