


2. 北京邮电大学 信息与通信工程学院, 北京 100876
提出了一种基于梅尔频率倒谱系数相关性的语音感知哈希内容认证算法.该算法提取分段语音的声纹梅尔频率倒谱系数作为感知特征.为提高算法的安全性, 算法利用伪随机序列作为密钥, 计算得到梅尔频率倒谱系数与伪随机之间的相关度, 最后量化相关值并加密生成感知哈希序列.语音认证过程中, 采用相似性度量函数来衡量哈希序列之间的距离, 同时与汉明距离方法进行了比较.仿真结果表明, 该算法对语音内容保持操作, 如重采样、MP3压缩等具有较好的鲁棒性, 相似性度量函数也对语音篡改检测定位具有较高的灵敏性.
2. School of Information and Communicaiton Engineering, Beijing University of Posts and Telecommunications, Beijing 100876, China
A perceptual hashing algorithm for speech content authentication based on correlation coefficient of mel-frequency cepstrum coefficients (MFCC) was proposed. The MFCC of the framed speech signal is extracted as perceptual feature. The correlation coefficients between MFCC and a pseudo-random sequence, which is generated by keys for security, were calculated. Hash sequence is generated by quantifying the correlation coefficients and then scrambling. For audio authentication procedure, a new method, similarity metric, was used to measure the distance of hashes, which is compared with the hamming distance method. Simulations show that the algorithm is robust against content-preserving manipulations such as re-sampling, MP3 compression, and so on. It is very sensitive to tamper of speech by similarity metric.
随着信息化技术、计算机网络的应用以及多媒体处理技术的快速发展,语音作为传递信息最便捷的多媒体形式之一,在人类交流中发挥了越来越重要的作用.同时,随着现代音频编辑处理工具的多样化、简单化,对语音内容的改动变得十分容易便捷,对语音的真实性和完整性认证显得特别重要.常用于多媒体内容的真实性和完整性认证技术手段是哈希技术.传统的哈希技术因其对数据改动的敏感性不适合用于对语音的内容认证,基于感知的语音哈希技术[1]被提出.感知哈希具有出色的鲁棒性、区分性、可靠的安全性,成为多媒体信息管理和信息安全领域不可或缺的一项新兴技术.
感知哈希技术最初应用在图像认证领域,在图像认证中应用广泛且成熟[2-4].近年来,针对音频的感知哈希研究逐渐增多[5-8],但是针对语音认证,感知哈希的应用研究还较少. 2009年,Jiao等[5]提出了一种基于感知哈希的语音内容认证算法,该方案提取语音线谱对作为感知特征,其哈希构造依赖于密钥,算法具有较高的抗碰撞性和安全性,对保持内容不变的操作具有良好的鲁棒性,对于恶意攻击能正确检测并在一定程度上对攻击位置进行定位,但是定位精度不高. Chen等[6]提出了一个鲁棒语音哈希算法,该算法提取线性预测系数为感知特征,用非负矩阵分解对特征矩阵降维,从而构造哈希序列,但是哈希函数的安全性却没有涉及;Chen等[7]还提出了基于线性预测倒谱系数和矢量量化的语音哈希算法;Nouri等[8]提出了基于离散小波变换的线谱对系数的语音认证算法.这些算法都能够检测恶意篡改,然而效率却不是很高,也不能实现精确篡改定位.针对上述问题,提出一种基于梅尔频率倒谱系数(MFCC,Mel-frequency cepstrum coefficients)相关性的高效率高安全性语音认证算法,先计算每帧的MFCC系数,并计算每帧系数与随机向量的相关值,以相关系数为感知特征量化后得到哈希序列,最后在语音认证过程中采用汉明距离和相似性度量函数技术分别计算哈希序列之间的相似性.
1 语音感知哈希生成算法基于MFCC相关系数的语音感知哈希生成过程如图 1所示.

|
图 1 语音感知哈希生成框图 |
梅尔频率倒谱系数是语音识别技术的重要特征参数之一.与普通的倒谱分析不同,MFCC的分析主要着眼于人耳的听觉特性.因为人耳所听到的声音高低与声音的频率并不是线性的关系,用梅尔频率尺度则更符合人耳的听觉特性.梅尔频率与实际频率的具体关系可用下式表示
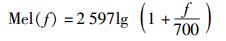
|
(1) |
其中f为频率.提取MFCC的过程如图 2所示.

|
图 2 MFCC提取框图 |
具体提取流程如下:
1) 对输入的语音信号进行分帧、加窗,然后作离散傅里叶变换,获得频谱分布信息.
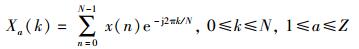
|
(2) |
其中:x(n)为输入的语音信号,N为傅里叶变换的点数,Z为总分帧数.
2) 将幅度谱|Xa(k)|通过M个梅尔滤波器组Hm(k),计算每个滤波器输出的对数为
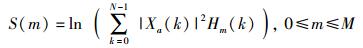
|
(3) |
3) 经离散余弦变换得到MFCC系数:

|
(4) |
经上述MFCC特征提取过程,将得到一个大小为M×Z的特征矩阵,记为A(i, j),1≤i≤M,1≤j≤Z.定义一个基于密钥K1生成的伪随机向量R=[r1, r2, …, rM]T作为参考向量.假设I是特征矩阵中某一列向量,I和R的相关度描述为
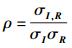
|
(5) |
其中:σI和σR分别为I和R的标准差,σI, R为协方差
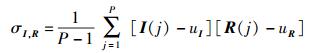
|
(6) |
其中:P为I成员总数,I(j)和R(j)分别为向量I和R中第j个成员,uI和uR为均值.特别地,当σI和σR都为0时,ρ=1;当σI和σR不全为0时,ρ=0.
1.3 哈希构造首先,将特征提取过程得到的相关系数ρi映射到ci∈[0,1]
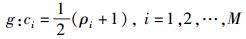
|
(7) |
为了减少存储量,C={ci|i=1, 2, …, M}进一步分为L=「M/T

|
(8) |
序列h1, h2, …, hL采用非均匀量化:
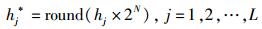
|
(9) |
其中,round(·)即就近取整函数.因此,每个hj*可以用Q比特表示,即hj*=[bQ … b1 b0]j,bi∈{0, 1}.顺次链接,得到哈希序列,即
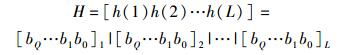
|
(10) |
为了提高算法的安全性,采用置乱加密算法对哈希序列进行处理.首先基于K2生成伪随机序列R=[r1, r2, …, rL],并按照大小重新排列,得到ra1≤ra2≤…≤raL,加密后的序列为
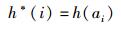
|
(11) |
在认证过程中,采用距离函数度量语音的相似性,通常采用归一化汉明距离来度量两段哈希的相似性,归一化汉明距离定义为
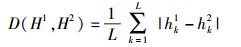
|
(12) |
其中,H1和H2分别为两段哈希序列,L为长度.
假设阈值为τ(一般取0~0.3的值),如果两两语音D≤τ, 则认为他们是同一语音并且没有被篡改,认证通过;否则,认证不通过.为了评估语音认证算法的性能,定义误识率函数(FAR,false accept rate),即
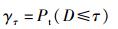
|
(13) |
其中Pt(·)为概率. τ越小,误识率越低,哈希可区分性越高,认证准确率越好.
相似性度量函数的定义如下:
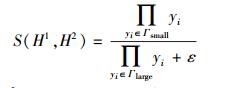
|
(14) |
其中:H1和H2分别为两段哈希序列,ε为一个接近零值的常数,如0.01,yi定义为
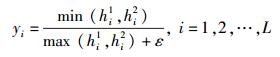
|
(15) |
hi1和hi2分别是从哈希序列H1和H2用密钥K2解密得出值,Γsmall和Γlarge分别是yi中最小的p个值和最大的p个值,S∈[0, 1). S值越靠近1,则音频相似性越高,反之,则越低.假设阈值为τs,如果两两语音S > τs, 则认为他们是同一语音并且没有被篡改,认证通过;否则,认证不通过.此时,误识率函数定义为
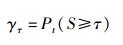
|
(16) |
为验证算法的鲁棒性、抗碰撞能力、密钥依赖性及篡改检测定位能力,实验中采用美国之音(VOA, voice of American)音频中不同内容的男女语音段作为初始数据,处理后得到采样频率为16 kHz、精度为16 bit、长度为3 s的wav格式语音段,作为测试数据库.
实验主要参数设置如下:LA=298, M=13, T=2, m=3, N=6.
3.1 抗碰撞能力取120段语音(不同说话者,不同内容)作为测试语音,并作如下仿真:
1) 根据式(14) 分别计算两两哈希序列之间相似性度量函数S值(根据实验样本数,S共7 140个值),得其概率分布直方图如图 3(a)所示.

|
图 3 基于相似性度量值得抗碰撞能力测试 |
由图 3(a)可以看出,假设结果可近似拟合为高斯分布,则其中数学期望uS=0.189 9和标准差σS=0.050 8,其理论上误识率FAR由下式给出:
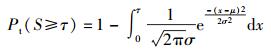
|
(17) |
FAR反映感知哈希认证算法的可区分性,阈值τ越大,FAR越小,可区分性越高,抗碰撞能力越高;反之算法可区分性越低. 图 3(b)反映了理论计算得到的FAR与实验得到的FAR对比.由图 3(b)可以看出理论与实际计算得到的FAR曲线,由此可以看出,在阈值τ < 0.4时,实验中得到的FAR曲线接近理论值.
2) 由式(12) 计算两两哈希之间的归一化汉明距离D值,其概率分布直方图如图 4(a)所示.假设结果符合高斯分布,则其中数学期望uD=0.474 3和标准差σD=0.044 7,其理论上误识率FAR为

|
(18) |

|
图 4 汉明距离用于抗碰撞能力测试结果 |
FAR反映算法的可区分性,与仿真相反,阈值τ越大,FAR越大,可区分性越低,抗碰撞能力越低. 图 4(b)反映了理论计算得到的FAR与实验得到的FAR对比.当τ < 0.3,语音段可以完全区分.
从上述分析可以看出,用相似性度量函数计算哈希之间的距离更贴合理论值,即哈希认证算法具有更好的可区分性.
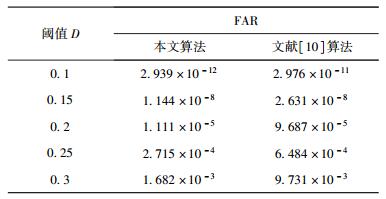
表 1显示了用汉明距离认证时,相同阈值下,提出算法与文献[10]中(取相等的哈希长度,即取分帧数为298) 算法测试的FAR值,对比可以看出,所提算法FAR值更小,表明其抗碰撞能力越强.
|
|
表 1 FAR值比较 |
为验证语音认证算法的感知鲁棒性,采用一些正常的不改变语音语义的处理和扰动操作,如重采样、MP3压缩、加噪、重量化、回声等常规信号处理操作对语音进行处理,具体信号处理操作及其对应的参数设置如表 2所示.实验时计算处理后的语音得到哈希与原始哈希相似性度量函数和汉明距离.由表 2可知,所有S值均大于0.4.结合抗碰撞试验,τs可设为0.4,τD可设为0.3,同时,由对比文献[10]可知,相同哈希长度时,提出算法在对抗某些音频信号处理操作,如低通滤波、加噪声等操作时具有更好的鲁棒性.
|
|
表 2 各类攻击及相似性度量值S |

由于感知哈希的产生必须依赖于密钥,即要求不同密钥,算法得出的哈希将不同.笔者基于一组密钥(K1, K2)提高算法的安全性.其中K2用于哈希序列加密存储,保证存储的安全性. K1用在哈希的生成过程中,不同密钥生成的哈希认证序列将不同,从而保证算法的安全性.
3.4 篡改检测为验证该算法对篡改定位的精度,随机选取了一条6 s语音段,内容为“Joshua Okello and two other students at Makerere University”,并对其随机地进行约1 600个采样点的多处替换,如图 5所示,篡改没有改变语音内容.分别用相似性度量和汉明距离测试,得到S=0.206 5和D=0.021 1.若τ分别设为0.5和0.3,则用相似性度量函数能检测出篡改而汉明距离则不能.

|
图 5 篡改检测及定位 |
提出了一种可定位篡改的,基于感知哈希的语音内容认证算法.该算法利用与语音识别相关的声纹特征MFCC系数作为感知特征来构造哈希值,进行语义级的感知内容认证,并分别利用相似性度量函数和汉明距离对篡改检测和定位.借助MFCC相关系数的鲁棒性,算法能有效地抵抗常规操作如重采样、MP3压缩等,相较于汉明距离,相似性度量函数能够敏感地检测出语音的微小改动以及对局部小范围篡改进行精确定位,有效验证语音内容的完整性.从实验中可以看出,提出算法在抗碰撞性上比文献[10]的算法好,对低通滤波、加噪声等常规信号处理上具有较好的鲁棒性,在安全性方面也得到加强,算法不足是对重采样、重量化等常规操作的鲁棒性较差,算法的效率问题也有待进一步提高.
| [1] |
牛夏牧, 焦玉华. 感知哈希综述[J]. 电子学报, 2008, 36(7): 1405–1411.
Niu Xiamu, Jiao Yuhua. An overview of perceptual Hashing[J].Acta Electronic Sinica, 2008, 36(7): 1405–1411. |
| [2] | Tang Zhenjun, Zhang Xianquan, Huang Liyan, et al. Robust image Hashing using ring-based entropies[J].Signal Processing, 2013, 93(7): 2061–2069. doi: 10.1016/j.sigpro.2013.01.008 |
| [3] | Li Yuenan, Lu Zheming, Zhu Ce, et al. Robust image Hashing based on random Gabor filtering and dithered lattice vector quantization[J].Image Processing, IEEE Transactions on, 2012, 21(4): 1963–1980. doi: 10.1109/TIP.2011.2171698 |
| [4] |
陈慧婷, 覃团发, 唐振华, 等. 综合纹理统计模型与全局主颜色的图像检索方法[J]. 北京邮电大学学报, 2011, 34(s1): 100–103.
Chen Huiting, Qin Tuanfa, Tang Zhenhua, et al. A method of image retrivals based on texture probability statistics and global dominant color[J].Journal of Beijing University of Posts and Telecommunications, 2011, 34(s1): 100–103. |
| [5] | Jiao Yuhua, Ji Liping, Niu Xiamu. Robust speech Hashing for content authentication[J].Signal Processing Letters, IEEE, 2009, 16(9): 818–821. doi: 10.1109/LSP.2009.2025827 |
| [6] | Chen Ning, Wan Wanggen. Robust speech Hash function[J].ETRI Journal, 2010, 32(2): 345–347. doi: 10.4218/etrij.10.0209.0309 |
| [7] | Chen Ning, Wan Wanggen. Speech Hashing algorithm based on short-time stability [C] //Artificial Neural Networks-ICANN 2009. Cyprus: Artificial Neural Networks, 2009: 426-434. |
| [8] | Nouri M, Farhangian N. Conceptual authentication speech hashing base upon hypotr-ochoid graph [C]//Telecommunications (IST), Sixth International Symposium on. Tehran: IEEE, 2012: 1136-1141. |
| [9] | Tang Zhenjun, Wang Shuozhong, Zhang Xinpeng, et al. Structural feature-based image hashing and similarity metric for tampering detection[J].Fundamenta Informaticae, 2011, 106(1): 75–91. |
| [10] | Chen Ning, Wan Wanggen. Robust audio hashing based on discrete-wavelet-transform and non-negative matrix factorization[J].Communications IET, 2010, 4(14): 1722–1731. doi: 10.1049/iet-com.2009.0749 |