


2. 北京邮电大学 泛网无线通信教育部重点实验室, 北京 100876
提出一种基于内存共享机制数据中心进程优化调度策略, 并基于软件定义网络(SDN)架构建立数据中心负载模型及内存节点能耗模型, 给出2个用于降低内存能耗的启发式进程调度算法.这2个算法以实际内存节点为研究对象, 在保证数据中心负载均衡的基础上, 通过合理进程调度实现内存共享率最大, 使得处于活动态的内存节点数最少, 从而达到数据中心内存能耗优化目的.仿真结果表明, 提出的启发式进程调度算法能有效降低内存能耗.
2. Key Laboratory of Universal Wireless Communications, Ministry of Education, Beijing University of Posts and Telecommunications, Beijing 100876, China
A new heuristic process scheduling strategy was proposed on the basis of a memory sharing mechanism. Based on software defined networking (SDN) architecture, A workload model and a memory energy consumption model were designed. Two heuristic process scheduling algorithms were designed to save the memory energy consumption. The algorithms come from physical memory nodes. The key idea of the above proposed algorithms is to achieve the largest sharing ratio of memory which assures workload balance through scheduling processes reasonably. The least number of active memory nodes means the least memory energy consumption of data center. Simulations verify that these strategies can reduce the energy consumption effectively.
移动互联网日臻成熟,用户应用及服务激增,用于处理用户业务的数据中心规模、数量日趋庞大,数据中心能耗问题日益严重[1]. IBM Bohrer等指出数据中心服务器利用率低是导致高能耗的一个主要原因. Ranganathan等对若干典型Web服务器负载进行研究,发现数据中心服务器的平均利用率在11%~50%[2].通过提高服务器利用率来降低能耗成为研究热点.内存条是数据中心服务器主要能耗部件之一.笔者选择内存能耗优化作为研究对象.
目前相关研究主要有:Kansal等以虚拟化为基础,对数据中心虚拟机进行能耗建模,包括CPU能耗模型、内存能耗模型及磁盘能耗模型,但内存能耗模型的有效性缺乏进一步研究验证[3];Guo等基于数据中心处理任务不均衡性,通过Lyapunoy最优化技术设计在线算法,该算法在能量存储与花费节省之间作折中,处理任务少时将多余电能通过电池存储,处理任务多时将存储电能释放,以数据中心整体为单位设计能耗模型,并基于此展开研究[4];Delaluz等基于内存节点4种模式(活动、待机、休眠、掉电)设计策略,通过监测内存使用情况及时转换内存节点模式,在不影响数据中心负载均衡前提下减少能耗,但是没有严格考虑模式间切换时机[5].
针对上述问题,笔者选择软件定义网络(SDN, software defined networking)作为网络架构,提出一种新型面向多处理器内核进程调度策略,在保证数据中心负载均衡的前提下,使得处于活动模式的内存节点最少.通过仿真实验,与先进先出(FIFO, first in first out)比较,该节能策略可有效节能28.16%.
1 系统建模建立负载模型及内存能耗模型.负载表示到达Openflow交换机待分配的数据包,这些数据包将会被Openflow交换机分给数据中心服务器.内存能耗模型是推导内存能耗优化策略的前提.
1.1 负载模型在时间段t内,负载到达Openflow交换机的速率为λi(t), i∈{1, 2, …, n}.设s为Openflow交换机模型,则S=(s1, s2, …, sm),si表示第i个Openflow交换机. Ai(t)表示t时刻到达Openflow交换机的第i个负载.通过网络控制器,到达Openflow交换机的负载被分配到数据中心服务器Sj.在t时刻,Openflow交换机sj工作负载到达速率定义为λij(t).这样,将会得到数据中心第i个服务器负载到达模型:
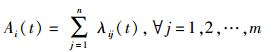
|
(1) |
设Pa表示t时刻活动模式下内存节点能耗功率,Ps表示t时刻待机模式下内存节点能耗功率,Na(t)表示t时刻处于活动模式下内存节点个数,P(t)表示t时刻数据中心所有内存节点的总能耗功率,将会得到
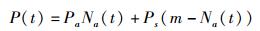
|
(2) |
其中m表示数据中心所有内存节点个数.
设E表示整个数据中心所有内存节点的总能耗,T表示整个数据中心总运行时间,将得到内存能耗模型:
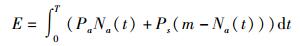
|
(3) |
将式(3) 展开合并,得到
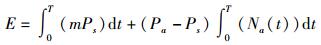
|
(4) |
节能策略核心思想:使数据中心所有内存节点总能耗最小,即E最小.由式(4) 可知,对于变量t而言,m、Ps全是常数. 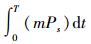
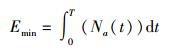
|
(5) |
由式(5) 可知,应力求在某一时刻使处于活动模式的内存节点数最少.但是Jang等已证明该问题是NP-complete问题,即该问题不能直接求解[6].因此,以式(5) 为理论依据,从另一角度出发设计进程调度算法,以便间接解决该问题.
2 节能方案及算法实现节能方案基于SDN架构,将节能算法植入网络控制器中,并通过Openflow交换机来控制整个数据中心服务器,对服务器中CPU内核上排队进程进行合理调度,使得处于活动模式的内存节点数最少,达到内存能耗优化目的.
2.1 节能方案研究发现,在保证数据中心负载均衡的前提下,处于活动模式的内存节点既可以被单个进程独占,也可以被多个进程共享,不论被单个进程独占还是被多个进程共享,处于活动模式的内存节点的能耗保持不变,且不影响CPU执行时间.因此可以从全局角度出发考虑内存使用策略,以此来提高内存共享率,在保证负载均衡的前提下使处于活动模式的内存节点数量最少,最终达到降低内存能耗的目的.节能方案架构如图 1所示.

|
图 1 节能方案架构 |
提出2种启发式进程调度算法:最大覆盖集优先改进(BCSFA,biggest cover set first advanced)算法及内存能耗进程优化算法(POAMEC,process optimal algorithm of memory energy consumption).这2种算法都能有效提高内存共享率,从而降低内存能耗.下面给出算法实现核心思想及伪代码.
1) 算法符号定义
定义数据中心为向量f=(f1, f2, …, fn),其中n表示数据中心所有服务器数量,fi表示第i台服务器.定义处理器内核为矩阵C=(cij)n×m,其中n表示服务器数量,m表示每台服务器中处理器内核数量,cij表示第i台服务器中第j个处理器内核.每个处理器都有自己的进程执行队列,定义该队列为p(cij)=(pij1, pij2, …, pijq),其中q表示某个处理器内核上等待进程数量,pijk表示第i台服务器第j个处理器内核进程队列中第k个进程,mem(pijk)表示处理器内核cij上被第k个进程使用的内存节点.
第t个时间片,在服务器fi上运行的进程定义为
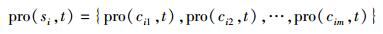
|
(6) |
其中pro(cij, t)为服务器fi的处理器内核cij上运行的进程.
2) FIFO算法与最大覆盖集优先(BCSF, biggest cover set first)算法
FIFO算法与BCSF算法作为对比算法.
FIFO算法不使用任何进程调度策略,执行过程中队列中进程顺序不发生改变.
BCSF算法的核心思想是找到t时刻某个处理器内核进程访问队列内存节点最大访问集,该集合可以被第(t-1) 时间片内的活动内存节点集合M(fi, t-1) 完全覆盖,或者被M(fi, t-1) 最大限度覆盖.
3) BCSFA算法
BCSFA算法通过比较mem(pro(cij, t))与M(fi, t-1) 来获取下一个待执行进程.
第i台服务器fi在t时刻的活动内存节点集合可表示为
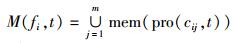
|
(7) |
由于在每个处理器内核中进程访问队列可以被调度,即重新排列,因此可得出
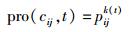
|
(8) |
其中pijk(t)为服务器fi上第j个处理器内核cij在t时刻运行第k个进程.每个进程在进程队列中的序号k与时刻t相关,故表示为k(t). k(t)的初始值与FIFO算法相同.经过进程调度,处理器内核cij得到新的进程队列顺序k(t).此时有
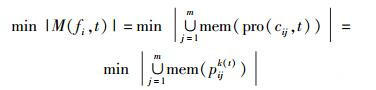
|
(9) |
BCSFA算法思想:得到处理器内核cij的最优进程队列顺序k(t),使得mem(pijk(t))重叠部分最大,从而使活动内存节点数量最少.
BCSFA算法的伪代码如下.
1.pro(t)←Ø
2. for i=1 to n
3. for j=1 to m
4. pro_else(fi, t)←pro(fi, t)-pro(ci, t)
5. pro(cij, t)←pij1
6. for k=2 to q
7. if (|mem(pijk∪pro_else(t))| < |mem(pro(cij, t)∪pro_else(t))|)
8. pro(cij, t)←pijk
9. end if
10. end for
11. pro(fi, t)←pro(ci, t)∪pro_else(fi, t)
12. end for
13. pro(t)←pro(t)∪pro(fi, t)
14. end for
4) POAMEC算法
BCSFA能获得单个处理器内核上内存节点的最大共享率.但当mem(pro(cij, t))与M(fi, t-1) 重叠少,而mem(pro(cij, t))与其他处理器内核进程访问队列重叠多时,该算法易陷入局部最优.当2个进程在各自处理器内核执行队列上的内存共享率最大时,最佳方案是将这2个进程分给不同处理器内核,且同时运行.使用全局优化算法将会获得更佳的节能效果,POAMEC算法就是从全局的角度出发进行进程调度.在t时刻,POAMEC算法为每一台服务器选择下一个要执行的进程,此时第i台服务器fi在t时刻的活动内存节点集合可表示为
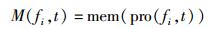
|
(10) |
在此算法中,各处理器内核之间的进程可以被调度,因此可以得出
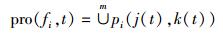
|
(11) |
其中pi(j(t), k(t))在t时刻表示服务器fi中运行的m个进程中第i个进程,此进程的选择不仅与进程队列序号k相关,还与进程所在CPU内核序号j相关.则
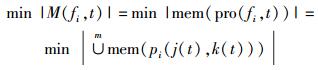
|
(12) |
POAMEC核心思想:得到t时刻服务器fi最优进程排列组合(j(t), k(t)),使得mem(pi(j(t), k(t)))重叠部分最大,从而使得活动态的内存节点数最少. POAMEC算法流程如图 2所示.

|
图 2 POAMEC算法流程 |
从活动内存节点个数对内存能耗影响、总内存节点数对内存能耗影响和排队进程数对内存能耗影响3个方面进行了仿真,并分析仿真实验结果.
3.1 仿真环境参数设置参数1 CPU时间片设为30 ms.在1个CPU时间片内,活动内存节点数为Na(t).
参数2 进程持续时间.进程持续时间对各算法间能耗无影响,所以仿真过程中各进程的运行时间保持一致.
仿真结果采用相对Emax表示所有内存节点均处于活动状态下的能量消耗.
3.2 活动内存节点数对内存能耗影响实际中,单进程的内存使用率不会达到100%.如果单进程所使用内存节点数等于总内存节点数,那么调度策略失效.因此,仿真进程所使用的内存节点数为1个至总内存节点数-1.在活动内存节点数不同的场景下,各算法节能效果对比如图 3所示.

|
图 3 活动内存节点数目场景下各算法节能效果对比 |
由图 3可知,随着进程使用内存节点(活动内存节点)数的增加,4种算法节能效果下降.当忽略处于待机模式的内存节点能耗时,可以得出
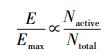
|
(13) |
其中:E为采用节能策略后的内存能耗,Emax 为不采用任何节能策略即所有内存节点均处于活动模式下的内存能耗,Nactive为活动内存节点数,Ntotal为总内存节点数.随着每个进程所使用平均内存节点数增加,Nactive递增,从而导致4种算法节能效果随进程使用内存节点数增加而递减.
由图 3易知,4种算法中POAMEC算法节能效果始终最好,原因在于POAMEC算法是从全局出发考虑每一轮进程所使用的内存节点,最大限度地提高内存节点共享率,减少处于活动态的内存节点个数,从而达到内存能耗优化目的.
3.3 总内存节点数对内存能耗影响在处理器内核数一定的条件下,依次对总内存节点数为8、16、24的情况进行仿真.
由图 4可知,无论总内存节点数是多少,在4种算法中POAMEC节能效果最好,BCSFA算法节能效果次优.随着总内存节点数的增加,4种算法的节能效果逐渐变好,原因在于每个算法运行过程中,Nactive没有改变,但Ntotal有提高.通过对进程使用2~4个内存节点这3种情况进行区分,可以看出,随着进程使用内存节点数增加,4种算法节能效果均有所下降,这间接验证了3.2节结论正确.

|
图 4 总内存节点数不同情况下各算法节能性能对比 |
由于BCSFA算法和POAMEC算法的运算复杂度与总进程数相关,所以需要针对不同进程排队队列长度(进程数目)进行仿真.
由图 5可知,各算法随进程总数增加,节能百分比呈缓慢上升趋势,但整体性能变化幅度不大,而且随着进程总数的增加,BCSFA和POAMEC算法运算次数会大大增加,因此排队队列中的进程总数不宜过大.

|
图 5 不同排队进程数场景下各算法节能性能对比 |
随着数据中心规模及数量的日益庞大,数据中心高能耗问题亟待解决.研究中发现,在保证数据中心负载均衡的前提下,处于活动模式的内存节点可被共享,而且内存节点共享率越高,节能效果越好.基于此,设计了2个启发式调度算法:BCSFA算法和POAMEC算法.这2个算法全部基于SDN架构,对CPU内核上排队的进程进行合理调度,达到提高内存节点共享率,并降低内存能耗的目的.仿真结果表明,BCSFA算法和POAMEC算法对降低内存能耗的效果明显.为进一步降低数据中心能耗,还应全面考虑CPU、内存、硬盘三者的协作问题,并将其作为下一步的研究目标.
| [1] | Deng Wei, Liu Fangming. Harnessing renewable energy in cloud datacenters: opportunities and challenges[J].IEEE Journals and Magazines, 2014, 28(1): 48–55. |
| [2] | Ranganathan P. Recipe for efficiency: principles of power aware computing[J].Communications of the ACM, 2010, 53(4): 60–67. doi: 10.1145/1721654 |
| [3] | Kansal A, Zhao Feng, Liu Jie, et al. Virtual machine power metering and provisioning[C]// Proceedings of the 1st ACM Symposium on Cloud Computing. [S.l.]: ACM, 2010: 39-50. |
| [4] | Guo Yuanxiong, Fang Yuguang. Electricity cost saving strategy in data centers by using energy storage[J].Parallel and Distributed Systems, IEEE Transactions on, 2013, 24(6): 1149–1160. doi: 10.1109/TPDS.2012.201 |
| [5] | Delaluz V, Sivasubramaniam A, Kandemir M, et al. Scheduler-based DRAM energy management [C]//Proceedings of the 39th Annual Design Automation Conference. [S.l.]: ACM, 2002: 697-702. |
| [6] | Jang J W, Jeon M, Kim H S, et al. NP-completeness of memory-aware virtual machine scheduling problem[R]. Technical Report CS-TR-2009-321, Computer Science Dept, KAIST, 2009. |