


面向资源有限的工业无线网络, 提出一种基于单查找表的快速高级加密标准(AES)的加密方法.对目前普遍采用的基于4张1 KB查找表方法的查找表进行压缩和优化, 构建了一张512 B的查找表, 减小了查找表的存储开销, 并有效降低GF(28)上乘法所产生的开销; 同时对轮加密公式进行了优化, 减少因查找表被压缩而引起的附加操作.实验结果显示, 相比4查找表法, 该方法降低了72%的存储开销, 但在时间开销和能量开销上均提高了43%;相比射频芯片上的硬件加速器, 该方法降低了55%的时间开销和61%的能量开销, 但存储开销为它的2.5倍.
A fast advanced encryption standard (AES) encryption method based on one lookup table for resource-constrained industrial wireless network was presented. A 512-Byte lookup table was constructed by compressing and optimizing the lookup table of the widely used method based on four 1KB lookup tables, It decreases the storage of lookup table and the overhead consumed by the GF(28) multiplications; the round function was optimized as well, decreasing the additional operations caused by the compressed lookup table. Experiment shows that this method saves 72% at the cost of 43% more computation time and power compared with the method based on four 1 KB lookup tables; and saves 55% computation time and 61% power at the cost of 2.5 folds storage consumption compared with the method based on the accelerator on radio chips.
由于具有较高的安全性和灵活性,AES[1]被众多工业网络标准[2-3]定义为其数据链路层的核心加密算法.但由于AES加密包含大量高计算复杂度的GF(28)乘法,使得其难以在资源受限、高实时性的工业无线网络中实施.如何提高AES的加密速度一直以来都是AES研究的一大热点.
目前针对AES加密的加速优化主要包含硬件加速器、指令集扩展和软件优化3类.虽然硬件加速器[4-5]和指令集扩展[6-7]可以获得很高加速比,但需要附加硬件支持,额外的能量开销和有限的可选器件使得它们并不适合在电池供电的工业无线网络中使用.而AES的软件优化主要是以利用多计算单元[8-9]或计算位宽[10]的并行提高AES加密吞吐率,但这些方法并不适用于以串行处理为主的网络帧处理.利用4张1KB查找表替代轮加密函数中的大部分操作[11]是目前AES加密速度优化中最为有效的方法,但由于引入了4张1KB查找表,对于资源受限的工业无线网络节点构成了不小负担.文献[12-14]分别面向不同资源受限系统提出了优化方案,但它们所获得的加速比并不能满足工业网络高实时性的需求.
对此,笔者提出了一种基于单查找表的低开销快速AES加密方法1-T.该方法不仅获得了与基于4查找表方法相当的加密速度,而且有效降低了查找表的存储开销,满足工业无线网络中低开销和高实时性的需求.由于目前网络帧加密中普遍采用密码块链接[15]和计数器[16]2种加密模式,只涉及AES加密过程,且一般采用128位长度密钥,因此将只对128位AES的加密过程优化进行详细介绍.
1 AES加密1.1 AES加密机制AES加密过程如图 1所示. KeyExpansion用于将输入密钥进行扩展,为每一轮加密提供密钥K.加密过程中需要对表示为4×4的状态矩阵的明文进行N(密钥长度为128位时N=10) 轮加密,其中前N-1轮包含字节替换(SubBytes)、行位移(ShiftRows)、列混淆(MixColumns)及密钥相加(AddRoundKey)4种操作,而最后一轮不包含列混合操作.

|

|
图 1 AES加密 |
分别表示每轮轮加密的状态输入和密钥,则轮加密函数可表示为
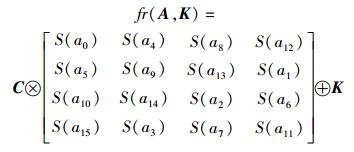
|
(1) |
其中: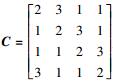
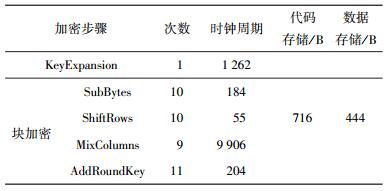
对AES算法采用C语言实现,在Keil上采用O3参数面向ARM CortexM3编译并获得开销评估.
1) 传统AES实现GF
传统AES实现直接计算GF(28)乘法,其实现开销如表 1所示,可以看到其存储开销很低,而时钟开销却很大,且大部分时钟开销来源于列混淆操作.这源于列混淆操作中大量的GF(28)乘法运算,这些乘法不被处理器支持,每次计算均要耗费大量周期.
|
|
表 1 GF的实现开销 |
2) 基于4查找表AES实现4-T
列混淆中的GF(28)乘法均是混淆矩阵中固定元素进行相乘,因此通过建立与这些特定元素相乘结果的查找表,即可将复杂的乘法运算转换为简单的查表操作.文献[11]建立了4张1 KB查找表:TS2113、TS3211、TS1321和TS1132,分别存储
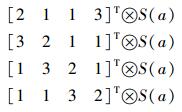
|
的结果,即S2113(a)、S3211(a)、S1321(a)和S1132(a),并将原来的按字节操作转换为按字(4 B)操作,其轮加密公式可以转换为
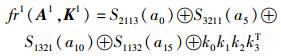
|
(2) |
式(2) 仅表示了新状态第1列的计算方法,其余列可以类似推出.可以统计到,由式(2) 进行轮加密计算只包含16次查表和16次异或计算. 4-T的实现开销如表 2所示,可以看到,4-T虽然有效地降低了加密的时钟开销,但引入的4张1 KB的查找表对资源受限的工业无线节点造成了巨大的负担.
|
|
表 2 4-T的实现开销 |

观察4-T中的4张查找表,其对应表项间可以通过相互循环移位获得,所以,只需要保存其中一张表再通过循环移位的方式获得其他3张表.由此查找表的存储开销可以由4 KB降为1 KB,而代价是需要进行额外的循环位移以获得另外3张查找表的结果.
而对于4-T中任意一张查找表,每个表项中包含了2个1⊗S(a),若将该表拆成TS1、TS2和TS3分别存储1⊗S(a)、2⊗S(a)和3⊗S(a)的结果S1(a)、S2(a)和S3(a),则查找表的存储开销可降为768 B.同时,在GF(28)乘法上有3⊗S(a)=1⊗S(a)⊕2⊗S(a),则只需保留TS1和TS2,查找表的存储开销降为512 B.
2.2 表结构优化虽然采用TS1和TS2可以有效降低存储开销,但存在2个问题.首先,采用TS1和TS2时,每轮轮加密中需要对状态中的每个元素进行2次查表访问,比4-T多了1倍,而对于一般的处理器而言,访存指令的时钟开销往往比其他计算指令要大;其次,由于查找结果均为字节结果,需要通过额外的计算先将这些字节结果合并为4-T的字结果,才能进行如式(2) 所示的计算.
但如果将S1(a)和S2(a)合并为一个半字(2 byte),构成一张2×256 B的查找表,则对S1(a)和S2(a)的查找可以在一次访存中获得,并保持查找表的存储开销不变.与此同时,查找结果是一个包含了S1(a)和S2(a)的半字,因此对于需要组成的字结果中有S1(a)和S2(a)相邻的情况,可以将所查找到的结果一次放置到相应的位置上,从而节省部分由组字引起的操作.
图 2所示为所要组成的各个字中包含S1(a)S2(a)(椭圆虚线框)和S2(a)S1(a)(矩形虚线框)排列的情况.直观上看,这些字中只出现了3次S1(a)S2(a)排列的情况,而没有S2(a)S1(a)排列出现.但由于S3(a)由S1(a)和S2(a)异或得到,所以S3(a)和它左边的S2(a)构成了一个S2(a)S1(a)排列,和它右边的S1(a)也构成了一个S2(a)S1(a)排列.由此可见,这些字中出现了6次S2(a)S1(a)排列,意味着采用S2(a)S1(a)排列可以比采用S1(a)S2(a)排列节省更多因组字产生的操作.由此构建存储S2(a)S1(a)的512 B查找表T21,其表项表示为S21(a).

|
图 2 字中包含S1(a)S2(a)和S2(a)S1(a)排列的情况 |
对于S2(a)和S1(a)的计算,有S2(a)=S21(a)≫8和S1(a)=S21(a)&0xff,且利用变量表示范围溢出,有S1(a)≪24=S21(a)≪24,则基于单查找表的AES实现1-T的轮加密公式可以表示为
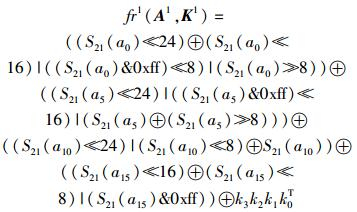
|
(3) |
对于状态中的其余列也可以由式(3) 类似计算得出. 表 3所示为1-T的轮加密操作开销.相较4-T,虽然1-T增加了提取字节结果、计算S3(a)及组合字结果等操作,但是其轮加密消耗周期仅比4-T多了不到1倍;同时,存储开销已经下降为4-T的27%.
|
|
表 3 1-T的实现开销 |

对4-T和1-T的轮加密函数进行分析,其操作可以分为5类:查表(LUT),通过异或计算S3(a)(Gen-S3),通过与和右移提取字节结果(Gen-Byte),通过或和左移将字节结果合并成字结果(Gen-Word),以及相加(ADD). 表 4所示为按不同操作对2种实现的轮加密公式进行时钟开销统计的结果,其中在ARM指令集中,访存需要2个时钟周期,其余计算指令需要1个时钟周期.
|
|
表 4 轮加密时钟开销对比(周期) |
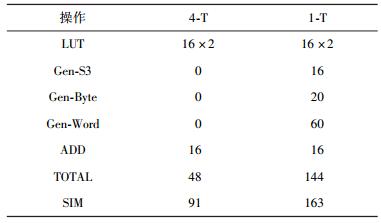
通过对比,4-T只包含LUT和ADD2种操作,而1-T则包含了上述的5种操作.对于LUT,4-T和1-T的开销相当.对于Gen-S3,4-T由于直接保存了S2113(a)等值,所以不需要计算S3(a);而1-T由于只保存了S1(a)和S2(a),所以需要对每个元素都计算一次S3(a).由于4-T保存的S2113(a)可直接用于相加计算,所以不需要进行Gen-Byte和Gen-Word操作. 1-T由于保存的是半字,需要进行Gen-Byte和Gen-Word操作. ADD为AES轮加密固有运算,所以2种方法的ADD次数相同.
由此,轮加密的时钟开销为
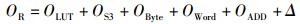
|
(4) |
其中:OLUT、OS3、OByte、OWord和OADD分别为LUT、Gen-S3、Gen-Byte、Gen-Word和ADD所消耗的时钟周期,其总和如表 4中TOTAL所示;Δ为修正值,用于修正实际消耗周期(SIM,由模拟器得到)和TOTAL之间的误差.误差主要来自于:① 计算公式只对轮加密公式中的操作进行统计,但密钥读取、状态读取/写回等操作并没有统计,而这部分操作也不是所要优化的目标;② 轮加密用函数封装,而函数调用产生的开销未统计到公式中;③ CortexM3指令集支持指令后缀,对于部分移位指令可以附加在其他指令的末端并行执行,从而不占用时钟周期.从TOTAL上看,1-T的轮加密函数虽然消耗的时钟周期为4-T的3倍,但是将函数调用的开销、状态读取/写回等因素考虑进去后,其实际消耗的时钟周期不到1-T的2倍.
3.2 实现开销对1-T实现开销的评估在ARM CortexM3处理器STM32F103RE上进行,工作主频为72 MHz.为了得到更客观的评估,评估将与GF、4-T及采用射频硬件加速的AES实现(HW)进行横向对比,射频芯片为AT86RF231ZU.评估的指标包含存储开销、时间开销及能量开销.
3.2.1 存储开销对比4种AES实现的存储开销(见图 3),HW由于将大部分计算都放在硬件上实现,其代码主要来自串行外设接口(SPI,serial peripheral interface)通信,所以其代码存储最小.由于1-T的轮加密函数较为复杂,所以其代码开销在4种实现中最大,但是也仅比最小的HW大29.3%.对于数据存储,4-T的4张1 KB查找表导致其数据存储达到4 540 B;GF仅存储一张256 B的S-box,数据存储只有444 B;1-T存储的是一张512 B的查找表,所以其数据存储开销也较小,比GF大57.6%,但只有4-T的15.4%.

|
图 3 存储开销对比 |
图 4所示为4种AES实现进行密钥扩展(KeyExpansion)及加密一个明文块(BlockEncrypt)所需时间的对比.可以看到,GF、4-T和1-T的密钥扩展所需时间相同,这是因为此3种实现方式的密钥扩展实现部分相同;而HW的密钥扩展时间则较大,源于通过SPI将密钥传输至CPU的时间.对于加密时间,虽然HW采用AES加速器进行加密,但是SPI通信时间过长使其落后于基于查表法的软件实现4-T和1-T. GF需要进行大量复杂的GF(28)乘法,因此远远大于其他3种方法. 4-T轮加密函数较为简单,所以其加密时间最小;而1-T由于轮加密相比4-T复杂,从而加密时间比4-T长43.5%.

|
图 4 时间开销对比 |
采用软件实现的GF、4-T和1-T的能量计算公式为
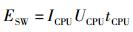
|
(5) |
其中:ICPU为只有CPU工作时的电流,UCPU为供电电压,tCPU为程序的运行时间. HW的开销主要分为2部分:一部分是数据通过SPI在CPU和射频芯片间传输时的开销;另一部分是射频中AES加速器进行加密而CPU在等待时的开销. HW能量计算公式为
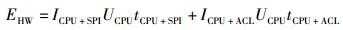
|
(6) |
其中:ICPU+SPI和tCPU+SPI分别为CPU和SPI都工作时的电流和时间,ICPU+ACL和tCPU+ACL分别为CPU和射频中AES模块都工作时的电流和时间.各种工作模式的电流如表 5所示,由此计算得到各种实现进行密钥扩展及加密一个明文块所需的能量,如图 5所示.可以看到,对于软件实现的3种方法,能量开销和时间开销成正比;而HW除了CPU的能量消耗,还有射频AES硬件和SPI通信的能量消耗,因此能量消耗为4-T的3.67倍,1-T的2.56倍.
|
|
表 5 不同工作模式下的电流 |


|
图 5 能量开销对比 |
针对资源受限的工业无线网络节点,提出了一种基于单查找表的快速AES加密算法1-T.相比传统采用4张1 KB查找表的方法4-T,1-T在查找表的存储上做了优化,其存储开销只有4-T的28%;同时通过对表结构的优化,1-T在ARM CortexM3平台上的时间开销和能量开销只比4-T高43%.相比直接进行GF(28)乘法的GF,1-T的时间开销和能量开销仅为其2.3%.相比采用硬件加速方案HW,1-T的时间开销和能量开销分别只有其45%和39%.综上,1-T在存储、时间及能量3种开销上做了折中,在不显著提高存储开销的前提下极大优化了时间和能量开销.
| [1] | Daemen J, Rijmen V. AES proposal: Rijndael[C]//First Advanced Encryption Standard (AES) Conference. US: NIST, 1998. |
| [2] | WG802.15.802.15.4—2006, IEEE standard for information technology—local and metropolitan area networks—specific requirements—Part 15.4: wireless medium access control (MAC) and physical layer (PHY) specifications for low rate wireless personal area networks (WPANs) [S]. IEEE, 2007. |
| [3] | ISA-100. 11a—2009, Wireless systems for industrial automation: process control and related applications[S]. ISA, 2009. |
| [4] | Rahimunnisa K, Karthigaikumar P, Kirubavathy J, et al. A 0.13-μm implementation of 5 Gb/s and 3-mW folded parallel architecture for AES algorithm[J].International Journal of Electronics, 2013(ahead-of-print): 1–12. |
| [5] | Wang Yi, Ha Yajun. A performance and area efficient ASIP for higher-order DPA-resistant AES[J].Emerging and Selected Topics in Circuits and Systems, IEEE Journal on, 2014, 4(2): 190–202. doi: 10.1109/JETCAS.2014.2315877 |
| [6] | Jeffrey. Intel® advanced encryption standard instructions (AES-NI) [EB/OL]. 2012[2013]. https: //software. intel. com/en-us/ articles/intel-advanced-encryption-standard-instructions-aes-ni. |
| [7] | Yumbul K, Sava E, Kocaba Ö, et al. Design and implementation of a versatile cryptographic unit for risc processors[J].Security and Communication Networks, 2014, 7(1): 36–52. doi: 10.1002/sec.555 |
| [8] | Liu Bin, Baas B M. Parallel AES encryption engines for many-core processor arrays[J].Computers, IEEE Transactions on, 2013, 62(3): 536–547. doi: 10.1109/TC.2011.251 |
| [9] | Schneider, T, Von Maurich, I, Guneysu, T. Efficient implementation of cryptographic primitives on the GA144 multi-core architecture[C]//Application-Specific Systems, Architectures and Processors (ASAP), 2013 IEEE 24th International Conference on. US: IEEE, 2013: 67-74. |
| [10] | Rebeiro C, Selvakumar D, Devi A S L. Bitslice implementation of AES[C]//5th International Conference, CANS 2006. Germany: Springer Berlin Heidelberg, 2006: 203-212. |
| [11] | Gladman B. A specification for Rijndael, the AES algorithm[EB/OL]. 2001[2013]. http://fp.gladman.plus.com/cryptography_technology/rijndael/aes.spec.311.pdf. |
| [12] | Bertoni G, Breveglieri L, Fragneto P, et al. Efficient software implementation of AES on 32-bit platforms[C]//Cryptographic Hardware and Embedded Systems-CHES 2002. Germany: Springer Berlin Heidelberg, 2003: 159-171. |
| [13] | Atasu K, Breveglieri L, Macchetti M. Efficient AES implementations for ARM based platforms[C]//Proceedings of the 2004 ACM Symposium on Applied Computing. US: ACM, 2004: 841-845. |
| [14] | Babu M R, Reddy A R. Optimization of memory for AES Rijndeal algorithm implementation on embedded system[J].IJCSNS, 2013, 13(9): 105. |
| [15] | Bellare M, Kilian J, Rogaway P. The security of cipher block chaining[C]//Advances in Cryptology—CRYPTO'94. Germany: Springer Berlin Heidelberg, 1994: 341-358. |
| [16] | Lipmaa H, Wagner D, Rogaway P. Comments to NIST concerning AES modes of operation: CTR-mode encryption[C]//Symmetric Key Block Cipher Modes of Operation Workshop. US: National Institute of Science and Technology, 2000. |