


面向英语文章的词性标注是对英语文章实现自动批改的基础, 虽然研究者对英语词性标注做了大量有益的研究, 但是大多数的研究都面向英语为第一语言的用户, 而面向英语为第二语言用户的相关研究则很少.为此, 对以英语为第二语言用户的英语文章进行了人工标注, 在此基础上提出了一种面向英语文章的词性标注算法, 融合了词聚类、无标语料统计信息、单词发音等特征.实验结果表明, 该算法能有效提高词性标注性能, 标注正确率从94.49%可提高到97.07%.
Part-of-speech tagging for Chinese English learner language is the base of automated essay scoring system. Much of fruitful part-of-speech tagging researches researchers was done, however, most of them are focused on the English essays written by native speaker, there is no research about essays of Chinese English learner. A corpus of Chinese English learner essay are annotated, and a part-of-speech tagging algorithm for Chinese English learner language is presented. This algorithm uses rich features, such as unsupervised word clusters, unsupervised tag dictionary and phonetic normalization. Based on these rich features, the system outperforms the state-of-art tagging on the corpus, and the tagging accuracy is raised from 94.49% to 97.07%.
词性标注,即在给定句子中判断每个词的语法范畴,确定词性.研究者对英语词性标注的研究做了大量有益的工作,出现了许多优秀词性标注系统,标注正确率已经达到97%~98%[1],达到了人们对词性自动标注的期望,词性标注一度被认为是一个“已经解决了”的问题.然而,将词性标注系统应用到另一种新文本时,标注正确率会显著下降[2].大部分的词性标注系统是基于英语官方的新闻文章进行训练的,如宾州树库(来源于华尔街日报语料[3]).由于英语文章中常出现拼写错误、泊来词、专有名词、臆造词和其他未知语法错误,故将这些优秀的词性标注系统应用到英语文章上时会出现许多问题.
张雷刚与李红认为学生英语文章中动词做主语(词性误用)、谓语动词缺失、冠词误用、双谓语动词/多谓语动词和形容词副词误用等是常出现的错误[4-5].上述5类错误在英语文章中最为普遍,对智能评改系统的负面影响最大,因此,可重点关注这5类错误.如“Play/VB basketball/NN is/VBZ my/PRP$ favorite/JJ sport/NN./.”.根据语法知识“VBG NN VBZ”识别出句子中“play/VB basketball/NN”应该为“playing/VBG basketball/NN”,从而解决这个错误.因此,英语文章的词性标注是对英语文章进行智能评改的必要前提,具有十分重要的意义.
笔者对英语文章进行人工词性标注,并提出一种基于easy-first策略与双向依存网络的英语文章词性标注算法,该算法充分利用大规模无标语料.算法首先对无标语料进行预处理,提取出统计信息;其次使用布朗词聚类算法对大规模无标语料进行聚类,得到簇信息;然后使用Metaphone语音匹配算法生成单词的发音键值;最后在上述人工标注语料和官方新闻语料上进行实验,实验结果表明所提算法对英语文章及官方新闻的词性标注非常有效.
1 面向英语文章的词性标注算法算法流程如图 1所示.

|
图 1 面向英语文章的词性标注算法流程 |
1) 对无标语料进行预处理,得到格式化数据,再进行词聚类,获得每个词的簇信息(1.3节);
2) 对规范化的数据进行词性标注,统计出每个词可能的标记及频次(1.4节);
3) 在标注的数据上进行单词发音匹配,获得单词发音统计信息(1.5节);
4) 融合词的簇信息、标记统计信息、单词发音信息等特征,在easy-first标注策略(1.1节)下,根据评价函数score(wi, ti)(见式(1))对未标注的单词进行词性标注,算法如下.为更好地利用ti左右两侧的标记信息,score(wi, ti)基于双向依存网络(1.2节)进行计算.
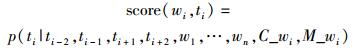
|
(1) |
其中:wi为序列中第i个位置上的单词,ti为序列中第i个位置上单词的词性,C_wi为与wi相关的词聚类特征,S_wi为与wi相关的无标语料统计信息特征,M_wi为与wi相关的单词发音特征.
算法1:easy-first序列标注
输入:W=w1w2…wn
输出:T=t1t2…tn
1. tagset ={t1, t2, …, tl}
2. unlabeledset={w1, w2, …, wi, …, wn}
3. while unlabelset ≠″″do
4. (wi*, ti*)←arg max score(wi, ti);
wi∈unlabeledset;
5. remove(unlabeledset, wi)
6. return T
1.1 easy-first标注策略easy-first标注策略首先寻找到句子中“最容易”的词进行标注,然后再寻找“次容易”的词进行标注,直到所有的词都被标注完,因此,应将最难标注的单词推迟到最后进行标注.当对最难标注的单词进行标注时,该单词两侧的相对容易标注词的词性信息都已获得,因此可以被用来为当前单词的标注提供辅助信息,从而保证标注结果的正确性,标注误差的传播范围也可以在一定程度上被抑制[6].其中“容易”程度是根据评价函数来确定的,这个评价函数不仅为每个单词选择一个尽可能合理的标记,而且还决定了每个单词被标注的顺序.
1.2 双向依存网络序列标注图 2描述了具有2个节点的简单依存网络,其中图 2(a)与(b)是容易理解、语义清晰的图模型,图 2(c)中含有环,不是标准的贝叶斯网络,而是更一般的双向依存网络. 图 2(c)中每个节点代表一个随机变量,表示以所有传入边(源变量)为条件的条件概率模型,因此,双向依存网络与标准贝叶斯网络语义上是一致的.

|
图 2 简单依存网络 |
在对wi进行标注时,将wi上下文的信息分解为多种情况,从而在标注过程中为每个wi选择最合适的情形,避免了标注信息的重复计算.笔者以当前词wi为基准,左右窗口大小为2,序列标注算法如下.
localdecision(wi, ti, W, T):
1. if ti-2=ti-1=ti+1=ti+2=″ ″
2. p(ti/wi, W)
3. if ti-2≠″ ″ & ti-1=ti+1=ti+2=″ ″
4. p(ti/wi, ti-2, W)
5. if ti-1≠″ ″ & ti-2=ti+1=ti+2=″ ″
6. p(ti/wi, ti-1, W)
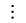
11. if ti-2≠″ ″ & ti-1≠″ ″ & ti+1=ti+2=″ ″
12. p(ti/wi, ti-2, ti-1, W)
13. if ti-2≠″ ″ & ti+1≠″ ″ & ti-1=ti+2=″ ″
14. p(ti/wi, ti-2, ti+1, W)
15. if ti-2≠″ ″ & ti+2≠″ ″ & ti-1=ti+1=″ ″
16. p(ti/wi, ti-2, ti+2, W)
23. if ti-2≠″ ″ & ti-1≠″ ″ & ti+1≠″ ″ & ti+2=″ ″
24. p(ti/wi, ti-2, ti-1, ti+1, W)
25. if ti-2≠″ ″ & ti+1≠″ ″ & ti+2≠″ ″ & ti-1=″ ″
26. p(ti/wi, ti-2, ti+1, ti+2, W)
31. else if ti-2≠″ ″ & ti-1≠″ ″ & ti+1≠″ ″ & ti+2≠″ ″
32. p(ti/wi, ti-2, ti-1, ti+1, ti+2, W)
与其他从左到右或从右至左进行标注的算法相比,该算法可以充分利用词性标记ti左右两侧的标记信息.单词wi的词性标记概率分布通过带有不等式约束的最大熵模型[7]来计算,在训练完成后,模型的大部分参数都会变成零,使得参数集合变得紧凑,对计算时间和运行时的内存要求更少.
1.3 布朗词聚类布朗词聚类算法利用平均互信息作为评价标准[8].该算法将一个大词汇表V中C个频度最高的词作为C个单独的类,将未被分配词中频度最高的一个词作为第C+1类,然后将这C+1个类中互信息损失最少的2个类合并,经过V-C步后,词汇表中的V个词被分成C个类.使用布朗词聚类得到的簇可以提高能名实体识别[9]、Twitter词性标注[10]的性能.
1.4 无标语料统计信息由于搜索的空间相当大,基于双向依存网络词性标注的一个重要问题是解码(寻找最佳标记序列)的计算时间花费比较大.为减小标注时的搜索空间,Ratnaparkhi使用标记统计信息[11],只考虑在训练语料中出现过的(单词,标记)对做候选标记,从而降低该单词解码时的搜索空间和时间复杂度.
1.5 Metaphone语音匹配Phillips提出的Metaphone语音匹配算法[12],以发音检索英语单词,适用于匹配与发音相关的英语拼写错误.该算法依据英语的发音规则来对单词进行编码处理,包括重写辅音与删除元音等19条规则,将单词对应到简单的键值,从而实现粗粒度的发音归一化.
2 特征描述2.1 基本特征基本特征模板如表 1所示.
|
|
表 1 基本特征模板 |

为减少噪声,将句子进行了去重处理,并过滤掉在语料中出现10次以下的词,用布朗词聚类得到簇的所有前缀作为词聚类特征.如果某个词不属于任何一个簇,则通过常见拼写错误列表①为这个词构建一个模糊集,将模糊集中任意词的所属簇赋给该词.
① http://norvig.com/ngrams/spell-errors.txt
2.3 无标语料统计信息特征使用GENIA Tagger②对51 840 035个无标句子进行词性标注,然后统计所有的(单词,标记)对,再计算每个标记出现的频次,将频次作为其权值.
② http://www.nactem.ac.uk/GENIA/tagger/
2.4 单词发音特征使用Metaphone语音匹配算法将词替换成相应的发音键值,并统计出每个发音键值所对应的词性标记出现的频次,得到的数据格式为“发音键值:标记1频次,标记2频次,…,标记n频次”.
3 实验3.1 标注语料说明为使本课题的研究更具有科学性,语料标注人员均为专业英语编辑,标注过程如下.
1) 语料预处理.从PIGAI③的52 115 096条句子中随机挑选出1.5万条,滤掉过短及过长等不标准的句子后剩下14 115个句子,并将文章中出现的“------”“----”“!!!!”“???”等使用错误的标点划分为一个标记.使用OpenNLP④进行语料标注.
2) 手工标注. 4名标注人员对上述标注结果进行修正,将模棱两可的标注记录下来,通过参照华尔街日报语料中的标注,一起讨论确定最终的标注结果.
3) 标注结果审核. 2名标注者审查和修正第1阶段标注的所有句子,对于有异议的标注进行记录,通过标注小组讨论,确定最终的标注结果.第3名标注者在不参照第2) 步中标注结果的情况下,重新标注了300个句子,标注一致率为93.79%,表明该标注结果有效.最后由第4名标注者来对整个语料进行扫描,修正人工标注中出现的错误,进一步提高语料标注的一致性.
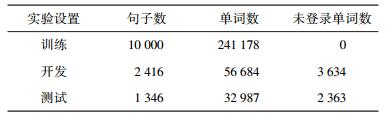
3.2 主要实验实验数据为上述语料(3.1节)中随机抽取的14 022个句子,其中训练集为1万句,开发集为1 780句,测试集为2 242句.未标语料为PIGAI中随机抽的51 840 035个句子.主要实验数据统计信息如表 2所示,不同特征组合的算法标注结果(正确率)如表 3所示.
|
|
表 2 主要实验数据的统计信息 |
|
|
表 3 不同特征组合的算法标注结果(正确率) |
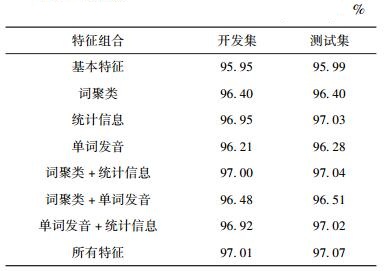
由表 3的实验结果来看,使用所有特征的词性标注器的性能最好,在测试集上正确率达到了97.07%.一系列的特征削减实验结果表明,统计信息是词汇知识的一种强有力的体现,词聚类对词汇知识也有较好的表现能力,单词发音对词汇知识有一定的表现能力.
3.3 与GENIA Tagger比较目前Tsuruoka等提出的GENIA Tagger在词性标注任务上取得了优秀的结果.笔者以GENIA Tagger作为基准与所提算法进行了比较,实验结果如表 4所示.
|
|
表 4 3个标注模型实验结果(正确率) |

从表 4可见,所提算法所实现的模型较基准模型大大提高了英语文章上词性标注的正确率,超过了目前的研究结果.
3.4 华尔街日报语料的词性标注以官方新闻——华尔街日报为实验语料,第02-21章语料为训练集,23章语料为开发集,24章语料为测试集,对GENIA Tagger和所提算法进行了比较,实验结果如表 5所示.
|
|
表 5 2个模型实验结果(正确率) |
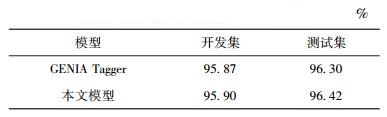
从表 5可见,所提算法在开发集、测试集上标记的正确率都有一定提升,充分说明所选的特征对标注有效.
4 结束语英语文章自动批改在实际应用中遇到了传统词性标注器在英语文章上标注正确率低下的问题,笔者对此进行了深入细致地分析,结合现有的语料资源,对英语文章进行了人工标注,并提出了面向英语文章的词性标注算法.该算法融合词聚类、无标语料统计信息、词发音等特征,并在标注语料上进行实验,实验结果证明该算法能有效提高标注正确率.最终面向英语文章的词性标注被应用到英语文章智能评改系统中,用户的反馈显示,评改系统对一些具有典型错误句子的语法检查方面有了较好的提升.
| [1] | Kristina Toutanova, Dan Klein, Christopher D Manning, et al. Feature-rich part-of-speech tagging with a cyclic dependency network[C]//Proceedings of NAACL-HLT 2003. Los Angeles, California: Association for Computational Linguistics, 2003, 1: 173-180. |
| [2] | Ana Dıaz-Negrillo, Detmar Meurers, Salvador Valera, et al. Towards interlanguagepos annotation for effective learner corpora in sla and flt[J].Language Forum, 2010, 36: 1–15. |
| [3] | Mitchell Marcus, Beatrice Santorini, Mary Ann Marcinkiewicz. Building a large annotated corpus of English: the penn treebank[J].Computational Linguistics, 1993, 19: 313–330. |
| [4] |
李红. 大学生英语写作常见错误归类分析[J]. 当代教育论坛:学科教育研究, 2006, 8: 120–121.
Li Hong. The common errors analysis of college englishwriting[J].Forum on Contemporary Education, 2006, 8: 120–121. |
| [5] |
张雷刚. 英语写作常见错误分析及教学建议[J]. 经济研究导刊, 2010, 19: 243–244.
Zhang Leigang. Common errors in English writing and teaching suggestions[J].Economic Research Guide, 2010, 19: 243–244. doi: 10.3969/j.issn.1673-291X.2010.03.112 |
| [6] | Yoav Goldberg, Michael Elhadad. An efficient algorithm for easy-first non-directional dependency parsing[C]//Proceedings of NAACL 2010. Los Angeles, California: Association for Computational Linguistics, 2010: 742-750. |
| [7] | Jun'ichi Kazama, Jun'ichi Tsujii. Evaluation and extension of maximum entropy models with inequality constraints[C]//Proceedings of EMNLP 2003. Honolulu, Hawaii: Association for Computational Linguistics, 2003: 137-144. |
| [8] | Peter F. Brown, Peter V. Desouza, Robert L. Mercer, et al. Vincent J. Della Pietra, and Jenifer C. Lai. Class-based n-gram models of natural language[J].Computational Linguistics, 1992, 18(4): 467–479. |
| [9] | Alan Ritter, Sam Clark, Mausam, et al. Named entity recognition in tweets: an experimental study[C]//Proceedings of EMNLP 2011. Honolulu, Hawaii: Association for Computational Linguistics, 2011: 1524-1534. |
| [10] | Olutobi Owoputi, Brendan O'Connor, Chris Dyer, et al. Improved part-of-speech tagging for online conversational text with word clusters[C]//Proceedings of NAACL-HLT 2013. Los Angeles, California: Association for Computational Linguistics, 2013: 380-390. |
| [11] | Adwait Ratnaparkhi. A maximum entropy model for part-of-speech tagging[C]//Proceedings of EMNLP 1997. Honolulu, Hawaii: Association for Computational Linguistics, 1996, 1: 133-142. |
| [12] | Lawrence Phillips. Hanging on the Metaphone[J].Computer Language, 1990, 7(12): 39–44. |