


协同过滤(CF)推荐系统可以通过了解用户过去的行为向用户推荐项目.针对现有的CF推荐系统没有利用潜在的项目偏好信息, 提出了一种利用项目偏好改进CF的推荐方法.该方法首先采用K-means算法对用户进行聚类, 然后利用用户聚类和效用矩阵构建项目偏好矩阵, 最后在基于项目的CF方法中, 综合项目评分相似度、项目属性及其偏好特征相似度产生推荐.实验结果表明, 该方法获得了较好的推荐精度, 在一定程度上缓解了稀疏问题.
Recommender systems suggest a few items to the users by understanding their past behaviors. However, the existing collaborative filtering (CF) based recommender systems do not employ the information about latent item preference. In this article, a new CF personalized recommendation approaches was proposed. This approach aims to find user clusters using K-means clustering, and utilizes user clusters and utility matrix to construct item preference matrix, then, combines the item rating similarity, the item attribute and its preference features similarity in the item based CF process to produce recommendations. Experiments show the approach achieves the better result, but also to some extent alleviate the sparsity issue in the recommender systems.
CF推荐通过用户对项目的历史评级信息计算用户的相似度,但由于系统中用户和项目数量众多,再加之不是每个用户均会对每个项目进行评级,所以存在评级数据稀疏的问题,从而影响该类推荐系统的准确性.为提高协同推荐系统的性能,可以综合各种信息进入推荐系统.但是,现有的CF推荐系统并没有利用潜在的项目偏好信息.本研究在项目轮廓(profile)中引入了项目偏好矩阵,并在基于项目的CF方法中,综合项目评分相似度、项目属性及其偏好特征相似度选取项目最近邻居并提供个性化推荐.
1 相关研究CF算法是目前应用最广泛的推荐系统技术之一,它分为基于用户的CF(UCF, user-based CF)和基于项目的CF(ICF, item-based CF).但CF的性能受到评分数据稀疏性的限制.现有的CF推荐系统通常利用用户交互信息和项目信息构建用户的喜好模型,以改善推荐性能.例如,Zheng和Li[1]研究了标签和时间信息在预测用户偏好中的重要性和有用性,提出了利用此类信息建立有效的资源推荐模型. Liu[2]利用基于主题模型的方法捕捉每个用户的兴趣,并在此基础上开发了CF框架. Gong[3]提出了一种综合用户信息和项目信息的CF算法,它首先利用UCF算法填充目标评分矩阵中缺失的评分,然后用ICF算法预测目标用户的预测评分.这种方法尽管缓解了评分数据的稀疏度,但也带来了计算代价. Zhang[4]使用项目领域特征来构建用户偏好模型,并将此用户偏好模型与CF相结合以实现个性化推荐. Eckhardt[5]提出了一种用于描述用户喜好的模型,并利用此模型测量用户相似度.
现有的方法忽略了一个重要的事实:项目本身的特性及其偏好会影响用户的选择行为.本研究提出一种综合项目偏好的混合式CF(CFAP, CF using item attribute and preferences). CFAP首先从用户角度生成项目偏好矩阵,并在项目轮廓中引入项目偏好矩阵,然后采用ICF算法构建个性化推荐系统.实验结果显示出CFAP具有良好的性能.
2 综合项目属性和偏好的CF2.1 利用用户域特征构建项目偏好矩阵在推荐系统中,存在2类元素,一类称为用户,另一类称为项目.用户和系统的交互数据构成了用户-项目对,这些数据可表示成一个效用矩阵.该矩阵中每个用户-项目对所对应的元素值代表当前用户对当前项目的喜好程度.喜好程度的取值可来自一个有序的整数集合,代表用户对项目的评分.假设I={1, 2, …, n}表示推荐系统中一组项目,并设置用户集合为U={1, 2, …, m}.用户对项目的效用矩阵定义为R=(rj, i),其中rj, i为用户j对项目i的评分. Ri表示用户对项目i的评分向量,Ri=(rj, i|j∈U,i∈I).
在推荐系统中,有必要建立项目轮廓.项目轮廓包含2类特征:一类为刻画项目自身特性的项目基础特征,如电影流派、导演、演员等,该类特征通常由一些易于发现的项目特征构成; 另一类为与用户域特征相关的项目偏好特征,如受年轻人欢迎的程度、受女性观众欢迎的程度等,该类特征可以在一定程度上反映项目的适宜人群.例如,如果大多数年轻人对某部电影评分非常高,但中年人对其评分较低或给出的评分非常少,则说明该电影比较受年轻人喜欢.项目的偏好一般可以从用户对项目的评分中获得暗示.
项目的基础特征集合形式化定义为Fb={fb, 1, fb, 2, …, fb, L},其中fb, c(1≤c≤L)为项目第c个基础特征.项目基础特征矩阵Vb为一个n×L矩阵,项目i的基础特征向量为Vb中第i行向量,定义为Vbi=(vb, 1i, vb, 2i, …, vb, Li),其中vb, ci为项目i在基础特征fb, c上的取值.项目偏好特征集合的形式化定义为Fp={fp, 1, fp, 2, …, fp, t},其中fp, k(1≤k≤t)为项目第k个偏好特征.对fp, k特征有贡献的用户集合记为Uk,例如,如果将“项目受女性观众欢迎的程度”定义为某一偏好特征,则所有女性观众对此特征都有贡献,因此所有女性观众隶属于Uk集合. CFAP采用聚类算法获得Uk,即采用K-means算法依据用户矩阵UF将各用户分配到t个簇中,其中UF为m×(h+n)矩阵,前h列为用户基础特性(如年龄、性别),后n列为用户对n个项目的评分.
项目i的偏好矩阵Ei=(ej, ki)为一个m×t矩阵,其中列表示项目的偏好特征,行表示用户对项目的偏好. ej, ki由具备项目偏好特征fp, k的用户j∈Uk对项目i的评分决定,即
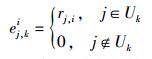
|
(1) |
对于由K-means算法确定的第k类用户对应的项目偏好特性fp, k,如果用户j隶属于Uk,则ej, ki为用户j对项目i的评分.
项目i的偏好向量用Vpi=(vp, 1i, vp, 2i, …, vp, ti)表示,vp, ki(1≤k≤t)为项目i在偏好特征fp, k上的取值,该值是项目i的偏好矩阵Ei中第k列向量Ei, k的聚合函数,即vp, ki=F(Ei, k).聚合函数可以具有不同的形式,最常见的一种是计算Ei, k中所有评分的平均值,即
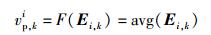
|
(2) |
项目偏好矩阵Vp为一个n×t矩阵,由所有项目的偏好向量组成.
2.2 综合项目偏好的CF图 1所示为CFAP的处理流程. CFAP是ICF的扩展.项目相似度计算方法有2种:① 评分相似性方法,如果各个用户对2个项目具有相似的评分,则可以认为这2个项目是相似的;② 项目特征相似性方法,如果2个项目的特征相似,则可以认为这2个项目是相似的. “评分相似性”方法获得的项目相似性较为准确,但是也存在不足:① 仅当有大量的用户给项目评分时,才可以计算出较为正确的相似性;② 只有当2个用户同时为一个以上的项目评分时,CF才能估计这2个用户的评分相似性.如果同时为2个项目评分的用户集是不相交的,则是没有办法估算项目的评分相似性的.为解决上述问题,CFAP综合了上述2种项目相似性计算方法.项目i1和i2之间的相似度S(i1, i2)依赖于项目特征的相似度SF(i1, i2)和项目评分的相似度SR(i1, i2),如式(3) 所示.
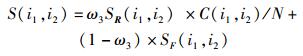
|
(3) |

|
图 1 CFAP处理流程 |
其中:ω3为SR(i1, i2)在S(i1, i2)中的权重,C(i1, i2)为共同为项目i1和i2评分的用户数,N为效用矩阵R中共同为2个项目评分的最大用户数.
CFAP采用Pearson公式计算项目评分相似度SR,利用式(5) 计算项目i1和i2特征的相似度SF.由于项目特征包括基础特征和偏好特征,所以项目特征的欧几里德距离D(i1,i2)包括2部分,即
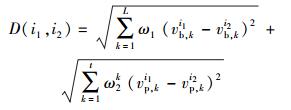
|
(4) |
其中:ω1为项目基础特征的权重,ω2k为项目偏好特征fp, k的权重.
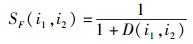
|
(5) |
最近邻居的选取通常有2种方法:① 采用Top-n技术,即选取前n个相似度最高的邻居;② 阈值选取方法,即选取相似度大于设定相似度阈值的邻居. CFAP采用了相似度阈值的方法选取最近邻居.当项目i1和i2的相似度S(i1, i2)大于ω4时,项目i1就是项目i2的最近邻居,即i2∈Ni1,其中Ni1为项目i1的近邻集合.
2.4 预测评分计算找到项目最近邻居后,使用式(6) 计算目标用户j对项目i的预测评分值.
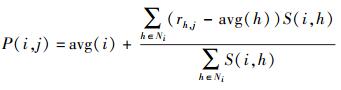
|
(6) |
其中函数avg(i)返回项目i的平均评分.
2.5 推荐结果评估评估推荐系统的性能度量主要包括精度类度量和覆盖类度量.常用到的精度度量有平均绝对偏差(MAE, mean absolute error)方法和均方根误差(RMSE, root mean squared error)方法. MAE方法主要是通过计算预测的用户评分与实际的用户评分之间的偏差来度量推荐结果的准确度.显然,MAE的值越小,表示推荐结果准确度越高. MAE和RMSE的计算方法分别为
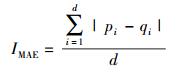
|
(7) |
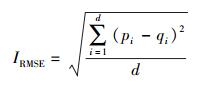
|
(8) |
其中:d为成功预测评分的项目数目,集合{p1, p2, …, pd}为对d个项目预测的评分集合,集合{q1, q2, …, qd}为d个项目实际的用户评分集合.
3 实验与结果分析实验选取MovieLens、Yahoo! Movies数据集.选取的MovieLens数据集包含了943个用户、1 682部电影的评分数据;从Yahoo! Movies数据集中随机选择了1 699个用户、1 167部电影,共计79 088个评分.这2个数据集均提供了用户和电影的特征,便于构建项目轮廓及项目偏好矩阵.实验采用Matlab实现了CFAP、综合项目属性的CF(CFIA, CF using item attribute)和ICF. CFAP定义的Fp包括5个偏好特征:项目受所有用户欢迎程度fp, 5、分别受4类用户欢迎程度(记为fp, 1、fp, 2、fp, 3、fp, 4),其中用户的类别采用K-means聚类算法依据用户特征和用户评分矩阵确定. CFIA和CFAP的不同之处是,CFIA在计算项目相似度时只综合了项目属性相似度和评分相似度,未考虑项目偏好相似度.通过IMAE、IRMSE分析各方法的性能,可得出下面的结论.
1) 图 2、表 1显示了在各数据稀疏度下CFAP均获得了比CFIA、ICF更高的推荐准确度,尤其在稀疏度较高的情况下,CFAP性能改善的程度比CFIA、ICF高,在一定程度上缓解了稀疏性问题.其主要原因在于CFAP在项目轮廓中引入了项目偏好矩阵.项目偏好矩阵是依据用户域特征和评分数据生成的,有助于检测到用户与项目之间的隐含关系,而这些信息是CFIA和ICF的评分矩阵和项目特征所缺失的.

|
图 2 IMAE比较 |
|
|
表 1 IRMSE值 |
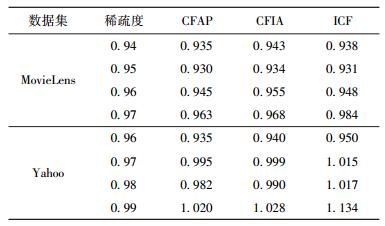
2) Yahoo数据集获得比MovieLens更高的推荐准确度.这主要是由于实验从Yahoo数据集中选取了比MovieLens更多的项目特征,Yahoo数据集包含了电影流派、演导职员列表等,而MovieLens的项目只选取了简单的分类特征,所以基于更丰富项目特征的推荐可以获得更高的推荐精度.
3) 图 3比较了CFAP和CFIA算法的ω3权重,实验结果显示ω3权重取值与数据集和稀疏度有关.由于项目偏好补充了用户与项目之间潜在的关系,所以在CFAP中,评分相似度在项目相似度中所占的权重会变小.尤其在处理稀疏度达98%和99%的数据集时,选取的ω3权重只有0.1,即此时项目的相似度主要取决于项目属性和项目偏好特征的相似度.

|
图 3 ω3比较 |
为解决传统CF技术存在的稀疏性问题,提出利用用户域特征和评分数据构建项目偏好特征向量,并将项目偏好特征向量应用于CF推荐算法中.实验结果证明这种推荐方法在一定程度上缓解了稀疏性问题,改善了推荐精度.
| [1] | Zheng Nan, Li Qiudan. A recommender system based on tag and time information for social tagging systems[J].Expert System with Applications, 2011, 38(4): 4575–4587. doi: 10.1016/j.eswa.2010.09.131 |
| [2] | Liu Qi, Chen Enhong, Xiong Hui, et al. Enhancing collaborative filtering by user interest[J].IEEE Transactions on Systems, Man, and Cybernetice—Part B: Cybernetics, 2012, 42(1): 218–233. doi: 10.1109/TSMCB.2011.2163711 |
| [3] | Gong Songjie. Employing user attribute and item attribute to enhance the collaborative filtering recommendation[J].Journal of Software, 2009, 4(8): 883–889. |
| [4] | Zhang Jing, Peng Qinke, Sun Shiquan, et al. Collaborative filtering recommendation algorithm based on user preference derived from item domain features[J].Physica A: Statistical Mechanics and its Applications, 2014, 396: 66–76. doi: 10.1016/j.physa.2013.11.013 |
| [5] | Alan Eckhardt. Similarity of users'(content-based) preference models for collaborative filteringin few ratings scenario[J].Expert Systems with Applications, 2012, 39(14): 11511–11516. doi: 10.1016/j.eswa.2012.01.177 |