


提出了一种基于时间上下文的协同过滤推荐(TCCF-LI)算法, 实现了基于高校图书馆图书借阅记录数据上的学生学习兴趣挖掘.在传统协同过滤算法上引入时间上下文信息, 既考虑了大尺度用户群体爱好的趋同性, 又兼顾了小尺度个体用户爱好的短时相关性, 获得了更高的推荐性能.在实际数据集上的实验结果表明, 该算法在推荐精准度、召回率等方面比传统推荐算法有较好表现.
A time context based collaborative filtering recommendation (TCCF-LI) algorithm this paper was proposed, and students' learning interest mining from university library borrow record was implemented. The time context information was imported into the traditional collaborative filtering recommendation algorithm, in which, both interest homoplasy of large scale user groups and short-term correlation of small scale user groups was considered. Good recommendation performance was gained. According to the experiments on real dataset, TCCF-LI algorithm presents higher precision and recall rate compared with traditional recommendation algorithm.
基于协同过滤(CF, collaborative filtering)上下文感知推荐生成技术[1]是基于“集体智慧”的思想,将上下文信息融入到基于用户相似性、项目相似性和基于模型的CF中.已有的基于内容上下文感知推荐生成技术的主要研究思路是,将上下文信息融入基于内容的推荐方法,着重考虑用户偏好、上下文与项目属性的匹配度.基于社交关系数据来提高推荐系统的性能方面,近年来研究的较多.在文献[2-5]中,研究者加入用户间的社交网络上下文信息; 文献[6-7]基于用户签到位置轨迹与社交活动数据进行融合推荐; 文献[8-9]将用户位置上下文信息与用户位置签到行为上下文相结合,实现基于位置上下文的CF.
基于时间上下文的协同过滤推荐(TCCF-LI, time context based collaborative filtering recommendation)算法是融合借阅时间作为推荐系统的另一个上下文维度,进一步地研究了在不同的时间上下文环境下,推荐系统的精度以及在算法上的改进.
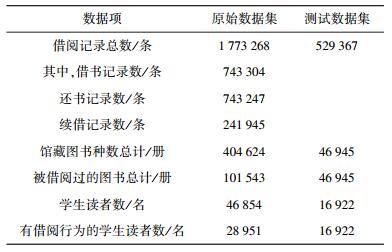
1 学习兴趣挖掘的推荐算法建模1.1 实验数据集分析及评分模型构建实验采用北京邮电大学图书馆提供的借阅记录作为数据集,具体情况如表 1和表 2所示.
|
|
表 1 图书借阅记录原始数据集情况 |
|
|
表 2 图书借阅记录原始数据集数据分布情况 |
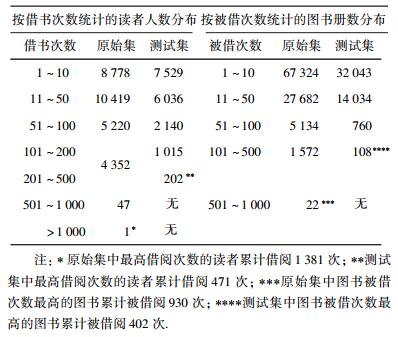
因为原始数据集图书(item)和读者(user)的数量级较高,不适合在算法测试和验证阶段进行全集数据的运算.因此在数据预处理阶段,将借阅记录为0和1的用户过滤出去,并将借阅次数高于500的用户和图书过滤去除.因为这其中包含了部分系统非有效数据(图书借阅系统自身测试数据等噪声数据).
构建推荐系统必须建立用户模型(user model)保存用户的偏好.这里用U={u1, 2, …, un}代表学生借阅用户集,用D={d1, 2, …, dm}代表图书集.初始读者用户对图书的评分用借阅记录表示:一次借阅表示用户对这本书的喜欢(或者评分)为1,续借或非连续地借阅2次则评分为2,并逐次累加.
通过借阅记录构建用户对图书的评分矩阵R.R代表评分项ri, j的n×m评分矩阵,这里i∈{1, 2, …, n},j∈{1, 2, …, m}.如果用户i没有借阅过图书j,视为对该图书没有评分,则对应的矩阵项ri, j为空.
为了减小较高借阅次数对相似性计算的误差,本实验中将用户的借阅次数通过式(1) 转化为(0, 5) 的评分.
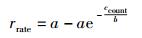
|
(1) |
其中:rrate为最后的得分,ccount为书籍的借阅次数,a和b分别为调整系数.为了将得分分布在(0, 5) 之间,a赋值为5.通过调整b的值来适应数据的分布规律,实验中b赋值为4.5.通过式(1) 可以将分布(1, 402) 的评分映射到(0, 5) 之间.
2 TCCF-LI算法设计引入时间上下文信息在基于借阅记录的学生兴趣挖掘上有重要的意义.学生的学习兴趣与其所在学年和学期课程内容,以及领域技术更新的情况具有较高的时间效应.读者用户在相隔很短的时间内感兴趣的书籍具有更高相似度,也可以建模为读者在相隔很短的时间内喜欢的图书具有更高相似度.因此,在预测阶段将读者近期借阅行为相比用户很久之前的行为加重了权值.
Item-based CF算法,设U为所有图书i和j评分的读者集,则图书i和j之间的相似度sim(i, j)为
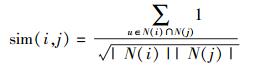
|
(2) |
其中:N(i)为借阅图书i的读者集合,N(j)为借阅图书j的读者集合.因此,式(2) 的分子部分表示同时借阅图书i和图书j的读者用户数;分母部分中|N(i)|表示借阅图书i的用户数,|N(j)|表示借阅图书j的用户数.而在给读者u做推荐时,读者u对图书i的兴趣p(u, i)为
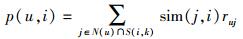
|
(3) |
其中:N(u)为读者u借阅图书的集合,S(i, K)为和图书i最相似的K个图书集合,ruj为读者u对图书j的评分.
引入时间衰减项f(|tui-tuj|),其中tui为读者u借阅图书i发生的时间.f函数的含义是,读者对图书i和图书j借阅行为发生的时间越远,则f(|tui-tuj|)越小.实验中引入衰减函数为
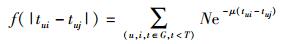
|
(4) |
其中:tui及tuj取值为借阅记录日期;N和μ为时间衰减参数,它们的取值在不同系统中不同;G为实验仿真中的测试集,限定了i、j、t的取值空间.N一般取值为1.如果一个系统用户兴趣变化很快,就应该取比较大的μ,反之需要取比较小的μ,在实验3中对μ取值进行了测试和讨论.
在得到时间信息(用户对物品产生行为的时间)后,可以通过式(5) 改进相似度的计算.
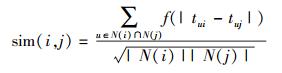
|
(5) |
下面将通过仿真来验证采用不同相似性计算方法的User-based CF,以及采用余弦相似性的User-based CF和TCCF-LI算法的性能.这里将实验数据集的数据划分为训练集(training set)和测试集(test set).训练集和测试集的划分是9:1,按照借阅时间排序取最早借阅记录的90%作为训练集,余下的为测试集.
3.2 算法评价指标推荐预测是为学生读者推荐感兴趣的图书,也就是经典的Top-N问题,评价这类问题可以通过精准度Pprecision和召回率Rrecall来衡量推荐的准确度,即
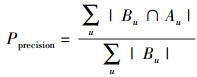
|
(6) |
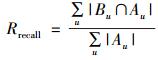
|
(7) |
其中:Bu为给读者u的推荐列表集合,Au为在测试集中读者u感兴趣的图书集合.
为了同时考查精准度和召回率,实验中还使用了F指标,F指标定义为
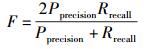
|
(8) |
通过F指标可以选择合适的Top-N的推荐长度,以兼顾精准度和召回率的表现.
3.3 仿真结果与分析笔者将所提出的TCCF-LI算法与已有的User-based CF进行相关的对比.
实验1 本实验应用场景中,CF算法中不同相似性计算方法的性能表现.
实验中将续借的记录作为用户对书借阅的权值,来实现带权余弦的计算,并在不同的推荐列表长度的情况下,对3种算法进行比较,图 1、图 2反映了实验结果.其中,图 1显示了3种算法在推荐列表K长度依次为1、3、7、10时的精准度、召回率对比,得出以下结论.

|
图 1 推荐长度K取1~10下的精准度和召回率 |

|
图 2 推荐长度K取1~10下的F指标 |
1) 从整体上看,推荐的精准度随着推荐列表的增加而降低,召回率正好相反.其中,余弦算法的整体效果要好于修正余弦,而这2种算法的推荐效果要明显优于皮尔逊算法.余弦算法的推荐精准度最高达到了10.72%,最低也有6.1%.
2) 召回率中,表现最好的是余弦算法为11.87%,最差的是皮尔逊算法.
3) 一般推荐列表长度越长,召回率越高,精准度很有可能会随之下降.而图 2综合考虑了召回率与精准度.对于表现最好的余弦算法,精准度和召回率相交在5~6之间.实验仿真验证了北邮读者用户通常平均每次借阅书籍5~6册.
实验2 对比TCCF-LI算法与实验1中选出的性能最好的CF的性能表现.
TCCF-LI算法中,时间上下文是以用户借阅图书行为发生时间为参数的.因为在数据集中,同一个用户对同一本书产生了多次借阅,取值为用户最后一次借阅该图书的时间.实验中计算时间tui-tuj及t0-tuj时,采用用户借阅时间的时间戳来计算.差值再按照2个时间的时间戳的毫秒差折算为天数来计算,从而获得的tui-tuj及t0-tuj的天数差值的取值空间是(0, 548)(借阅记录数据集的时间范围).时间衰减参数μ的取值在实验3中测试,这里取其性能表现最优的值.如图 3和图 4所示,可以得到以下结论.

|
图 3 TCCF-LI与余弦CF精准度和召回率比较 |

|
图 4 TCCF-LI与余弦CF的F指标比较 |
1) TCCF-LI与传统单一模型的CF算法相比,在精准度和召回率方面都具有较好的表现,在精准度上最好可以是12.8%,召回率最好可以是15.5%.
2) 图 4中TCCF-LI在推荐长度K取7~10时,F指标都有较好的表现,且明显优于单一模型CF算法.
实验3 TCCF-LI算法中时间衰减因子μ对预测结果的影响.
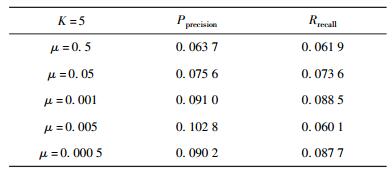
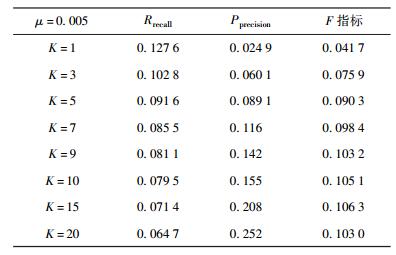
实验中通过调整时间衰减因子μ以及推荐长度K来对比结果.由表 3和表 4,可以得到以下结论.
|
|
表 3 不同时间衰减因子μ取值下的精准度和召回率 |
|
|
表 4 μ取值0.005时不同K的精准度和召回率 |
1) 在K=5且衰减因子μ初始逐步调低时,精准度和召回率都在逐步提升;在μ取值为0.005达到波峰时,Pprecision为10.28%,Rrecall为6.01%.因此,在本实验应用场景中μ取值为0.005.
2) 在μ取值为0.005时,可以发现在K取15时,F指标最好,为10.63%.此时,推荐系统的精准度可以达到20.8%,召回率为7.14%,实验性能有较大提升.
4 结束语笔者针对高校学生个性化培养平台建设的目标,研究并提出了一种TCCF-LI算法.该算法将时间上下文信息引入协同过滤方法中以获得更好的推荐精确度,由此提出了基于一种新的时间衰减函数的时间上下文CF算法.通过详细实验测试,① 验证了CF算法在所提应用场景实践中适合的相似性计算方法为余弦相似性;② 验证了所提出的TCCF-LI相比传统CF算法具有更好的性能表现;③ 通过实验给出了所提出的TCCF-LI算法中时间衰减因子的合理取值.
| [1] | Chen Annie. Context-aware collaborative filtering system: predicting the user's preference in the ubiquitous computing environment[J].Lecture Notes in Computer Science, 2005, 3479: 244–253. doi: 10.1007/b136418 |
| [2] | Liu Fengkun, Lee H J. Use of social network information to enhance collaborative filtering performance[J].Expert Systems with Applications, 2010, 37(7): 4772–4778. doi: 10.1016/j.eswa.2009.12.061 |
| [3] | Yang Shuanghong, Long Bo, Smola A, et al. Like like alike: joint friendship and interest propagation in social networks[C]//Proceedings of the 20th International Conference on World Wide Web. Bangalore India: ACM, 2011: 537-546. |
| [4] | Hasan S, Zhan Xianyuan, Ukkusuri S V. Understanding urban human activity and mobility patterns using large-scale location-based data from online social media[C]//Proceedings of the 2nd ACM SIGKDD International Workshop on Urban Computing. Chicago USA: ACM, 2013: 1-8. |
| [5] |
胡祥, 王文东, 龚向阳, 等. 基于流形排序的社会化推荐方法[J]. 北京邮电大学学报, 2014, 37(3): 18–22.
Hu Xiang, Wang Wendong, Gong Xiangyang, et al. Social recommendation based on manifold ranking[J].Journal of Beijing University of Posts and Telecommunications, 2014, 37(3): 18–22. |
| [6] |
孙甲申, 王小捷. 一种用于社会化标签推荐的主题模型[J]. 北京邮电大学学报, 2014, 37(3): 38–42.
Jiashen, Wang Xiaojie. A topic model for social tag recommendation[J].Journal of Beijing University of Posts and Telecommunications, 2014, 37(3): 38–42. |
| [7] | Ying Josh Jia-Ching, Lee W C, Ye Mao. User association analysis of locales on location based social networks[C]// Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Location Based Social Networks. Chicago USA: ACM, 2011: 69-76. |
| [8] | Yuan Quan, Cong Gao, Ma Zongyang. Time-aware point-of-interest recommendation [C]// Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. Dublin Ireland: ACM, 2013: 363-372. |
| [9] | Zheng Ning, Jin Xiaoming, Li Lianghao. Cross-region collaborative filtering for new point-of-interest recommendation[C]//Proceedings of the 22nd International Conference on World Wide Web Companion. Seoul Korea: [s.n.], 2013: 45-46. |