


2. 西安电子科技大学 综合业务网理论与关键技术国家重点实验室, 西安 710071
当多播业务扇出数较小时,现有的多播信元入队策略均衡能力差,造成多播队列数目增加却不能使调度算法从中获利的现象,为此提出了一种加权取模的多播信元入队算法,对扇出位的加权和进行取模运算.以此作为多播信元入队的依据,可更好地均衡小扇出数的多播信元.仿真结果表明,小扇出多播业务下,调度算法采用加权取模入队策略时的吞吐率要高于采用传统入队策略时的吞吐率.
2. State Key Laboratory of Integrated Service Networks, Xidian University, Xi'an 710071, China
When the fanout number of multicast cells is relatively small, the existing cell assignment scheme has poor performances under balancing traffic load. The scheduling algorithm can almost not benefit from the increase of multicast queues. A weighted modulo (WM) algorithm for multicast cell assignment was presented, which can ensure more scheduling opportunities and work conservation. The proposed scheme performs modulo operation on the weighted sums of the fanout bits to get the mapped queue number, thus the multicast cells with small fanout numbers can be balanced very well. Simulations show that multicast scheduling algorithm adopting the proposed scheme has higher throughput than that adopting the Modulo algorithm.
在进行交叉开关矩阵(Crossbar)多播调度算法设计时,需要着重解决以下2个问题:一是提供高吞吐率的排队机制;二是提供公平服务的队列调度算法.用bj表示端口j是否为多播信元的目的端口,若是目的端口,则bj=1,否则,则bj=0.多播信元的扇出集可表示为Φ={bN-1, …, b1, b0},扇出数|Ф|也即目的端口数,可表示为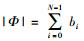
笔者提出了一种加权取模(WM,weighted Modulo)的多播信元入队机制,并将其用于Crossbar交换结构的多播调度.通过对扇出位的加权和进行取模运算,WM入队算法更好地均衡了小扇出的多播信元,并且采用WM入队机制的调度算法可以随着多播队列的增加而提高吞吐率性能.最后给出了仿真结果和分析.
1 多播信元入队机制考虑复杂度和性能之间的折中,目前多播调度算法通常采用K个多播队列.到达各个输入端口的多播信元按照一定的信元分派策略选择K个队列中的一个进行排队,每个端口的K个多播队头信元可以参与每时隙的调度过程.由于无法完全避免多播信元的排头阻塞,如何将到达的多播信元安置到K个队列很关键,这将影响到调度算法的性能.文献[6-7]针对多播入队策略给出了3个基本规则.
规则1 各多播队列的队头信元应尽可能不同,以便保证更多的端到端匹配.
规则2 具有相同或者相似扇出集合的多播信元应进入同一多播虚拟输出队列.
规则3 多播入队策略还应考虑在各个多播队列之间进行流量均衡.
需要说明的是,对于多播业务,扇出数越大,输入输出端口对间获得有效匹配的概率越高[7],并且在归一化输出负载条件下,由大扇出数信元构成的多播业务,其业务到达速率较小,受入队策略、多播队列数的影响较小.因此,多种入队策略在大扇出多播业务下均能达到较优的性能,且各入队策略之间的差异较小.而由小扇出数信元构成的多播业务,其业务到达速率相对较高,并且匹配效率降低,更易受入队策略和多播队列数的影响.相对来说,小扇出数的多播业务的流量均衡对调度算法的性能提升更为关键,但目前少有文献涉及这一问题.
2 基于加权取模入队机制的多播调度2.1 加权取模入队策略Modulo算法具有算法复杂度低、硬件实现简单的特点,在多播调度算法中获得广泛应用.具体步骤如下:令多播队列Qi, q表示该队列是输入i的第q+1个多播队列,其中0≤i≤N-1,0≤q≤K-1.对每个输入端口i,到达多播信元c具有扇出集Φ,若满足
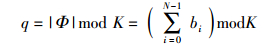
|
(1) |
则将该信元入队Qi, q.
但Modulo算法存在一个问题,即不能对扇出数目较少的多播信元更好地实现负载均衡.对于小扇出数的信元而言,增加队列数至超过其最大扇出时,信元仍然只进入低于其最大扇出的队列中.这是由Modulo算法模K取余的特点决定的. 图 1(a)所示为Modulo入队算法业务不均衡情况示例,其中K=4.扇出数为1和2的信元分别入队Qi, 1和Qi, 2,剩余两个队列Qi, 0和Qi, 3没有信元进入.该情况下参与匹配的队首信元只有两个.

|
图 1 多播信元入队算法示例 |
笔者提出了一种增强型的多播入队策略,称为加权取模入队机制.该机制可以充分地均衡小扇出数的信元,并且能够随着多播队列的增加而提高可匹配的队头信元数目,从而获得吞吐率性能的改善. WM入队机制:对每个输入端口i,到达多播信元c具有扇出集Φ,若满足
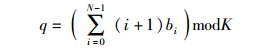
|
(2) |
则将该信元入队Qi, q.
如图 1(b)所示,同样的业务,在WM方案中,扇出数为1的信元分别进入Qi, 0至Qi, 3,多个队列间均匀分布,增加了参与匹配的队首信元,有效地缓解了多播信元的排头阻塞问题.具体的吞吐率性能的改善程度将通过仿真验证.
2.2 基于WM机制的Crossbar多播调度图 2所示为N×N的Crossbar交换网络,每个输入端口i有K个多播队列,记为Qi, q,其中0≤i≤N-1,0≤q≤K-1.每个输入和输出端口分别有一个输入调度器AI(i)和输出调度器AO(j).每个输入端口维护一个本地多播指针PI(i),指向当前优先调度的多播队列.各输出端口维护一个全局多播指针PO,指向当前优先调度的输入端口.全局多播指针的功能在于每次至少能保证优先调度的输入端口的多播信元可以完整被发送.

|
图 2 具有K个多播队列的Crossbar交换网络 |
变长分组在进入交换网络之前被切割成定长信元,并在经过交换网络后,重新组装成分组.本研究所涉及的排队和调度均是以信元为单位.
一个到达的多播信元首先经信元分派调度器进入相应的多播队列,位于队首的多播信元将参与Crossbar的多播信元调度.为比较多播信元分派机制的效率,仿真中采用相同的信元调度算法,各方案仅在信元入队机制有区别,可分别采用Modulo入队机制和WM入队机制.调度过程包括3个步骤.
步骤1 请求.输入端口调度器AI(i)按照轮询规则,从当前请求指针PI(i)所在的位置开始选择最近的非空队列,并按照队头信元的扇出发送请求到对应的输出端口.
步骤2 许可.如果输出端口收到多个请求,则输出端口调度器AO(j)按照轮询规则,从当前全局许可指针PO所在的位置开始选择最近的一个输入端口的请求进行许可.
步骤3 接受.输入端口若接收到许可信号,则接受该许可,并且将该输入端口和输出端口标记为已匹配.
上述过程需要进行多次迭代,在前一轮未匹配的输入和输出端口参与新一轮的匹配过程,其中输入端口在请求时将选择离前一轮未匹配的多播队列最近的非空队列.匹配结束后,获得匹配的输入端口发送队头信元的拷贝到各目的端口.当一个多播信元的所有扇出都已发送完,则从队首移除该信元,并更新本地多播指针PI(i)至接受服务的队列Qi, q的下一个队列,即PI(i)=(q+1) modK.全局许可指针PO在每个时隙结束后,更新到当前位置的下一个位置,即PO=(PO+1) modN.
3 仿真结果基于网络仿真系统OPNET对各方案的性能进行了评估.仿真过程统计了分别采用Modulo入队机制和WM入队机制的多播调度算法在单一扇出和均匀扇出两种多播业务下的吞吐率性能.仿真时长为10万个时隙.输入和输出都是可允许业务.输入负载包含多播部分(fm)和单播部分(fu),其中0≤fm, fu≤1,且fm+fu=1.多播信元的扇出可分为两种形式:一种是单一扇出,即所有多播信元的扇出数为同一个常数值,但是扇出目的端口在所有输出端口间均匀分布;另一种是均匀扇出,即多播信元的扇出数在一个范围内均匀分布.
1) 单一扇出
多播信元的扇出数为常数|Φ|,其中1≤|Φ|≤N.基于以上条件,交换网络的输入负载λ和输出负载μ之间的关系可表示为
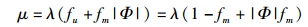
|
(3) |
2) 均匀扇出
多播信元的扇出数|Φ|在|Φ|min到|Φ|max之间均匀分布,其中1≤|Φ|min≤|Φ|≤|Φ|max≤N,通常取|Φ|min=1.此时交换网络的输入负载λ和输出负载μ之间的关系可表示为
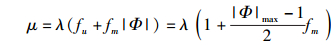
|
(4) |
图 3所示为分别采用Modulo和WM入队机制的多播调度算法在单一扇出多播业务下的吞吐率性能.这一部分的仿真中,取fm=1,即纯多播业务.归一化输出负载μ=1,迭代次数为4.首先,随着扇出数的增加,各方案的吞吐率性能都在改善.这是因为队首信元的扇出位越多,越容易实现输入和输出端口之间的匹配.每次匹配的效率提高,算法的吞吐率也将提高.扇出数|Φ|=8的业务,在两种入队机制下均能实现100%吞吐率.

|
图 3 单一扇出业务下算法的吞吐率性能(N=8, 均匀到达) |
另外,单一扇出的多播业务下,Modulo方案会造成所有输入多播信元只进入一个队列,因此即使多播队列由1增加到8,其吞吐率性能始终不变,如图 3中虚线所示.与Modulo算法不同的是,WM算法中,吞吐率随着多播队列的增加而增加.这是因为,WM入队机制使得多播信元能够在所有队列间均衡到达业务.更多信元位于队首,则可参加匹配的信元数增加,这就意味着算法的吞吐率性能可获得提高.对于扇出数|Φ|=1的业务,如当前多播队列数为8,则扇出位在b0, b1, …, b7的多播信元分别入队Qi, 1, Qi, 2, …, Qi, 7, Qi, 0,此时队首多播信元之间实际无排头阻塞影响,因此吞吐率接近100%.
图 4所示为突发到达的单一多播业务下算法的吞吐率性能仿真结果,其中平均突发长度B为10,一次突发中的连续信元具有相同的扇出数和目的端口.采用入队策略Modulo和WM的算法其吞吐率均比均匀到达业务下的吞吐率有所下降.但大致趋势与均匀到达业务下的结果一致.

|
图 4 单一扇出业务下算法的吞吐率性能(N=8,B=10) |
图 5所示为64×64规模的Crossbar交换网络各入队方案在单一扇出业务下的吞吐率性能.除数值不同,大致趋势与N=8时的趋势一致.采用WM入队机制的多播调度算法吞吐率性能要高于采用Modulo入队机制的多播调度算法的性能.扇出数越小,两种入队方案的吞吐率性能差距越大.

|
图 5 各入队算法在单一扇出业务下的吞吐率性能(N=64) |
图 6所示为分别采用Modulo和WM入队机制的多播调度算法在均匀扇出多播业务下的吞吐率性能.采用WM入队方案的多播调度算法随着多播队列的增加,吞吐率提高.而采用Modulo入队方案的多播调度算法的吞吐率性能曲线由两部分组成,前一段曲线处于上升阶段,这时候的多播队列数小于|Φ|max,因此多播队列增加,多播信元可进入的队列数同时增加,吞吐率性能获得提升;当多播队列数大于|Φ|max后,多播信元进入的队列数目不超过|Φ|max个,因此吞吐率性能不会改变.

|
图 6 各入队算法在均匀扇出业务下的吞吐率性能(N=64) |
相比扇出数大的多播业务,扇出数小的多播业务具有相对较低的匹配效率,也更容易受排队机制的影响.笔者提出的基于加权取模的多播信元入队策略,可更好地均衡小扇出数的多播业务.仿真结果表明,采用加权取模入队策略的多播调度算法,其吞吐率随多播队列数增加而提高;并且扇出数越小、多播队列数越多,加权取模入队策略相对于Modulo入队策略的优势越明显.
| [1] | Shanthi G, Shanmugam A. Mathematical analysis of the input-queued packet switch under multicast traffic[J].IEE Proc Communication, 2005, 152(6): 845–849. doi: 10.1049/ip-com:20045344 |
| [2] | Hui J Y, Renner T. Queueing analysis for multicast packet switching[J].IEEE Transactions on Communications, 1994, 42(2-4): 723–731. |
| [3] | Sun Shutao, He Simin, Zheng Yanfeng et al. Multicast scheduling in buffered crossbar switches with multiple input queues [C]//Proc IEEE HPSR. Hong Kong: IEEE Press, 2005: 73-77. |
| [4] | Mhamdi L. On the integration of unicast and multicast cell scheduling in buffered crossbar switches[J].IEEE Transactions on Parallel and Distributed Systems, 2009, 20(6): 818–830. doi: 10.1109/TPDS.2008.262 |
| [5] | Jiang Yongbo, Qiu Zhiliang, Zhang Maosen, et al. Integration of unicast and multicast scheduling in a two-stage switch architecture with low scheduling overhead[J].IET Communications, 2012, 6(17): 2825–2832. doi: 10.1049/iet-com.2012.0105 |
| [6] | Gupta S, Aziz A. Multicast scheduling for switches with multiple queues [C]//Proc IEEE High Performance Interconnects. Los Alamitos: IEEE Press, 2002: 28-33. |
| [7] | Song Min, Zhu Weijing. Throughput analysis for multicast switches with multiple input queues[J].IEEE Communications Letters, 2004, 8(7): 479–481. doi: 10.1109/LCOMM.2004.832733 |