


2. 齐鲁工业大学 信息学院,济南 250353
为提高符号网络的连边符号预测准确率,深入分析了影响连边符号的各项基本机理,拓展了“结构平衡理论”和“地位理论”,同时将网页网络中的“PageTrust”度量引入符号网络用以刻画符号网络中节点的重要性.在融合从不同角度反映连边符号形成机制理论的基础上,抽取出一组最能反映连边正负的网络特征,并将这类网络特征用于2类机器学习模型的训练与测试. 2个真实网络数据集上的实验结果表明,训练所得模型具有较已有模型更高的预测准确率和更好的通用性.
2. School of Information, Qilu University of Technology, Jinan 250353, China
In order to make the link sign prediction more accurate in signed networks, it is necessary to analyse each underlying principle of generating signed networks. Structure balance theory and status theory are extended to gain more information for link sign prediction. A new measurement named PageTrust in web network is introduced to describe the importance of node of signed networks. On the basis of integrating different kind principles of generating signed networks, a group of refined features are extracted. Based on those creative features, two link sign predictors using supervised machine learning algorithms are established. Experimental results on two real signed networks demonstrate that learned model is more accurate and generalized than other state-of-the-art methods.
近年来,社交网络已经成为人们建立联系与分享信息的主要媒介.传统的社交网络(如Facebook)可以建模为一个无符号简单二值网络,该类网络中连边属性只有一种值.另外,一些新型的社交网络(如Epinions)允许连边赋予更多的属性值以表达更丰富的语义,如连边属性值可以是正、负号的符号网络.符号网络中的正、负号边可用于区分积极、消极2种类型的关系.连边符号预测是符号网络分析中的一个核心问题,该问题的解决有助于个性推荐、态度预测等应用的开发.目前,针对连边符号预测的研究可以分为2类:无监督学习方式和监督学习方式. Guha等[1]最早研究了信任网络中信任预测问题,其先将信任传播转化为一系列矩阵操作,然后再使用无监督学习方式来研究信任的传播. Kunegis等[2]拓展了谱分析方法,使其能适合符号网络的分析,并解决了符号网络连边符号预测的问题.文献[3]利用spring嵌入算法进行连边符号预测,该算法假定正号边两端的节点相互吸引,负号边两端的节点相互排斥. Leskovec等[4]最早给出了连边符号预测问题的形式化定义,并在监督机器学习框架下进行研究,其抽取出2种类型的网络特征,一类为传统的节点局部网络特征,另一类网络特征则借鉴于结构平衡理论. Chiang等[5]拓展了度量网络不平衡程度有序环的长度,基于任意长度关系环的不平衡累加提出了一种新的度量并应用于连边符号的预测.
上述方法中,监督学习方法具有诸多优势,但是已有方法对影响连边符号的特征挖掘还不够,各种机器学习算法的比较也较少.为此,笔者深入分析影响连边符号形成的各项机理,并在此基础上抽取出一组最能反映连边符号的优质网络特征,这组网络特征同时涵盖了符号网络的局部特性与全局特性,使用获得的网络特征对2类机器学习模型进行训练和测试. 2种真实网络数据集上的实验验证了学得的融合多特征的机器学习模型是有效和通用的.
1 连边符号预测模型1.1 问题定义连边符号预测问题可以形式化描述如下:给定一个符号网络,使用边(u, v)以外其他边的已知符号信息推断出边(u, v)的符号Sign(u, v). 图 1给出了符号预测问题的一个简单示例,在该符号网络中,除节点u和v形成的连边上的符号Sign(u, v)未知外,其他各边的符号均为已知,目标是要预测Sign(u, v).

|
图 1 符号网络连边符号预测 |
符号网络的连边符号预测问题本质上还是一个二元分类问题,因此连边符号预测的准确度与特征的选取有着很大的关系.下面将重点考虑2个方面的网络特征,即局部网络特征和全局网络特征.局部网络特征主要试图刻画个人的口味与习惯.全局网络特征则试图从全局的角度来刻画一个用户的信誉度或重要性.
1.2.1 局部网络特征1) 三角形结构平衡网络特征
结构平衡理论是符号网络领域中最基本的理论.传统结构平衡理论主要围绕三角形的平衡性展开研究,在符号网络中,考虑符号性后三角形的关系具有如图 2所示的4种模式.根据结构平衡理论,图 2(a)和图 2(b)对应的三角形是结构平衡的,而图 2(c)和图 2(d)对应的三角形是结构不平衡的.上述三角形的结构平衡判定可以简单概括为4个直观认识:① 我朋友的朋友是朋友;② 我朋友的敌人是敌人;③ 我敌人的朋友是敌人;④ 我敌人的敌人是朋友.其中,图 2(a)对应第① 个直观认识,图 2(b)符合直观认识②~④,而图 2(c)不满足上述4个直观认识的前3个,图 2(d)不满足第④ 个直观认识.为了判定节点u和v之间的连边符号,选取4种不同符号模式三角形的个数作为网络特征,进行机器学习模型的训练与测试.

|
图 2 结构平衡与结构不平衡三角形 |
2) 四边形结构平衡网络特征
传统结构平衡理论主要研究了三角形结构,长度大于3的环(如四边形)也可以作为扩展结构平衡理论的研究对象.真实符号网络的实证分析发现,网络中存在很大比例的结构平衡的长环(具有偶数数目负号连边的关系长环).因此,将长度大于3的环所对应的网络结构平衡特征考虑进来,对分类机器学习模型的训练必然是有益的.笔者采用类似三角形结构平衡的分析方法,共统计出8种不同符号模式的四边形,并将这8种类型的四边形个数组成一个8维向量,作为判定连边(u, v)符号的网络特征.
3) 共同邻居与邻居并集比例特征
三角形结构平衡特征虽能刻画共同邻居观点一致的个数多少,但并不能反映观点一致的比例,因而不能准确反映节点u和v品味一致性.为此,引入节点u与v的共同邻居与邻居并集之比这一网络特征,力求更加准确刻画2个节点间的品味一致性.
4) 节点u给出正面评价的先验概率特征
一个节点给出正面评价的先验概率反映了一个人习惯性给出正面评价的可能性,这在一定程度上也反映了该节点对其他节点的评价尺度.
5) 节点u给出评价个数特征
特征4) 反映了一个节点给出正面评价的概率,这在一定程度上能刻画该节点给出正面评价的可能性,但是该网络特征却没有将评价数量考虑其中.显然,在特征4) 相同的情况下,评价数量越多的用户对连边符号预测的影响越大,因此引入特征5),即节点u给出评价的总个数.
6) 节点v获得正面评价的先验概率特征
类似特征4),一个节点v获得正面评价的概率反映了一个人习惯性获得正面评价的可能性,这在一定程度上反映了该节点被广泛认可的程度.
7) 节点v获得评价个数特征
类似特征5),该特征用来刻画相同特征6) 情况下,获得正面评价数目越多,对于连边符号预测影响越大这一直觉.
1.2.2 全局网络特征1) 地位理论网络特征
地位理论认为,连边的正负号取决于节点间的地位差异,具体表述如下:如果u到v是正号边,则表示u认为“v的地位比u高”;如果u到v是负号边,则表示u认为“v的地位低于u”.这种地位高低关系具有传递性.假设孤立点的“地位值”为0,当一个节点做出一个正面评价或者获得一个负面评价时,其“地位值”减1.相反,如果一个节点做出一个负面评价或者获得一个正面评价,则该节点的“地位值”加1.最终得到的节点u和节点v的“地位值”可以作为预测节点u到节点v连边符号的网络特征.
2) PageTrust值特征
PageRank,网页排名,是Google公司对网页进行排序的一项重要指标.在符号网络中,同样存在节点重要性衡量的需求.一个级别更高(重要性高)的节点做出的正、负评价更具可信性,同时,2个节点的级别(重要性)对于2个节点间连边正负号的形成也是有影响的.因此可以将PageRank的思想引入到符号网络. PageTrust则是一个PageRank的扩展算法,它可以处理正号边与负号边并存时节点重要性度量的问题,笔者将节点u和节点v对应的PageTrust值作为连边(u, v)符号预测的2个特征.
1.3 特征组合与分类方法为考查不同特征在连边符号预测中扮演的重要程度,将上述网络特征进行3种形式的组合:Ⅰ.结构平衡特征(三角形结构+四边形结构);Ⅱ.结构平衡与PageTrust;Ⅲ.全部网络特征(所论述的9类特征).在Ⅰ组合中的三角形结构对应一个4维向量,如[4, 2, 0, 2].假如考查边是+号,则[4, 2, 0, 2]向量表示包含考查边的+++、+--、+-+、++-符号模式的三角形个数分别为4、2、0、2.对于Ⅰ组合中的四边形结构采用上述类似分析方法得到一个8维向量.因此Ⅰ组合最终对应一个12维的特征向量.对于Ⅱ组合中的PageTrust特征,对文献[6]中的方法进行了实现,求出所有节点对应的PageTrust值.考查边的2个端点对应的PageTrust值构成一个2维向量.最终Ⅱ组合对应一个14维的特征向量.地位理论特征与PageTrust特征处理过程类似. Ⅲ组合包含所论述的9类特征,共组成一个21维特征向量.
笔者使用2类监督机器学习分类算法来对连边符号进行预测. Logistic回归模型是对数线性模型的一种特殊形式.当对数线性模型的一个二分类变量被当作因变量,并定义一系列自变量函数时,就变成了Logistic模型. Logistic回归将学习到一个如下形式的模型:
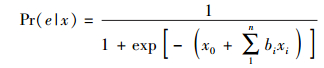
|
(1) |
其中:exp表示指数函数,bi为需要通过训练得到的权重系数,xi为连边对应的各种特征的值.在预测过程中,如果Pr(e|x)>0.5,则连边e的符号被预测为1,即正号;否则,连边e的符号被预测为-1,即负号.
支持向量机(SVM, support vector machine)是根据Vapnik提出的统计学习理论发展而来的.当训练集线性可分时,SVM的目标就是构造线性最优分类超平面wx+b=0,将2类样本完全正确地分开,并使分类间隔最大化,其优化问题如下:
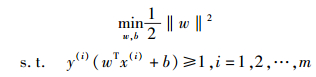
|
(2) |
其中:w为需要通过训练得到的权重系数向量,x(i)为第i个训练样本对应的特征向量,y(i)为第i个训练样本对应的标注(连边的符号),‖w‖2表示权重向量w的2-范数.当找到最优超平面后,就可以根据每个连边相对超平面的位置来对该连边的符号做出预测.
2 实验数据主要收集了2种真实符号网络数据集,分别为Epinions和Slashdot.其中,Epinions是一个在线商品评价网站,Slashdot是一个资讯科技网站.
2.1 网络数据集统计分析对2种网络数据集的基本信息进行了统计,如表 1所示.
|
|
表 1 网络数据集统计信息 |

2种网络数据集对应的度分布对数图如图 3和图 4所示,很明显这2种数据集的度分布都符合幂率分布.

|
图 3 Epinions网络度分布 |

|
图 4 Slashdot网络度分布 |
使用Matlab对Logistic回归算法进行了实现,同时使用Matlab版本的LIBSVM[7]软件包对特征数据进行SVM模型训练与测试. 2类算法均是使用规格化后的特征向量与考查边符号作为输入进行模型训练的.
实验按照上述3种特征组合进行特征提取并对模型进行训练和预测.另外,由于所选取符号网络数据集中正、负连边的比例并不是相等的,所以在生成训练数据与测试数据时分2种情况进行.其中,表 2对应的数据是正、负连边比例各为50%的情况;而表 3对应的数据是正号连边占85%,负号连边占15%的情况.另外,为了得到可靠的预测准确率,实验采用了十折交叉验证,最终结果出现在表 2和表 3中.
|
|
表 2 不同网络特征所学模型预测准确率(正边:50%) |

|
|
表 3 不同网络特征所学模型预测准确率(正边:85%) |
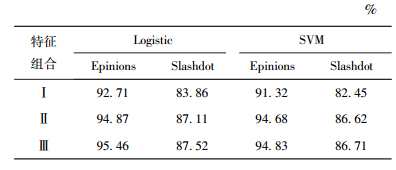
结构平衡特征可以为符号网络的连边符号预测提供重要支持,尤其将四边形结构平衡特征引入后,预测准确度较已有文献只使用三角形平衡特征有显著提高.在Epinions网络数据集中,仅使用结构平衡特征就能获得87.75%(表 2)和92.71%(表 3)的较高预测准确率.这也进一步验证了适当扩大结构平衡环的长度可以为连边符号预测提供更多的信息.对于长度大于5的结构平衡环在所用2种数据集中所占比例非常小,因此只重点考虑了三角形和四边形2种结构平衡环.
全局特征PageTrust的引入,对连边符号预测的准确率有较大提升.这一方面验证了符号网络中节点“重要性”对两节点间连边的正负有较大影响,另一方面也说明了将网络局部特征与全局特征进行融合可以获得更多有利于连边符号预测的信息.另外,全部网络特征对应的预测结果相比结构平衡与PageTrust的预测结果并没有显著提高.其主要原因是地位网络特征和PageTrust特征都是全局网络特征,两者在提供连边正负预测信息方面具有重叠性.另外,在使用全部网络特征的情况下,所提学习模型在Epinions网络数据集上获得95.46%的预测准确率,优于使用相同数据集的文献[4]获得的93.5%的准确率.
复杂的SVM模型相对于简单的Logistic模型在符号网络连边符号预测问题上并没有表现出优势,有些结果甚至还不如Logistic模型.这可能与本实验所使用的数据集规模不够大有一定关系.此外,训练得到的机器学习模型还表现出具有跨网络数据集的通用性.这种通用性具体表现如表 4所示.此数据的获得是在训练机器学习模型时分别使用Epinions和Slashdot单一数据集,而在测试时则使用在其中一个数据集上训练得到的模型同时在2个测试数据集上进行预测. 2组数据均较好地反映了所得机器学习模型的通用性.分析其原因,应该是真实的符号网络在结构上总是有很多相似之处的.
|
|
表 4 通用性预测准确率 |

在深入分析各种影响连边符号机理的基础上,抽取出一组最能反映网络局部属性和全局属性的网络特征,利用这些与连边正负密切相关的网络特征对2类机器学习模型进行训练和测试. 2个真实网络数据集上的实验结果表明,抽取出的网络特征能揭示网络连边符号形成的机制,训练出的模型能获得更高的预测准确率和更好的通用性.对更多能反映连边符号形成的网络特征进一步探索是下一步工作的重点,另外,使用更多的真实网络数据集来进一步验证学得模型的通用性也是未来的工作.
| [1] | Guha R, Kumar R, Raghavan P, et al. Propagation of trust and distrust[C]//Proceedings of the 13th International Conference on World Wide Web(WWW). USA: ACM Press, 2004: 403-412. |
| [2] | Kunegis J, Lommatzsch A, Bauckhage C. The slashdot zoo: mining a social network with negative edges[C]//Proceedings of the 18th International Conference on World Wide Web(WWW). ESP: ACM Press, 2009: 741-750. |
| [3] | Liu Haifeng, Lim E P, Lauw H W, et al. Predicting trusts among users of online communities: an epinions case study[C]//Proceedings of the 9th ACM Conference on Electronic Commerce. USA: ACM Press, 2008: 310-319. |
| [4] | Leskovec J, Huttenlocher D, Kleinberg J. Predicting positive and negative links in online social networks[C]//Proceedings of the 19th International Conference on World Wide Web(WWW). USA: ACM Press, 2010: 641-650. |
| [5] | Chiang K Y, Natarajan N, Tewari A, et al. Exploiting longer cycles for link prediction in signed networks[C]//Proceedings of the 20th ACM International Conference on Information and Knowledge Management(CIKM). USA: ACM Press, 2011: 1157-1162. |
| [6] | De Kerchove C, Van Dooren P. The PageTrust algorithm: how to rank web pages when negative links are allowed[C]//SIAM International Conference on Data Mining(SDM). USA: ACM Press, 2008: 346-352. |
| [7] | Chang Chihchung, Lin Chihjen. LIBSVM: a library for support vector machines[J].ACM Transactions on Intelligent Systems and Technology, 2011(2): 1–27. |