


为了消除文本中命名实体的歧义,提出了一种结合实体链接与实体聚类的命名实体消歧算法,结合2种方法,可弥补单独使用其中一种方法的局限.该算法在背景文本中将待消歧实体指称扩充为全称,使用扩充后的全称在英文维基百科知识库中生成候选实体集合,同时提取多种特征对候选实体集合进行排序,对于知识库中没有对应实体的指称使用聚类消歧.实验结果表明,该算法在KBP2011评测数据上的F值为0.746,在KBP2012评测数据上的F值为0.670.
In order to eliminate the ambiguity of named entities in the documents, a named entity disambiguation algorithm combining entity linking and entity clustering is proposed, and the proposed algorithm combines two methods to compensate for the limitations of only using one of the methods. The proposed algorithm expands the mentions in the background document firstly, and generates candidates in the English Wikipedia knowledge base for expansions secondly, then extracts a variety of features to rank candidates, lastly uses clustering to disambiguate the mentions which has none candidates in the knowledge base. The experimental results show that, in the proposed algorithm, the F measure in KBP2011 data set is 0.746 and the F measure in KBP2012 data set is 0.670.
命名实体消歧(NED, named entity disambiguation)是自然语言处理(NLP, natural language processing)中的一项基础研究,在NLP的研究和应用中有着重要作用,是不可缺少的一环.提高NED的准确性和实用性,可以更好地为开发通用、高性能的NLP系统奠定基础.
为解决消歧问题,笔者提出了一种结合实体链接与实体聚类的英文NED算法.该算法主要对3种命名实体即人名(person)、地名(geographic)及组织机构名(organization)进行消歧,通过实体指称扩充、候选实体生成、候选实体排序及无指代实体聚类4个部分来减少命名实体存在的歧义.
1 NEDNED研究的主要内容是根据给定的背景文本消除该文本中实体指称(mention)的歧义.命名实体歧义指一个给定的命名实体指称可能同时具有多个含义,即同时指向多个实体.
由于自然语言的灵活性和多样性,命名实体歧义这种现象广泛存在,给NLP带来了一定的困难.这种困难主要体现在下述2个方面[1].
1) 命名实体指称多样性:一个命名实体可以用多种方式表达.
2) 命名实体指称歧义性:一个指称可能表示不同的命名实体.
2 国内外研究现状目前国内外对NED的研究已经有几十年的历史,比较受认可的主流研究方法主要有2种:命名实体聚类消歧和命名实体链接消歧[1].命名实体聚类消歧是利用聚类算法来对实体进行消歧.命名实体链接消歧则是借助外部知识库将待消歧命名实体指称链接到外部知识库中对应实体来进行消歧.
随着NED问题逐渐变得复杂,仅仅使用实体聚类消歧算法已经无法应付现在的NED任务.而命名实体链接消歧能很好地达到消歧目的.实体链接消歧不仅能将不同的待消歧命名实体指称区分开,而且能显示出待消歧命名实体指称的确切含义.
Bunescu和Pasca首次提出了一种基于余弦相似性排序的方法来实现NED[2]. Cucerzan利用维基百科页面等信息提取语义知识来进行消歧[3]. Sean Monahan等[4]将实体链接重定义为跨文本的共指消解问题.谭咏梅等[5]使用语义及主题等特征取得了较好的结果. Ben Hachey等的工作结果表明,共指消解和缩写词的处理在系统性能的提升方面有很大贡献[6].
中文方面NED的研究也已经取得了很大进展.史天艺和李明禄[7]提出了一种多策略的无监督算法来对命名实体进行消歧.杜婧君等使用维基百科页面等信息,在待消歧命名实体指称上下文文本的基础上进行中文命名实体的消歧[8].但是由于使用的数据资源及研究语言的不同,无法将其与本文的算法进行比较.
以往的研究中,研究人员只集中在实体链接或聚类方法中的一种来解决消歧问题.然而,这2种方法都有其局限性.实体链接主要借助于知识库的信息,使得该方法主要依赖于知识库的规模.实体聚类方法虽然不受知识库规模的限制,然而无法准确地链接到指称所指向的实体.为了解决这些问题,提出了一种结合2种方法优点的消歧算法,首先根据维基百科知识库的信息,使用实体链接的方法进行消歧,接着使用实体聚类的方法弥补知识库规模不足这一问题.因此该方法是具有创新性的一种方法,能在一定程度上弥补现有方法的不足.
3 结合实体链接与实体聚类的NED结合实体链接与实体聚类的NED算法包括4个部分:实体指称扩充、候选实体生成、候选实体排序及无指代实体聚类.该算法流程如图 1所示.

|
图 1 算法流程 |
实体指称往往具有歧义,实体指称扩充的主要任务是根据实体指称所在的背景文本,将其扩充为全称以减少歧义.对实体指称进行扩充能极大地减少歧义,获得更好的消歧效果.
算法主要针对首字母缩写词以及简称形式的实体指称进行扩充.为描述方便,设实体指称为M,其扩充词尾Exp,具体方法如下所述.
1) 首字母缩写词扩充:首字母缩写词指的是通过组合每个词的首位字母构成的新词或专有名词.
对于一个首字母缩写词M=m1m2…mn,其长度为n且M的对应背景文本为D.首先在D中查找“M (Exp)”标记,若存在相关标记,则Exp为M的扩充词;若不存在这样的标记,则查找“(M)”标记,在标记处向前查找最长的连续序列Exp,Exp不包括标点符号或者多于2个停用词.
由于背景文本多为非结构性的文本,在大多数背景文本中无法找到上述2种文本标记.对于这样的实体指称,则在文本中查找到以M的第1个字母m1为首字母的词,向后查找最长连续序列Exp作为扩充词,Exp不包括标点符号或者多于2个停用词.
2) 简称的扩充:简称指的是由全称的部分词简化而来的词.对于一个简称M,首先在M对应的文本D中查找M所在的位置,并在该位置向前或向后提取出对应的单词作为M的扩充词Exp,Exp全为大写单词或不多于2个停用词.
3.2 候选实体生成候选实体生成的主要任务是为每个实体指称M,在知识库中生成可能的候选实体集合SET(EM).算法使用的知识库是维基百科知识库,在生成候选实体之前,首先需要对知识库进行处理,找到每个实体E的对应指称集合SET(ME).在维基百科知识库中,可提取的资源如下所述.
1) 页面标题:每篇维基百科描述实体的指称形式.在实体E对应的维基百科XML页面中,页面标题以<title>ME</title>格式表示,即ME是E的一个指称形式.
2) 重定向信息:重定向页面指向另一个同义词实体页面.重定向信息以{{Redirect|ME}}格式表示,即ME是E的一个指称形式.
3) 锚文本:内部超链接的描述文本,在维基百科中以[[E|ME]]或[[E(ME)]]格式描述,即ME是E的一个指称形式.
4) 消歧信息:消歧页面以“(disambiguation)”结尾,其标题为该页面描述的实体共同指称形式.
算法根据上述几种资源找到实体E对应的所有指称形式,将其描述为一个指称集合SET(ME),若实体指称M跟集合中某一指称形式完全匹配,则该实体E为查询词M的一个候选实体.由于知识库中资源有限,无法为所有的查询词生成对应的候选实体,将那些无法生成候选实体的实体指称定义为无指代实体,以nil表示,并将该实体指称加入无指代实体集合SET(nil)中.
3.3 候选实体排序对于每个在候选实体生成步骤生成候选实体集合SET(EM)的实体指称M,通过排序选择出最优实体Etop组成<M, Etop>对.
每个生成候选实体的实体指称M,都对应着一个候选实体集合SET(EM),该候选集合可以表示为{EM1, EM2, …, EMi, …, EMn},将这个集合中的所有EM与M组成指称——候选实体对<M, EM>.首先对每个<M, EM>对提取多重特征,接着使用支持向量机排序(Ranking-SVM, ranking support vector machine)方法来进行排序以选取最优实体.每个<M, EM>对都被表示成一个特征向量的形式,主要提取的特征如表 1所示.
|
|
表 1 特征总览 |
经过候选实体排序后,每个实体指称M分别对应一个最优候选实体Etop,此时使用SVM方法训练一个二分类模型来判断Etop是否为实体指称M所指向的实体.在训练模型的过程中,使用与候选实体排序相同的特征.如果Etop不是M所指向的实体,则将M定义为无指代实体,以nil表示,并将该实体指称加入无指代实体集合SET(nil)中.
3.4 无指代实体聚类对于3.2节和3.3节中生成的无指代实体集合SET(nil)中的所有实体指称,消歧算法主要使用层次凝聚聚类(HAC, hierarchical agglomerative clustering)的方法来进行聚类消歧.将代表同一种实体的不同实体指称聚为一类,可以弥补知识库的不足,从而达到消歧的目的.
具体使用的聚类消歧方法:① 对每个无指代实体指称,提取表 1所述的所有特征,将该实体指称表示为一个特征向量;② 根据提取的特征,使用HAC算法对所有无指代实体指称进行聚类;3) 将每类无指代命名实体指称标记为NILxxx(xxx为与已知序号不重复的任意序号),这样虽然无法给出每类实体指称的确切含义,但能从类别上进行区分,即NIL001与NIL002指代的是不同的实体.
4 实验4.1 评价方法为了便于比较,使用B-Cubed+方法来对实验结果进行评价. 2个实体指称之间关系的正确性计算方法为
|
(1) |
其中:L(e)和C(e)为实体指称e的类别,SI(e)GI(e)为系统和正确答案中,实体指称e指代的实体.也就是说,2个实体指称拥有正确的关系当且仅当它们为同一个类别且指向正确的实体. B-Cubed+方法中一个实体指称的精度是在这个类别中正确关系的比例.正确率P、召回率R和F值的计算方法分别为

|
(2) |
|
(3) |
|
(4) |
为了验证方法的有效性,实验所用数据为KBP评测2011年和2012年Entity Linking数据. KBP2011数据包括2 250个实体指称,KBP2012数据包括2 229个实体指称. KBP2011和KBP2012数据均包括3种命名实体,即人名、地名及组织机构名.算法使用2008年10月版本的英文维基百科作为知识库,该知识库共包含818 741个实体条目.
表 2为在KBP2011和KBP2012数据集上的最优实验结果.
|
|
表 2 实验结果 |
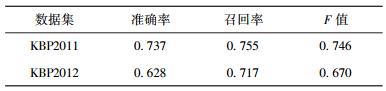
为了更好地说明所提方法是可行的,特将实验结果与BUPTTeam参加KBP2012评测时的结果进行了对比,如表 3所示.
|
|
表 3 实验结果对比 |

在表 3中,KBP2012结果为使用提出的结合实体链接与实体聚类的消歧算法进行实验得出的结果,BUPTTeam1、BUPTTeam2、BUPTTeam3为BUPTTeam参加KBP2012评测的3组实验结果,KBP2012平均结果为所有参加KBP2012评测队伍提交结果的平均值.由表 2、表 3可以看出,结合实体链接与实体聚类的消歧算法的实验结果远远高于平均结果,且对于KBP2012评测结果有了大幅度的提高,说明了方法的有效性.
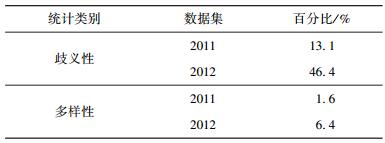
另外,由表 2可以看出,KBP2012数据集上结果低于KBP2011数据集结果,主要有2方面原因:实体指称的歧义性、实体指称的多样性. 表 4示出了2个数据集的歧义性及多样性.歧义性指的是在数据集中可指代多个实体的指称所占百分比,多样性指的是可用多个指称表示的实体所占百分比.由此可见,歧义性与多样性制约着实体消歧的性能,即歧义性与多样性越高,消歧性能越差.
|
|
表 4 歧义性及多样性统计 |
为了解决实体歧义问题,提出了一种结合实体链接与实体聚类的NED算法.为了验证方法的有效性,在公开的数据集上做了大量实验,且实验结果说明了该算法的有效性.这种算法能提高NED系统的性能,但仍然有一些问题需要解决: ① 地名实体消歧仍然难点很多,较小地方的地名需要背景知识来进行消歧;② 知识库规模也制约着系统消歧性能,尽管维基百科已经包含了上百万个实体,但仍然不能包含每个真实存在的实体,这给无指代实体的聚类增加了困难.
| [1] |
赵军, 刘康, 周光有, 等. 开放式文本信息抽取[J]. 中文信息学报, 2011, 25(6): 98–110.
Zhao Jun, Liu Kang, Zhou Guangyou, et al. Open text information extraction[J].Journal of Chinese Information, 2011, 25(6): 98–110. |
| [2] | Bunescu R C, Pasca M. Using encyclopedic knowledge for named entity disambiguation[C]//Proceedings of the Conference of the European Chapter of the Association for Computational Linguistics, 2006, 6: 9-16. |
| [3] | Cucerzan S. Large-scale named entity disambiguation based on wikipedia data[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2007, 7: 708-716. |
| [4] | Monahan S, Lehmann J, Nyberg T, et al. Cross-lingual cross-document coreference with entity linking[C]//Proceedings of the Text Analysis Conference, 2011. |
| [5] | Tan Yongmei, Wang Zhichao, Yang Xue, et al. BUPTTeam participation at TAC 2012 knowledge base population[C]//Proceedings of the Text Analysis Conference, 2012. |
| [6] | Hachey B, Radford W, Nothman J, et al. Evaluating entity linking with wikipedia[J].Artificial intelligence, 2013, 194: 130–150. doi: 10.1016/j.artint.2012.04.005 |
| [7] |
史天艺, 李明禄. 基于维基百科的自动词义消歧方法[J]. 计算机工程, 2009, 35(18): 62–66.
Shi Tianyi, Li Minglu. Automatic word sense disambiguation method based on wikipedia[J].Computer Engineering, 2009, 35(18): 62–66. doi: 10.3778/j.issn.1002-8331.2009.18.020 |
| [8] |
杜婧君, 陆蓓, 谌志群. 基于中文维基百科的命名实体消歧方法[J]. 杭州电子科技大学学报, 2013, 32(6): 57–60.
Du Jingjun, Lu Bei, Chen zhiqun. Named entity disambiguation[J].Journal of Hangzhou Dianzi University, 2013, 32(6): 57–60. |