


2. 华夏银行股份有限公司 科技开发中心, 北京 100005
为实现Hadoop分布式文件系统的负载均衡,并保证较低的负载迁移代价和数据传输代价,提出了确定环境下多阶段多目标(CMM)决策模型.该模型以CPU、内存和磁盘剩余负载能力作为决策条件,以负载均衡效果、负载迁移代价和数据传输代价作为决策目标,依据决策节点间的影响关系构建有向无环图,通过多个决策阶段的决策,并计算方案效用确定最优均衡方案.仿真实验结果表明,基于CMM模型的负载均衡策略能取得较好的负载均衡效果、负载迁移代价和数据传输代价.
2. Science and Technology Development Center, Hua Xia Bank Limited Company, Beijing 100005, China
In order to balance the load of Hadoop distributed file system with lower load migrating cost and data transmission cost, a certainty multi-stage and multi-object (CMM) decision model was proposed. The model is a directed acyclic graph built on decision nodes, which adopts the remaining load capacities of CPU, memory and disk as decision preconditions, and also adopts load balancing effect, load migrating cost and data transmission cost as decision targets. By CMM model, the best balancing plan is determined by selecting results of multiple decision stages and computing the plan usage. Simulations show that the CMM based strategy can achieve better load balancing effect, load migrating cost and data transmission cost.
随着新数据写入、作业调度以及数据节点的加入和退出,Hadoop分布式文件系统(HDFS, hadoop distributed file system)集群会出现负载失衡,从而导致集群性能下降. HDFS提供了一种默认的基于机架感知的负载均衡策略[1],基于磁盘利用率实现优先机架内然后机架间的负载均衡,但没有考虑集群中数据节点的配置差异以及CPU和内存的负载失衡问题.文献[2]提出了一种超负载机架的优先平衡策略,能快速实现超负载机架的负载均衡,但没有兼顾负载迁移代价和数据传输代价.文献[3]提出了一种基于改进模糊聚类分析的负载均衡方法,能快速判断负载均衡时执行迁移任务的节点.该策略使用输入/输出速度和磁盘、CPU利用率作为评价指标,但仍没考虑节点间的性能差异.
本研究的目标是提出一种能准确反映数据节点的剩余负载能力,兼顾CPU、内存和磁盘负载均衡效果、负载迁移代价和数据传输代价的负载均衡策略.为此,提出了CMM决策模型,以解决HDFS的负载均衡决策问题.
1 CMM模型建立CMM模型是由决策节点和代表决策节点之间逻辑关系的有向边组成的有向无环图.
1.1 决策节点的设计CMM模型定义了5类决策节点,其设计如下.
1) 决策环境节点
决策环境节点是提前收集的先验信息,不受决策者控制.设计3个决策环境节点:CPU、内存和磁盘的剩余负载能力,即C={C1, C2, C3}.采用均值归一化进行统一度量,方法如下.
设di(i=1, 2, …, n)为HDFS集群中n个数据节点的磁盘剩余容量,上述剩余容量的算术平均值为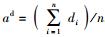
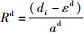
2) 决策选择节点
设计4个决策选择节点,D={D1, D2, D3, D4},代表4个决策阶段.每个决策阶段有一组决策结果供决策,即Di={di1, di2, …, dik}.决策选择节点之间在时间和逻辑上存在先后关系,前一阶段的结果会影响后一阶段的选择结果.
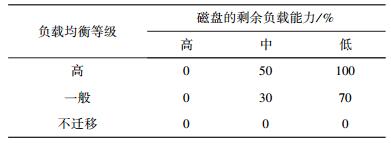
D1为负载均衡等级,用于衡量整个系统的负载均衡紧迫程度,有3个选项:高、一般、不迁移. D2为迁出概率阈值,表示将数据节点加入到相应迁出队列的概率阈值,有3个选项:50%、70%和100%. D3为迁移数据,用于从迁出队列的数据节点上选出需要执行迁移任务的数据块,根据1.3节的算法1选择. D4为优先实现目标,用于对负载均衡的目标进行选择,选项有负载均衡效果、负载迁移代价和数据传输代价.
3) 决策传递节点
决策传递节点由前一个决策阶段的选择结果得出,并为下一阶段的决策提供先验信息.设计7个决策传递节点,即E={Ei|1≤i≤7}.
动态数据迁移概率E1:动态数据是指被调入到内存用以执行调度任务的数据. CPU和内存使用情况都与正在执行的任务有关,因此取这2个环境节点的剩余负载能力等级的最小值,即M=min(C1, C2). E1由C1、C2和D1共同决定,其概率分布P(E1|M, D1)如表 1所示.
|
|
表 1 动态数据迁移概率的概率分布表 |

静态数据迁移概率E2:静态数据是指没有执行任务调度的数据,与磁盘使用情况有关.因此E2的值由C3和D1决定,概率分布P(E2|C3, D1)如表 2所示.
|
|
表 2 静态数据迁移概率的概率分布表 |
迁出动态数据数据节点列表E3:需要执行动态数据迁出操作的数据节点.将集群中动态数据迁移概率E1大于D2选择结果的数据节点加入E3.
迁出静态数据数据节点列表E4:需要执行静态数据迁出操作的数据节点.将集群中静态数据迁移概率E2大于D2选择结果的数据节点加入到E4中. 1个数据节点可能同时位于E3和E4 2个队列.
动态数据迁出列表E5:需要执行迁移任务的动态数据,由E3中的迁出数据节点和D3选择的迁出数据列表组合得出.
静态数据迁出列表E6:需要执行迁移任务的静态数据,由E4中的迁出数据节点和D3选择的迁出数据列表组合得出.
迁移任务列表E7:负载均衡方案中需要执行的数据迁移任务,是以E5、E6为条件信息,对D4进行决策的结果.一个迁移任务由迁出数据节点、动态及静态数据和迁入数据节点列表组成.
4) 决策目标节点
设计3个决策目标节点:负载均衡效果O1、迁移代价O2、数据传输代价O3,即O={O1, O2, O3},分别代表负载均衡方案执行后各数据节点上负载的均衡程度、负载迁移代价和集群中数据到用户之间的传输代价.
5) 决策价值节点
设计3个决策价值节点:剩余负载能力方差V1、迁移时间V2和数据到用户的平均距离V3,分别对O1、O2和O3进行量化度量.为了消除用户所处网络环境差异对方案评价的影响,计算V3时采用用户到数据所在数据节点的路由跳数减去用户与HDFS中距离最近的数据节点之间的路由跳数.
1.2 模型建立基于1.1节中决策节点之间的依赖关系可以建立负载均衡问题的CMM决策模型,如图 1所示.

|
图 1 CMM决策模型 |
CMM模型的决策过程:首先,根据D1的选择结果和3个环境节点决策出数据迁移概率E1和E2;然后,以E1和E2作为条件信息,根据D2的选择结果决策出需要执行数据迁移任务的数据节点列表E3和E4;之后,将E3和E4中迁出数据节点和D3中相应类型数据组合,得到迁出数据节点的动态和静态数据迁出列表E5和E6;最后,进行D4的决策选择,以E5和E6为条件信息决策出迁入数据节点列表,得出迁移任务列表E7.每完成一轮4个决策阶段的选择之后就确定了一种负载均衡决策方案,通过决策价值节点对决策目标进行评估,可以确定针对特定决策目标的最优决策方案.
1.3 算法描述算法1:迁移数据选择
输入: E3, E4
输出: D3
1.T←ϕ; list1←ϕ; list2←ϕ; list3←ϕ
//T用于临时存储数据节点的静态数据或动态数据
//list1、list2、list3用于存储需要执行迁移任务的数据块
//ϕ为空值
2.for each (dn in E3){
3. T←所有动态数据//用一个数据节点上的所有动态数据填充T
4. i←1
5. while(3次){
6. //随机选出能满足负载均衡要求的数据块列表
7. while(数据节点CPU/内存负载高于平均值){
8. Blocklist←add(Random(T))
9. }
10. listi.Push(Blocklist)
11. i++
12. }
13.}
14.Blocklist←ϕ
15.for each (dn in E4){
16. T←所有静态数据//用数据节点上的所有静态数据填充T
17. i←1
18. while(3次){
19. //随机选出能满足负载均衡要求的数据块列表
20. while(数据节点磁盘负载高于平均值){
21. Blocklist←add (Random(T))}
22. listi.Push (Blocklist)
23. i++}
24.}
25.D3.Push(list1, list2, list3)
2 CMM模型求解CMM模型的求解过程就是利用决策价值节点求解决策方案最终效用的过程.
2.1 剩余负载能力方差求解首先求出CPU的剩余负载能力方差:
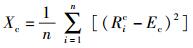
|
其中:n为数据节点数量,Ric为第i个数据节点的CPU负载指标归一化值,Ec为所有数据节点CPU负载指标归一化值的期望值,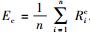
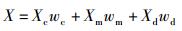
|
其中wc、wm、wd分别为CPU、内存和磁盘负载指标的权重,wc+wm+wd=1.
2.2 迁移时间求解迁移时间T度量负载均衡方案的迁移代价,则
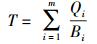
|
其中:m为迁移任务的个数,Qi为第i次迁移的数据量大小,Bi为第i次迁移中,迁出和迁入节点之间的带宽.
2.3 数据传输代价求解数据到用户的平均距离用来衡量负载均衡方案的数据传输代价,集群中所有迁移数据的数据传输代价之和为
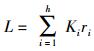
|
其中:Ki为数据块i的数据到用户的平均距离,反映数据储存位置到用户的平均网络距离,Ki= 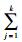

由于3个决策价值节点的值度量单位不同,在求出每个负载均衡方案的3个决策价值节点值后,采用极差格式化法将所有负载均衡方案的3个评价值格式化为可以统一度量的值,格式化的结果为介于0~1之间的小数.剩余负载能力方差的极差格式化方式为

|
其中:Xmax为所有负载均衡方案剩余负载能力方差的最大值,Xmin为最小值.同样,可求出迁移时间和传输代价的格式化值T′和L′.最后,求出每个负载均衡方案的最终效用值为
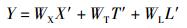
|
(1) |
其中WX、WT、WL为权重.根据式(1) 计算方案价值评价列表并排序,得出最优负载均衡决策方案.
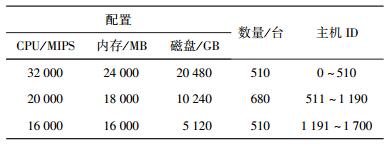
3 仿真实验3.1 仿真环境基于cloudsim云仿真平台[4]对方案进行仿真实验,并将仿真结果与HDFS默认的负载均衡策略以及文献[3]的策略进行比较.以2011年的淘宝Hadoop集群的1 700台主机规模为基准[5],将1 700台主机随机分布在10个机架上,并构建一个170×170的路由跳数矩阵来仿真HDFS集群的网络拓扑,矩阵中每个元素均为1~10的随机值,机架内节点间的路由跳数为0.设置3种不同配置的主机,具体主机数量及配置如表 3所示.
|
|
表 3 仿真环境主机配置列表 |
设置如下参数:
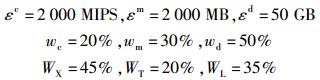
|
进行了3个仿真实验:负载均衡效果仿真、迁移代价仿真和数据传输代价仿真.在仿真实验中,dmlb为本研究提出的基于CMM决策模型的负载均衡方案,hdfslb为HDFS默认的负载均衡方案,fcmlb为文献[3]提出的负载均衡方案.
1) 负载均衡效果
图 2所示为dmlb与hdfslb的磁盘剩余负载能力对比,均衡前不同配置节点的磁盘剩余负载能力较分散且呈阶梯状分布;进行hdfslb之后,同类型配置节点之间的剩余负载能力分布集中,但不同配置节点之间没有实现负载均衡;而进行dmlb之后,不同配置节点之间的磁盘剩余负载能力分布集中,实现了集群整体的磁盘负载均衡.

|
图 2 CMM模型和HDFS默认策略的磁盘均衡效果 |
从图 3和图 4中可以看出,均衡前各节点的剩余负载能力比较分散,并呈阶梯分布;在进行dmlb后,CPU和内存剩余负载能力大多集中在均值周围,说明基于dmlb不仅很好地均衡了磁盘负载,也很好地均衡了CPU和内存负载;fcmlb在一定程度上均衡了CPU负载,但并没有在CPU性能差异较大的数据节点间实现负载均衡.

|
图 3 CMM模型和文献[3]方案的CPU均衡效果 |

|
图 4 CMM模型的内存均衡效果 |
2) 迁移代价
为了衡量迁移代价,分别用2种负载均衡策略进行了11次实验.仿真使用Ncdc气象数据集[5]中的数据模拟文件写入操作和数据调度操作.
如图 5所示,开始时,dmlb的迁移代价略高于hdfslb.这是因为在仿真系统初始化时已经根据HDFS数据放置策略写入了一部分数据,这时数据节点之间磁盘利用率差异较小、剩余负载能力差异大,dmlb需要从高配置节点迁移更多的数据到低配置节点.随着数据规模的扩大,HDFS数据放置策略的影响不断降低,dmlb的优势开始显现.数据规模越大,作业调度越频繁,dmlb迁移代价的优势越明显. fcmlb聚类时考虑到了节点间的I/O速度,且没有在性能差异大的数据节点间大量迁移数据,所以在数据规模较小时fcmlb的迁移代价具有明显优势.但是随着数据规模的增加,低端配置数据节点利用率上升很快,造成fcmlb频繁地将数据从低端配置数据节点迁移到高端配置数据节点,这时dmlb的迁移代价明显低于fcmlb.

|
图 5 迁移代价变化曲线 |
3) 数据传输代价
从图 6中可以看出,hdfslb的数据传输代价呈平滑的对数曲线上涨.在数据规模比较小时,数据块的数据传输代价分布差异很大;当数据量增长到一定规模后,数据块的数据传输代价分布相对平均,系统的数据传输代价逐渐趋于平稳. fcmlb由于同样没有考虑数据传输代价,它的变化趋势和hdfslb接近.在dmlb作用下,系统的数据传输代价及其增长速度明显要小,即使在数据规模比较小时,系统的数据传输代价也没有快速增长,这是因为该策略在数据迁移时尽量把数据块迁移到与它距离最近的数据节点.另外,dmlb除了考虑数据传输代价外,还考虑了均衡效果和迁移代价,所以其数据传输代价不像hdfslb那样呈平滑的曲线上升,而是波动上升.可见,本研究提出的负载均衡策略能更好地将数据块均衡到距离用户最近的数据节点,使得系统的传输代价更低、响应速度更快.

|
图 6 数据传输代价变化曲线 |
提出的HDFS负载均衡策略将负载均衡问题涉及的因素抽象为决策变量建立CMM决策模型,通过模型求解得出最优负载均衡方案.在负载均衡效果方面,综合考虑了CPU、内存和磁盘负载情况,能实现综合负载均衡,避免了由于单一指标负载失衡造成的系统瓶颈.在迁移代价方面,本研究提出的策略更适合数据规模较大的情况.
研究发现,在HDFS集群运行的不同阶段或者不同应用中,负载均衡的目标可能不同.在系统运行初期,数据规模较小,大部分数据节点的剩余负载能力较大,这时可以重点考虑迁移代价和传输代价.本研究提出的均衡策略的灵活之处在于,可以通过调整决策价值节点的权重来选择不同的最优负载均衡方案.但是,这些决策价值节点的权重值是此消彼长的关系,如何在不同的应用场景,根据不同的负载均衡目标设置这些权重值还需要进一步的理论和数据分析.
| [1] | Wang Jun, Xiao Qiangju, Yin Jiangling, et al. DRAW: a new data-grouping-aware data placement scheme for data intensive applications with interest locality[J].IEEE Transactions on Magnetics, 2013: 1–8. |
| [2] |
刘琨, 肖琳, 赵海燕. Hadoop中云数据负载均衡算法的研究及优化[J]. 微电子学与计算机, 2012, 29(9): 18–22.
Liu Kun, Xiao Lin, Zhao Haiyan. Research and optimize of cloud data load balancing in Hadoop[J].Micro-electronics and Computer, 2012, 29(9): 18–22. |
| [3] |
姚婧, 何聚厚. 基于模糊聚类分析的云计算负载平衡策略[J]. 计算机应用, 2012, 32(1): 213–217.
Yao Jing, He Juhou. Load balance strategy of cloud computing based on fuzzy clustering analysis[J].Journal of Computer Application, 2012, 32(1): 213–217. |
| [4] | Rodrigo N, Calheiros, Rajiv Ranjan, et al. CloudSim: a toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms[J].Software: Practice and Experience, 2011, 41(1): 23–50. doi: 10.1002/spe.v41.1 |
| [5] | Whait. Hadoop, the definitive guide[M]. [s.l.]: O'Reilly Media, Inc, 2010: 573-575. |