


为了解决推荐中存在的数据稀疏、准确度不高等问题,提出了一种基于用户信任网络的推荐方法.首先利用基本的社会网络,融合用户的基本信任关系、角色影响力、属性相似关系、偏好相似关系构造带权重的社会网络;然后基于此网络提出关键路径发现算法以发现满足约束条件的用户信任网络;最后基于用户信任网络进行推荐.在Filmtipset数据集上对影响推荐质量的各个因素进行了对比分析,结果表明,基于用户信任网络的方法能得到更好的推荐效果.
To solve the problem of low recommendation precision and data sparsity in recommendation, a recommendation method based on user trust network was proposed. A weighted user trust network was constructed as well based on basic social network, including the trust relationship, the influence of user role, the similarity of user attribute and similarity of user preferences. Based on the trust network, a key path discovery algorithm was proposed to find user trust network within constrains, which is further utilized for recommendation. The comparison experiments were conducted on Filmtipset dataset. A comparative analysis was made aimed at factors that influence the quality of recommendation. It was shown that the method based on user trust network can achieve better recommendation.
近年来,社会网络信息被引入到推荐过程中,以解决传统的协同过滤推荐算法[1]中存在的数据稀疏性等问题[2].用户信任网络的发现和计算会影响推荐的性能,并且社会网络中用户之间的直接社会关系也比较稀疏.为有效利用社会网络中的用户信任关系进行准确的推荐,需要提供相应的方法和机制来发现并计算用户之间的信任关系.通常基于用户的直接社会关系[3]或随机漫步算法[4]来发现用户之间的信任关系,并基于用户在社会网络中的距离或用户之间评价的相似性来计算其信任权重[5].
为进一步提高推荐的质量,笔者研究了基于用户信任网络的推荐方法.首先给出了用户信任网络的定义;然后基于启发式算法发现从源用户到目标用户的关键路径,计算用户间的基本信任关系,并结合用户的角色影响力、属性相似度、偏好相似度等影响因素,进一步提出用户间综合信任关系的计算方法,基于用户信任网络进行服务的推荐;最后在Filmtipset数据集上对影响推荐质量的各个因素进行了对比分析.
1 用户信任网络针对推荐过程中用户信任网络和推荐精确度问题,本节首先介绍基本的社会网络,并在此基础上综合考虑用户基本信任关系、角色影响力、用户属性相似度、用户偏好相似度等因素,构建一种包含社会上下文信息的用户信任网络.
定义1 社会网络:社会网络是一个有向图G=(U, E),其中U是网络节点集合,表示用户;E为网络中有向边的集合,表示用户之间的社会关系.如果2个节点间存在1条边,则表示它们存在某种相互关系,如图 1所示.

|
图 1 基本社会网络结构 |
在社会网络环境下进行推荐,用户间的信任关系是用户考虑的重要因素.为了进行准确的推荐,需要搜索用户间的信任关系并计算信任强度,基于用户间的信任关系进行推荐.为了更准确地发现并计算用户间的信任关系,综合考虑用户属性相似度、用户偏好相似度、用户角色影响力和用户基本信任关系等因素,给出各个因素的定义如下.
定义2 用户属性相似度(dij):用户属性相似度是指用户属性背景方面的相似性,如性别、年龄、职业和教育背景等.利用余弦相似度计算任意2个用户之间属性相似度为
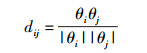
|
(1) |
其中:用户i的属性特征看作是属性特征空间上的向量θi,|θi|表示该向量的模;用户j的属性看作是属性特征空间上的向量θj,|θj|表示该向量的模.每类属性都根据自身的特性归一化到取值空间[0, 1].
定义3 用户偏好相似度(pij):用户偏好相似度指用户在服务上的偏好相似性.利用皮尔逊相关系数计算用户偏好相似度为
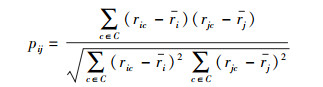
|
(2) |
其中:ri、rj分别为用户i和j对其使用过的所有服务的平均评价值,C为2个用户共同评价过的服务集合;ric和rjc分别为用户i和用户j对服务c的评价值.
定义4 角色影响力(wi):角色影响力指的是社会个体ui在某个社会网络中对其他用户的影响力.
文献[6]利用节点在用户社会网络结构模型中的度来量化计算角色影响力,即
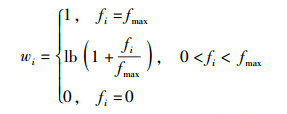
|
(3) |
其中:fi为节点i的度,fmax为社会网络结构中节点的最大度. wi的取值空间为[0, 1].
定义5 用户基本信任关系(tij):用户基本信任关系指用户在社会网络中直接或间接的连接关系,其关系强度可以基于用户在社会网络中路径的长度来计算.用户基本信任关系的强度为
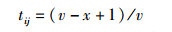
|
(4) |
其中:x为从源节点到目的节点的路径的长度;v为最大路径长度,即算法中的最大搜索深度.
定义6 包含社会上下文信息的用户信任网络:包含社会上下文信息的用户信任网络是一个有向图G=(U, E),其中U代表社会网络中节点(社会中的个体)的集合,E代表网络中有向边的集合.网络中2个节点中存在1条边,除了代表节点对应的个体间存在某种相互关系外,还包含节点间的用户基本信任关系、角色影响力、用户属性相似度、用户偏好相似度等信息,如图 2所示.

|
图 2 包含社会上下文信息的用户信任网络结构 |
定义7 综合信任关系(Tij):用户间的综合信任关系是指综合考虑用户基本信任关系、角色影响力、用户属性相似度、用户偏好相似度等影响因素而计算得到的用户间的信任关系.笔者使用线性方法融合各种因素计算综合信任关系,其计算式为
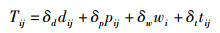
|
(5) |
其中:δd、δp、δw和δt分别为各因素所占的权重,其取值范围均为[0, 1],且各因素之和为1.因此,用户综合信任关系的取值范围为[0, 1].
2 基于用户信任网络的推荐方法基于第1节给出的包含社会上下文信息的用户信任网络的定义,给出用户信任网络发现方法及基于用户信任网络的推荐方法.
2.1 用户信任网络发现算法定义8 关键路径.在社会网络结构图中,ui和uj两个节点间不存在直接相连的边,但源节点ui和目标节点uj之间存在多条路径可以到达.若某条路径所包含的中间节点满足某些影响因子的约束(例如,基于这些中间节点路径计算出的源和目的节点间的信任值在某个区间),则此路径即为从ui到uj的一条关键路径.
为有效搜索社会网络中的关键路径,笔者提出一种启发式的关键路径发现(CPD,critical path discovery)算法来获取路径的近似最优解.
CPD基于宽度优先搜索算法,同时为了提高搜索效率,基于经典的“小世界理论”[7],搜索算法的深度设定为6. CPD的关键是选取搜索过程中的扩展节点,笔者综合关键路径的约束条件和节点在社会网络中的度来定义选择效用函数为
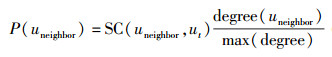
|
(6) |
其中:SC(uneighbor, ut)表示用户uneighbor和ut之间的约束值,约束值包括角色影响力、用户属性相似度、用户偏好相似度;degree(uneighbor)表示某个邻居节点的出度值;max(degree)表示最大度数;P(uneighbor)表示邻居用户uneighbor的选择效用值.
为了确保在搜索过程中后续节点能满足约束条件,P(uneighbor)将约束条件值作为效用函数的因素,节点间约束关系值越高,节点选择效用值越大.而节点度越大,其连接节点越多,则搜索到目标节点的可能性越大,选择效用值越大. CPD算法过程如下.
1) 从源节点出发,作为搜索的起始节点,将满足用户信任网络影响因子约束条件的邻居节点组成的集合作为第2) 步搜索过程中的扩展节点.
2) 计算所有扩展节点的选择效用值,并从高到低进行排序,选取效用值大于阈值a的节点作为第3) 步的扩展节点集合.
3) 判断当前扩展节点集合中选中的扩展节点是否为目标节点,若不是目标节点,则计算从源节点到扩展节点的综合信任关系值,若满足全局约束条件,则将扩展节点加入到当前关键路径中,并返回第1) 步,把当前的扩展节点作为起始节点进行搜索;若不满足全局约束条件,则选取扩展节点集合中的下一个节点.若是目标节点,则计算当前这条关键路径上源节点和目标节点间的全局社会上下文关系值,若满足全局约束条件,则当前搜索过程得到的关键路径有效,选取扩展节点集合中的下一个节点;若不满足全局约束条件,则当前搜索过程得到的关键路径无效,选取扩展节点集合中的下一个节点.
4) 在每次搜索过程中,计算当前所得路径步长,如果长度大于6,则终止当前搜索过程.
5) 返回所有的有效关键路径,结果为原始社会网络结构的子图.
本算法的时间复杂度为O(LQ),其中L为网络中从源节点到目的节点的平均长度,Q为网络中节点的最大出入度值.
2.2 服务预期评价方法为了更准确地进行推荐,本节融合CPD算法发现的用户信任网络,基于信任用户对服务的评价来预测目标用户对服务的评价.如图 3所示,目标用户u1对服务1的评价可以利用信任网络中的用户u7对服务1的评价来预测.

|
图 3 用户评价网络结构 |
假设社会网络结构中包括由m个用户组成的集合U={u1, …, um},这些用户使用过的n个服务组成的集合为S={s1, …, sn}.用户-服务评分数据集可以用m×n阶矩阵R表示,其中rij(1≤i≤m,1≤j≤n)表示用户ui对服务sj的评分.服务评价预测式为
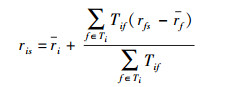
|
(7) |
其中:ri、rf分别为用户ui和用户uf对其使用过的所有服务的平均评价值,Ti为评价了服务s并且在用户ui的信任网络中的用户,Tif为用户ui和uf之间的信任关系强度.
3 实验及结果分析3.1 Filmtipset数据集Filmtipset[8]是瑞士最大的电影推荐社区,它拥有超过9万注册用户和2 000万条以上评分数据.如图 4所示,Filmtipset数据集中除了评分信息外,还包含朋友关系、用户年龄、用户位置、用户评论等用户相关的信息以及主演、编剧、电影类型等电影相关的信息.

|
图 4 Filmtipset数据集 |
本实验基于Filmtipset数据集,通过笔者提出的方法来分析与节点间综合信任关系计算相关的各类因素对于推荐质量的影响程度.实验方案采取以下5种对比方法.
1) 基于角色影响力的推荐方法(RIR,role influence-based recommendation);
2) 基于用户属性相似度的推荐方法(UAR,user attribute-based recommendation);
3) 基于用户偏好相似度的推荐方法(UPR,user preference-based recommendation);
4) 基于用户基本信任关系的推荐方法(BTR,basic trust-based recommendation);
5) 基于综合信任关系的推荐方法(CTR,composite trust-based recommendation),即综合考虑各种影响因素,利用节点间关键路径计算得到的综合信任关系进行评分预测和Top-N推荐.
评价方法采用推荐精确度P@N. P@N用于评价用户的前N(本实验中N=5和10) 个被推荐项目与测试集中的相关性.其中关键路径中阈值设为0.8,其值通过交叉验证试验来设定.对所有测试用户计算的P@N求平均值,可以得到推荐方法的P@N. P@N越大表明推荐精确度越高. P@N定义为
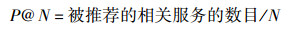
|
(8) |
表 1给出了各类影响因素对综合信任关系的重要性对比分析实验结果.
|
|
表 1 各影响因素对综合信任关系的重要性对比 |
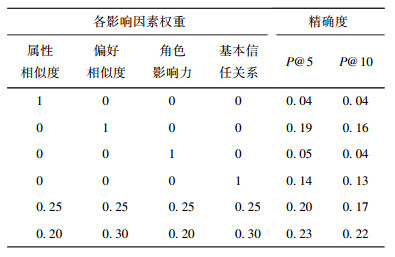
由以上结果可以看出,以P@5和P@10为评测标准,基于综合信任关系的推荐方法分别优于仅仅单独考虑用户属性相似度、用户偏好相似度、角色影响力、用户基本信任关系等因素的推荐方法,而且P@5的评价值一般优于P@10.单独考虑用户偏好相似度时,该方法等同于传统协同过滤推荐方法(通过偏好相似用户来预测目标用户的偏好).由实验结果可知,基于综合信任关系的推荐方法其推荐精确度优于传统协同过滤推荐方法.
当分别考虑用户属性相似度、用户偏好相似度、角色影响力、用户基本信任关系等因素时,由图 5的实验结果还可以看出,用户偏好相似度、用户基本信任关系这2个因素相比角色影响力、用户属性相似度,对于推荐精确度的影响更加明显.这表明在推荐过程中,需要重点考虑用户对服务的评价和用户之间的社会网络关系对推荐的影响.由实验结果可知,增加用户偏好相似度和用户基本信任关系的影响权重,可以得到更准确的推荐.

|
图 5 用户信任计算模型的影响因素对比实验 |
影响服务推荐的因素有许多种,考虑了用户间的基本信任关系,以及用户的角色影响力、属性相似度、偏好相似度等因素来提高推荐的质量.用户的地理位置、社会亲密度等,在某些应用场景下也会对推荐的效果产生影响.未来的工作将会在推荐算法中考虑更多的社会上下文信息,以进一步改善推荐的效果.
| [1] |
邓爱林, 朱扬勇, 施伯乐. 基于项目评分预测的协同过滤推荐算法[J]. 软件学报, 2003, 14(9): 1621–1628.
Deng Ailin, Zhu Yangyong, Shi Bole. A collaborative filtering recommendation algorithm based on item rating prediction[J].Journal of Software, 2003, 14(9): 1621–1628. |
| [2] | Adomavicius G, Tuzhilin A. Toward the next generation of recommender systems:a survey of the state-of-the-art and possible extensions[J].IEEE Transactions on Knowledge and Data Engineering, 2005, 17(6): 734–749. doi: 10.1109/TKDE.2005.99 |
| [3] | Golbeck J, Hendler J. Inferring binary trust relationships in web-based social networks[J].ACM Transactions on Internet Technology (TOIT), 2006, 6(4): 497–529. doi: 10.1145/1183463 |
| [4] | Adamic L A, Lukose R M, Huberman B A. Local search in unstructured networks[J].Handbook of Graphs and Networks, 2003: 295. |
| [5] | Liu Guanfeng, Wang Yan, Orgun M A.Trust transitivity in complex social networks[C]//Proc of AAAI, 2011(11):1222-1229. |
| [6] |
刘迎春, 郑小林, 陈德人. 信任网络中基于角色信誉的信任预测[J]. 北京邮电大学学报, 2013, 36(1): 72–76.
Liu Yingchun, Zheng Xiaolin, Chen Deren. Trust predicting using roles-based reputation in trust network[J].Journal of Beijing University of Posts and Telecom, 2013, 36(1): 72–76. |
| [7] | Milgram S. The small world problem[J].Psychology Today, 1967, 2(1): 60–67. |
| [8] | Said A, Berkovsky S, De L E W. Introduction to special section on CAMRA2010:movie recommendation in context[J].ACM Transactions on Intelligent Systems and Technology(TIST), 2013, 4(1): 13. |