


为了提高网络带宽利用率,实现网络负载和传输效率的平衡,提出了一种基于网络流量自回归技术的网络数据去重算法ANTREA.该算法将数据传输分割成多个传输单元,在每个传输单元中分成去重传输和直接传输2部分,前一部分实现去除冗余数据后传输,后一部分数据则利用空闲带宽实现传输.通过为每个传输单元的网络状况建模,预测下一个传输单元的网络可用带宽及查重处理时间,并据此调整直接传输的数据量,以求充分利用空闲带宽,提高网络带宽利用率.实验结果表明,ANTREA算法可以根据网络状况自动调整传输策略,能够充分利用网络带宽以实现更高的数据传输效率,比EndRE算法有更好的网络适应性,在10 MB/s的网络环境下,传输吞吐量几乎为EndRE的7倍.
For purpose of enhancing network bandwidth utilization and for a balance between network traffic and transfer efficiency, based on the network traffic autoregressive technology, a new network traffic redundancy elimination algorithm called ANTREA was proposed. It splits data transfer missions into transfer units. The data in one transfer unit are executed in two ways, one is traditional traffic redundancy elimination, and the other is direct data transfer. A transfer unit makes up models of network situation, and predicts the time cost of checking duplications and the available bandwidth. So, it adjusts the size of direct data transfer according to the result of prediction. Experiments show that ANTREA algorithm can adjust its transfer strategy according to the network situation and utilize network bandwidth sufficiently to achieve higher transfer efficiency. It is of better flexibility on network situation than EndRE and has almost 7 times transfer throughput than EndRE in network with 10MB/s bandwidth.
随着信息数据量呈爆炸式增长,大量的数据通过网络进行传输,高带宽需求成为当前网络传输面临的严峻挑战.然而随着信息量的剧增,大量的相同或相似数据在网络上往复传递,浪费了宝贵的通信资源.
数据去重作为一种能在任意网络中消除重复数据的技术,可以极大的节省网络带宽,减少网络负载的压力.近年来,提出了很多系统通过消除这些冗余数据的方法来提高网络效率. Douglis等[1]利用delta编码来消除Web对象中的冗余数据,但该方法往往是针对具体应用,对动态内容的有效性很差.因此,基于内容的方法得到了广泛的运用,MODP[2]将数据对象被切分成数据块,通过对比数据块的指纹值来检测冗余数据,实现在不同的数据对象中识别冗余数据.而EndRE[3]提出新的分块算法,以提高数据去重的效率,但数据块被限制在32~64 byte. Wanax[4]采用在发送端和接收端加入去重中间件的方式,为存储和带宽受限的地区提供数据去重方案. PACK[5]通过预测将要传输的数据块的方式,优化云端和用户之间数据去重的过程. Papapanagiotou等[6]提出将缓存和数据去重相结合,以优化资源开销和传输速度.
将已有数据块指纹索引存放在内存上可以提供较高的查重速度.然而,指纹索引随着数据集的增大而增大,导致需要存放到磁盘上,且由于哈希指纹本身具有随机性,每一次查重都极易造成磁盘读写,会严重影响数据去重的效率[7].
海量数据环境下,查重效率低下,查重处理时间过长,会导致无法充分利用带宽资源.随着网络设施性能却在不断的提高,网络带宽利用不足的问题变得愈发严重.因此,如何优化网络数据去重算法,充分利用带宽资源,进一步提高网络传输效率是亟待解决的问题.
为此,提出了一种新的网络数据去重算法(ANTREA,autoregressive-based network traffic redundancy elimination algorithm).该算法从提高网络带宽利用率的角度出发,将数据传输的任务分割成多个传输单元.每个传输单元基于自回归模型对网络状况建模,预测下一个传输单元的所需的查重处理时间及这段时间的可用带宽,并根据结果将数据划分成2部分分别传输,一部分数据来自去除冗余的数据,另一部分数据则利用空闲带宽直接传输,以提高带宽利用率,同时在网络负载和传输效率之间取得了平衡.最后给出了实验结果和分析.
1 系统模型概述ANTREA分为发送端和接收端2部分,系统结构如图 1所示.其中,发送端包括数据块切分模块和传输单元(包含数据查重模块和传输调度模块).

|
图 1 系统结构框图 |
数据切分模块从数据对象的头部开始,利用可变长分块算法[3],将数据对象切分成数据块,同时通过SHA-1算法,计算这些数据块的哈希指纹值.
传输单元中的数据查重模块负责将多个数据块的哈希指纹值打包发送到接收端,并将传输过程中的网络负载数据传递给传输调度模块;传输调度模块根据采集到的数据,利用自回归模型,对网络可用带宽及查重处理时间进行预测,并根据预测结果,调整直接传输的数据量.
传输单元TUn在其传输调度阶段预测传输单元TUn+1的查重处理时间及这段时间内网络近似可用带宽,完成后进入TUn的数据传输阶段,同时开始执行TUn+1,各个传输单元之间的关系如图 2所示.

|
图 2 传输单元执行示意图 |
在1次传输单元TUn中,主要步骤如下.
1) 数据查重.接收端将指纹包中的指纹值与数据块索引中的已有指纹进行比对,重复的指纹即代表对应数据块为冗余数据,再将非冗余数据块指纹在数据包中的位置信息返回给发送端.
2) 传输调度.数据采集模块记录查重过程中的网络传输数据;回归预测模块根据这些数据以及接收端返回的查重结果,计算该传输单元直接传输部分的数据量.
3) 数据传输.根据查重的结果,发送端将非冗余数据块打包发送到接收端;同时,根据模型的预测结果从数据对象的末尾开始,截取对应大小的一段数据,直接传输到接收端.
接收端主要存储数据块索引及未经去重的数据.其中,数据块索引负责处理数据查重的请求.利用数据块索引中存储的数据块信息和所接收到的未经去重的数据,即可还原数据对象.
2 传输调度算法2.1 数据采集每个传输单元记录指纹包传输过程中的近似可用带宽及数据查重的处理时间,这些信息描述如下.
1) 近似可用带宽.数据查重模块每次打包μ个数据块指纹,传输到服务器端,记TUn中数据包传输完成所需要的时间为Ci,指纹数据包大小为H,则近似可用带宽可以表述为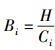
2) 查重处理时间.去重过程完成后,服务器端返回非冗余数据块在数据包中的位置序号,此外记录这整个查重过程完成所花费的时间Pi.
2.2 调度模型通过预测下一个传输单元的查重处理时间和这一小段时间内的近似可用带宽,进而可以求得最合适的直接传输数据量ddi+1的大小.传输单元的预测方法如下.
1) 近似可用带宽预测.时间为t,设
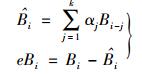
|
(1) |
其中:αj,j=1, 2, …, k为模型参数,eBi为模型预测误差.
2) 查重处理时间预测.设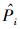
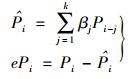
|
(2) |
其中:βj,j=1, 2, …, k为模型参数,ePi为模型预测误差.
3) 直接传输数据量.结合预测得到的近似可用带宽
|
(3) |
根据查重返回的结果,可以计算去重传输部分数据量dci的大小,假如dci≥di,则说明网络资源紧张,该传输单元退化为普通的网络去重传输;若dci < di,则可利用空闲带宽实现直接数据传输,而2部分数据的大小满足如下条件
|
(4) |
由式(1)~式(4),可得该阶段直接传输数据ddi的大小为
|
(5) |
对于可用带宽的观测值B1,B2,…,BN,采用AIC定阶法确定自回归模型阶数k0,记
|
(6) |

|
(7) |
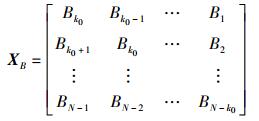
|
(8) |
模型中参数αj的求解表达式为
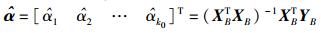
|
(9) |
同理可得
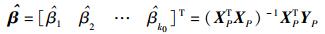
|
(10) |
基于N个历史采样值,通过最小二乘法,求解式(9)、式(10) 的结果,并代入式(5),便可以求得直接传输数据量的大小.
3 实验评估为了验证ANTREA算法的有效性,选择连接在校园网络环境中的2台计算机节点,分别作为发送端和接收端,并利用Linux源码包作为待传输数据进行测试.节点的配置:CPU为Intel Core Duo 2.93 GHz,内存为2 GB.在此实验平台上利用Java语言对算法进行了编码实现,并使用数据库来存储数据块索引,同时实现了EndRE[3]采用的传统数据去重算法,并进行了对比实验.
3.1 预测精度评估数据查重模块每次打包μ个数据块指纹发送到接收端,若μ太大时,则采样的间隔过大,预测结果不够准确,但由于Java虚拟机精度所限,实验中数据包的指纹数量采用μ=500.
基于100个观测值,利用AIC定阶法,实验使用k0=3作为自回归模型的阶数. 图 3(a)、(b)分别为网络可用带宽1步、5步预测值与实际观测值的对比图.由图 3可以看出,1步预测得到的结果与原始观测值比较相符,预测的步长越大,所得到结果的偏差也就越大.同样,图 4(a)、(b)分别为1步、5步查重处理时间预测值与实际观测值的对照图. 图 4更能体现预测步长越大,偏差越大的问题,图 4(b)中尖峰处的预测值甚至是原始观测值的100倍.

|
图 3 可用带宽预测结果 |

|
图 4 查重处理时间预测结果 |
综上所述,自回归模型作为短相关模型,随着预测步长的增加,预测精度将会很快下降.因此,为了保证预测精度,本实验中的预测步长为1.
3.2 传输效率评估在传输效率评估实验中,通过限制带宽的方式模拟了10 MB/s、5 MB/s、50 kB/s的带宽环境,分别进行实验.
图 5给出了ANTREA算法与EndRE中所采用的去重算法的数据去重率对比图. 图 5中ANTREA算法的数据去重率随着带宽的降低而上升,而EndRE所采用的算法则基本不变.这表明可用带宽越大,ANTREA算法就会将更多的数据通过空闲带宽直接传输,以充分利用带宽资源,进而提高传输效率.

|
图 5 数据去重率对比 |
图 6给出了ANTREA算法与EndRE中所采用的去重算法的传输吞吐量对比图. 图 6中ANTREA的网络吞吐量随着带宽的降低而降低,而EndRE则在不同的带宽下都没有改变.这表明带宽越低,ANTREA可利用的闲置带宽就越少,因而直接传输部分在数据传输中的比重就越低.因此,传输吞吐量就会受到影响.

|
图 6 传输吞吐量对比 |
结合图 5、图 6可以看出,带宽越高,ANTREA中利用闲置带宽直接传输的数据越多.因此,虽然数据去重率相对EndRE较低,但是有更好的传输效率.在10 MB/s的网络环境下,传输吞吐量将近为EndRE的7倍.实验结果也表明,ANTREA算法对不同的网络环境有更好的适应性,能够更有效地利用网络带宽资源,优化数据传输过程.
4 结束语从充分利用网络带宽、平衡网络负载和传输效率的角度出发,基于网络流量自相似的特点,提出了一种新的网络数据去重算法,将数据分解成多个传
输单元进行传输.每个传输单元基于自回归模型,预测下一个传输单元的所需的查重处理时间及这段时间的可用带宽,并根据结果将数据划分成2部分分别加以传输,一部分数据来自去除冗余的数据,另一部分数据则利用空闲带宽直接传输.实验结果表明,该算法可以根据网络状况自动调整传输策略,提高网络带宽利用率,实现更高的数据传输效率.
| [1] | Douglis F, Iyengar A. Application-specific delta-encoding via resemblance detection [C]//In USENIX 2003 Annual Technical Conference. San Antonio TX:USENIX, 2003: 113-126. https://www.usenix.org/publications/library/proceedings/usenix03/tech/full_papers/douglis/douglis_html/index.html |
| [2] | Anand A, Muthukrishnan C, Akella A, et al. Redundancy in network traffic: findings and implications[J].ACM SIGMETRICS Performance Evaluation Review, 2009, 37(1): 37–48. |
| [3] | Aggarwal B, Akella A, Anand A, et al. EndRE: an end-system redundancy elimination service for enterprises[C]//NSDI. San Jose CA: USENIX, 2010: 419-432. |
| [4] | Sunghwan I, Kyoungsoo P, Vivek S P. Wide-area network acceleration for the developing world [C]//In Proc. of USENIX ATC. Boston MA: USENIX, 2010. |
| [5] | Zohar E, Cidon I, Mokryn O. The power of prediction: cloud bandwidth and cost reduction[J].SIGCOMM-Computer Communication Review, 2011, 41(4): 86–97. doi: 10.1145/2043164 |
| [6] | Papapanagiotou I, Callaway R D, Devetsikiotis M. Chunk and object level deduplication for web optimization: a hybrid approach [C]//2012 International Communications Conference. Piscataway NJ: IEEE, 2012: 1393-1398. |
| [7] | Benjamin Z, Li Kai, Patterson H. Avoiding the disk bottleneck in the data domain deduplication file system [C]//FAST. San Jose CA: USENIX, 2008: 269-282. |