


提出了一种基于相关内容聚集的缓存方案,通过具有相同特征相关内容的相互吸引,使相关内容在节点上聚集,从而方便对缓存内容进行内容特征抽象,以减少向外通告的路由信息量,提高面向内容网络的路由可扩展能力;同时通过相关内容生存时间相互增强的策略,增强了缓存内容的稳定性,提高了其路由可信度.在此基础上设计了通用的相关内容聚集算法,仿真结果符合预期效果.
A related contents gathering based cache policy called cache gathering (CG) was proposed to solve the routing scalability problem brought by existing cache policies in content centric network. By the mutual attraction between the contents with same feature, called related contents, the related contents gathered on nodes, which facilitated the cache contents feature abstraction, so the routing advertisement was decreased and the routing scalability was improved. Meanwhile, with the strategy of lifetime-increasement between contents with main feature, CG was able to reduce the update frequency of cache content, so the routing reliability was improved. On this basis, the general CG algorithm was proposed. The simulation proved the reasonableness and efficiency of the schemes in this thesis.
面向内容网络[1]采用了“推倒重来”的设计理念对网络体系结构进行重新设计[2],解决现网面临的流量集中化和链路重复传输的问题[3],提高了内容分发的效率.
内容缓存作为面向内容网络技术的重要组成部分,已经受到了越来越多的关注.已有的缓存方案考虑了内容流行度、缓存位置、缓存冗余等因素,以提高缓存资源利用率,并改善用户体验.然而,由于面向内容网络采用基于内容名的路由方式,其路由目标是找到离用户最近的目标内容,需要对节点缓存的内容进行路由通告,而现有的缓存方案不能使节点所缓存的内容表现出明显的共同特征,缓存内容难以通过特征抽象,如分层内容名的前缀聚合,减少路由通告的信息量,导致网络中产生大量的路由更新消息,严重影响网络的路由可扩展能力.
针对上述问题,笔者提出一种基于相关内容聚集的缓存方案CG(cache gathering),通过具有相同内容特征的相关内容的相互吸引使缓存内容表现出明显稳定的内容特征,方便通过内容特征抽象减少路由通告的信息量,从而改善网络的路由可扩展能力.
1 相关研究面向内容网络以内容名作为路由标志,使用户可以直接对内容进行访问,其路由性能与网络中的内容分布密切相关.
LCE[4](leaving copies everwhere)是目前面向内容网络研究中常用的缓存方案.文献[5]提出了一种概率缓存策略ProbCache.文献[6]提出了一种基于内容热门度驱动的协作缓存算法TopDown.
笔者提出的CG方案通过缓存中与目标内容特征相同的相关内容对目标内容的吸引作用,使具有相同特征的内容在节点上聚集.这一过程会放大缓存中不同特征内容的数量差异,从而使缓存内容具有突出的主要内容特征及稳定的内容特征分布,方便对内容进行特征抽象以减少路由通告的信息量.
2 基于相关内容聚集的缓存方案2.1 名词解释为了便于描述,首先对CG方案中常用名词的含义进行简要说明.
内容属性:能代表内容某方面特征的元素,如分层的内容名前缀、内容类型等.
内容特征:如果将内容属性看成一个集合,则内容特征就是这个集合中的元素,如内容类型集合中的某一特定内容类型.
相关内容:具有相同内容特征的内容互为相关内容.
主要内容特征:节点大量缓存的内容所具有的共同内容特征.
次要内容特征:除主要内容特征外的其他内容特征统称为次要内容特征.
2.2 方案描述CG方案的基本原理:通过相关内容的相互吸引,使节点的主要内容特征更加突出和稳定,并排斥具有次要内容特征的内容在节点上的缓存,使节点表现出突出、稳定的内容特征.
CG方案是一种本地缓存方案,它通过节点已缓存内容对目标内容的吸引作用影响目标内容的缓存.通过这种方式,节点的主要内容特征逐渐被增强,而次要内容特征逐渐被削弱,最终使节点形成特征突出的内容分布,如图 1所示.

|
图 1 相关内容聚集效果图 |
如图 1所示,初始阶段在3个节点n1、n2、n3上均缓存有A、B、C三种特征的内容,且它们在数量上只有微弱的差异.经过相关内容聚集后,这种微弱的数量差异被放大,节点n1、n2、n3均表现出突出内容特征.
缓存内容频繁更新会在网络中产生大量的路由更新消息,同时还会降低缓存内容的路由可信度.针对这一问题,CG方案提出了新的缓存丢弃方案:节点为缓存中的每个内容维持一个生存时间,当某一内容的生存时间减为零时,该内容被丢弃;缓存中相关内容生存时间相互增强,则主要特征内容占据缓存内容数量的绝大多数,因此很难被丢弃,从而提高缓存内容的稳定性.
图 2是CG方案示意图,图中节点缓存中的内容分为主要特征内容和次要特征内容2部分,其占据缓存空间大小用矩形框的长度表示,矩形框之间的连接线表示缓存聚集的过程和产生的效果.如图 2所示,经过缓存聚集,具有主要内容特征的内容占据了更大的缓存空间,使节点的内容特征更加突出.生存时间相互增强只发生在主要特征内容之间,这是由于缓存空间有限,为了使内容特征抽象具有更高的可信度,节点需要集中资源大量存储某一特征的内容,避免出现多个主要内容特征.

|
图 2 CG方案示意图 |
CG方案并非一种具体的缓存算法,而是一种从缓存入手改变面向内容网络中内容无规律分布导致一系列路由可扩展问题的思路,这种思路可以应用在所有希望增强面向内容网络路由可扩展能力的研究中,下面以增强路由聚合场景为例进行分析.
增强路由聚合程度是CG方案最直观的一种应用场景,该场景中内容属性是内容名前缀,CG方案使具有相同内容名前缀的内容相互吸引,当相同前缀的内容聚集到一定程度时,节点就可以向外通告更短的内容名前缀,从而达到提高路由聚合程度的目的.
3 CG算法在CG方案的基础上,设计了通用的CG算法, 借鉴已有缓存方案的诸多思路,并根据实际环境进行了修改. CG算法中用到变量的简要说明如下.
R_F:相关内容因子,表征缓存中目标内容的相关内容对目标内容的吸引作用大小.
H_F:内容流行度因子,表征内容的流行程度,是内容流行度H的归一化值.
P_F:路径因子,表征当前节点距离用户的远近,其目的是使内容缓存在离用户更近的位置.
PL:路径长度.
cur_user_dis:当前节点到用户的距离.
FCS_F:剩余缓存空间因子,表征节点的缓存能力.
FCS:剩余缓存空间.
CS:总缓存空间
Life_Time:内容的生存时间.
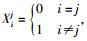
Tf:目标内容特征.
H:内容流行度.
Hmax:最大内容流行度.
A、B、C、D、E为常数.
3.1 缓存因子为了更好地利用缓存空间达到相关内容聚集的效果,CG算法采用了R_F、H_F、P_F、FCS_F四种缓存因子用于缓存决策,其计算公式如下:

|
(1) |

|
(2) |
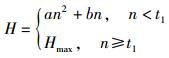
|
(3) |
其中:a、b为常数,n为内容请求经过节点的次数,t1为阈值.
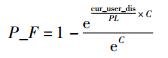
|
(4) |
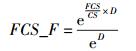
|
(5) |
目标内容的缓存概率为上述4种缓存因子的加权和.
3.2 缓存冗余避免策略由于CG方案是一种本地缓存方案,不能避免缓存冗余,同时由于其使相同特征内容聚集的特点,CG方案还会使初始的缓存冗余得到进一步增强,造成缓存资源的大量浪费.针对这一情况笔者提出2种避免缓存冗余的解决方案.
方案1 路径冗余避免策略
在内容数据包的包头中增加已缓存标识字段,用于标识该内容在路径上的缓存情况.当前节点根据这一字段判断目标内容是否被之前的节点缓存,如果已被缓存,则不缓存目标内容或提高缓存概率的阈值.
方案2 区域冗余避免策略
方案1的缺点是只能减少一条路径上的缓存冗余,对一定范围内的缓存冗余避免没有帮助.针对这一情况,结合面向内容网络基于内容名路由的特点,笔者提出区域冗余避免策略.其基本思路是通过查询本地路由表中的内容路由信息,获取目标内容在临近位置的缓存情况,用于判断是否缓存目标内容.
3.3 算法描述CG算法的过程如下.
步骤1 当目标内容到达节点时,CG算法首先根据缓存冗余避免策略判断是否有临近节点已缓存了相同的内容,以减少或避免缓存冗余.
步骤2 计算目标内容的缓存概率,并判断是否大于设定的阈值.若小于阈值,则不缓存目标内容,转步骤7;否则,转步骤3.
步骤3 缓存目标内容,并为其设置初始生存时间.
步骤4 判断目标内容是否具有主要内容特征,若具有,则转步骤5;否则,转步骤6.
步骤5 增加目标内容及缓存中已有的主要特征内容的生存时间.目标内容生存时间增加量T和已有主要特征内容生存时间增加量T′的计算公式分别为
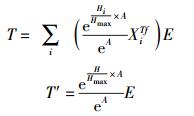
|
(6) |
步骤6 若缓存空间已满,则丢弃生存时间最短的内容.
步骤7 算法结束.
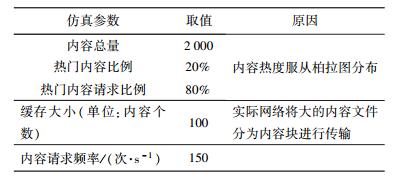
4 仿真分析为了验证CG算法是否能达到预期效果,本研究在VS2008平台上对算法进行了仿真.仿真参数设置如表 1所示.
|
|
表 1 仿真参数表 |
首先对CG算法能否达到使相同特征内容聚集的效果进行对比仿真,对比算法为经典的LCE算法,仿真效果如图 3所示.

|
图 3 不同算法节点内容特征分布 |
图 3中内容特征共分为5类,分别用不同纹路表示,柱状图的高度表示各特征内容数量.由仿真结果可以看出,采用CG算法时,各节点的主要内容特征和次要内容特征对比明显,具有主要内容特征的内容数量远远大于其他特征的内容数量,使节点具有鲜明的内容特征,达到了预期的效果.
图 4所示为CG算法和LCE算法及ProbCache算法的缓存更新频率对比.结果显示,CG算法的缓存更新频率相比于另2种算法有了明显的降低,这是因为CG算法通过相关内容生存时间相互增强,使占据缓存绝大多数的主要特征内容更难被丢弃,从而增强了缓存内容的稳定性,也使其具有更高的路由可信度.

|
图 4 缓存更新频率 |
对提出的2种缓存冗余避免策略进行了对比验证(见图 5),图中CRA(cache redundancy avoid)指缓存冗余避免,CRA1和CRA2分别指缓存冗余避免方案1及方案2.可以看出,当CG算法不采用缓存冗余避免策略时,其缓存冗余很高,仅次于LCE算法;而采用提出的缓存冗余避免方案后,缓存冗余性能获得了极大的改善,符合预期效果.

|
图 5 缓存冗余对比 |
针对已有的面向内容网络缓存方案严重影响路由可扩展性的问题,提出了一种基于相关内容聚集的缓存方案CG,并设计了通用的CG算法. CG方案通过使具有相同特征的相关内容自发地聚集在相同位置上,使缓存内容具有更突出、可信、稳定的内容特征,方便对缓存内容进行特征抽象,以减少路由通告的信息量.最后对通用的CG算法的效果及性能进行了仿真,仿真结果符合预期.
CG方案是一种可以适用于多种应用场景的缓存思路,本研究以增强内容名前缀聚合场景为例对其进行了简单的说明,下一步可以对其进行更深入的研究.此外,对于CG方案如何应用于其他场景需要进行更深入的探究.
| [1] | Jacobson V, Smetters D K, Thornton J D, et al. Networking named content[J].Communications of the ACM, 2012, 55(1): 117–124. doi: 10.1145/2063176 |
| [2] | Feldmann A. Internet clean-slate design: what and why?[J].ACM SIGCOMM Computer Communication Review, 2007, 37(3): 59–64. doi: 10.1145/1273445 |
| [3] | Alduán M, Álvarez F, Zahariadis T, et al. Architectures for Future Media Internet[M]. Palma deMallorca: User Centric Media, 2012: 105-112. |
| [4] | Laoutaris N, Syntila S, Stavrakakis I. Meta algorithms for hierarchical web caches[C]//Performance, Computing, and Communications, 2004 IEEE International Conference on. [S.l.]: IEEE, 2004: 445-452. |
| [5] | Psaras I, Chai W K, Pavlou G. Probabilistic in-network caching for information-centric networks[C]//Proceedings of the Second Edition of the ICN Workshop on Information-Centric Networking. [S.l.]: ACM, 2012: 55-60. |
| [6] | Li J, Wu H, Liu B, et al. Popularity-driven coordinated caching in named data networking[C]//Proceedings of the Eighth ACM/IEEE Symposium on Architectures for Networking and Communications Systems. New York: ACM, 2012: 15-26. |