


社会化标签中普遍存在标签的主题粒度和文档不一致以及部分标签和文档内容无关这两个问题, 而现有基于主题模型的社会化标签推荐算法并没有同时对二者进行建模.针对这两点, 提出了一种新的主题模型, 该模型不仅允许标签和文档具有各自的主题粒度, 而且允许标签来自与文档无关的噪声主题.在两个不同的社会化标签语料上的实验结果表明, 所提出的模型相比内容相关模型和标签的隐含狄利克雷分配模型, 在混淆度和平均正确率均值这两个指标上均有所提高.
It is common that the topic-granularity of social tags is not consistent with correspondent document, and some tags cannot describe the topic of the document content. The existing topic models-based tag recommendation did not address the foregoing problems simultaneously as well. Motivated by the fact, the proposed novel topic model allows different granularity of word topics and tag topics, and assumes that the tags can originate from a general distribution unrelated to the content. Experimental results show that the proposed model outperforms content relevance model (CRM) and tag-logical device address (tag-LDA) on two different social tagging corpora in both perplexity and mean average precision.
社会化标签允许用户用自造的标签来标注网络资源,对标签的内容、个数和一致性均无限制,因此较容易被互联网用户接受.但是,由于网络资源非常巨大,人工标注费时费力,难以实施,同时,人工标注中也存在大量错标、标注不一致的情况,这对标签的实用性带来了很大的困难.因此,利用计算机进行自动、高质量的标签推荐,一直以来都是业内学者研究的热点.
与基于协同过滤的方法不同,本研究是基于文档内容的社会化标签推荐方法.该类方法[1-2]可以不受新文档和冷门话题的限制,更适用于对有充足文本内容的文档进行推荐,如网页、博客文章、新闻等.而随着隐含狄利克雷分配模型(LDA, latent Dirichlet allocation)[3]的发展,越来越多的研究工作将LDA引入标签推荐任务[2, 4-7].虽然,这些主题模型一定程度上解决了对有标签语料的建模问题,但是,由于社会化标签的自由性,对比传统的标签,有其自有的特点:1) 社会化标签和对应文档的主题粒度差异较大;2) 社会化标签中含有大量与被标注内容无关的噪声标签.这其中包括用来描述内容以外的标签,以及用户有意或无意使用了错误的标签.
针对这两点,本研究将标签和文档可生成自不同粒度主题的思想以及标签中存在噪声主题的现象进行统一建模,提出了一个新的主题模型:引入标签粒度和噪声的LDA(TN-LDA,tag-granularity and noise-aware LDA),并基于该主题模型对未见文档进行标签推荐.
1 基于标签粒度及噪声标签的模型1.1 TN-LDA模型TN-LDA模型的生成过程如下,对应的生成图如图 1所示.

|
图 1 TN-LDA模型的生成过程 |
1) 抽样相关概率λ,服从beta(γ)
2) 对每个词主题k∈1,2,…,K,抽样一个词层的分布φwk,服从dir(βw);抽样一个标签主题(子主题)层的分布Ψk,服从dir(η)
3) 对每个标签主题q∈0,1,…,K1,抽样一个标签层的分布φtq,服从dir(βt),其中q=0表示与文档内容无关的噪声主题,q∈1,2,…,K1表示与文档内容相关的标签主题
4) 对应每个文档d∈1,2,…,D,抽样一个主题层的分布θd,服从dir(α)
5) 对该文档d的每个词wdn∈1,2,…,N
① 基于多项式分布mult(θd),抽样一个词主题zdn∈1, 2, …,K
② 基于当前主题zdn决定的多项式分布mult(φwzdn),抽样一个词wdn
6) 对该文档d的每个标签tdm∈1,2,…,M
① 基于多项式分布mult(θd),随机抽取一个词主题sdm∈1,2,…,K
② 基于当前主题sdm决定的多项式分布mult(Ψsdm),抽样一个标签主题ydm∈1,2,…,K1
③ 基于二项式分布Bernoulli(λ),抽取rdm
a.若rdm=1,基于当前标签主题ydm决定的多项式分布mult(φtydm),抽样一个标签tdm
b.rdm=0,基于噪声主题的多项式分布mult(φt0),抽样一个标签tdm
1.2 基于吉布斯采样的模型参数估计用吉布斯抽样方法对TN-LDA模型进行参数估计.给定文档的词W={wd}d=1D、标签T={td}d=1D、词的主题Z={zd}d=1D、标签的主题S={sd}d=1D和Y={yd}d=1D,以及相关量R ={rd}d=1D,当前文档d中,第i个词语wi属于主题k的概率为
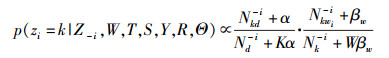
|
(1) |
其中:上标-i为不考虑当前词i的计数;Nkd-i为当前文档d(包括词语和标签)中含有主题k的频次;Nd-i为当前文档d中词语和标签总数;Nkwi-i为在整个文档集中,词i和主题k的共现次数;Nk-i为在整个文档集中主题k的出现次数;K为词主题的个数;W为文档集中词表的大小;α和βw分别为Dirichlet分布的超参数.
当前文档d中,第j个标签tj和文档相关的情况下,属于主题k以及标签主题q的概率为
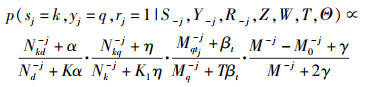
|
(2) |
其中:上标-j为不考虑当前标签j的计数,与式(1) 中仅有上标不同的变量将不作单独说明;Nkq-j表示主题k和标签主题q的所有共现次数;Nk-j表示在整个文档集中主题k的出现次数;Mqtj-j表示在整个文档集中,标签j和标签主题q的共现次数;Mq-j表示在所有标签中标签主题q的出现次数;M-j和M0-j分别表示所有标签数和噪声标签数;K1表示标签主题的个数;T表示文档集中标签表的大小;βt和η分别为Dirichlet分布的超参数;γ为beta分布的超参数.
第j个标签tj和文档不相关,属于噪声主题的概率为

|
(3) |
其中:M0tj-j表示在整个文档集中,标签j和噪声主题“0”的共现次数.
根据上述吉布斯抽样过程的结果,TN-LDA模型可以得到更新后的模型参数,并对未见文档dnew进行推导.然后根据式(4) 计算训练集标签的权值,并将满足式(4) 的前若干个标签推荐为该文档的标签.
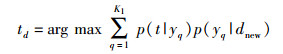
|
(4) |
其中,更新后的标签主题-标签分布为
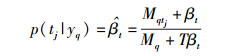
|
(5) |
更新后的文档-标签主题分布为

|
(6) |
其中Nqd表示当前文档d(只包括标签)中含有标签主题q的频次.
2 实验及分析2.1 数据准备实验采用2个不同性质的社会化标签数据集,其中BIBTEX来自学术论文收藏网站Bibsonomy①,BIBTEX数据集中的文档长度很短,主题相对集中在计算机科学和生物科学等研究领域,标签多为描述较细粒度的专业术语等概念词,极少含有噪声标签.
第2个数据集Delicious来自于分布式人工智能(DAI,distributed artificial intelligence)实验室的Wetzker等[8]提供一份从Delicious②上抓取的数据:dai_labor_delicious.
2.2 混淆度比较在主题模型中,混淆度(perplexity)被用来评测模型是否较好的拟合数据,混淆度越低表示更好的生成性能.混淆度的定义为
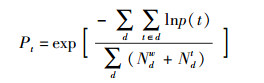
|
(7) |
图 2和图 3分别为两个数据集下,TN-LDA模型在不同的词主题数和标签主题数组合下的混淆度变化以及和内容相关模型(CRM, content relevance model)、Tag-LDA的比较结果.其中,图示表示对应的模型,括号内的数值表示TN-LDA模型的词主题数.

|
图 2 BIBTEX语料中主题和混淆度的影响 |

|
图 3 Delicious语料中主题和混淆度的影响 |
首先,由图 2可见,一方面,当词主题数为200时,TN-LDA模型的混淆度最低,其中标签主题数为800时混淆度达到最低值,这说明该模型的词主题数和标签主题数分别为200和800时,最适合对BIBTEX建模.另一方面,Tag-LDA和CRM的混淆度随主题数的增加而增加,说明这两个模型过拟合BIBTEX数据.而TN-LDA的混淆度趋势则相反,且在词主题数为200时基本低于Tag-LDA的混淆度,说明TN-LDA相比其他2个模型,当采用适当的主题数时,更适合对BIBTEX建模.
其次,由图 3可见,一方面,与BIBTEX语料的情况有所不同,当词主题数为400时,TN-LDA模型的混淆度较低,其中标签主题数为800时,混淆度仍然达到最低值,这说明,当该模型的词主题数和标签主题数分别为400和800时,对Delicious语料建模的能力最强.另一方面,与BIBTEX数据类似,CRM的混淆度仍是随着主题数的增加而增加的,这说明CRM过拟合该数据.而TN-LDA模型的混淆度仍然是随着主题数的增加而下降,而且在词主题数为400和800时均低于Tag-LDA和CRM的混淆度,这同样说明在Delicious语料上,在恰当的主题数下,同时考虑了标签主题粒度和标签噪声的TN-LDA模型比其他模型的建模能力强.可能的原因是TN-LDA模型可以在噪声标签现象较明显的Delicious语料上,发挥出其对噪声建模的优势.
再次,通过在BIBTEX和Delicious语料上的比较可以发现,一方面,混淆度均在标签主题数为800时达到最低,这印证了社会化标签多是一些表示具体概念的词,其主题粒度要小于文档中的词.另一方面,在BIBTEX语料上,混淆度随着词主题数的增大而升高,而在Delicious语料上,词主题数取适中的400时达到最优,这可能的原因是:BIBTEX的文档来源于学术出版物中的摘要,用词较规范,且频繁出现一些主题粒度较大的抽象词;而Delicious语料来源为网页,领域更加自由,既有粒度较小的词,也有粒度较大的词.
2.3 标签推荐性能比较实验中TN-LDA模型的词主题数选取第1组对比实验中混淆度最低的结果.
首先考察BIBTEX语料上的标签推荐性能.由表 1可知,随着标签主题数的增加,TN-LDA相比Tag-LDA提升较显著,说明BIBTEX数据中标签的主题粒度较小,更倾向于描述具体概念.
|
|
表 1 BIBTEX语料标签推荐性能 |
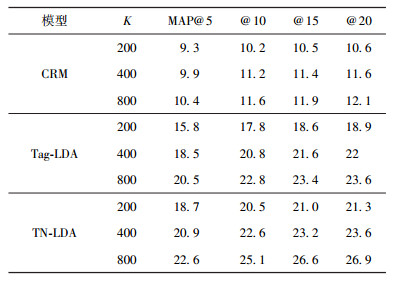
其次考察Delicious语料上的标签推荐性能.通过观察表 2,TN-LDA相比Tag-LDA,提升较大.这主要由于Delicious语料中社会化标签的噪声现象较明显,而且采用不同粒度的主题模型增大了模型的灵活性.同样的,随着标签主题数的增加,性能提升不是很显著,说明Delicious语料的标签虽然也比较倾向于较细粒度的标签,但是由于其标签间的主题粒度差异较大,提升程度不如BIBTEX明显.
|
|
表 2 Delicious语料标签推荐性能 |
针对社会化标签语料的特点,TN-LDA模型分别在标签主题粒度与文档不一致,存在部分噪声标签两个方面的问题上进行了改进.实验表明,在BIBTEX和Delicious语料上,TN-LDA模型,相比未同时对上述两个问题建模的CRM和Tag-LDA模型,在衡量建模能力的混淆度和标签推荐的MAP值这两个指标上均有所提高.
| [1] | Song Yang, Zhuang Ziming, Li Huajing, et al. Real-time automatic tag recommendation [C]//Proceedings of the 31st annual international ACM SIGIR conference on Research and development in information retrieval. Singapore: ACM Press, 2008: 515-522. |
| [2] | Si Xiance, Sun Maosong. Tag-LDA for scalable real-time tag recommendation[J].Journal of Information & Computational Science, 2009, 6(1): 23–31. |
| [3] | Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J].Journal of Machine Learning Research, 2003, 3(1): 993–1022. |
| [4] | Blei D M, Jordan M I. Modeling annotated data[C]//Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Toronto: ACM Press, 2003: 127-134. |
| [5] | Chen Xin, Lu Caimei, An Yuan, et al. Probabilistic models for topic learning from images and captions in online biomedical literatures[C]//Proceedings of the 18th International Conference on Information and Knowledge Management (CIKM). Hong Kong: ACM Press, 2009: 495-504. |
| [6] | Iwata T, Yamada T, Ueda N. Modeling social annotation data with content relevance using a topic model[C]//Proceedings of the 24th Annual Conference on Neural Information Processing Systems (NIPS). Vancouver: MIT Press, 2009: 835-843. |
| [7] | Krestel R, Fankhauser P, Nejdl W. Latent dirichlet allocation for tag recommendation[C]//Proceedings of 3rd ACM Conference on Recommender Systems (RecSys). New York: ACM Press, 2009: 61-68. |
| [8] | Wetzker R, Zimmermann C, Bauckhage C. Analyzing social bookmarking systems: a del.icio.us cookbook[C]//Proceedings of the 18th European Conference on Artificial Intelligence (ECAI). Amsterdam: IOS Press, 2008: 26-30. |