


针对回顾式话题检测方法存在的话题检测时效性较差的问题,提出了改进的位置敏感哈希(LSH)算法,并应用于互联网新闻层次化话题检测.在挖掘新闻内容特征的同时,应用潜在狄利克雷分布主题模型挖掘新闻的语义特征,将非二进制空间的内容特征向量和主题特征向量转换到二进制特征空间上,依次应用LSH算法对新闻文本基于内容特征和主题特征聚类,得到具有“主题-内容”层次的话题.实验结果表明,该方法通过挖掘新闻的内容特征和主题特征,能更准确和完整地表现新闻内容;将内容特征和主题特征转换到统一的二进制空间,有效降低了聚类过程的时间复杂度,在保证话题检测准确率和话题在语义层面上扩展性的前提下,提高了话题检测的效率.
To improve the timeliness of detecting topics in retrospective topic detection, an improved locality sensitive Hashing (LSH) algorithm is proposed and applied in constructing hierarchical topic model for web news. Firstly, the news content feature is excavated, and the topic feature is excavated using latent dirichlet allocation model. Then the non-binary content eigenvector and topic eigenvector are converted to binary feature space. Finally, news articles are clustered in order using binary content eigenvector and binary topic eigenvector by LSH, and the hierarchical topic-content news topic model is generated. Experiments prove the following results: extracting content feature and topic feature can express the news exactly; converting content eigenvector and topic eigenvector to unified binary space can reduce the time complexity of clustering, and thus increase the efficiency of topic detection while ensure the accuracy and semantic expansibility.
话题检测与追踪(TDT, topic detection and tracting)技术源于1996年美国国防部高级研究计划署计划,其目标是对新闻媒体信息流进行新话题的检测,并根据检测到的话题跟踪事件的发展变化.话题检测(TD, topic detection)是TDT的一项重要任务,其主要目标是将来自多个新闻源中,讨论相同话题的新闻文本聚类到一起,从而发现新的热点话题.话题检测通常包含在线话题检测和回顾式话题检测.近几年又提出了层次话题检测,区分新闻内容在层次上的差异,建立结构化的话题模型.
最早用于话题检测的是单路径聚类(single-pass)算法[1].按照新闻到达的时间顺序依次处理,当待检测新闻与已知话题的相似度超过系统设定阈值时,将该新闻归入相应话题,否则生成一个新话题.该算法存在结果受时序影响大,话题特征较少不利于发现话题等问题.回顾式话题检测针对已有的新闻集.早期通常采用凝聚层次聚类(HAC, hierarchical agglomerative clustering)算法实现[2]. HAC算法是一种自底向上的层次聚类算法,能排除时序的影响,对新闻话题的挖掘力度好于单路径法,但效率较低.近年来话题检测的研究主要针对短文本冗余性高、噪声大、特征向量高维且稀疏等特点,改进现有聚类算法,使其适应短文本[3-6].这些算法在一定程度上提升了话题检测的准确性,但在实际应用中无法较好地满足海量数据的实时性的要求.
针对海量数据导致的话题检测方法的实时性能低下的问题,笔者提出了一种改进的LSH聚类算法,并用于生成具有“主题-内容”层次的话题.
1 LSH改进算法LSH是为了解决高维向量数据的最近邻搜索问题而提出的一种聚类算法[7],算法的时间复杂度低. LSH算法应用于文本聚类时,包含3个步骤:特征向量抽取、最小哈希(minHash)降维、LSH聚类.这种聚类方法仅仅依据文字层面的内容特征,没有体现文本的主题特征,不适合话题检测.本研究对已有的LSH文本聚类算法和步骤进行改进,能挖掘到文本的主题特征,实现高效的话题检测.改进后的LSH聚类步骤如图 1所示.

|
图 1 改进的LSH文本聚类算法的流程 |
1) 内容特征抽取
内容特征由文本中分词组成的词组表示,这种词组通常称为shingle.根据给定shingle长度L,对每个文本用shingle的编号和该shingle在文本中出现的次数来表示文本.这样,生成每个新闻文本的内容特征向量为

|
(1) |
其中:Ti为文本编号,si为文本i包含的shingle数,fij为文本i中第j个shingle出现的次数.
2) 主题特征抽取
根据给定主题数m,对整个新闻文本集合进行潜在狄利克雷分布(LDA, latent Dirichlet allocation)主题模型训练,为每个文本生成LDA主题特征向量如下

|
(2) |
其中:wtj表示该文本在第j个主题下的权重,且
以shingle为特征的文本内容特征向量之间的相似度通常通过Jaccard相似度来度量,而以主题为特征的文本主题特征向量之间的相似度通常通过余弦相似度计算.本研究通过将主题特征向量转换到非负整数空间上,以应用Jaccard相似度进行度量,并应用LSH聚类算法,得到内容层次和主题层次上的话题.
设定参数θ, φ对式(2) 中的主题特征向量转化

|
其中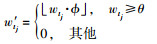
参数θ用于判定文本是否具有某主题上的信息.对于一个特定的文本,当一个主题的出现频率大于该值时,认为该文本中包含该主题信息.参数φ是一个转换参数,用于将m维的主题特征向量转换到与加权内容特征向量同样的特征空间上,即转换后的主题特征向量中每个主题j的特征项也是通过该主题的权值来表达.
将转化后主题特征向量中的每个主题的权值作为该主题出现的次数,即
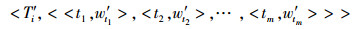
|
(3) |
1.1节生成的内容特征向量为加权shingle内容向量,1.2节转换后的主题特征向量则是处在同一高维非负整数空间上.为了minHash降维的需要,引入了一种加权向量转化方法,将非二进制特征向量转化到二进制空间上.
对式(1) 表示的内容特征向量的转换如下:

|
其中:Ti为文本编号,sip_fip表示将第s个shingle扩展成fip个二进制空间上的shingle.
对式(3) 表示的主题特征向量同理转换如下:

|
转换后的主题特征向量维度取决于θ,为θm.其思想是,在主题tj上的权值w′j越大,该主题在该文本特征中占的比重就越大,则主题tj出现的次数越多.这样文本的主题特征就能通过一个二进制的稀疏向量来表示.
1.4 MinHash降维经过上述转换后,分别对转换后的内容特征向量和主题特征向量进行minHash降维.
生成M对随机数(ai·bi),构成一个哈希函数(aix+bi)modp,对1.3节得到的文本对象的内容特征向量和主题特征向量的每一维进行哈希,得到最小的哈希值(minHash值)作为该文本对象的第i个哈希值,每个文本对象最终由M维的哈希向量表示,即minHash签名向量Qi=(m1, m2, …, mM),达到了降维的目的.
1.5 LSH聚类依次对minHash降维后的新闻内容特征向量和主题特征向量进行LSH聚类,实现重复文本删除、内容聚类和主题聚类,但不同步骤中相似度的门限值不同. LSH的算法过程如下.
输入:聚类门限τ,文本特征矩阵Q ;
步骤1 计算LSH聚类所需参数:每段中包含的minHash值个数r和段数b均为整数,且满足(1/b)1/r≥τ,b·r≤M.
步骤2 将文本集的minHash签名向量分为b段;
步骤3 通过哈希函数对每段r个minHash值进行哈希,值相同即分到同一桶中,每次生成ki个桶, ki≤n.重复此过程b次,每个文本被分到b个桶中,一共生成
对每个桶内的文本对象进行两两相似度检验,过滤出相似度未达到门限的对象.过滤的方法如下.将文本对象看作图中的节点,当相似度大于给定门限值τ时,认为此2个文本可达,即节点之间有边,最终计算得到一个组内成员的连通图,如图 2所示. ε, ε∈[1,n]为组内成员数,当组内对象与其他对象的连通度小于ε时,该对象被过滤出组.

|
图 2 组内成员连通关系图 |
然后进行冗余分组合并.选定每个桶内的中心文本,即本桶内与其他对象距离和最小的文本对象.将具有相同中心文本的桶合并,消除冗余桶,经过冗余过滤后,剩余的桶作为最终的聚类结果.如图 3所示.

|
图 3 冗余合并过程 |
基于上文提出的改进的LSH聚类算法,本研究的话题检测方法分为4个步骤,分别是文本特征抽取、重复文本删除、层次聚类、话题生成.其中,重复文本删除和层次聚类均利用LSH改进算法实现,区别在于相似度门限和抽取的文本特征不同.
文本是信息的载体,同时也是非结构化数据,在对文本进行聚类之前,需要对文本进行结构化的表示,使其成为一种能被计算机理解和处理的形式.特征抽取主要包括预处理、特征抽取、权重计算、特征转换与降维等.
用于话题检测的文本集是来自网络上的新闻,其中包含一些由于抄袭、镜像或同源文件等原因而出现的内容近似于重复的文本.这些重复文本提供很少的信息量,却会在文本处理过程中消耗资源,所以在文本聚类前需要对重复文本进行检测和删除.
新闻文本所描述的话题通常具有“主题-内容”的层次结构.内容属性即新闻的具体时间、地点、人物以及发生的具体事件等信息;而主题属性则是新闻文本内容背后深层的语义属性,包含了新闻事件所属类别或范围,不同内容的新闻可能在主题上相似.
采用层次化的聚类方法,首先对新闻集进行内容特征的抽取并基于内容特征进行文本聚类.然后基于内容特征的聚类结果进行主题特征的抽取,并基于主题特征进行第2次文本聚类,得到层次化的聚类结果.旨在发现热门内容的同时,发现该内容所属的主题,进而得到热门话题.
对层次聚类得到的每一层聚类结果进行可靠性筛选,可以得到最终的层次话题模型.可靠性筛选即检测聚类中的文本数是否在一定范围内,只有符合条件的聚类才能够代表某一热点话题.当聚类中的文本数过少时,不足以成为热门话题;而文本数过多时,可能是一个范围较宽泛的主题,不具有内容上的区分度.经过可靠性筛选后,可以得到有效聚类.在有效聚类中选择每类中的中心文本为该类的代表文本,以反映该聚类中所有新闻所属主题话题或者所属内容话题,即检测出当前的热点话题.
3 性能验证与分析通过实验对提出的改进的LSH聚类算法及基于该算法的层次化话题检测方法与基于Single-Pass和HAC算法的话题检测方法进行了对比,验证和分析了检出话题数量、话题检测的准确率、覆盖率以及时间复杂度等性能指标.
3.1 实验数据集及参数配置1) 实验数据集
采用从新闻聚合门户网站抽屉(http://dig.chouti.com)抓取的8万篇新闻作为实验数据集.
在实验中,将经过预处理后的5 000个新闻文本进行人工分类,得到标准分类表 1.
|
|
表 1 标准分类实验集 |

2) 实验参数设置
话题匹配判定门限.聚类算法的输出与表 1定义的人工分类不存在直接的对应关系,因此需要将实验输出结果与人工分类进行匹配,匹配程度由两种方法得到的分类中所含相同文本的个数来决定.
设匹配度η,实验聚类结果C,人工分类E,当η=
3) 聚类参数
通过在实际数据集上的多次测试,本实验最终选定,重复文本的判定标准为Jaccard相似度在0.6以上,内容聚类的Jaccard相似度在0.2以上,主题聚类的Jaccard相似度在0.2以上,Cosine相似度在0.5以上.内容聚类文本数范围在[2,15],主题聚类文本数在[10,100]之间,即认为是有效聚类.
3.2 实验结果分析1) 话题检出数量和时间性能
鉴于Single-Pass和HAC算法每次只能面向某一种特征向量进行聚类,为了便于比较,本实验对文本集的内容特征向量和主题特征向量分别进行聚类,统计检测出的话题数量和所需时间.
无论是主题特征向量还是内容特征向量,笔者提出的方法与HAC识别出的话题数相当,Single-Pass最少,如图 4所示.

|
图 4 检测出的话题数量 |
无论基于主题特征向量还是基于内容特征向量,HAC使用的时间都比较长,Single-Pass的时间较短,而本研究中所采用的方法消耗时间最短,如图 5所示.

|
图 5 话题检测时间 |
2) 正确率和覆盖率
定义话题识别的正确率和覆盖率分别为ρ和λ.
ρ=检测出的话题数/全部聚类结果数
λ=检测出的话题数/全部给定话题数
分别采用Single-Pass算法、HAC算法、本研究提出的LSH算法对实验新闻集进行内容聚类和主题聚类,统计检测出的话题的正确率ρ和覆盖率λ.
对于主题特征向量,HAC的最高,笔者提出的检测方法效果较好.对于内容特征向量,笔者提出话题检测方法的准确率最低,HAC的最高,如图 6所示.对于主题特征向量,HAC的话题检测覆盖率较高,本研究的方法得到适中的话题覆盖率,接近于HAC.对于内容特征向量,也是类似的结果,如图 7所示.

|
图 6 话题检测准确率 |

|
图 7 话题检测覆盖率 |
3) 层次化检测准确率
基于内容和主题的层次化话题检测的准确率如图 8所示.由图可见,改进LSH算法的检测准确率稍低于HAC和Single-Pass.

|
图 8 层次化话题检测准确率 |
4) 改进LSH的时间复杂度
为了进一步验证基于改进LSH算法的层次话题检测方法的时间复杂度,在8万篇新闻文本中选取了一组不同大小的新闻文本进行检测实验,如图 9所示.可见,改进LSH方法在新闻文本集数据较大时仍具有较好的实时性.

|
图 9 改进LSH时间复杂度 |
以上的结果证明,尽管提出的话题检测方法的准确率稍差,但其覆盖率能保证与HAC水平接近,而且话题检测时效性较好.准确率较低的原因是改进LSH算法会生成较多冗余聚类结果,而在话题覆盖率较高、所用时间较短的情况下,准确率较低并不影响实际应用.
4 结束语笔者针对回顾式话题检测语义层话题挖掘时效较差的问题,提出了一种基于改进LSH聚类算法的层次化新闻话题检测方法.通过将内容特征向量和主题特征向量转换到二进制空间,可以基于统一的minHash和LSH方法进行降维和聚类,得到具有语义特征的层次化的聚类结果,即层次化话题,并能显著节省检测时间,提高检测效率.但该方法需要占用大量的系统内存空间来换取时间上的高效,对系统要求较高,可扩展性受到一定的制约;另一方面,该方法的话题检测结果冗余度大,同样导致系统资源的消耗.以上两点有待进一步研究.
| [1] | Allan J, Papka R, Lavrenko V. On-line new event detection and tracking [C]//Proceedings of International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM Press, 1998: 37-45. |
| [2] | Trieschnigg D, Kraaij W. TNO hierarchical topic detection report at TDT 2004[R]. Amherst: University of Massachusetts, 2004. |
| [3] | Yang C, Dorbin T. Analyzing and visualizing web opinion development and social interactions with density-based clustering[J].IEEE Transactions on Systems, Man and Cybernetics, Part A: Systems and Humans, 2011, 41(6): 1144–1155. doi: 10.1109/TSMCA.2011.2113334 |
| [4] | Huang Bo, Yang Yan, Mahmood A, et al. Microblog topic detection based on LDA model and Single-Pass clustering[M]. 2012: 166-171. |
| [5] | Choi J, Croft W B, Kim J Y. Quality models for microblog retrieval[C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management. New York: ACM, 2012: 1834-1838. |
| [6] | Chung-Hong Lee. Mining spatio-temporal information on microblogging streams using a density-based online clustering method[J].Expert Systems with Applications, 2012, 39(10): 9623–9641. doi: 10.1016/j.eswa.2012.02.136 |
| [7] | Gionis A, Indyk P, Motwani R. Similarity search in high dimensions via Hashing[C]//Proceedings of the International Conference on Very Large Data Bases. Edinburgh, Scotland: ACM Press, 1999: 518-529. |