


2. 华北电力大学 控制与计算机工程学院, 北京 102206;
3. 北京邮电大学 计算机学院, 北京 100876
提出一种基于流形排序和社会化矩阵分解的推荐方法, 采用流形排序方法度量用户间的社会相似度, 利用正则化技术构建用于评分矩阵因式分解的目标函数, 将用户之间的偏好差异作为目标函数的惩罚项, 从而将用户之间的社会相似性融入评分矩阵的低阶矩阵分解过程.实验结果表明, 在大型的数据集上, 该方法获得了比当前同类方法更好的推荐精度和更低的评分预测均方根误差/评分预测平均绝对误差(RMSE/MAE)值.
2. School of Control and Computer Engineering, North China Electronic Power University, Beijing 102206, China;
3. School of Computer Science, Beijing University of Posts and Telecommunications, Beijing 100876, China
A new recommendation method based on manifold ranking and social matrix factorization is proposed, in which the social similarities among users are calculated by means of manifold ranking, the objective function of ratings matrix factorization is constructed via the regularization technique, with the differences among users' preferences as the penalty of objective function, the social similarities are infused into the low-rank matrix factorization. Experiments show that this method achieves higher precisions and lower root mean square error/mean absolute error (RMSE/MAE) value than other that of cognate methods.
推荐技术的研究吸引了来自机器学习、数据挖掘、信息检索等不同领域的研究者,但是,大多数推荐系统都受以下问题的困扰:1) 数据稀疏性问题,Badrul等[1]的研究表明,大多数用户只对极少数物品评分,稀疏的评分数据常使得推荐系统无法准确捕捉用户的偏好;2) 冷启动问题,当新构建的推荐系统没有评分历史数据或者新用户加入时,系统无法学习用户的偏好,因此推荐效果不理想;3) 传统的推荐技术忽略了用户之间的社会关系这一重要因素.笔者的研究目标是将用户的社会关系融入推荐系统,解决或减轻推荐系统所面临的数据稀疏性、冷启动等问题,使推荐过程更加符合现实情况,提高推荐系统的性能.笔者主要基于如下假设:用户的偏好可以通过对评分矩阵的因式分解得到;用户的偏好不是独立的,会受到来自其朋友的影响;用户之间的社会关系越亲近,他们的偏好就越相似.
1 相关工作构建社会化推荐系统的过程可分成紧密相关的两个任务,一个是度量用户的社会相似度,另一个是利用社会关系和评分数据构建社会化推荐系统.度量用户的社会相似度本质上是图上的连接预测问题,即度量图上结点之间的相似性的问题.基于共同邻居的度量方法计算量小,但只考虑到图结构的本地一致性;基于路径的度量方法虽然考虑到图结构的全局一致性,但是往往计算量很大.而流形排序算法同时考虑了图结构的本地一致性和全局一致性,迭代过程简单,适用于各种类型的图.针对社会网络的大规模和稀疏性特点,笔者拟用流形排序算法度量用户的社会相似度.
当前,已有研究者提出若干社会化推荐系统,SocialMF模型[2]将信任关系融入矩阵分解,但该方法假定用户的偏好完全由其朋友的偏好均值决定. STE模型[3]认为用户的偏好由自己和所信任的人共同决定,但训练过程比较复杂. Ma等[4]提出了基于正则化技术的SR1模型和SR2模型,SR1模型假定用户的偏好取决于其直接朋友偏好的加权平均值,SR2模型则强调偏好在用户之间的传播以及由此形成的直接/间接朋友之间偏好的一致性,实验结果表明,SR2模型显著优于SR1模型.
针对SR2模型强调偏好传播的特点,利用基于得分传播机制的流形排序方法度量用户之间的全局相似度的方法,并提出一种结合SR2模型和流形排序方法的新的社会化推荐方法.
2 基于流形排序的社会化推荐方法2.1 问题定义推荐系统包含用户集合U={u1, u2, …, uM}以及物品集合O={i1, i2, …, iN},用户对物品的评分为R=[Ru, i]M×N,Ru, i表示用户u对物品i的评分,分值常常是1~5的整数.用户的社会关系由邻接矩阵A=[Au, v]M×M表示,Au, v表示用户u和用户v之间存在的社会关系,1表示存在,0表示不存在.社会化推荐系统的任务是:如果用户u没有对物品i评分,根据评分矩阵R和社会关系矩阵A来预测用户u对物品i的评分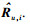
隐语义模型[5]认为每个用户的偏好仅由少量的因素决定,物品的特征也是由少数因素决定的.假设M, N分别表示用户和物品数量,D为特征的个数,且D < min(M, N),以矩阵UM×D表示用户的偏好,每个用户的偏好用向量Ui表示,即U中的一行;同理,以矩阵VN×D表示物品的特征,每个物品的特征表示为Vj;用RM×N表示评分矩阵. Thomas[5]认为评分Ru, i由用户u的偏好和物品i的特征共同决定,可以利用低阶矩阵分解方法进行评分预测,R≈UTV.该低阶矩阵分解问题可转化为一个最优化问题,
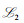
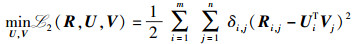
|
(1) |
其中:δ为指示函数,如果Ri, j有值,则δi, j为1,如果Ri, j缺失,则δi, j为0,式(1) 中为避免过度拟合的问题,进一步在目标函数加入变量U,V的正则项
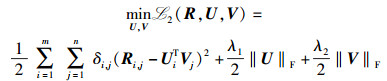
|
(2) |
其中λ1、λ2为正则化系数.利用梯度下降算法可以求解上述最优化问题,获得目标函数的局部最小值以及对应的U和V. Ruslan等[6]利用图模型给出了低阶矩阵分解的概率解释.
2.3 基于流形排序的社会相似度度量协同过滤方法常使用基于评分的相似度,如VSS、PCC、Cosine等,为了将用户的社会关系融入推荐系统,笔者使用用户的社会相似度,提出基于流形排序的社会相似度度量方法.流形排序的过程可以形象地描述为:首先根据社会关系构造一个权重图,并且为目标用户赋以一个初始的正得分, 其余用户的初始得分设为0;然后,所有的节点迭代地将其得分传播给与其相邻的节点,当网络达到全局平衡状态时, 传播过程停止;网络平衡后各个用户得分可被用来度量他们与目标用户的社会相似度.
将用户的社会关系用邻接矩阵A=Au, v]M×M表示;用户的社会相似度用矩阵S=[Su, v]M×M表示,所有元素的初始值为零,S矩阵的第u列记为向量Su,IM×M为单位矩阵,I中的第u列记为向量Iu.将基于流形排序的社会相似度度量算法描述如下.
算法1基于流形排序的社会相似度度量算法
输入:AM×M,α
输出:SM×M
//变量初始化S
S←0M×M
//用迭代方式计算社会相似度S
W←diag(sum(A))
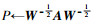
for t from 1 to maxIter1
for u from 1 to M
Su(t+1)←αPSu(t)+(1-α)Iu
end
end
算法首先对A进行对称规范化
社会网络中,用户与朋友们的偏好是趋于一致的,将用户u和用户f的偏好分别用Uu和Uf表示,则用户u和用户f的偏好的差异可表示为‖Uu-Uf‖F,用户u与朋友们总的偏好差异可以表示为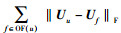
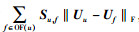
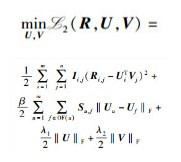
|
(3) |
其中:β是正则化系数,与式(2) 类似,式(3) 可以通过梯度下降搜索目标函数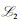
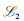
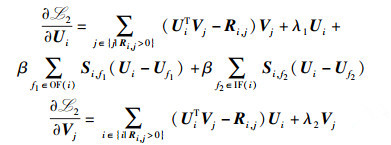
|
(4) |
根据以上分析,笔者提出基于流形排序和社会化矩阵分解的推荐方法(SMF-MR,social matrix factorization with manifold ranking),先利用流形排序度量用户的社会相似度,然后将社会关系融入评分矩阵的因式分解.算法2给出SMF-MR推荐算法的算法描述.
算法2 SMF-MR推荐算法
输入:RM×N,AM×M,β
输出: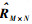
//变量初始化
UM×D←normal(0, 1),VN×D←normal(0,1)
由算法1计算社会相似度S
//用梯度下降算法求解U,V
for epoch from 1 to maxIter2
foreach (i, j) in {(i, j)|Ri, j > 0}
根据式(4) 计算
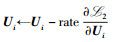
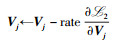
end
end
//计算预测评分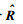
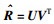
算法的输入包括评分数据RM×N、社会关系数据AM×M,输出为预测评分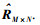
为了验证SMF-MR算法的有效性,实验将基于Flixster和Douban两个真实的数据集. Flixster是一个电影社交网站,Flixster数据集包含大约100万个用户、820万个评分、4.9万部电影、2 670万个双向的朋友关系,评分为取值之间的离散数值,共分10级. Daban是中国最大的在线社会网络之一,Douban数据集包含大学12.9万用户、5.9万部电影、168.3万个评分、169.2万个双向朋友关系,其中评分为1~5之间的数值.
3.2 评估方法采用了2个度量方法进行评估,评分预测的平均绝对误差(MAE, mean alosolute error)和评分预测的均方根误差(RMSE, root mean square error).实验将评分数据R按比率分成Rl和Rt 2个集合,集合Rl用于学习,集合Rt用于测试,MAE可以定义为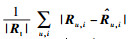
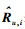

可以看出,MAE和RMSE越低预测的精度越高,推荐系统的性能越好.
3.3 实验结果及分析为了评估笔者提出推荐方法的性能,通过实验与另外3种推荐方法进行了比较:1) 协同过滤方法,使用最广泛的基于内存的推荐方法;2) 概率矩阵分解方法[6],采用基本的矩阵分解方法,未将用户的社会关系考虑在内;3) 社会正则化方法(SR2)[4], 将社会关系融入到矩阵分解,该方法的用户相似度采用了基于评分的VSS相似度和PCC本地相似度,而SMF-MR模型采用了基于流形排序的全局相似度.
笔者设计了2个实验,实验1分为2组,分别度量各种推荐方法的MAE值和RMSE值.第1组实验在Flixster数据集上进行,由于Flixster数据集比较稀疏,实验随机选取90%和80%的评分数据作为训练集,余下部分作为测试集.第2组实验在Douban数据集上进行,实验随机选取80%和60%的评分数据作为训练集,余下的为测试集.为了得到稳定的度量结果,实验将每组实验重复5次,度量的结果取各次度量结果的平均值.实验中,正则化参数λ1、λ2、β的取值均为10-3,维度D取值为经验值10,由于协同过滤不是基于矩阵分解的方法,所以不考虑这几个参数;流形排序参数α取经验值0.99.各种推荐方法的性能比较如表 1所示.
|
|
表 1 各种推荐方法的推荐性能比较(维度D=10) |
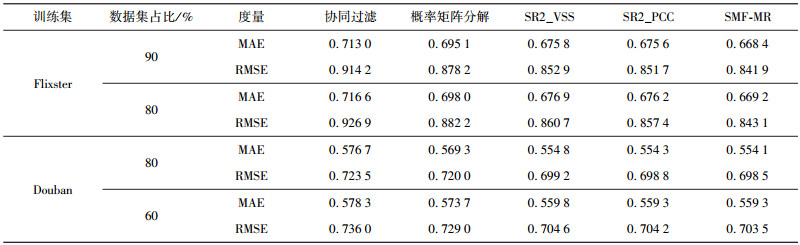
从表 1的结果可以看出,笔者提出的推荐方法所得到的MAE和RMSE结果稳定地低于其他方法.而Douban数据集上的实验结果低于Flixster数据集上的实验结果,这说明Flixster数据集可能包含较多的噪声.
上述实验中,SMF-MR中的参数λ1、λ2、D、α采用了普遍接受的经验值[6],而参数β控制着社会关系在系统中的重要性,β越大则社会关系对系统的影响越大,因此,实验2着重研究了参数β对SMF-MR性能的影响,通过调整β的不同取值,观察β对SMF-MR模型性能的影响,结果如图 1和图 2所示. 图 1显示了参数β在不同的取值情况下,SMF-MR在两个数据集上的评分预测的RMSE误差的变化情况,从图 1可以看出,β值小于10-4或者大于10-2时都会引起RMSE的值上升(系统性能下降). 图 2显示了参数β对评分预测的MAE的影响,β值小于10-4或者大于10-3时都会引起MAE值上升,因此,实验1中β的值设为10-3是合理的.上述实验结果同时也说明,适当地考虑社会关系对推荐过程的影响, 可以进一步提高传统推荐系统的性能.

|
图 1 参数β对RMSE的影响 |

|
图 2 参数β对MAE的影响 |
提出一种基于流形排序和矩阵分解的社会化推荐方法(SMF-MR),该方法将用户之间的社会相似性融入到评分矩阵的低阶矩阵分解过程,采用流形排序方法度量用户的社会相似度,通过学习得到表
示用户偏好和物品特征的低阶隐含语义矩阵,进而利用低阶隐含语义矩阵进行评分预测.实验表明,该方法在大型数据集上比同类的方法具有更好的性能.主要贡献在于3个方面:1) 将流形排序方法用于度量用户社会关系的亲近程度,并将度量结果用户社会化推荐系统;2) 指出了SR2模型在用户相似度度量上存在的不足,在结合SR2模型和流形排序的基础上,提出了融入全局社会相似度的SMF-MR推荐方法,实验表明,不论与同类的推荐方法还是SR2模型相比,SMF-MR方法均提高了推荐系统的精度;3) 提出的SMF-MR社会化推荐方法通过同时使用社会网络和传统评分两种数据,可减轻数据稀疏性问题、冷启动问题对推荐系统的影响.
| [1] | Badrul S, George K, Joseph K, et al. Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th International Conference on World Wide Web. New York: [s. n.], 2001: 285-295. |
| [2] | Mohsen J, Martin E. A matrix factorization technique with trust propagation for recommendation in social networks[C]//Proceedings of the 4th ACM Conference on Recommender Systems. 2010: 135-142. |
| [3] | Ma Hao, Irwin K, Michael R L. Learning to recommend with social trust ensemble[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2009: 203-210. |
| [4] | Ma Hao, Zhou Dengyong, Liu Chao, et al. Recommender systems with social regularization[C]//Proceedings of the 4th ACM International Conference on Web Search and Data Mining. 2011: 287-296. |
| [5] | Thomas H. Latent semantic models for collaborative filtering[J].ACM Transactions on Information Systems (TOIS), 2004, 22(1): 89–115. doi: 10.1145/963770 |
| [6] | Ruslan S, Andriy M. Probabilistic matrix factorization[J].Advances in Neural Information Processing Systems, 2008(20): 1257–1264. |
| [7] | Zhou Dengyong, Jason W, Arthur G, et al. Ranking on data manifolds[J].Advances in Neural Information Processing Systems, 2003(16): 169–176. |