


2. 西南科技大学 国防科技学院, 四川 绵阳 621000
针对认知无线电多用户的信道和功率资源分配问题,提出一种基于用户聚类和可变学习速率的多Agent强化学习方法.首先使用分层处理分离信道选择与功率控制,采用快速最优搜索结合用户数均衡调节实现信道分配; 其次,使用随机博弈框架对多用户功率控制问题进行建模,通过K均值用户聚类减少博弈参与用户数量和降低单个用户的环境复杂度,并使用可变Q学习速率和策略学习速率的方法进一步促进多Agent强化学习的收敛.仿真结果表明,该方法能使多个用户的功率状态和总收益有效收敛,并且使整体性能达到次优.
2. School of National Defense Technology, Southwest University of Science and Technology, Sichuan Mianyang 621000, China
A multi-agent enforcement learning method based on user clustering as well as a variable learning rate was proposed for solving the problem of channel allocation and power control within multi cognitive radio users. Firstly, a hierarchy processing method was used to separate channel selection and power control. The channel allocation was implemented by fast optimal search combined with user-number balance. Secondly, stochastic game framework was adopted to model the multiuser power control issue. In subsequent multi-agent enforcement learning, K-means user clustering method was employed to reduce the user number in game and single user's environment complexity, and a variable learning rate scheme for Q learning and policy learning was proposed to promote the convergence of multiuser learning. Simulation shows that the method can make multiuser's power status and global reward converging effectively, moreover the whole performance can reach sub-optimal.
在认知无线网络中,单个认知无线电(CR, cognitive radio)用户的通信性能不仅取决于其自身的动作,还受到网络中其他CR用户动作的影响.博弈论作为研究多个决策者决策行为和性能预测的工具,适合应用于认知无线网络的分布式资源分配.多Agent强化学习(MARL, multi-agent reinforcement learning)研究多个智能体利用经验和回报在线调整学习和决策动作,是指导多用户分布式资源分配的有效方法[1].研究者使用拍卖、Q学习、非合作博弈、Bush-Mosteller强化学习等方法解决认知无线网络的信道选择和功率控制问题[2-5].使用分布式方法解决CR网络中多用户的资源分配问题时,单个用户的外部环境是受其他用户动作影响的动态环境,自身学习收敛困难.由于缺乏降低用户状态、动作空间和促进多用户学习收敛的有效手段,难以适用于具有较多CR用户的场景.笔者旨在下垫式频谱共享方式下研究使多用户有效收敛的资源分配方法.
1 系统模型 1.1 网络系统模型通信场景如图 1所示,认知无线电系统使用下垫式(underlay)的频谱共享方式与主用户共存.网络中存在M个主发送端和1个主用户基站,M个主发送端分别使用不同的M个频谱信道,另外网络中还有N个CR用户发送端和1个CR用户基站,每个CR用户发送端选择信道和功率与CR用户基站通信.

|
图 1 CR用户与主用户共存网络场景示意图 |
设在一个信道c上,从CR用户k到CR接收站的信道增益为Gk(c),第k个CR用户与第l个CR用户间的相关系数是ρl, k,k, l∈{1, 2,…, N},为简单起见,假设ρk, l=ρl, k.时刻t用户k选择的传输功率为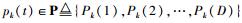
使用可达传输速率来表示链路的实际性能[6]. CR用户k的可达传输速率为
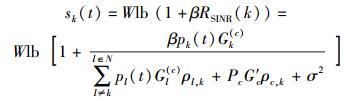
|
(1) |
其中:W表示频谱带宽,β为实际传输速率与香农容量的比值.定义单个CR用户k的综合通信性能指标为hk(t)=sk(t)-Kpk(t),其中:sk(t)是主要部分,表示可达传输速率;-Kpk(t)表示功率耗费对总体性能的惩罚项,K为功率耗费对综合性能的影响权重.在实现
信道选择与功率控制分层依次进行有利于降低整个资源分配的复杂度.信道选择基于2个基本原则:一是倾向于选择增益大的信道,因为信道增益的提高能使接收信号强度增加,从而增大收益; 二是用户在每个信道上的分配应尽可能平衡,因为过多用户分配在同一信道上使干扰信号强度增加,从而降低收益.这里采用快速最优信道搜索结合用户数均衡调节的方法来进行信道分配,单个CR用户首先独立选择信道增益最大的信道,然后依照用户数分布均衡的思想进行可能的调整,步骤如下.
步骤1 找出当前CR用户数最多的某信道a,记录该信道用户集合Φ(a)的用户数ka,找出当前CR用户数最少的某信道b,记录用户数kb,判断是否满足ka-kb < 2,若满足,则用户数均衡调整结束;不满足,则进入步骤2.
步骤2 在信道a上的用户中找出候选用户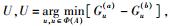
信道a失去用户U时,整体收益中直接减少hu(t)=su(t)-Kpu(t)这一项,同时,由于用户U的离开,其他用户受到的CR用户间干扰略微下降,使其他用户的性能有微量增加,总的性能通常是减小.对于信道b,情况则相反,加入的新用户会直接增加1个用户的性能,但其他用户的性能微量减小,总的性能通常是增加.对于信道a、b的联合整体性能增量Δ(a)+Δ(b),信道增益差值Gu(a)-Gu(b)越小,用户数差值ka-kb越大,越有利于联合整体性能的增加.
1.3 多用户功率选择随机博弈模型使用随机博弈框架对分布式的功率控制进行建模,一个标准的随机博弈由元组 < I, S, A1, …, An, r1, …, rn, P>表示,其中I为有限用户集合,用户数为n,S为状态空间,Ai为动作空间,ri为回报函数,P为状态转移函数.在多用户功率博弈有
1) 状态空间S:S=(S1, S2, …, Sn),子状态空间S1表示用户1的当前功率级别,即S1=p1(t)∈P 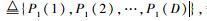
2) 动作空间Ai:用户i有3个动作,包括功率减小1级、功率保持不变、功率增大1级.
3) 回报函数ri:回报值使用用户的综合通信性能hi(t),
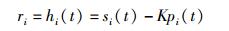
|
(2) |
分布式多Agent强化学习的挑战在于对单个用户而言,其他用户构成环境的一部分,使环境具有非马尔可夫和非静态特性,因此难点在于使多个用户的状态、动作、整体收益有效收敛并达到最优或次优.笔者从降低环境复杂度和减小学习计算量角度出发,提出基于用户聚类的多Agent强化学习方法,在多用户分布式功率控制博弈场景中,依据用户的信道增益值进行用户聚类.假设信道增益在整个博弈过程中保持不变[2],信道增益值接近的用户构成一类,从中选举出最接近类质心的代表成员,每类的代表成员进行多用户的Q学习和策略学习,其他成员仅执行其代表成员选择的动作.由于采取按类别执行相同动作的方法,使环境复杂度大大降低,有利于算法收敛.
采用典型的基于距离的K均值聚类算法,以用户信道增益的欧氏距离作为相似度测度,使用误差平方和函数作为聚类准则函数.具体的用户聚类过程如下.
步骤1 在所有n个用户的信道增益G1, G2, …, Gn中(后面均以信道增益代表用户),随机选择K个作为质心m1(1), m2(1), …, mK(1).
步骤2 对每个用户计算到每个类质心的距离,并把它归入最近质心的类Ck(t)中,即
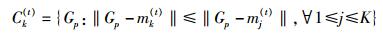
|
(3) |
步骤3 重新计算各类的质心
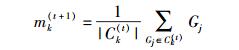
|
(4) |
若各质心均无变化,则聚类收敛,否则跳转到步骤2继续迭代运算.
2.2 可变学习速率学习CR用户经K-Means聚类后,按类进行分布式多用户Q学习,需要设计合适Q学习更新以及策略更新的方法,以促进多用户的状态和系统整体收益的收敛.受文献[7]的WOLF算法启发,并结合MARL最佳响应的基本原则,即用户在观察自身收益的同时也要考虑其他用户的策略和收益,提出了可变速率Q学习和策略学习方法,Q值更新使用当前Q值与自身收益的衰减加权平均方法,但更新速率的确定要综合考虑自身收益和整体收益.若自身收益与整体收益的变化方向一致,都增大或减小,此时应给予较强的反馈,即使用较大的Q学习速率αb;反之,自身收益与整体收益变化不一致时,使用较小的Q学习速率αs.用户动作选择策略采用ε贪婪策略,并且策略学习更新也使用2种不同的速率δb、δs.学习过程如下.
步骤1 系统初始化.
步骤2 各用户重复迭代执行动作选择、参数更新、Q值更新、策略更新,直到达到规定学习次数或算法收敛.
1) 在当前状态s(功率级别),根据概率π(s, a)和ε贪婪策略,选择执行动作a(功率减小1级,功率保持不变,功率增大1级).
2) 进行Q学习速率和策略学习速率的更新,
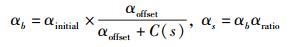
|
(5) |
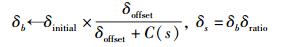
|
(6) |
3) Q学习:根据式(2) 计算个人收益r,并根据个人收益变化和整体收益变化,更新Q值表
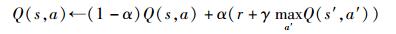
|
(7) |
当个人收益与整体收益变化方向一致时,α=αb;否则,α=αs.
4) 策略学习
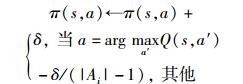
|
(8) |
当个人收益与整体收益变化方向一致时,δ=δb; 否则,δ=δs.
5) 判断是否达到学习次数或满足收敛条件为:最近m次的整体收益均方误差和小于门限TH.
3 仿真结果与性能分析设定CR用户数N为12~60,主用户和信道数M为3,CR用户功率pk(t)∈{12dBm,14dBm,…,30dBm},共10级,主用户功率P=12dBm,ρl, k=ρc, k=0.1,主用户信道增益Gc=0.5-100dB,CR用户增益Gk=[0.1+0.9rand()]-100dB,噪声功率σ2=-80dBm,W=1,β=0.5,K=0.0002.
首先对信道选择时的用户数均衡调整方案进行仿真. 图 2所示为不同用户数情况下用户数均衡调整的判决门限.当信道上用户数差值最小,即Δ=2时,调整门限值最低,信道增益差值小于约0.09时才允许执行用户数均衡,并且随着信道上用户数的增加,该门限逐渐降低,表明此时需要执行用户数均衡动作的概率进一步降低.当Δ增加时,调整门限也相应提高,表明信道上的用户数相差越大,越倾向于执行用户数均衡动作.

|
图 2 不同用户数情况下需用户均衡的信道增益差值门限 |

|
图 3 多Agent学习收敛过程 |
随后进行随机博弈框架下多用户功率控制的仿真.多用户Q学习的参数设置为:αinitial=0.9,αoffset=100,δinitial=0.01,δoffset=200,γ=0.9.图 3所示为CR用户数N=30、主用户和信道数M=3,某个信道上用户数为10,分为4类时,用户聚类的可变学习速率多Agent学习的收敛情况.由图 3(a)可见,采用可变速率的Q学习和策略学习,学习速率比率均为1:5时,该信道上用户的总收益能较好地收敛,且收益值约4.35,也接近最优的总收益; 图 3(b)反映了不采用可变Q学习速率和策略学习速率,即使用统一的速率时,系统总收益波动更明显,收敛困难,并且最后收益值也较可变学习速率方法获得的收益更低.可见,基于用户聚类和可变学习速率的多Agent强化学习方法能使系统总收益有效收敛,并且获得的性能为次优.
图 4所示为主用户和信道数M=3,K均值分类数为4时,不同CR用户数情况下,系统采用本文的信道选择与多用户功率控制方法得到的系统总收益曲线,曲线为30次仿真下的平均性能.由图可知,采用本文方法时,系统的总收益随用户数的增加而增大,比随机的信道、功率选择方法获得的性能高出约30%,比直接进行最大增益信道选择且平均分配功率的方法获得的性能高出约10%,尤其是在用户数较多(N=45~60) 时,随机选择得到的总收益已经开始出现轻微下降,而使用本文方法仍获得总收益的缓慢提升.由此可见,本文方法能有效提升系统的整体性能.

|
图 4 系统总收益随CR用户数变化曲线 |
研究了CR用户采用下垫式频谱使用方式和主用户共存场景下,多用户的信道分配与功率控制问题.提出用户聚类的方法,多用户经过K均值聚类后,按类别进行多Agent强化学习,并且根据个人收益与整体收益的变化方向是否一致选择较大或较小的Q学习速率和策略学习速率.计算机仿真结果表明,用户聚类和可变学习速率方法使多用户功率控制的整体收益有效收敛,并达到次优值.
| [1] | Busoniu L, Babuska R, De Schutter B. A comprehensive survey of multiagent reinforcement learning[J]. IEEE Transactions on Systems, 2008, 38(2): 156–172. |
| [2] | Husheng L. Multi-agent Q-learning for Aloha-like spectrum access in cognitive radio systems[C]//Fifth IEEE Workshop on Networking Technologies for Software Defined Radio Networks. Boston: IEEE, 2010: 1-6. |
| [3] | Yinglei T, Yong Z, Fang N, et al. Reinforcement learning based auction algorithm for dynamic spectrum access in cognitive radio networks[C]//Proc of 72nd Vehicular Technology Conference Fall. Ottawa: IEEE, 2010: 1-5. |
| [4] |
赵成林, 李鹏, 蒋挺. 快速收敛的认知无线电功率控制算法[J]. 北京邮电大学学报, 2009, 32(1): 73–76.
Zhao Chenglin, Li Peng, Jiang Ting. A power control algorithm with faster convergence for cognitive radio[J]. Journal of Beijing University of Posts and Telecommunications, 2009, 32(1): 73–76. |
| [5] | Pan Z, Yusun C, Copeland J A. Reinforcement learning for repeated power control game in cognitive radio networks[J]. IEEE Journal on Selected Areas in Communications, 2012, 30(1): 54–69. doi: 10.1109/JSAC.2012.120106 |
| [6] | Attar A, Nakhai M R, Aghvami A H. Cognitive radio game for secondary spectrum access problem[J]. IEEE Transactions on Wireless Communications, 2009, 8(4): 2121–2131. doi: 10.1109/TWC.2009.080884 |
| [7] | Bowling M, Veloso M. Multiagent learning using a variable learning rate[J]. Artificial Intelligence, 2002, 136(2): 215–250. doi: 10.1016/S0004-3702(02)00121-2 |