


针对现有方法主要用于顺序程序的路径覆盖的问题,提出了一种可应用于并发程序路径覆盖的适应值函数构造方法及实现算法,测试者可以运用该方法生成覆盖指定并发路径的测试用例.该方法的核心是通过计算测试用例的执行轨迹和目标路径之间的相似度来评估测试用例的适应值.实验结果表明,该方法为搜索可覆盖小概率目标路径的测试用例提供较强的导向性,并可以完全自动化地为每条目标路径构造出其适应值函数.
Nowadays many researchers have proposed different methods to generate test data using genetic algorithm for a specified path.Existing methods primarily focus on the path coverage for sequential programs testing.An approach to construct the fitness function for test case generation in concurrent programs testing is provoked.This approach evaluates the fitness values of the test case by assessing the similarity between the path exercised by a generated input data and the target concurrent path.Algorithm for the fitness function is proposed.Studies indicate that this approach provides guidance for seeking the test case covering small probability target path, and generates fitness function for each target path automatically.
现有的并发程序测试方法可以分为不确定性测试和确定性测试,确定性测试还可以进一步细分为基于覆盖的测试和状态空间探索的测试.研究人员已经证明演化测试可以应用于基于覆盖的测试[1].在基于遗传算法的结构性测试中,测试目标被建模为适应值函数.针对结构性测试目标,目前存在3种适应值函数的构造方法:面向条件的方法[2];面向整体覆盖的方法;组合式方法.面向条件方法的适应值函数导向性较强,但是对于一些测试目标,难以自动化地构造出合适的适应值函数;面向整体覆盖的方法难以应用于一些更加复杂的程序;组合式方法结合了以上2种方法的思想,利用第1种方法中的静态距离信息和第2种方法中的动态覆盖率信息来构造适应值函数. Wegener等[3]采用该方法开发了全自动的基于遗传算法的测试数据生成器.但因为程序中的条件通常有各种形式,这就需要人工为每个特定条件构建对应的适应值函数.
Xie等[1]认为,目前上述3种适应值函数设计方法主要用于语句和分支覆盖,而较少应用于面向路径的演化测试,因此提出了一种可应用于面向路径测试的适应值函数的设计方法.但其适应值函数设计方法只适用于顺序程序产生的路径,并不适合于并发程序产生的并发路径覆盖测试.为解决现有测试数据生成器覆盖多个目标路径的低效率问题,Ahmed和Hermadi[4]设计了一种可应用于多路径覆盖的适应值函数设计方法,可以在一次运行中生成可覆盖多个目标路径的测试数据集.但该方法所覆盖的路径仍是顺序路径,且其适用函数也不具有通用性,需要人工为每条路径构造一个特定的适应值函数.目前还没有一种可用于并发路径覆盖的测试数据生成方法.笔者构建了一个用于并发路径测试的适应值函数及其相似性评价算法.
1 基于遗传算法的测试数据生成 1.1 问题描述并发进程由一组相互协作的并发执行的线程组成,其中每个线程的目标子路径可以是一个从线程的入口开始向前移动、直到线程退出的语句序列. n个协作并发线程的并发路径用P1‖…‖Pn表示,其中P1,…,Pn分别代表每个线程的目标子路径.例如,在图 1所示的某个并发程序活动图中,有3条顺序路径:P1=a→c→e→f,P2=a→d→f和P3=a→b→f.这3条顺序路径可组成P1‖P3和P2‖P3 2条可能的并发路径,测试人员可以选择任意1条并发路径作为测试的目标路径.

|
图 1 含并发路径的活动图 |
为生成可覆盖某并发路径的测试用例,需要验证测试用例执行的正确性.验证方法之一是评估测试用例的执行轨迹是否依次覆盖了目标路径中各子路径中的语句.例如,对于图 1所示的并发程序中,目标测试路径P1‖P3有2条子路径.如果某个测试用例的执行轨迹为Ttr=a→c→b→e→f,则Ttr可以依次序覆盖目标子路径P1和P3中的各语句.但如果按文献[1]所述的方法生成测试用例,则生成的测试用例只能覆盖并发路径中的1条子路径,不能同时覆盖目标路径中所有的子路径.为解决上述问题,本研究改进了适应值函数的构造方法,使之可以应用于并发路径的测试数据生成.
1.2 适应值函数在面向并发路径覆盖的测试中,测试用例的执行轨迹由并发进程中各线程的执行轨迹组成,因此它包含一串不连续的、离散的语句序列,表示并发进程中各语句的执行次序.笔者提出的适应值函数设计方法的关键技术是:计算测试用例的执行轨迹和目标路径之间的相似度.
假设某条目标并发路径Tta=P0‖…‖Pk-1,其中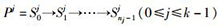
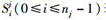
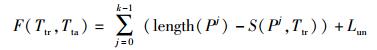
|
(1) |
其中,函数length()为返回目标路径Pj的长度,即路径所包含语句的个数;函数S(Pj,Ttr)用来评估测试用例的执行轨迹和目标子路径之间的相似度,值越高,表示Ttr和Pj越相似,如果Ttr完全不同于Pj,则S(Pj, Ttr)返回0,相反,如果Ttr中的一部分语句可有序覆盖目标子路径Pj中的所有语句,则S(Pj, Ttr)返回最大值length(Pj); 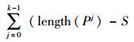
对于式(1) 的适应值函数,适应值取值范围为0,
针对式(1) 中函数S(Pj,Ttr)提出了一种基于路径匹配的相似度计算算法(见图 2).该算法的主要思想是在目标子路径Pj中寻找可依次被执行轨迹的某个子串所覆盖的最长前缀.如果搜索到满足条件的前缀,则该函数将返回此前缀的长度,并将此长度作为Ttr和Pj的相似度.如果执行轨迹依序覆盖了子路径Pj中的所有语句,则它们之间的相似度达到最大值nj. S(Pj,Ttr)在最坏情况下的时间复杂度是O(mmin(nj, m)).

|
图 2 相似度函数流程 |
图 2中失配队列Uun表示Ttr中未被目标路径覆盖的语句序列.
适应值函数的实现方法如算法1所示.算法1 F(Ttr,Tta)
Begin
f = 0; Uun = Φ;
for (Pj∈Tta)
f = f + length(Pj) - S(Pj,Ttr);
f = f + length(Uun);
End;
2 案例研究 2.1 实验设置在案例研究中,采用IHit、IHAG和ITTC 3个指标评估演化测试的性能,实验采用开源的Java遗传算法包(JGAP,Java genetic algorithms package)工具.由于演化测试的随机性,一次实验结果不能代表测试的性能.因此,同样的实验需要重复做300次.假设实验的总次数为G,种群的大小为Psize,在1次实验中最大演化代数是Imax,变异概率是pm,交叉概率是pc. 3个指标的定义如下:
1) 命中率(IHit).命中率值越高,则演化测试的效率越高. IHit=Th/G,其中Th表示成功生成可覆盖目标路径测试用例的次数.
2) 命中平均演化代数(IHAG).为生成所需测试用例所经历的平均代数,该指标反映了演化的收敛速度. IHAG值越低,演化测试收敛速度越快. IHAG=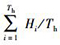
3) 测试用例总数(ITTC).为实验中生成的测试用例总数的平均值. ITTC值越低,演化测试越轻型.
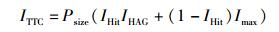
|
(2) |
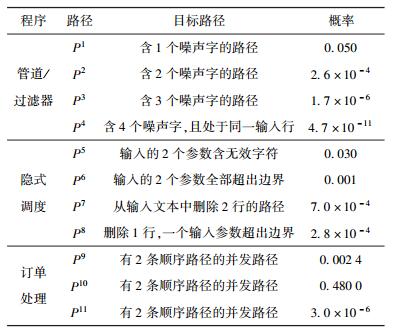
为了评估演化测试的这3个指标,选择了基于隐式调度的上下文关键字(KWIC,key word in context)程序、基于管道/过滤器风格的KWIC程序和电信业务订单处理程序作为被测对象.选择它们作为被测对象的理由是:KWIC通常作为软件设计的经典案例,它们和订单处理程序均具有并发特性,程序中存在分支、循环、过程调用等各种结构,便于选择各种目标路径.为满足实验要求,所选择的并发路径在运行时被覆盖的概率各不相同(见表 1).如果某个路径在程序执行时被覆盖的概率较低,即执行时较难被覆盖到,则称该路径为小概率路径.
|
|
表 1 测试目标 |
分别采用面向路径(PO,path oriented)的测试方法、面向路径条件(PC,path condition)的演化测试方法和随机测试方法(RT,random testing)为被测对象生成测试数据,并通过IHit和ITTC值比较各方法的性能.通过实验结果,可得出5个结论.
1) PO测试在性能方面优于RT测试.如图 3所示,相比于随机方法,PO测试可以获得较高、生成较少的测试用例.但对于概率较大的路径,PO测试提高的幅度则不及小概率路径的改进幅度,所以对于概率较大的路径,还是建议采用随机测试方法.

|
图 3 3种测试方法比较 |
2) PO测试可以获得与PC测试类似的性能,如图 3所示.但PC测试的适应值函数不具有通用性,需要对每条目标路径进行数据流分析,以发现变量之间的依赖,然后才能构造特定的适应值函数;而PO测试的适应值函数却适合于所有目标路径.其主要原因是PO测试构造的适应值函数不需要路径上各分支的谓词信息或数据流分析信息.这使得整个测试过程可以实现完全自动化,减小测试代价.
3) 不同的选择/生存算子对PO测试有非常大的影响.实验提供了如下3类配置:第1类(C1):在交叉变异之前执行择优选择算子,同时在交叉变异之后再次执行择优生存算子;第2类(C2):在交叉变异之前执行择优选择算子,在交叉变异之后不重复的染色体可以进入下一轮;第3类(C3):随机选择染色体进入候选染色体池,并在交叉变异之后执行择优生存算子.从如图 4所示的实验结果可以得出,在C2配置下,针对小概率路径的演化测试,IHit较低.相反,概率较高的路径在C2配置下,获得了较高性能,其更适宜于配置较高选择压力的选择算子,以加速对全局最优解的搜索.

|
图 4 PO测试中3种配置下的性能比较 |
4) 变异算子对PO测试有非常大的影响.针对各路径,PO测试在C3配置下分别执行了1次变异操作和2次变异操作.如图 5所示,对于所有路径,2次变异操作均获得比1次变异操作更好的性能,尤其对于小概率路径,其提高的幅度更大.

|
图 5 PO测试中变异操作性能比较 |
5) 图 6显示了变异概率pm对各测试目标的影响.实验结果显示,当变异概率变小时,对于极小概率的目标,其性能会急剧降低.这主要是由于较高的变异概率有助于提高种群的多样性,具有保持对搜索空间进行持续探索的能力.

|
图 6 对各测试目标的影响 |
采用组合式方法构造了一种可应用于并发路径演化测试的适应值函数,该适应值函数基于目标路径和执行轨迹之间的相似度来评估测试用例质量.
通过对实验结果的分析,可以得出以下结论:
1) 可以运用提出的适应值函数生成覆盖指定并发路径的测试用例;
2) 变异操作和变异概率对测试性能有较大影响;
3) PO测试方法特别适合于小概率的目标路径,可以为执行时难于覆盖的程序结构提供较强的导向;
4) 在确定目标路径之后,演化测试过程对任何路径都是相同的,适应值函数具有通用性,不需要为每个路径人工构造特定的适应值函数,可以完全自动化地为每条目标路径构造出其适应值函数.
| [1] | Xie X Y, Xu B W, Shi L, et al. Genetic test case generation for path-oriented testing[J]. Journal of Software, 2009, 20(12): 3117–3136. doi: 10.3724/SP.J.1001.2009.00580 |
| [2] | Wappler S, Wegener J. Evolutionary unit testing of object-oriented software using strongly-typed genetic programming[C]//Proceedings of the 8th Annual Conference on Genetic and Evolutionary Computation. New York: ACM Press, 2006: 1925-1932. |
| [3] | Wegener J, Buhr K, Pohlheim H. Automatic test data generation for structural testing of embedded software systems by evolutionary testing[C]//Proceedings of the Genetic and Evolutionary Computation Conference. New York: Morgan Kaufmann, 2002: 1233-1240. https://link.springer.com/chapter/10.1007/11875567_32 |
| [4] | Ahmed M A, Hermad I. GA-based multiple paths test data generator[J]. Computers & Operations Research, 2008(35): 3107–3124. |