



2. 同济大学生命科学与技术学院, 上海 200092, 中国;
3. 佛蒙特大学计算机系, 伯灵顿 05405, 美国
2. School of Life Sciences and Technology, Tongji University, Shanghai 200092, China;
3. School of Computer Science, University of Vermont, Burlington, VT 05405, USA
新药开发是一个极其耗时费力的高风险过程。充分发掘已有药物的新用途、对药物进行重定位,一直受到生物医药产业的广泛重视[1, 2]。目前已获得FDA批准上市的药物超过1 710种[3],已收入UMLS医疗数据库的疾病超过25 000种[4],因而组成数以百万计的药物-疾病关系对,经统计这其中仅有约4.5%药物-疾病为治疗或副作用关系。如何从大量尚未被证实的关系对中发现具有潜在治疗关系的药物-疾病,是药物重定位问题的研究焦点[5, 6, 7, 8, 9]。借助机器学习模型,分析医药大数据从而已有整合药物和疾病的信息,可以提高潜在药物-疾病关系对的富集程度,以降低预测的假阳性率。在推荐系统中,将某商品推荐给某特定用户既依赖于该商品和用户本身的属性特征,也受到整个网络中用户和用户之间的关联性以及该用户对于其他商品偏好性的影响。从这个角度,我们将引入社交网络领域中的推荐模型思想[10],把药物看作用户,疾病看作商品,并假设结构相似的药物可能治疗相似的疾病,进而提出一种面向药物重定位的推荐模型。本研究的推荐结果可作为药物重定位研究的信息参照。
1 材料与方法 1.1 基本假设(1)当目标药物与特定药物具有相似的化学结构,则两个药物可能具有相似的适应症;
(2)将药物-疾病关系对看作研究对象,假设具有治疗作用的药物-疾病为正样本,具有副作用的药物-疾病为负样本。
1.2 总体流程

|
| Fig 1 The overall procedure |
(1)所收集药物全部来自DrugBank数据库上FDA批准药物。药物-疾病的治疗关系数据来自Comparative Toxicogenomics Database (CTD),药物-疾病的副作用关系数据来自OFFSIDES。共收集1 710个药物和1 452个疾病,分别记为d1和s1;
(2)药物的化学结构特征数据集来自PubChem数据库,得到该描述符的药物共859个,记为d2;
(3)疾病本体信息的数据来自UMLS数据库,所得到的本体树包含26 959个疾病,记为s2;
(4)由D=d1∩d2及S=S1∩S2可得到859个药物和1 263个疾病,其中d中的药物都带有描述化学结构的指纹特征,s中的疾病都对应于本体树的某个节点;
(5)由CTD数据库和OFFSIDES数据库分别得到11 208个治疗关系和70 553个副作用关系。由此可以构建859×1263的矩阵X,其中用元素值1表示治疗关系,即正样本;0表示副作用关系,即负样本,其中已知的治疗和副作用关系对仅占0.95%;
(6)进一步的,为降低数据稀疏性对协同过滤算法的影响,在矩阵中X引入参数support,并得到满足support ≥ 2条件的矩阵X′,该矩阵包括576个药物、653个疾病,及6 650个治疗关系和58 372个副作用关系,而其中已知作用的关系对比例增加至11.28%;
(7)计算药物-药物相似性矩阵和疾病-疾病相似性矩阵,记为Wu和Wv;
(8)将X,Wu和Wv作为输入,使用协同过滤算法药物-疾病关系预测矩阵,并根据预测值排序,选择TOP-K的关系对作为最终预测结果。
1.3 药物和疾病的相似性度量(1)药物相似性:小分子结构的相似性
度量两个药物相似性可通过药物的化学结构描述符,较常使用的是指纹特征[11],该特征为881维0~1序列,分别表述该药物是否具有某种结构,如α螺旋、β折叠等。该描述符绝大多数的表达值为0,仅含少量的1。在此情况下,如果使用传统的距离度量方法,比如欧式距离,就会高估两条序列的相似性。因此,我们将采用tanimoto距离[12]度量方法:
设Si,Sj分别为两条序列中表达值为1的位置所构成的集合,则|Si|,|Sj|分别表示两条序列含有1的个数,|Si∩Sj|为两条序列在同一位置都为1的个数,那么对于序列i和j的距离,可记为:
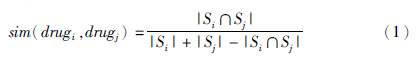
(2)疾病相似性:疾病的相似性基于本体相似性
基于UMLS Metathesaurus语义数据库[5]和UMLS-Interface与UMLS-Similarity软件包[13]构建疾病本体树,其中包括26 959个节点,并根据疾病在本体树中对应节点的距离度量疾病相似性[14]:

其中nA,nB分别表示疾病A,B到公共父节点的距离,nAB则为两疾病公共父节点到本体树根节点的距离。
1.4 参数support调节矩阵的稀疏程度当矩阵X非常稀疏时,并不适于直接用于推荐系统,通过引入参数support以降低矩阵的稀疏性,定义如下:

其中,

我们将使用协同过滤算法GWNMF算法[15]构建推荐系统模型,算法输入输出如下:
(1)输入:药物-疾病关系矩阵,药物-药物相似性矩阵,疾病-疾病相似性矩阵。
(2)输出:药物-疾病预测矩阵。
设有m个药物和n个疾病,一种基于矩阵分解的协同过滤算法可描述如下:已知药物-疾病关系矩阵 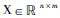 ,药物相似性矩阵WU=[WijU]和疾病相似性矩阵WV=[WijV]。由矩阵X,可得到矩阵,其中Yij=1表示药物i与疾病j作用关系已知,Yij=0表示未知关系。算法通常搜索两个子矩阵
,药物相似性矩阵WU=[WijU]和疾病相似性矩阵WV=[WijV]。由矩阵X,可得到矩阵,其中Yij=1表示药物i与疾病j作用关系已知,Yij=0表示未知关系。算法通常搜索两个子矩阵 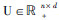 和
和  ,其中UVT为预测矩阵,d表示两个子矩阵所关联的特征维度。由上所述,基于带权非负矩阵正交分解的协同过滤算法GWNMF,其目标函数是:
,其中UVT为预测矩阵,d表示两个子矩阵所关联的特征维度。由上所述,基于带权非负矩阵正交分解的协同过滤算法GWNMF,其目标函数是:
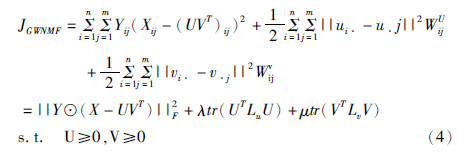
其中⊙是Hadamard乘积,||·||F是Frobenius范数,ui·表示与疾病i有作用关系的药物集,其中1≤i≤n,μ·j表示与药物j有作用关系的疾病集,其中1≤j≤m;λ,μ≥0为正交化参数;UVT为预测矩阵。在使用协同过滤算法时,需要调节参数d,λ和μ,其取值范围分别是d={5,10,15},λ∈[0.001,0.1],μ∈[0.001,0.1]。根据总体流程的步骤5,对参数的全部14种取值组合分别调用CF算法并进行十折交叉验证,对各组结果计算得平均AUC值,且当d=5,λ=μ=0.012时,得到最大值  =0.832。
=0.832。
基于协同过滤算法推荐系统所预测的药物-疾病对应有预测值,值越大表明该关系对更有可能是治疗关系,因而可对药物-疾病排序,并选择排名靠前的部分作为预测结果。结果验证部分,我们基于PubMed数据库,对预测结果查阅文献,并选择具有明确实验支持的文献,且按实验类别将文献分为“综述”、“临床”、“模式生物”、“细胞”,其中有综述报道的关系对,说明其临床研究已十分成熟。另外,存在个别药物-疾病已被验证并无治疗效果,将其记为“无关系”类别。其余尚未得到文献支持的关系对,作为“尚未有报道”类别,这些关系对尚未得到实验验证,但仍可能具有潜在治疗关系,今后尚需进一步关注。
2.2 推荐模型预测结果实验列举了在预测模型中排名TOP100,所支持文献为临床实验且发表年份在3年以内的预测结果(Tab1)。例如,Hawkes等[16]假设一氧化氮可能降低疟疾的死亡率,并对患疟疾的乌干达病人进行临床试验,结果表明一氧化氮可作为抗疟疾的辅助治疗手段;Shebl等[18]收集过往前列腺癌患者的用药数据计算HR(Hazard Ratio),结果发现日用阿司匹林和降低前列腺癌相关。
| Drug | Known treatment of the disease | Relocation of the disease | Ranking | Supported by the literature |
| Nitric oxide | Meningitis,tachycardia | Malaria | 18 | [16] |
| Nitric oxide | Meningitis,tachycardia | Open-angle glaucoma | 62 | [17] |
| Aspirin | Colds,ischemic heart disease | Prostate tumors | 67 | [18] |
| Nitric oxide | Meningitis,tachycardia | Huntington's disease | 93 | [19] |
| Fosfomycin | Acute coronary syndrome | Endocarditis | 115 | [20] |
| cyclophosphamide | Rheumatoid arthritis | Breast tumor | 135 | [21] |
| Aspirin | Colds,ischemic heart disease | Colon tumors | 137 | [22] |
Tab2与Fig2分别给出了推荐模型预测结果所支持文献的实验与发表年份。结果表明,排名在TOP50,TOP100和TOP200的预测关系对中,都有大约40%的关系对得到文献支持,其中包括约11%的文献来自临床报道,以及2%来自综述报道,说明该药物-疾病关系对已经研究较为成熟,有上市的可能。上述所支持的文献大部分在近5年内发表,说明近期仍是研究热点。另外,模型的预测结果包含少量不准确关系,如排40名的Nitric Oxide与Spondylitis,Ankylosing和排286名的关系对Aspirin 与Glioma,文献[23]与文献[24]分别报道上述药物-疾病并不存在治疗关系,原因可能是某些药物-疾病并不满足相似性假设。
| Summaryreports | Clinicalvalidation | Modelorganismsverification | Cell Validation | No relations | Not yet reported | |
| TOP50 | 0 | 6 | 7 | 7 | 1 | 29 |
| TOP100 | 2 | 12 | 13 | 16 | 1 | 56 |
| TOP200 | 5 | 25 | 19 | 35 | 1 | 115 |
| TOP500 | 10 | 54 | 36 | 64 | 2 | 334 |

|
| Fig 2 Literature-supported year of CF prediction results |
本实验对照了3种模型的预测结果,分别由协同过滤算法GWNMF[15]、分类算法PREDICT[7]和随机抽样得到,每组包含在预测模型中排名TOP200和TOP500的关系对集合(Fig3)。结果表明,相比于已有的分类模型和随机抽样结果,协同过滤算法预测的药物-疾病关系对,可以明显提高具有潜在治疗作用的关系对的富集程度(从15%提高至30%以上)。此外,对于模型所预测且尚未报道的药物-疾病可额外关注。

|
| Fig 3 Comparison of prediction results in three models from published literatures |
排名在TOP200的药物和疾病类别分布(Fig4,5)。结果表明,药物的主要类别是呼吸系统相关和抗肿瘤;疾病的主要类别为肿瘤相关和神经系统疾病,我们推测这些类别的药物和疾病更有可能适合重定位研究。

|
| Fig 4 Drug category distribution in top 200 of CF prediction results |

|
| Fig 5 Disease category distribution in top 200 of CF prediction results |
推荐模型的特点是考虑研究对象之间的关联性,我们将药物-疾病的关系看作一种网络拓扑结构,并借助推荐模型将医药大数据中已知的药物-疾病、药物-药物、疾病-疾病的信息融合,以进行系统性药物重定位研究。
实验部分从Drugbank、CTD、OFFSIDES开源医疗数据库[4, 25, 26]中收集已知药物-疾病的治疗关系和副作用关系,并分别作为训练数据集中正、负样本;同时从PubChem数据库[27]上收集药物的化学结构描述符,以计算药物-药物相似性;并基于UMLS数据库中疾病的语义本体树,计算疾病-疾病相似性;之后,使用协同过滤算法构建推荐模型以融合上述信息,并得到2 667对药物-疾病,且带有预测权重。
实验结果表明,我们基于已发表的文献,验证了排名前500名的关系对,结果表明有1.8%的预测关系对已得到综述报道,11%得到临床实验支持,此外有20%得到模式生物或细胞实验支持。因此,通过推荐模型可以将潜在的药物-疾病富集在极小的范围内,尽管很可能遗漏了某些潜在的关系对,但相比于已有模型和随机结果,所预测的500组关系对已明显降低了假阳性率,这将给重定位研究提供重要的信息参照。此外,对于尚未有文献报道的预测关系对,也值得额外关注。
本模型目前尚欠缺的是对新出现疾病的治疗药物预测,因为上述疾病尚缺少明确的治疗药物,使得推荐模型产生“冷启动”问题,即在模型学习过程中缺少训练样本,造成推荐偏差较大;另一方面,对于新药可以进行重定位预测,因为上市药物都有明确的治疗效果说明,可作为模型的训练样本,所以对新药与老药的预测方法没有区分。综上所述,将推荐模型应用于药物重定位研究,可以明显提高具有潜在治疗作用药物-疾病关系对的富集程度,降低了预测的假阳性率,所预测的500对药物-疾病关系对可作为药物重定位研究的参照。
(致谢:本实验在同济大学生命科学与技术学院的刘琦老师实验室和曹志伟老师实验室完成,感谢实验室的老师们对本实验的帮助与指导)
| [1] | Dudley J T, Deshpande T, Butte A J. Exploiting drug-disease relationships for computational drug repositioning[J]. Brief Bioinform, 2011, 12(4):303-11. |
| [2] | 王可鉴, 石乐明, 贺 林,等. 中国药物研发的新机遇:基于医药大数据的系统性药物重定位[J]. 科学通报, 2014, 59(18):1790-6. Wang K J, Shi L M, He L, et al. New opportunity for Chinese pharmaceutical R & D:systematic drug repurposing based on big data[J]. Chin Sci Bull, 2014, 59(18):1790-6. |
| [3] | 黄海宁, 张 浩, 汪 海. 沙利度胺抗肿瘤机制及其作用靶点CRBN的研究进展[J].中国药理学通报, 2015, 31(6):745-8. Huang H N, Zhang H, Wang H. Research progress on the anticancer mechanism of thalidomide and the function of its target protein CRBN[J].Chin Pharmacol Bull, 2015, 31(6):745-8. |
| [4] | Knox C, Djoumbou Y, Guo A C, et al. DrugBank 4.0:Shedding new light on drug metabolism[J]. Nucleic Acids Res, 2013, 42:D1091-D1097. |
| [5] | Bodenreider O. The Unified Medical Language System (UMLS):Integrating Biomedical Terminology[J]. Nucleic Acids Res, 2004, 32(22):D267-D270. |
| [6] | 张永祥, 程肖蕊, 周文霞. 药物重定位——网络药理学的重要应用领域[J]. 中国药理学与毒理学杂志, 2012, 26(6):779-86. Zhang Y X, Chen X R, Zhou W X. Drug repositioning:an important application of network pharmacology[J]. Chin J Pharmacol Toxicol, 2012, 26(6):779-86. |
| [7] | Gottlieb A, Stein G Y, Ruppin E, et al. PREDICT:a Method for inferring novel drug indications with application to personalized medicine[J]. Mol Syst Biol, 2011, 7(1):496-504. |
| [8] | Hurle, M R, Yang L, Xie Q, et al. Computational drug repositioning:from data to therapeutics[J]. Clin Pharmacol Ther, 2013, 93(4):335-41. |
| [9] | Sanseau P, Agarwal P, Barnes M R, et al. Use of genome-wide association studies for drug repositioning[J]. Nat Biotechnol, 2012, 30:317-20. |
| [10] | Wang Z Y, Zhang H Y. Rational drug repositioning by medical genetics[J]. Nat Biotechnol, 2013, 31:1080-2. |
| [11] | Raymond J W, Willett P. Effectiveness of graph-based and fingerprint-based similarity measures for virtual screening of 2D chemical structure databases[J]. J Comput Aid Mol Des, 2002, 16(1):59-71. |
| [12] | Godden J W, Xue L, Bajorath J. Combinatorial preferences affect molecular similarity/diversity calculations using binary fingerprints and tanimoto Coefficients[J]. J Chem Inf Comp Sci, 2000, 40(1):163-6. |
| [13] | Mcinnes B T. UMLS-Interface and UMLS-similarity:Open source software for measuring paths and semantic similarity[C]. AMIA Annual Symposium Proceedings Archive, 2009, 2009:431-5. |
| [14] | Pedersen T, Patwardhan S, Michelizzi J. WordNet:Similarity-measuring the relatedness of concepts[C]. In Proceedings of the 19th National Conference on Artificial Intelligence, 2004:1024-5. |
| [15] | Gu Q Q, Zhou J, Chris D. Collaborative filtering:Weighted nonnegative matrix factorization incorporating user and item graphs[C]. In Proceedings of the SIAM International Conference on Data Mining, 2010:199-210. |
| [16] | Hawkes M, Opoka R O, Namasopo S, et al. Nitric oxide for the adjunctive treatment of severe malaria:Hypothesis and rationale[J]. Med Hypotheses, 2011, 77(3):437-44. |
| [17] | Emam W A. Endothelial nitric oxide synthase polymorphisms and susceptibility to high-tension primary open-angle glaucoma in an egyptian cohort[J]. Mol Vis, 2014, 20(3):804-11. |
| [18] | Shebl F M, Sakoda L C, Black A, et al. Aspirin but not Ibuprofen use is associated with reduced risk of prostate cancer:a PLCO study[J]. Brit J Cancer, 2012, 107(1):207-14. |
| [19] | Carrizzo A, Pardo A D, Maglione V, et al. Nitric oxide dysregulation in platelets from patients with advanced huntington disease[J]. Plos One, 2014, 9(2):e89745. |
| [20] | Chen L Y, Huang C H, Kuo S C, et al. High-dose daptomycin and fosfomycin treatment of a patient with endocarditis caused by daptomycin-nonsusceptible staphylococcus aureus:case report[J]. BMC Infect Dis, 2011, 11(21):9-11. |
| [21] | Vici P, Brandi M, Giotta F, et al. A multicenter phase III prospective randomized trial of high-dose epirubicin in combination with cyclophosphamide (EC) versus docetaxel followed by EC in node-positive breast cancer[J]. Ann Oncol, 2012, 23(5):1121-9. |
| [22] | Bastiaannet E, Sampieri K, Dekkers O M, et al. Use of aspirin postdiagnosis improves survival for colon cancer patients[J]. Brit J Cancer, 2012, 106(9):S439. |
| [23] | Ismail S, Yusuf Z I, Gercek C, et al. Is there a relationship between endothelial nitric oxide synthase gene polymorphisms and ankylosing spondylitis[J]? Clinics, 2013, 68(3):305-9. |
| [24] | Gaist D, García-Rodríguez L A, Sørensen H T, et al. Use of low-dose aspirin and non-aspirin nonsteroidal anti-inflammatory drugs and risk of glioma:a case-control study[J]. Brit J Cancer, 2013, 108(5):1189-94. |
| [25] | Davis A P. The comparative toxicogenomics database's 10th year anniversary:update 2015[J]. Nucleic Acids Res, 2015, 43:D914-D20. |
| [26] | Tatonetti N P, Ye P P, Daneshjou R, et al. Data-driven prediction of drug effects and interactions[J]. Sci Transl Med, 2012, 4(125):125ra31. |
| [27] | Wang Y. PubChem:a public information system for analyzing bioactivities of small molecules[J]. Nucleic Acids Res, 2009, 37(2):623-33. |