 2016, Vol. 33
2016, Vol. 33 



2. 中国科学院大学, 北京 100049
2. University of Chinese Academy of Sciences, Beijing 100049, China
随着科学技术的发展,人类在日地空间的科学活动日渐频繁,诸如空间飞行器、探空火箭、探空气球以及地面台站等探测手段的使用极大地提高了人类对于日地空间的探索能力,科学探测范围不断扩大,探测器数量和种类日益增多,卫星探测任务也日渐频繁,这些因素客观上决定了日地空间科学数据体量巨大、种类多样、结构复杂的特点.与此同时,日地空间科学数据涉及的物理参量众多,数据之间存在空间和时间维度上的关联和依赖关系,各类数据格式并存,导致数据关系非常复杂,难以描述,这些都为该领域内的科学数据检索提出了极大的挑战.目前,在日地空间科学领域,国际上使用广泛的数据发布服务系统,如SPIDR、NGDC、SPDF等,其检索模块仍以关键词匹配、布尔查询、属性分类等传统检索方式为主,这些检索模块在技术层面上远远落后于目前信息检索领域主流的检索技术,从而无法利用数据之间的潜在关联,提供更加全面准备的检索服务.为了使检索更好地利用这些潜在关系,基于语义的检索技术应该被引入到日地空间领域科学数据检索中,基于本体的语义检索模型和基于数据挖掘的语义检索模型是当前常用的语义检索模型.
基于本体的语义检索模型主要根据预先建立好的领域知识本体进行语义推理和查询扩展,进而发掘语义关系,最近几年很多学者做了相关的研究[1-7]:Jones等[1]在2002年使用地理空间领域本体支持其SPIRIT系统中的检索功能,取得了良好的效果;Li等[2]在2011年利用领域本体SWEET(semantic web for earth and environmental terminology)以及相关的推理机制实现了语义检索,该方法主要使用本体内子类和超类的相关关系对于查询进行扩展;Bhattacharjee和Ghosh[3]在2014年提出使用基于本体的方法来解决语义异构的问题,进而获得更加高效准确的检索效果.除借助领域本体进行语义拓展以外,也有一些学者尝试使用一些开源词典进行语义拓展,相关的研究有Wu等[4]、Pal等[5]使用wordnet进行语义拓展和查询优化,取得一定成效.基于数据挖掘的语义检索模型则主要使用数据挖掘技术自动发现检索对象之间的语义关系,具有很强的客观性和可操作性,学术界在这个方面的研究也有很多[8-13].Janowicz[8]在2012年尝试使用数据挖掘的方法来挖掘语义标签,进而助力于数据发现服务;Christidis等[9]在2012年使用聚类技术来分类大规模数据集合从而提升信息检索系统的性能;Li等[10-11]使用潜在语义索引技术(latent semantic indexing,LSI)来支持地理空间数据的语义检索,取得较好的实践效果.
然而分析发现,基于本体的语义检索方法往往存在一定问题,其检索效果的关键依赖于本体模型的优劣.本体模型的建立具有主观和局限性,更多依赖于领域专家对于领域知识的理解程度,因此一个优秀领域本体的构建往往需要大量的人力投入和时间代价.在日地空间科学领域内,由于各类知识管理体系标准不统一,现阶段还不具备构建统一领域知识本体的基础和条件.结合日地空间科学数据特征和组织形式,基于潜在语义索引的检索技术比较适合日地空间科学领域数据检索的应用场景.基于潜在语义索引的检索技术能够把一组文档中具有隐含的语义联系的词语联系起来,绕开对于自然语言的理解,以大样本数量挖掘词语之间的相关性,以使检索结果更优.其基本流程是:把高维的向量空间模型(VSM)中表示的文档通过奇异值分解的办法映射到低维的潜在语义空间中,经过降维忽略一些无关的细节,进而更好地发现具有潜在语义关系的相关集合.在日地空间科学领域中,为科学数据提供描述的科学元数据可以作为语义信息的来源,在对数据描述相关信息进行提取的基础上,使用潜在语义索引技术可以很好地发掘和利用这些数据背后的潜在联系,从而更好地为日地空间领域的科学数据检索服务.
1 模型结构设计基于前期的调研,结合日地空间系统科学的数据现状设计以下检索模型,用以支持该领域内科学数据的语义检索.该模型由信息提取模块、向量化模块、语义降维模块完成原始检索集合的索引,当用户查询语句到达之后即可快速得到检索结果.
图 1是针对日地空间系统科学数据设计的语义检索模型结构图.

|
Download:
|
|
图 1 科学数据语义检索模型结构图 Fig. 1 Structure of semantic retrieval model for scientific data |
|
{kind=link}
通过日地空间领域科学数据组织模型的研究,对于该领域的科学数据形态有了较为全面的认识.日地空间领域科学数据通常由2部分组成:科学数据文件本身以及用来描述科学数据的科学元数据文件.日地空间领域科学元数据目前存在标准不一致的问题,比较通用的是美国国家航天航空局(NASA)提出的SPASE和PDS元数据规范,同时还有一小部分科学数据符合GMD、CSDGM等元数据规范.
以NASA的SPASE元数据规范为例,该规范定义了3类数据资源类型,如表 1所示.
|
|
表 1 SPASE元数据基本资源类型 Table 1 Basic resource types of SPASE |
这3类资源类型下分别有相应的标签对具体的科学数据属性进行描述.然而针对科学数据检索而言,一些针对数据管理者以及访问信息等的相关标签对于检索而言没有太大意义,因此在信息提取模块中将其排除,从而专注于科学数据相关的标签信息.
图 2展示广州某台站的宇宙射线相关数据,其元数据文件符合SPASE元数据规范,其中图 2(a)图为科学数据本身,图 2(b)图为该数据配套的元数据文件.

|
Download:
|
|
图 2 科学数据样例 Fig. 2 Scientific data sample |
|
{kind=link}
通过对日地空间领域科学数据文件和元数据文件仔细分析后,可以发现,针对科学数据文件而言,除数值类型的科学文件中的文件头部会包含一部分数据描述信息外,其他例如图像、视频等数据一般不包含关于数据本身的描述信息.而对于科学元数据文件而言,往往包含较为全面的数据描述信息,涉及数据集本身、观测设备、观测台、观测区域、数据参数等相关信息,而这些信息在评估数据与检索相关性的时候至关重要,因此应该将其纳入考虑范围,并且适当舍弃掉其他无关信息项.
基于多种元数据的分析,在预处理阶段将重点提取以下属性标签:
ResourceName, Description, MeasurementType, ObservedRegion,
Parameter, Name, Description, //针对数值类型数据
Observatory, ResourceName, Description,
Instrument, ResourceName, Description.
在模型验证测试阶段,将根据具体的测试效果对相关属性进行增删.图 3展示检索模型预处理模块对于图 2(b)中元数据的处理结果.

|
Download:
|
|
图 3 SPASE格式元数据预处理结果样例 Fig. 3 Result sample from metadata pre-process module |
|
{kind=link}
该模块主要负责对日地空间科学领域元数据中提取的数据相关信息进行文档向量转化,主要步骤包含:分词,去停用词,词项还原,TF-idf计算,构成词项文档矩阵.
首先对文档内容进行分词,目前常用的自然语言处理工具包有很多,为了支持更多的科学元数据文件,模型需要保证工具包中英文的分词能力,在实验中选用jieba分词组件.
在分词的同时,将直接去掉与检索关系不大,却出现频率很高的一些介词、代词和冠词,例如“the”、“a”、“an”、“that”、“those”等停用词.
随后对于以上词项进行词项还原和词频统计,可得单个文档的词项频率.考虑到不同词项在检索中的重要性不同,在这里使用词项的tf-idf权重作为组成词项-文档矩阵的数据项.公式如下
| ${{w}_{t,d}}=\left( 1+\log t{{f}_{t,d}} \right)\cdot \log \frac{N}{d{{f}_{t}}},$ |
其中,tft, d为词项t在文档d中的词项频率,dft表示包含词项t的文档的数量,即文档频率,该权重可以随着词项频率的增大而增大,随着词项罕见度的增加而增大,因此可以更好地表征不同词项的重要程度.
计算TF-idf权重需要大量的统计运算,在实验中使用gensim文本处理工具库,来进行各种词频和文档频率的统计.
以2.1中展示的科学数据名称为例,对其进行常规的文档向量化操作.
GuangZhou Cosmic Ray Meson Counts Level 2 Data in TXT Format
对以上文档分词、去停用词之后,得到以下数据:
GuangZhou Cosmic Ray Meson Counts Level Data TXT Format
随后对于以上词项进行词项还原和词频统计,可得单个文档的词项频率:
guangzhou:1 cosmic:1 ray:1 meson:1 count:1 level:1 data:1 txt:1 format:1
最后根据整个检索集合词频统计得出文档频率,进而计算出该文档中各词项的TF-idf值.
1.3 语义空间降维接下来对文档向量化得到的原始词项-文档矩阵进行奇异值分解.
奇异值分解和特征值分解在机器学习领域的应用十分广泛,二者有着紧密的联系,它们的目的都是一样的,就是提取矩阵最重要的特征.特征值分解是提取矩阵特征的一个很好的方法,然它只能对方阵进行操作,在现实生活的各类应用场景中,绝大多数的矩阵都不是方阵,奇异值分解则可以很好地处理各类矩阵的分解问题.
对于任意m×n的矩阵,将其分解为m×m的U矩阵,m×n的Σ奇异值矩阵,n×n的VT矩阵,如下所示:
| $\boldsymbol{A}=\boldsymbol{U}\mathit{\Sigma} {{\boldsymbol{V}}^{\text{T}}}.$ |
其中,U矩阵的列向量被称为左奇异向量,这些向量是矩阵AAT的特征向量;Σ矩阵中对角线上的元素称为奇异值,是AAT或者ATA的非零特征值的平方根,矩阵中的非对角线元素均为0;V矩阵的列向量被称为右奇异向量,这些向量是矩阵ATA的特征向量.
其计算过程如下
| $\left( {{\boldsymbol{A}}^{\text{T}}}\boldsymbol{A} \right){{\boldsymbol{v}}_{i}}={{\lambda }_{i}}{{\boldsymbol{v}}_{i}}.$ |
对ATA方阵求解特征值和特征向量,得到的v即为上面所说的右奇异向量,对特征值λi求平方根即可得到奇异值σi:
| $\begin{align} & {{\sigma }_{i}}=\sqrt{{{\lambda }_{i}}}, \\ & {{\boldsymbol{u}}_{i}}=\frac{\boldsymbol{A}{{\boldsymbol{v}}_{i}}}{{{\sigma }_{i}}}. \\ \end{align}$ |
这里的ui即为上面的左奇异向量.
可以在根据分解后的矩阵的基础上,使用前N个较大的奇异值以及其对应的左右奇异向量来近似模拟原始矩阵,从而发掘不同元素间的潜在关系,同时也可以去除噪声,节约存储空间.基于这些特性,奇异值分解被广泛应用于数据压缩、图片降噪、数据分析等领域.
在原型系统中主要使用NumPy、SciPy等数值计算扩展包对于矩阵进行奇异值分解.
以下列文档集合为例,经过文档向量化处理之后,可得到其对应词项-文档矩阵,如表 2所示.
·w1: Plasma Electrons and Currents Experiment (PEACE) Data at the ESA Cluster Science Archive
·w2: Depletion of solar wind plasma near a planetary boundary
·w3: observations of solar plasma electric fields
·w4: Wind 3DP Electron Plasma Moments
·n1: the neutral component of the interstellar gas
·n2: Kinetic parameters of interstellar neutral helium
·n3: Neutral-stabilized electron-ion recombination in ambient helium gas
·n4: An introduction to the helium ion microscope
该文档集合由太阳风(Solar wind)相关的4条语句以及中性气体(Neutral gas)相关的4条语句构成,其中w1—w4为太阳风相关的语句,n1—n4为中性气体相关的语句.在做文档向量化处理的时候,除常规的停用词被去掉之外,也去除了在整个文档集合中只出现1次的词语,从而更好地关注与多篇文章都有关联的词项.
|
|
表 2 原始词项-文档矩阵 Table 2 Original term-document matrix |
为了使降维前后的矩阵对比更加直观,在这里统一将在文档中出现的词项权值标注为1,在检索模型实现时依然使用TF-idf权重.
上文文档集的词项-文档矩阵经过奇异值分解之后得到如下3个矩阵:
| $\begin{array}{*{35}{l}} \text{electron}\left( \text{ic} \right) & -0.59 & -0.02 & 0.44 & -0.48 & 0 & -0.01 & 0.3 & -0.37 \\ \text{plasma} & -0.6 & 0.31 & -0.17 & -0.1 & 0 & 0.15 & -0.49 & 0.49 \\ \text{solar} & -0.3 & 0.19 & -0.27 & 0.43 & 0.71 & -0.12 & 0.25 & -0.2 \\ \text{wind} & -0.3 & 0.19 & -0.27 & 0.43 & -0.71 & -0.12 & 0.25 & -0.2 \\ \text{neutral} & -0.21 & -0.62 & -0.2 & -0.01 & 0 & 0.08 & 0.49 & 0.53 \\ \operatorname{int}\text{erstellar} & -0.09 & -0.41 & -0.53 & -0.17 & 0 & 0.41 & -0.3 & -0.5 \\ \text{gas} & -0.18 & -0.46 & 0.08 & 0.12 & 0 & -0.74 & -0.43 & -0.07 \\ \text{helium} & -0.14 & -0.26 & 0.54 & 0.59 & 0 & 0.47 & -0.2 & -0.05 \\ \end{array}$ |
如上所示,该矩阵为奇异值分解后的U矩阵,在U矩阵中,每个词项对应一行,每个min(M,N)对应一列,其中M为词项的数目,N是文档的数目.这是个正交矩阵:
(i)列向量都是单位向量;
(ii)任意2个列向量之间都是互相正交的,可以想象这些列向量分别代表不同的“语义”维度.矩阵元素uij给出的是词项i和第j个“语义”维度之间的关系强弱程度.
| $\begin{array}{*{35}{l}} 3 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 2.5 & 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 1.6 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 1.2 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0.8 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0.5 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0.2 \\ \end{array}$ |
如上所示,该矩阵为奇异值分解后的Σ矩阵,矩阵Σ是个min(M,N)×min(M,N)的对角方阵,对角线上是矩阵A的奇异值,由大到小排列,奇异值的大小度量的是相应“语义”维度的重要性.
| $\begin{array}{*{35}{l}} {{w}_{1}} & {{w}_{2}} & {{w}_{3}} & {{w}_{4}} & {{w}_{1}} & {{w}_{2}} & {{w}_{3}} & {{w}_{4}} \\ -0.4 & -0.4 & -0.5 & -0.5 & -0.16 & -0.1 & -0.38 & -0.05 \\ 0.12 & 0.27 & 0.19 & 0.19 & -0.6 & -0.41 & -0.55 & -0.1 \\ 0.17 & -0.44 & 0 & 0 & -0.41 & -0.46 & 0.54 & 0.34 \\ -0.49 & 0.63 & -0.13 & -0.13 & -0.05 & -0.16 & 0.2 & 0.5 \\ 0 & 0 & 0.71 & -0.71 & 0 & 0 & 0 & 0 \\ 0.19 & -0.12 & 0.03 & 0.03 & -0.32 & 0.64 & -0.25 & 0.61 \\ -0.44 & 0 & 0.11 & 0.11 & -0.54 & 0.41 & 0.35 & -0.44 \\ 0.57 & 0.39 & -0.43 & -0.43 & -0.23 & 0.12 & 0.21 & -0.22 \\ \end{array}$ |
如上所示,该矩阵为奇异值分解后的VT矩阵,在矩阵VT中,每篇文档对应一列,每min(M,N)对应一行.同样,这也是一个正交矩阵:
(i)每个行向量都是单位向量;
(ii)任意2个行向量之间都是正交的,同样每个行向量代表的是一个语义维度,矩阵元素vij代表的是文档i和语义维度j的关系强弱程度.
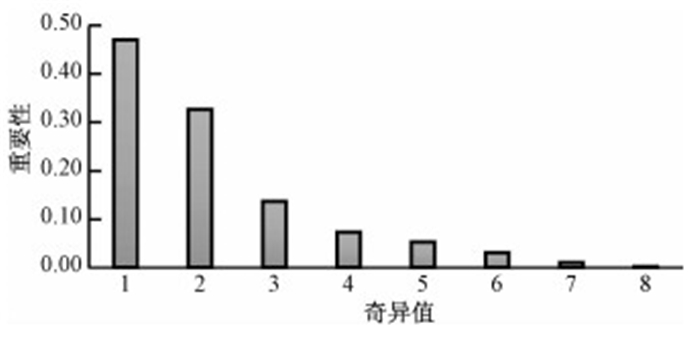
图 4显示了各奇异值的大小占比如图所示,矩阵Σ中的奇异值从大到小排列,而且σ的减少特别得快,在很多情况下,前10%甚至1%的奇异值之和就占了全部奇异值之和的99%以上,因此可以通过忽略较小的奇异值来凸显其他重要的语义维度.

|
Download:
|
|
图 4 各奇异值重要性占比 Fig. 4 Importance of each singular value |
|
{kind=link}
在上面在例子中,仅提取前2维,设置其余的奇异值为零,将3个矩阵相乘,得到新的词项文档矩阵A′,如表 3所示.
|
|
表 3 提取前2维的词项-文档矩阵 Table 3 Generated term-document matrix from the first two dimensions |
经过将降维后的词项-文档矩阵A′与原始矩阵对比,可以发现一些细节上的变化:
在日地空间系统领域,electron和plasma是太阳风中比较常见的物质,很多情况下二者或共同出现.由于词项electron和plasma在文档w1,w3,w4中频繁共现,LSI技术可以发现这种共现关系,并在降维后的词项-文档矩阵中予以体现.在A′中w2文档的electron被置为0.67,尽管w2中并未出现该词汇.另一方面,尽管在原始矩阵中文档n3的词项electron权重为1,然而在降维后的矩阵中,其值被调整为0.46,以体现其在语义空间中不重要性.另外根据文档向量之间的余弦相似度计算可得,文档w1与文档w4在降维前后的相似度从0.48变为0.998,增加了将近1倍,从而凸显了二者的相关性.
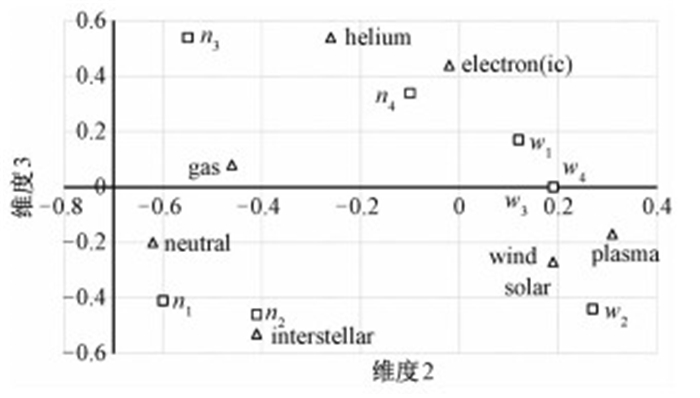
矩阵分解后,不同维度所代表的意义往往比较微妙,往往需要领域专家研究后进行解读.一般情况下,第1维的值受到文档长度和词频的影响比较大.所以这里提取语义空间中第2维度和第3维度的数据绘制出各个词项和文档在抽象语义空间中的位置,从图像中可以比较直观地看出它们之间的相互关系,如图 5所示.

|
Download:
|
|
图 5 抽象语义空间下词项与文档的近似位置 Fig. 5 Approximate locations of terms and documents in abstract semantic space |
|
{kind=link}
从图 5中可以看出,第2维度的零点基本可以区分出2种不同类型的文档,与Neutral gas相关的文档在该维度上的值都小于零,而与Solar wind相关的文档均分布在零点右侧.相似文档以及相关文档有明显的聚集现象,由此可以推测在高维的抽象语义空间下,各个词项以及各个文档之间的相对位置关系.在检索相关文档的同时也可以发现相关的词项,可以通过聚类提取文档集合中的近义词,挖掘词项之间的语义关系.
1.4 检索操作在检索集合不变的情况下,以上所述的原始检索集合索引所包含的3个步骤只需要一次执行即可,针对用户的检索语句,检索模型仅需要对检索语句进行向量化操作得到检索向量Q,随后计算检索向量Q与降维之后的矩阵A′中的文档向量Di的语义距离.
在这里,使用余弦相似度来定义检索向量与文档向量之间的语义距离,公式如下:
| $\begin{align} & \text{sim}\left( \boldsymbol{Q},\boldsymbol{D} \right)=\cos \left( \boldsymbol{Q},\boldsymbol{D} \right)= \\ & \frac{\sum\nolimits_{i=1}^{n}{{{\boldsymbol{Q}}_{i}}\times {{\boldsymbol{D}}_{i}}}}{\sqrt{\sum\nolimits_{i=1}^{n}{{{\left( {{\boldsymbol{Q}}_{i}} \right)}^{2}}}}\sqrt{\sum\nolimits_{i=1}^{n}{{{\left( {{\boldsymbol{D}}_{i}} \right)}^{2}}}}} \\ \end{align}$ |
根据检索向量与文档向量之间的语义距离由低到高来对检索结果进行展示.
2 实验对比基于上面介绍的检索模型,实现了一个原型系统,并对模型有效性进行检验,为获取前期测试用数据集,实验设计了爬虫程序爬取NASA空间物理数据发布系统(NASA′s Space Physics Data Facility)中的1 365个科学数据元数据文件,在此基础上对检索模型的准确率和召回率进行测试,并以SPDF系统中的检索工具作为对比组,进行效果对比.
经过对科学元数据进行信息提取,文档向量化处理之后,得到的原始矩阵大小为10 206×1 365,针对该矩阵做不同程度的降维处理,进而分析模型的有效性.
在评价指标上,基本依照常规的检索评价指标,即准确率和召回率.然而计算召回率时需要实验者准确获知测试文档集中所有相关文档的数量,然而以现有的条件,很难准确地获取这一数据,所以本实验对于召回率指标进行了调整,使用召回率比作为评价召回率的替代指标,其计算公式如下
| $\text{recal}{{\text{l}}_{\text{ratio}}}\text{=}\frac{\text{recal}{{\text{l}}_{\text{new}}}}{\text{recal}{{\text{l}}_{\text{cmp}}}}\text{=}\frac{R{{r}_{\text{new}}}}{R{{r}_{\text{cmp}}}}$ |
其中,Rrnew和Rrcmp分别代表实验组与对比组的检索到且相关的文档数量.
为了相对全面地展示检索模型的具体性能,实验选取日地空间领域中相对独立的几个概念作为查询样例,如表 4所示,并对其检索结果进行对比分析.
|
|
表 4 测试样例 Table 4 Test case |
下面将分别展示实验结果,包括不同降维程度下召回率,准确率的变化情况,以及检索模型各步骤效率分析.
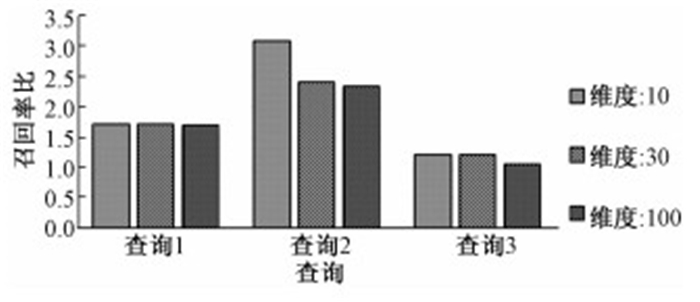
从图 6召回率比的变化图像可以看出,在对原始矩阵做不同程度的降维所得到的结果略微不同,在维度较低的情况下,检索模型的召回率较高,随着维度的逐渐增加,模型的召回率逐渐下降,然而召回率比基本都大于1,说明该模型的召回率高于对比组的召回率,说明该检索模型相比于对比组能够检索到更多相关的科学数据.

|
Download:
|
|
图 6 召回率对比 Fig. 6 Recall rate comparison |
|
{kind=link}
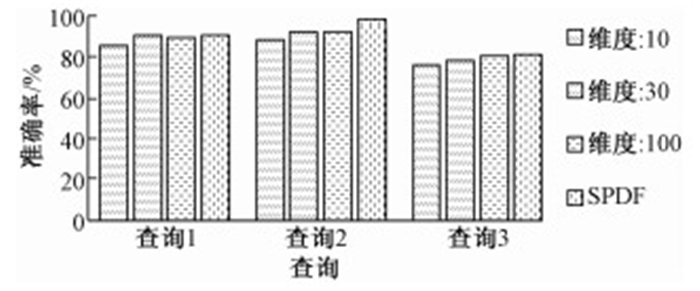
通过图 7的准确率对比可以发现,对原始矩阵进行不同程度的降维同样会对准确率产生一定的影响.整体而言,在维度较低的情况下,检索模型的准确率相对于对比组而言比较低,但是差别不大,且准确率水平依然很高,随着维度的增加,准确率逐渐提高.另外,通过对检索结果显示的优化,可以保证检索结果中排名靠前结果项的准确率,确保了用户体验.

|
Download:
|
|
图 7 准确率对比 Fig. 7 Precision rate comparison |
|
{kind=link}
虽然低维度会导致检索模型整体上的准确率损失,但是模型整体的计算效率会明显增加,同时召回率会得到极大的提升,而且科学数据检索往往更加强调“发现数据”的能力,所以总体来看,是利大于弊的.
下面展示一些检索结果,来分析该检索模型在语义方面的特性.
从图 8的检索结果可以发现,针对于检索词“Magnetic Field”的检索,可以同时获取到“MFI”,“Magnetometer”,“SuperMAG”等相关的科学数据,对于第20位的检索结果“TWINS 1-Spacecraft Ephemeris”,通过分析其科学数据后发现,尽管数据名称为星历相关的数据,但是其数据中的确包含卫星所在位置的磁场信息,因此针对于该检索,前20个检索结果的准确率为100%.

|
Download:
|
|
图 8 检索词“Magnetic Field”的top20结果 Fig. 8 Top 20 retrieval results for "Magnetic Field" |
|
{kind=link}
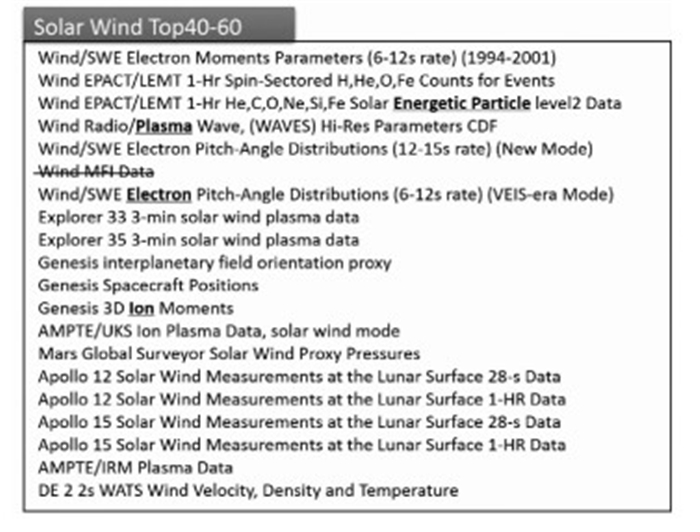
图 9主要展示检索词“Solar Wind”的40~60的检索结果,之所以展示这部分数据并不是因为top40的检索结果不好,恰恰相反,前40的检索数据中均包含检索词“Solar Wind”,而在40~60这部分结果中出现“Energetic Particle”,“Plasma”,“Electron”,“Ion”等太阳风相关的科学数据.

|
Download:
|
|
图 9 检索词“Solar Wind”的top40~60结果 Fig. 9 Top 40~60 retrieval results for "Solar Wind" |
|
{kind=link}
从以上结果样例中可以看出,该检索模型的检索结果能够兼顾到一定的语义信息,可以检索到与检索词潜在相关的概念数据,从而为用户提供相对全面的数据检索结果.
与此同时,也对检索模型不同阶段的耗时情况进行了统计和分析.
从图 10可以看出数据预处理阶段、分词和去单操作占比较高,3个阶段的操作占总计算时间的90%,其中去单操作约占总时间一半,该操作在传统的文档向量化过程中是没有的,然而在本文的检索方法中,如果不执行去单操作的话,准确率一般在70%左右,而执行该操作之后,准确率可以得到明显的提升.主要原因是分词操作之后,词表中会出现一些在整个文档集中只出现过1次的异常罕见词项,这些词项有可能是一些科学名词的简写,也有可能是因为分词失败或者打字错误造成的特殊词项,如果不对其进行处理,根据tf-idf权重计算公式,这些词汇可能会因为其罕见性而被赋予很大的权值,从而对后期的检索产生干扰,因此去单操作是必不可少的过程.在实验中的测试集合上,去单操作可以将分词操作生成的12 601个词项中去除2 395个异常的词项,一定程度上减轻了后续步骤中奇异值分解的压力,同时也极大提高了检索的准确率.

|
Download:
|
|
图 10 检索模型各步骤耗时占比 Fig. 10 Proportion for each step in the whole processing time |
|
{kind=link}
另外奇异值分解所在的步骤“LSI”的耗时根据降维程度的不同而有所变化,在试验中,模型要对10 206×1 365维的矩阵进行奇异值分解,在其降维至10,100,1 000等不同大小的维数下,其耗时分别为2,3,30 s.然而在试验中发现,针对测试数据集合,在降维维数超过100之后,维数的增加对于准确率的提升贡献非常小.因此实际上,花费更多的计算资源进行更高维度的近似是没有意义的,往往得不偿失.
在实际的应用场景中,虽然每天都会有新的科学数据产生,对于日地空间领域科学数据而言,这只是数据集合在时间维度上的扩展,不会导致其相应科学元数据的变更.因此尽管检索集合预处理阶段的耗时相对较多,但实际上该部分操作的执行频率极低,在没有新的科学数据集加入的情况下,以上原始检索集合的索引操作不需要重复执行,因此该检索模型可以保证很好的检索效率.
3 结论与讨论计算机理论唯有与特定学科紧密结合,才能产生更加广阔的科学前景和更加深远的社会影响.该项目利用信息检索以及自然语言处理领域的主流技术,结合日地空间科学领域的实际情况,实现了兼顾潜在关联的数据检索模型,丰富了日地空间领域科学数据检索方法,提高了该领域科学数据的检索质量,为数字地球和宇宙地图等科学计划奠定了基础.与此同时,该方法也可以应用于生物、水文、极地、海洋等科学领域的数据检索,对于不同种类的元数据具有很好的兼容性和扩展性.
鉴于原始检索集合索引的效率相对较低,接下来会对这一部分的处理效率进行优化,而Spark计算框架具有完备的矩阵运算并行化处理库[14],擅长处理高重复、可并行化的运算,因此该计算框架将会作为后期模型改进的基础框架.另一方面,鉴于日地空间科学数据以及元数据种类的多样性,接下来模型会增加对于多类元数据格式的支持,增加检索集合覆盖的科学数据种类和范围,并进行跨系统的数据检索尝试.
感谢国家科技基础条件平台地球系统科学数据共享网——“空间科学数据共享平台”的数据支持.
| [1] | Jones C B, Purves R, Ruas A, et al. Spatial information retrieval and geographical ontologies an overview of the SPIRIT project[C]//Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval. ACM, 2002:387-388. http://cn.bing.com/academic/profile?id=2167687441&encoded=0&v=paper_preview&mkt=zh-cn |
| [2] | Li W, Yang C, Nebert D, et al. Semantic-based web service discovery and chaining for building an Arctic spatial data infrastructure[J]. Computers & Geosciences , 2011, 37 (11) :1752–1762. |
| [3] | Bhattacharjee S, Ghosh S K. Automatic resolution of semantic heterogeneity in GIS:an ontology based approach[M]//Advanced Computing, Networking and Informatics-Volume 1. Springer International Publishing, 2014:585-591. |
| [4] | Wu Z, Zeng W, Wu J, et al. Method for semantic service registration and query based on WordNet:U.S. Patent 8671103[P]. 2014-03-11. |
| [5] | Pal D, Mitra M, Datta K. Improving query expansion using WordNet[J]. Journal of the Association for Information Science and Technology , 2014, 65 (12) :2469–2478. DOI:10.1002/asi.2014.65.issue-12 |
| [6] | 邓志鸿, 唐世渭, 张铭, 等. Ontology研究综述[J]. 北京大学学报:自然科学版 , 2002, 38 (5) :730–738. |
| [7] | Cui W, Wu H. Using ontology to achieve the semantic integration and interoperation of GIS[C]//Geoscience and Remote Sensing Symposium, 2005. IGARSS'05. Proceedings. 2005 IEEE International. IEEE, 2005, 2:3. |
| [8] | Janowicz K. Observation-driven geo-ontology engineering[J]. Transactions in GIS , 2012, 16 (3) :351–374. DOI:10.1111/tgis.2012.16.issue-3 |
| [9] | Christidis K, Mentzas G, Apostolou D. Using latent topics to enhance search and recommendation in Enterprise Social Software[J]. Expert Systems with Applications , 2012, 39 (10) :9297–9307. DOI:10.1016/j.eswa.2012.02.073 |
| [10] | Li W, Goodchild M F, Raskin R. Towards geospatial semantic search:exploiting latent semantic relations in geospatial data[J]. International Journal of Digital Earth , 2014, 7 (1) :17–37. DOI:10.1080/17538947.2012.674561 |
| [11] | Li W, Bhatia V, Cao K. Intelligent polar cyberinfrastructure:enabling semantic search in geospatial metadata catalogue to support polar data discovery[J]. Earth Science Informatics , 2014, 8 (1) :111–123. |
| [12] | Li W, Yang C, Raskin R. A semantic enhanced search for spatial web portals[C]//AAAI Spring Symposium:Semantic Scientific Knowledge Integration, 2008:47-50. |
| [13] | Li W, Yang P, Zhou B. Internet-based spatial information retrieval[M]//Encyclopedia of GIS. Springer US, 2008:596-599. http://cn.bing.com/academic/profile?id=1796509154&encoded=0&v=paper_preview&mkt=zh-cn |
| [14] | Zaharia M. Spark:in-memory cluster computing for iterative and interactive applications[C]//Invited Talk. NIPS Big Learning Workshop:Algorithms, Systems, and Tools for Learning at Scale.Granada, Spain. December 12-17, 2011. |