 2016, Vol. 33
2016, Vol. 33 



视频作为一种广受欢迎的资源在网络上日益流行,电影、电视剧、动漫、娱乐节目、纪录片等都以视频的形式呈现在我们面前.这些视频带给我们视觉和听觉的享受,丰富了现代生活.
另一方面,视频在提供丰富生动的内容的同时也带来了对其进行存储和访问的挑战.由于视频文件同时包含图像和声音,存储时需要更多的存储空间.尽管大多数视频均使用压缩格式进行存储,但其对空间的要求依然远高于一般文件.同时,对于视频提供商来说,用户观看视频对网络状况有一定的需求.如果网络状况较差,视频流接收速率低,容易导致播放卡顿,严重影响用户体验.
为解决视频存储空间和传输成本的问题,DAN(Directed Access Network)被提出,DAN使用分布式的可扩展的方式存储视频文件以解决存储空间的问题,并设置一系列的边缘节点作为视频文件缓存,使得用户的请求可以就近得到响应,提升用户的播放体验[1].在先前版本的DAN系统[2]中,视频文件的存储和检索是非常重要的一个方面,尽管使用Bloom Filter进行优化,仍然需要对存储节点进行由近及远的逐个查找,效率较低;同时在给视频文件选择存储节点的过程中仅考虑了地域分布,未考虑到存储节点的存储均衡.
针对以上问题,本文提出一种基于哈希和Bloom Filter的文件系统HBF(Hash and Bloom Filter Based File System).HBF可以应用于原有DAN中取代原有的文件系统,它同DAN中的文件存储系统一样具备可伸缩易扩展的特性,同时改进了其文件存储和检索的性能, 文件在多个节点进行存储时更加均衡.HBF取代DAN系统中的存储节点,并结合原有的总控节点和边缘节点,可以构建一个更加高效稳定的流媒体分发系统.其中总控节点负责维护全局元数据和视频列表,边缘节点提供缓存和用户接口,存储节点高效均衡地进行文件存储,所有这些节点共同协作,为用户提供流畅的视频播放体验.
本文主要就分布式视频存储的策略进行研究,探索HBF的节点设置、存储方法、可伸缩性和检索方法等问题.
1 相关原理 1.1 Bloom FilterBloom Filter是一种能够快速查询某元素是否包含于特定集合的数据结构[3-4].它使用一组哈希函数和一个向量来表示集合数据,其中的向量为二进制向量,即某个维度的值为0或1.
在将元素key插入集合的时候,首先通过k个哈希函数分别计算得到k个哈希值,然后将k个哈希值作为下标对应至二进制向量的k个位置并将这些位置的值置为1.
在查询某个元素key是否存在于集合中的时候,同样通过k个哈希函数得到k个值,并检查以这些值为下标的位置上的值是否均为1,如果是则返回元素存在,反之如果存在不为1的位置,则要查询的元素不在集合内.
但是Bloom Filter有可能出现伪正例,即在元素不存在集合中时有很小的可能返回元素存在.针对这一问题,可以通过优化设置Bloom Filter的各项参数改善.假定Bloom Filter结构含有m个二进制位,k个哈希函数,且有n个元素需要存入,则最优哈希函数个数为
| $k=\frac{m}{n}\ln 2,$ |
给定伪正例出现概率p,最优的二进制位个数为
| $m=-\frac{n\ln p}{\ln 2}.$ |
此外,如果给定了m, n, k,有
| $p={{\left( 1-{{e}^{-k\left( n+0.5 \right)/\left( m-1 \right)}} \right)}^{k}}.$ |
一致性哈希是应用在分布式系统中的算法[5-6].它首先随机或按一定策略产生一组token,然后为每个节点分配一个token.在进行文件存储的时候,通过哈希函数将文件映射到哈希空间的某个值,并查找到第一个不小于该值的token,该token所对应的节点即为文件将要存放的节点.文件检索的流程与存储的过程类似,通过计算要查找的文件的哈希值,找到文件可能存放的位置,如果该位置存在要查找的文件则查找成功,否则系统中未存有该文件.
在实际应用中,为了错误恢复一般要进行文件的冗余存储.对于一个文件,一般采用3个副本的策略进行存储.一致性哈希中的通常做法是在文件存储到某个节点时,将这一节点之后的2个节点同时存储一份拷贝.
一致性哈希中相对容易出现各节点存储不平衡的问题,解决办法通常是将存储压力过大的节点的哈希空间分裂到其他节点,与此同时,对应的文件也需要进行物理转移,这种方式增加了维护存储均衡的开销.
1.3 KinesisKinesis是微软研究院提出的分布式存储系统[7].在Kinesis中,服务器节点被划分为k个组,每组的存储量基本一致.每个组具有一个与其他组不同的线性哈希函数,能够将文件映射到组内某个节点.在进行文件存储的时候,对于某一特定文件,假设其备份策略为r备份,则在划分好的k个服务器组中计算出k个位置,每个位置对应特定服务器组内的某个节点,通过计算这些节点的负载,将r个负载小的节点选取出来,并将文件存储在这r个节点中.通过这种存储策略,使得文件在存储的时候即考虑到负载均衡,避免了在负载不均衡发生后进行文件调度以重新获得均衡所需的开销.
Kinesis在文件进行存储时即充分考虑负载均衡,避免了后期因负载不均衡而造成的文件移动开销.但是在该系统中增加节点不够灵活,往往需要增加原有节点一倍数量的节点,当特定哈希空间不均衡时不能通过简单地增加一个或少量几个节点来解决.
2 HBF存储原型系统对于一个分布式文件系统来说,在设计实现的时候需要考虑的因素有很多,重要的如可扩展性、负载均衡、存储和检索效能、错误恢复等,在工业环境中还需考虑更多的因素如配置管理、系统监控与报警、任务调度等[8-9].本文主要就HBF的文件操作接口、扩展性、存储划分策略、查询策略等方面做重点研究.
2.1 系统接口HBF由一系列的平行节点组成,各个节点的角色分工相同,提供文件的存取功能.它是一个基于key-value的存储系统,value对应具体的文件,key是文件相关联的识别标志(如文件名,MD5值等).和大多数key-value的存储系统一样,HBF的系统接口十分简洁,它只有2个接口方法:一个是put,一个是get.Put方法将一个文件放入文件系统,get方法将一个key对应的文件取出.
2.2 存储策略HBF在设计时充分考虑了文件在各个节点之间的平衡分布,在一致性哈希的基础上加以创造性改进,使得存储负载更加均衡.
在一致性哈希算法中,哈希函数的取值空间可以看做是一个环形.系统从这个取值空间中随机产生k个token,每个token分配给一个服务器节点.当调用put操作存放文件时,由文件名或文件的其他特征得出文件的key,再由hash函数计算出其对应的value值.然后按照从小到大的顺序查找token,找到第一个不小于value的token,在这个token所对应的节点存放文件,形成key到value再到节点的对应关系.
在传统的系统中进行副本存储时,假设副本个数为M,经典的做法是先按照一致性哈希算法计算得到一个节点,然后在哈希环上按照顺时针方向依次找到该节点的M-1个后继节点,并在这些后继节点上存储文件的副本[10].按照这种方式进行存储划分容易出现的问题是文件存储不均衡,为此很多使用一致性哈希的系统设置了虚拟节点[11],并在不均衡产生时调整虚拟节点与实际物理节点的对应关系,并将对应的文件在物理机器间加以传递,使得存储负载大的节点上的文件分摊到负载小的节点上.这种事后补救的做法一定程度加重了节点间的IO负担.
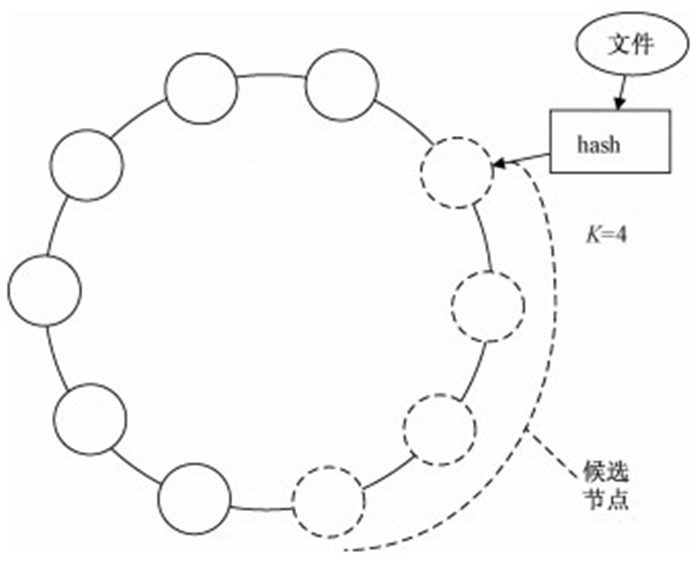
在HBF中存储副本的做法与此不同,如图 1所示,HBF引入了候选节点的概念,文件在存储时会从多个候选节点中选择其中部分节点存储副本.假设副本数量为M,候选节点数为K(K > M),它从K个候选节点中选择存储负载小的M个节点,并将副本存储于这些节点,给存储平衡以新的机会.在HBF中,副本个数M和候选节点个数K可以由用户自定义.在将文件存储至某一节点时,该节点及其顺时方向上的K-1个节点组成候选节点,这些节点可能有不同的可用容量,从中选择存储负载小的M个进行实际的存储可以使得这些节点间保持相对的存储平衡.

|
Download:
|
|
图 1 HBF存储策略图示 Fig. 1 HBF storage strategy |
|
{kind=link}
通过改变K和M的值,可以得到不同的系统特性,获得不同的效果:
1) 如果K等于M,系统等价于采用传统的一致性哈希算法;
2) 如果K > M,可以使得文件在存储时充分考虑节点间的存储平衡;
3) 若N等于系统的节点总数,相当于在整个系统中选择存储压力最小的节点进行存储,系统将达到相当理想的存储平衡程度.
值得注意的是,在取得存储平衡的同时,由于增加了从K个候选节点中选取M个副本节点的过程,效率会有轻微的损失.但是由于增加的计算量为常数量级,且常数项很小,一般情况下对性能的影响可以忽略不计.
2.3 增加节点在HBF中增加节点时,会优先考虑从负载较大的节点处划出一部分哈希空间给新增加的节点,以分担其负载,划分的比例可简单地为原节点哈希空间的一半,或根据原节点负载压力的紧迫程度和新节点的能力适当调整,并将原节点上的文件根据哈希值重新分配,计算得到的哈希值落在新节点的转存在新节点上.由于新增了节点,会导致原有的存储结构部分失效.
具体地,假设新加入的节点编号为i,那么对于节点i逆时针方向数第K个节点,其候选节点由于新节点的加入变为了(i-K)~(i+1),为了维持原有的规则不变,将第i+1个节点中作为第i-K个节点副本的文件删除,并在第i-K到i个节点中为其增加一个副本,这里选取节点的方式与2.2节中介绍的相同.
2.4 移除节点节点需要移除的情况有两种,一种是由于系统缩小规模降低成本等原因永久性地移除节点,另外一种是由于节点故障导致节点临时不可用,但在较短时间内能够重新上线.
对于第1种情况,可将要移除的节点的哈希空间划分到相邻节点,并将对应的文件转移,如果文件从A节点移入B节点,但B节点已经含有该文件,那么就按照2.2中的方法再次选取一个节点,来维护副本数量不变.对于第2种情况,如果能够在短时间内将故障节点恢复,则可不对故障节点内的文件进行转移,仅将故障节点标记为不可用节点,不作为文件存取的候选节点.
2.5 视频文件检索对于用户请求的视频,系统必须能够找到其存放的位置,才能为用户提供相应的视频流服务.对于某个视频,其存储位置可由哈希值得到.具体的做法为:
Step1采用与视频文件存储时相同的哈希函数,对用户请求的视频产生一个哈希值value;
Step2按照从小到大的顺序查找存储节点,找到第一个token值不小于value的节点,该节点及其后续的N-1个节点即为候选节点;
Step3从N个候选节点中找出含有用户请求的视频的M个节点.
在Step3中,由于每个节点都对应有Bloom Filter结构,可以通过查找候选节点的Bloom Filter数据,判断其是否含有用户要找的视频[12].
在DAN系统中,需要逐个节点通过Bloom Filter进行查找,而HBF则通过采用一致性哈希快速定位候选节点,避免了在DAN中低效的检索过程,使得系统效能得以提升.
3 实验为了验证HBF在文件存储中所能达到的效果,我们设计了2个实验.第1个实验对HBF算法的效率进行验证分析,第2个实验测试HBF在不同条件下所能达到的平衡性.
3.1 实验环境本文主要针对检索效率和存储平衡性进行算法的改进,为了更好地验证算法在多种不同环境下的表现,也由于硬件数量的限制,所以本实验采用仿真验证的方式进行.具体实验软硬件环境如表 1所示.
|
|
表 1 实验环境表 Table 1 Experimental environment |
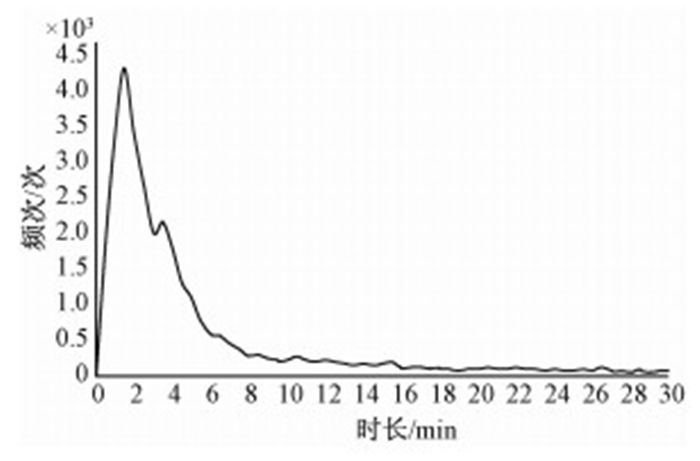
为使数据更加贴近真实应用场景,通过网络爬虫抓取国内视频网站爱奇艺的部分视频数据,视频量共计34 124个.在这些视频中,最长视频约5.4 h,最短视频仅2 s.具体的时长分布如图 2所示,其中1~5 min之间的短视频数量最多,占视频总数的54.8%.

|
Download:
|
|
图 2 实验数据的分布状况 Fig. 2 Distribution of experimental data |
|
{kind=link}
这种数据的分布规律符合互联网视频的特点,契合HBF系统针对互联网视频资源进行存储的使用场景.也正是由于这种数据特点,HBF不进行文件的分块存储.对文件先分片再进行存储在分布式系统中较常见,但这类系统一般适用于存储大型文件,而HBF针对的是众多短小的互联网视频,这是HBF不进行分片的主要考量因素.同时,小文件多大文件少,也使系统在偶尔遇到大文件时可能会产生平衡波动,这种现象将在后续的实验中详细阐述.
3.3 检索性能实验在文件检索性能测试中,模拟用户访问文件的动作,重复进行30万次查询测试,并记录系统在查询过程所花费的平均时间.同时使用DAN和一致性哈希算法进行同样的实验.表 2是当节点数量为200个时各个不同策略的查询时间对比.
|
|
表 2 检索时间表 Table 2 Query cost time |
通过表格数据可以发现HBF在3种方法中显著优于DAN原有存储方案,与一致性哈希相比仅有微小差距.
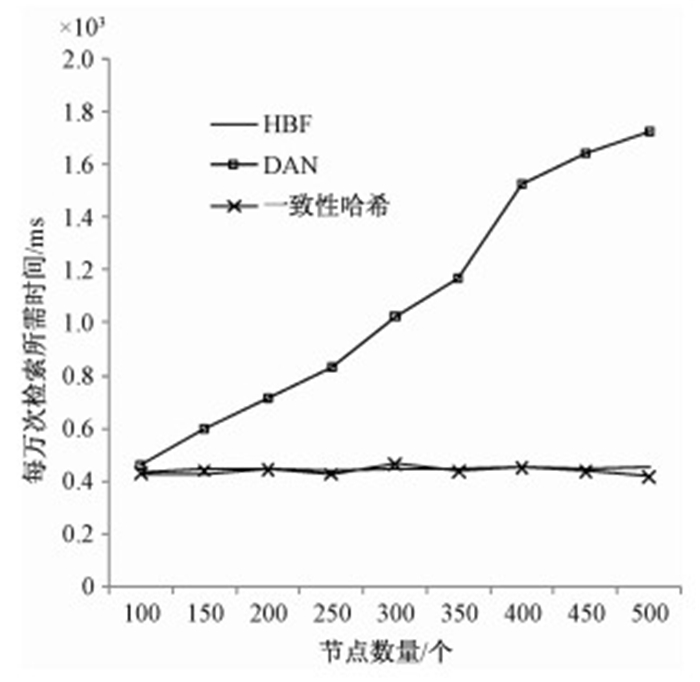
为验证节点数量对不同方法检索的影响,分别在节点数为100,150,300,350,400,450,500时对查询所需时间进行测量,得到图 3所示的结果.从图 3可以发现,HBF具有接近常数级的查找时间.

|
Download:
|
|
图 3 检索时间随节点数量的变化情况 Fig. 3 Variation in guery time with node amount |
|
{kind=link}
DAN原有查找算法的查找时间会随着节点的增加而增加,而HBF和一致性哈希在算法的运行时间方面不依赖于节点的数量,且二者具有几乎一致的时间效率.
HBF在效率方面较DAN有量级的提升,与一致性哈希几乎相同,这一结果与算法本身的时间复杂度吻合.因为HBF和一致性哈希都是使用哈希函数直接定位节点,其中HBF额外包含了Bloom Filter查找过程,而哈希函数和Bloom Filter的时间复杂度为O(1),因此整体复杂度仍然是O(1);DAN原有存储系统需要逐个节点进行查找,这一过程时间复杂度为O(N),因此呈现出随着节点数量增加,文件查找所需时间线性增长的现象.
3.4 存储平衡实验传统的一致性哈希中,存储平衡的维护要推迟到存储失衡时再进行节点间文件的调度,对IO资源的消耗大.相对于一致性哈希,HBF最大的优势是在文件存储进系统时即对存储平衡进行更严格的维护,节省后续调整所需的IO资源.
在平衡性实验中,分别控制候选节点数量,存储副本数量,并与DAN和一致性哈希进行对比,记录系统失衡节点数量随时间的变化.衡量存储平衡的指标借鉴Hadoop采用的衡量标准,用每个节点的存储使用率(节点磁盘使用量/节点存储总量)与整个系统的存储使用率(系统已使用的存储空间/系统存储空间总量)进行比较,如果差异超过一定阈值,则认为节点存储失衡.设节点存储使用率为u,系统存储使用率为v,阈值为t则
| $\left| u-v \right|=\left\{ \begin{align} & \le t,平衡 \\ & >t,失衡 \\ \end{align} \right..$ |
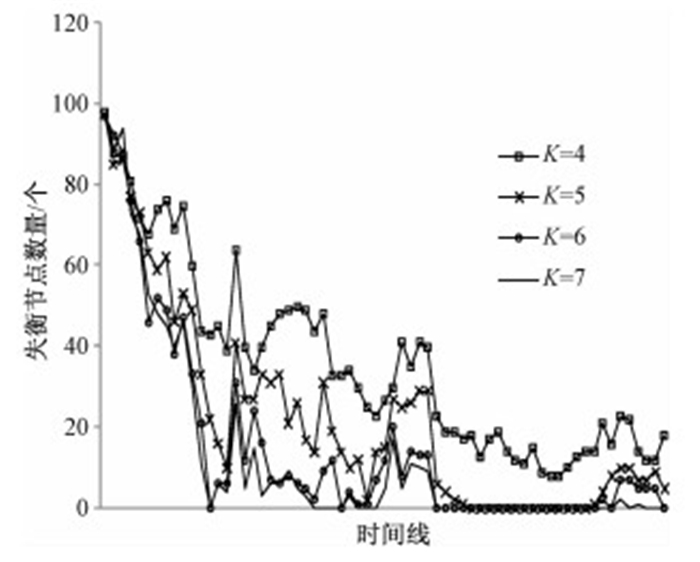
设定实验阈值t为5%,按照以上衡量指标,首先在不同候选节点数量下进行实验.图 4是在节点数量为100,实际副本数为3,控制候选节点数K分别为4,5,6,7情况下的实验结果.

|
Download:
|
|
图 4 不同候选节点数量对应的存储平衡情况 Fig. 4 Storage balance for different candidate node numbers |
|
{kind=link}
通过该实验可以得出如下规律:
1) 系统内失衡节点数量随候选节点数增加呈递减的趋势,候选节点数越多,系统的整体平衡性越好;
2) 随着时间的推移,平衡性达到更好的状态,且更趋于稳定;
3) 随着候选节点数增多,平衡效果加强但增量逐渐减少,在K=6和K=7时仅有较小差别.在K取更大值的时候我们也进行了测试,发现平衡性没有显著提高.
通过上述实验可以发现HBF存在冷启动的问题,即在系统开始存放文件时,会存在较大的不平衡性,这是由于系统在没有存储任何文件时,每个节点的存储量均为0,处于完全平衡状态,此时放入任何文件都很容易打破这个平衡.随着时间的推移,系统内存储的文件较为均匀地分布于整个系统,使系统在平衡性方面更加健壮.
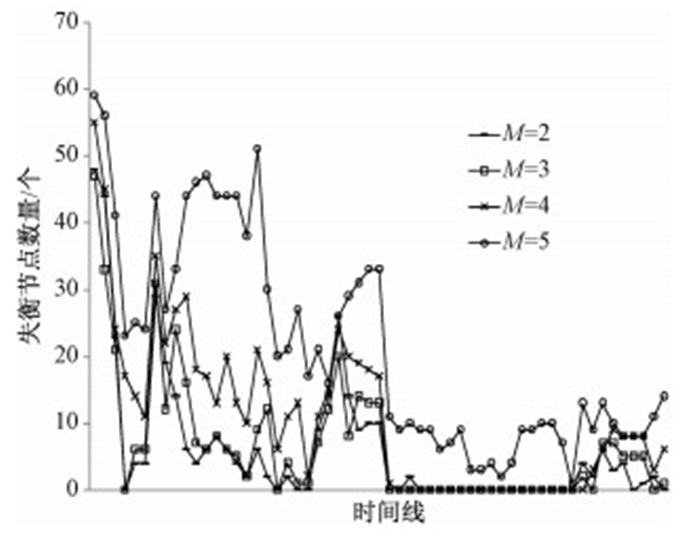
为保证系统的可靠性,存储在系统内的文件一般设置为3个副本,但有时因为特殊需求,副本的数量也会适当调整.分别令副本数量为2,3,4,5,并测试其对平衡性的影响,结果如图 5所示.

|
Download:
|
|
图 5 不同副本数对平衡性的影响 Fig. 5 Influence of copy number on balance |
|
{kind=link}
从图 5可以发现,副本数量为2、3、4时存储平衡效果较好,而副本数量为5时存储失衡节点数增加,平衡效果相对较弱.因为副本数为5时,6个节点中有5个节点必须要存储文件,可供选择的余地小,因此平衡性差.
同时也可以注意到,在系统的运行过程中,失衡节点数量偶尔有所震荡,通过查询震荡点的数据发现通常是在震荡点存储了大文件,导致存储平衡受到影响.
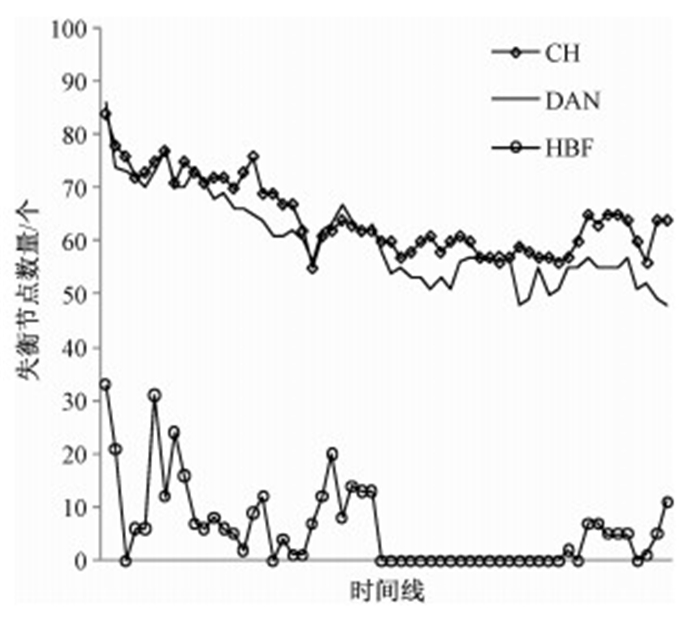
为比较HBF的平衡策略与传统的一致性哈希以及DAN的平衡策略的差异,进一步利用上述实验数据,并设定HBF的副本数为3,候选节点数为6,做了3种方法的对比实验.实验结果如图 6所示.图 6表明,HBF在存储平衡方面显著优于DAN和一致性哈希,采用HBF的存储平衡策略后将对集群节点资源的利用更加均衡合理,使得各个节点的能力得到更加充分的利用.

|
Download:
|
|
图 6 不同方法的存储平衡性 Fig. 6 Storage balance by using different methods |
|
{kind=link}
系统的失衡率为失衡节点数量与总节点数量的比值,这一指标可以用来有效衡量系统的存储平衡性.通过对连续时间点的采样统计,在本实验条件下一致性哈希的节点失衡率为64.53%,DAN的失衡率为60.31%,HBF的失衡率为5.95%.相对于一致性哈希和DAN,HBF在节点平衡性方面分别提高10.8倍和10.1倍.
4 总结和展望HBF提供了一个分布式环境下的视频文件存储策略,它为文件的存取提供了简洁的接口,文件能够以平衡、高效的方式存储在不同的节点上,存储节点能够灵活地增加或删除,使得系统具备可伸缩的容量,具有良好的可扩展性.
与一致性哈希相比,HBF通过有针对性地选择存储节点来存放文件,使得存储平衡性得到显著的改善,相对于Kinesis,它不需要每次增加一倍的节点来扩充容量,使得系统具有更好的可伸缩性,而且在性能方面,HBF通过快速的哈希和Bloom Filter的结合,提供了与一致性哈希一致的性能.
HBF具有均衡存储的效果,同时具备高效的性能.但在处理大文件时容易造成系统的震荡,今后将针对该问题进行重点研究.
| [1] | Wang Z, Luo T. Intelligent video content routing in a direct access network[C]//Symposium on Web Society. 2011:147-152. http://cn.bing.com/academic/profile?id=2079926929&encoded=0&v=paper_preview&mkt=zh-cn |
| [2] | Hou J, Luo T, Wang Z, et al. An intelligent media delivery prototype system with low response time[C]//Advances in Swarm and Computational Intelligence. Springer International Publishing, 2015:253-264. |
| [3] | Bloom B H. Space/time trade-offs in hash coding with allowable errors[J]. Communications of the ACM , 2010, 13 (7) :422–426. |
| [4] | Qiao Y, Li T, Chen S. Fast bloom filters and their generalization[J]. IEEE Transactions on Parallel & Distributed Systems , 2014, 25 (1) :93–103. |
| [5] | Karger D, Lehman E, Leighton T, et al. Consistent hashing and random trees:distributed caching protocols for relieving hot spots on the World Wide Web[C]//Proceedings of the Twenty-Ninth Annual ACM Symposium on the Theory of Computing. 1997:654-663. http://cn.bing.com/academic/profile?id=2020765652&encoded=0&v=paper_preview&mkt=zh-cn |
| [6] | Zhao N, Wan J, Wang J, et al. GreenCHT:a power-proportional replication scheme for consistent hashing based key value storage systems[C]//Mass Storage Systems and Technologies (MSST), 201531st Symposium on. 2015:1-6. |
| [7] | Maccormick J, Murphy N, Ramasubramanian V, et al. Kinesis:a new approach to replica placement in distributed storage systems[J]. ACM Transactions on Storage (TOS) , 2009, 4 (4) :1–28. |
| [8] | Weil S A, Brandt S A, Miller E L, et al. CRUSH:controlled, scalable, decentralized placement of replicated data[C]//SC 2006 Conference, Proceedings of the ACM/IEEE. IEEE, 2006:31-43. |
| [9] | Sun B J, Wu K J. Research on cloud computing application in the peer-to-peer based video-on-demand systems[C]//Intelligent Systems and Applications (ISA), 20113rd International Workshop on. IEEE, 2011:1-4. |
| [10] | 王君君.网络文件的分布式存储设计与实现[D].济南:山东大学, 2015. |
| [11] | Decandia G, Hastorun D, Jampani M, et al. Dynamo:amazon's highly available key-value store[J]. ACM Sigops Operating Systems Review , 2007, 41 (6) :205–220. DOI:10.1145/1323293 |
| [12] | Wang Z, Luo C, Luo T, et al. A bloom filter-based index for distributed storage systems[C]//Distributed Computing and Artificial Intelligence, 12th International Conference. Springer International Publishing, 2015:293-301. |