 2016, Vol. 33
2016, Vol. 33 



2. 中国科学院大学, 北京 100049
2. University of Chinese Academy of Sciences, Beijing 100049, China
近年来,将地理信息系统作为工具进行聚落考古的研究成果日益增多[1-4].聚落考古涉及的空间遗址数据繁多,处理起来费时费力,而空间数据挖掘技术可以从数目庞大的空间数据中挖掘出其内在的模式和隐含的规律[5-6].利用空间数据挖掘技术处理考古遗址数据,探寻聚落形态、分布和内部结构及聚落的历史演变规律,对于更好地指导考古研究和理解古人类活动具有重要意义[7].自有聚落以来,择群而居就是一种普遍的历史现象,聚落的组织形态随着文化更替也在不断发生变化[8].对于空间分布不均、种类与数目繁多的遗址空间与属性数据,采用聚类分析的方法进行聚落考古研究已经成为一种新的趋势.如毕硕本等[9-10]先后使用k-means和DBSCAN算法对郑洛地区进行聚类分析研究;张开广等[11]用PATHCLUST算法对郑州地区进行聚类,闫丽洁等[12]将地形和水系加入k-medoids算法中对环嵩山地区进行聚类研究.但这些研究中均未考虑遗址间关系对聚落划分的影响,缺乏对划分后聚落内部结构的研究.考古学家认为聚落内遗址间存在功能和规模的差异[13],遗址间作用关系体现在大型遗址对周围小型遗址控制力和吸引力[14].本文以聚落中重要遗址为研究切入点,利用决策树分类方法与改进的k-means方法,把遗址间的作用关系和区域地形考虑到分析中,对辽宁西部地区遗址进行聚类分析,并探究聚落的空间分布、内部结构和演变规律.
1 研究区域和数据源 1.1 研究区域辽宁西部地区地理坐标为北纬40°~42°33′,东经118°41′~122°24′,处于蒙古高原向沿海平原过渡的低山丘陵区,区内群山起伏,沟壑纵横,有松岭山、大青山等千余座山头,有大凌河、小凌河、老哈河等河流.该地区属于半干旱半湿润季风型大陆气候.著名的牛河梁遗址就位于此区域内,此前发掘出土了大型玉凤等文物,在中华文明起源上具有重要意义[15].
目前,辽宁西部地区已发现人类文化遗址几千处,先秦时期整体上秉承小河西文化—兴隆洼文化—赵宝沟文化—红山文化—小河沿文化—夏家店下层文化—夏家店上层文化—战国文化这一文化演化序列.相关研究表明受5~4.4kaB.P.寒冷事件的影响,小河西—赵宝沟文化时期,生活环境遭到严重破坏,遗址数目极少,暂未列入研究范围[16].
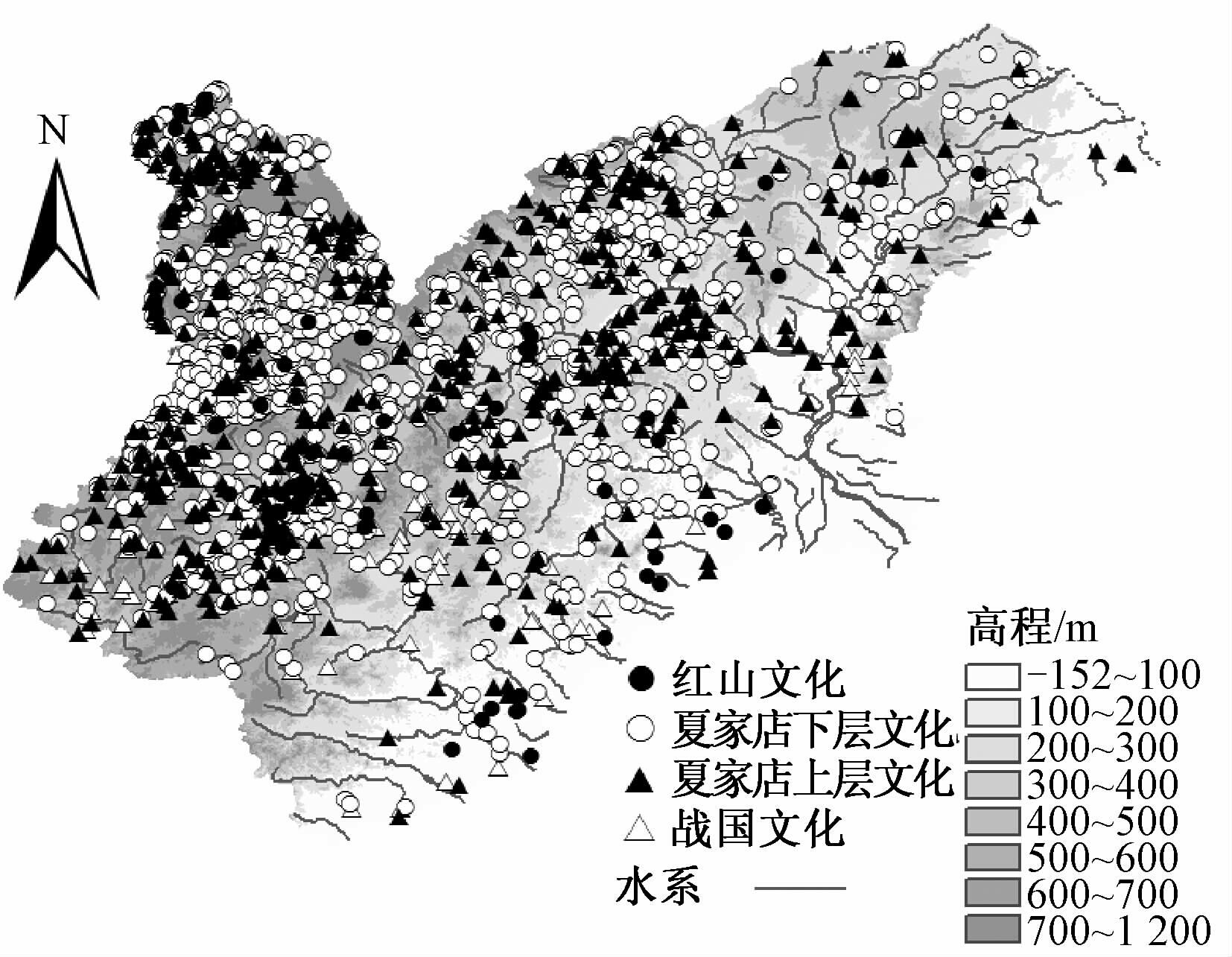
1.2 数据源研究中使用的遗址数据来源于《中国文物地图集·辽宁分册》中各文化时期的1∶220万的各县市文物图.共收集研究区域内4市15县文物地图 26幅,从中采集研究时期遗址点1923处.地理空间数据包括中国科学院计算机网络信息中心地理空间数据云(http://www.gscloud.cn)提供的ASTER GDEM 30m分辨率DEM数据、西辽河流域1∶100万地貌数据和水系数据.所有数据统一采用WGS84坐标系,原始数据分布和统计见图 1和表 1[17].

|
Download:
|
| 图 1 辽宁西部遗址分布 Fig. 1 Distribution of archaeological sites in the western part of Liaoning | |
{kind=link}
|
|
表 1 各期文化遗址数量 Table 1 Numbers of archaeological sites |
决策树分类算法是空间数据挖掘的基础方法,适合处理数目繁多的遗址数据[18-19].本文首先利用决策树算法分类评定未知规模遗址.严文明[20]认为遗址的重要性不能仅以面积作为唯一评估指标,王巍[13]则认为不同等级聚落出土遗存种类和数量大不相同.因此本文将遗址面积和遗存种类作为特征构建决策树,输入特征变量集包括遗址的名称、遗址面积和遗存种类.遗址样本选择《中国文物地图集·辽宁分册》中记载的一些已知规模的遗址.对每个文化时期的遗址选择训练样本分别进行分类,未用于构建决策树的已知规模遗址用于对决策树分类精确度进行评估.本文采用的评估指标是F值(分类结果的准确率和召回率的调和平均值).当F值大于70%时,表明决策树分类精度达到分类要求,此时构建成的决策树的面积和遗存种类的值作为分类的阈值,不同文化时期该值不同,决策树分类步骤流程图如图 2所示.

|
Download:
|
| 图 2 决策树分类步骤 Fig. 2 Flow chart of the decision tree classification | |
{kind=link}
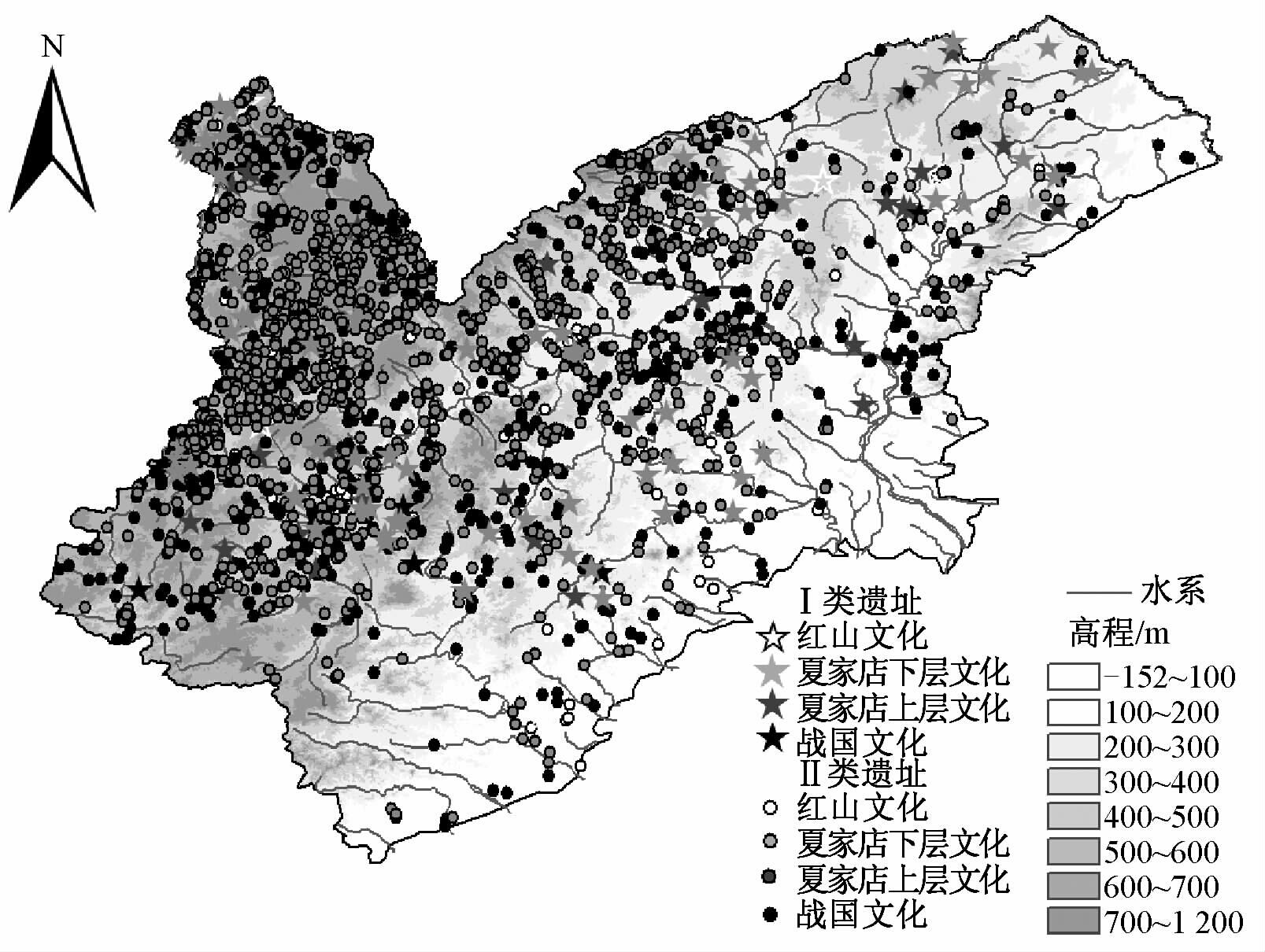
将F>70%作为构建决策树合格的条件,保证各文化时期的准确率都维持在较高的水平.同时召回率最低的文化时期也达到67%,分类结果可信度较高,见图 3和表 2.从高等级遗址占总遗址比例来看,随着文化时期的更替,高等级遗址的比例明显下降,决策树分类的结果不但划分了遗址等级,也反映了不同文化时期各等级遗址的存在数量和比例关系.

|
Download:
|
| 图 3 辽宁西部地区遗址等级分类 Fig. 3 Level map of archaeological sites in the western part of Liaoning | |
{kind=link}
|
|
表 2 遗址分类结果 Table 2 Classification of archaeological sites |
针对目前考古聚类研究中存在的问题,本文将遗址间相互作用关系和区域的地形环境等加入到聚类分析中[21-22],参考相关聚类方法[23],对k-means方法改进,改进算法聚类的结果更符合考古研究中聚落的划分要求[24-25],对聚落的划分更科学.
3.1 算法流程改进k-means空间聚类算法思路:
1) 首先按照遗址的等级赋予遗址相应权重z,表征遗址的重要程度,选取k个高等级遗址的位置作为聚落中心的初始位置.
2) 计算聚类质心位置时,由于高等级遗址权重较大,与k-means算法相比得到的新聚类中心会向级别高的遗址坐标位置发生偏移,符合聚类中高等级遗址位于中心位置的情况.
3) 考虑到实际地形存在起伏,使用路径距离代替欧氏平面距离更合理.在计算遗址点到聚类中心的距离时,利用遗址等级权重值,使得对遗址的“引力”作用更强的高等级遗址存在比例高的聚落计算得到的距离值小,因此待划分遗址在相同条件下会被划分进高等级遗址存在比例高的聚落.
4) 考虑到主干河流对古聚落的隔断作用,对经过主河道的路径设置阻碍,增大路径可达成本.
改进后算法流程如下:
1) 输入记录遗址地理位置和遗址规模的数据,指定待划分聚落的数目k,在输入的遗址数据中选取k个高等级的遗址作为初始聚类中心.
2) 根据相似度准则将待聚类的遗址分配到最近的聚类,完成一次聚类.相似度准则是根据聚落的中心与遗址点的距离进行判定划分的,遗址路径距离聚落中心越小则遗址划分到该聚落的可能性就越大.在计算中加入了聚落中遗址等级权重,这样划分更加合理.相似性准则的计算公式如下:其中n为当前遗址聚落中的遗址个数,path_distance为遗址到待计算聚落中心的路径距离,A为当前遗址聚落的集合,z为权重值,λ为权重调节数.
| $d=path\_distance\times n/\sum\limits_{\partial \in {{A}_{中}}}{(\lambda +z)},$ | (1) |
3)更新聚落的聚类中心,将聚落中按权重计算的遗址平均位置作为聚落的中心.聚类新中心的x、y坐标的计算公式为:
| $\overline{{{x}_{中}}}=\sum\limits_{x\in {{C}_{i}}}{x\times z/\sum\limits_{x\in {{C}_{i}}}{z}},$ | (2) |
| $\overline{{{y}_{中}}}=\sum\limits_{y\in {{C}_{i}}}{y\times z/\sum\limits_{x\in {{C}_{i}}}{z}}.$ | (3) |
4) 反复执行第2)步和第3)步直至满足终止条件,终止条件为连续2次计算得到聚类中心不变.
3.2 量化策略遗址聚类分析的基础数据库构成如表 3所示.本文在进行聚类分析时,遗址点的坐标数据来源于文物地图集中记载的遗址位置信息;遗址点权重值来源于决策树分类的结果,决策树分类的I级遗址权重设为2,II级遗址权重设为1;path_distance是利用DEM数据计算得到的2点间的路径距离.
|
|
表 3 辽宁西部地区遗址聚落划分基础数据库结构 Table 3 Basic database structure of settlement group division for archaeological sites in the western part of Liaoning |
通过修改河流在DEM上像元灰度值来实现河流距离增大,具体步骤:一级河道在DEM影像的灰度值设为区域DEM最大值像元灰度值×1.5,二级河道像元值直接设为最大灰度值,河流的支流由于对交通影响不大,还可以为古人提供水资源,不必设定阻碍.将各聚落中的高等级遗址的位置坐标统计求取平均值,得到聚落高等级遗址的控制中心位置坐标.确定聚落中心控制半径的方法是计算聚落内一般遗址与该中心位置的距离求取平均值,确定圆心和半径可以绘制出表征各聚落控制范围的圆形,圆形区域可以反映出高级别遗址对聚落内遗址的控制范围情况.
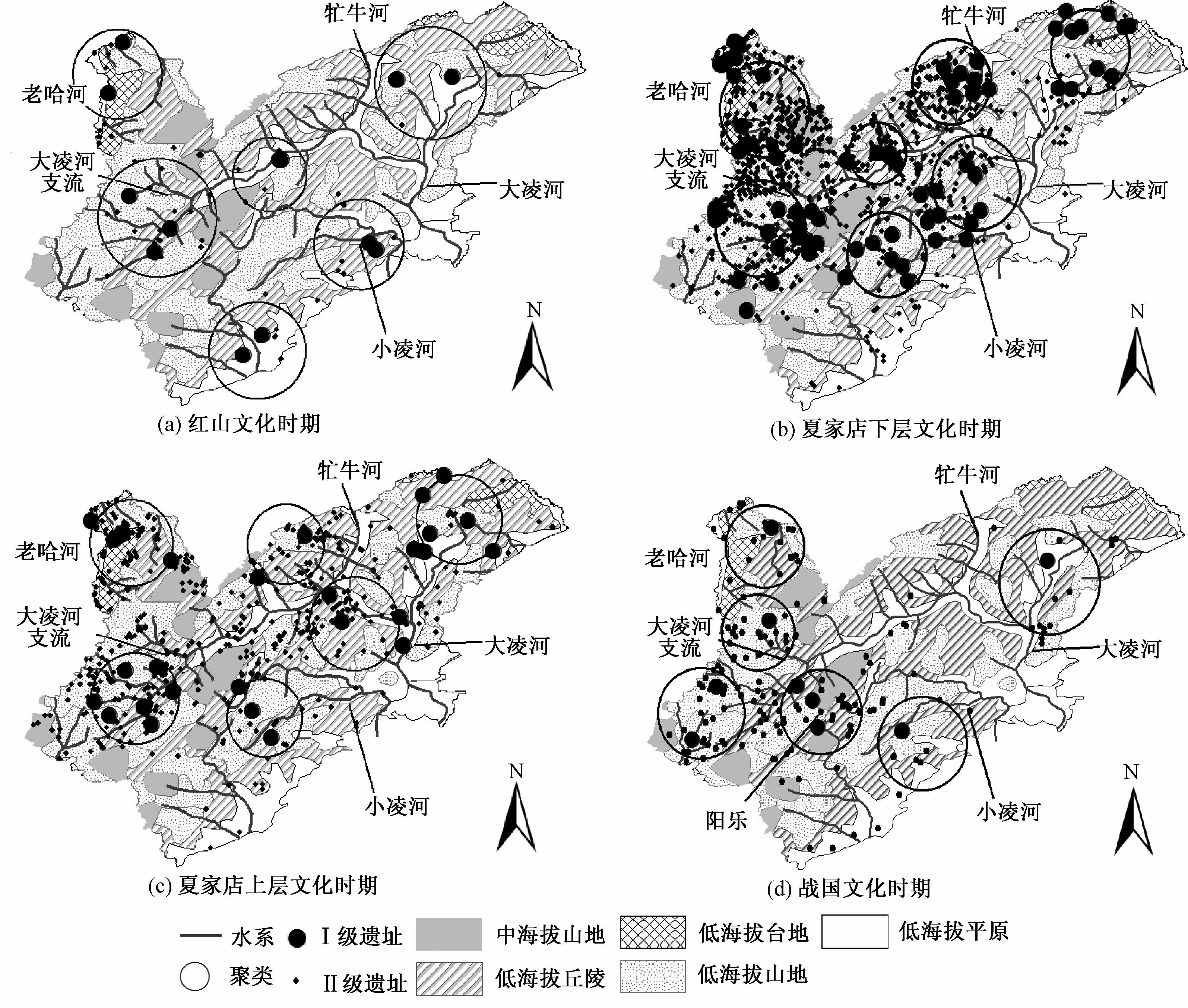
3.3 聚类结果和相关分析由于聚落分布受区域各种环境影响,对区域内相关环境因子进行全面分析,并统计区域内遗址在坡度、高程、距水系距离和地貌上的分布情况,便于研究区域内聚落的分布,对应分析区域聚落划分的结果(图 4)和发现聚落随时间的变化趋势,整理成表 4如下.

|
Download:
|
| 图 4 辽宁西部地区聚落划分结果 Fig. 4 Results of the settlement group division in the western part of Liaoning | |
{kind=link}
|
|
表 4 辽宁西部地区遗址环境分布 Table 4 Geographic location and environment distributions of archaeological sites in the western part of Liaoning % |
红山文化时期聚落群空间分布上较为分散,聚落分布与河流分布基本吻合.同其他文化时期相比,聚落更多地分布在海拔高度较低且坡度较缓的平原地区.从空间上来看,红山文化时期聚落间相对孤立,各聚落内部高等级遗址占比远高于其余各文化时期.在早期文化中,聚落规模相对较小的情况下,重要遗址在聚落中的作用更为突出.
由于4.4~2.27kaB.P.时期气候极适宜于人类居住,夏家店下层文化遗址数目远多于其他文化时期,甚至超过现代居民点的密度[16].聚落内部的遗址分布非常集中,存在明显的群居现象.在分布上表现出“西密东疏”的现象,西北部区域多为海拔400m以上的高地,不仅免于受到洪水侵袭,且便于获得食物.西北部的高地区域,虽然面积不及研究区总面积的1/5,却容纳了超过1/3的遗址.夏家店下层文化时期聚落明显地向海拔和坡度相对较高的山地地带过渡.牤牛河流域开始出现聚落,可能是迁徙过来的人口在此开辟新居住区域.研究区域南部的聚落向水系分布更密集和海拔高的大凌河支流区域移动,其余聚落分布大致与红山文化时期一致.在聚落内部构成上,各聚落高等级遗址的数目和比例均存在显著差异,小规模聚落中高等级遗址在数目和比例上较高,因而在聚落中发挥的作用更大,但单个遗址控制影响力不高;反之,大规模聚落中重要遗址对周边其他遗址的吸附能力更强,控制作用明显.
夏家店上层文化的聚落内部遗址密度适中,空间格局清晰,可以明显看出水系对聚落分布的影响.主干的河道从地理上隔断了遗址间的联系,使得它们组成了不同的聚落.区域西北部高地位置夏家店下层文化时期高密度的聚落移动到低海拔的平原和丘陵地区.遗址分布又逐渐从高地区域向平原地带移动,与2.7kaB.P.的寒冷事件吻合,同时与该时期生产方式改变为以畜牧业为主表现出相关性.牤牛河流域2个聚落演变为一个聚落,聚落中高等级遗址走向了消亡,小型遗址所占比例较高.聚落的内部结构上看,高等级遗址大都位于聚落中心,遗址呈主从式环状分布.除东北方向的聚落高等级遗址比例较高,其他聚落均处于2.7%~6.8%区间,聚落间遗址比例表现出趋于稳定的趋势.
战国文化时期研究区域的聚落明显密集分布在西部腹地区域.聚落集中于大凌河支流西部的区域,该位置与战国时期研究区域辽西的郡首阳乐[26]十分相近(位置标于图 4),该位置与整个区域的遗址质心位置上也非常接近.在聚落内部构成上,战国时期各聚落重要遗址的个数和比例更加相似,各聚落遗址比例在4%~7.6%区间分布得较为均匀,总体比例接近6%左右,相比于夏家店上层文化时期,各聚落内部构成越来越趋于一致.
在4个文化时期中,位于区域西北部的聚落一直比较稳定,没有明显的移动,聚落变化相对不大.从地形上分析该区域位于山地较多的盆地地区,交通闭塞,与外界沟通不便.聚落内部遗址一直分布比较稀疏,高级别遗址占比远高于其余几个聚落.位于大凌河支流的聚落,遗址的数目和密度一直较高,该区域水系支流众多,不靠近主干河流,也不易受到洪灾,相对适合人类居住,后来还出现了郡首阳乐.各文化时期聚落大都分布在距水系5km的区域内,各文化时期并无显著差异.从聚落内部比例上来看,聚落在发展过程中内部结构不断调整,聚落内部结构经历的是从无序到有序的一个进程,而这种有序,是以中心聚落城市为主导的引力作用,最终各等级遗址达到的“平衡比例”反映的正是最终高等级遗址对聚落中遗址的控制能力.
3.4 聚类结果的评估古聚落划分精度验证的最佳方法是通过遗址房屋的构造、埋葬方式等资料进行计算相似度.但目前研究区域内出土资料不全,仅能获得几个特殊遗址的详细资料,直接计算精确度存在困难.轮廓系数是评估k-means聚类结果的最佳指标,通过计算划分聚落的轮廓系数来确定聚类结果的准确率是一种有效的方法[27],轮廓系数计算公式如下
| ${{S}_{i}}=\frac{{{b}_{i}}-{{a}_{i}}}{max\{{{a}_{i}},{{b}_{i}}\}},$ | (4) |
其中,ai代表遗址到聚落内其余遗址的平均路径距离,bi代表遗址到所有非所属聚落遗址的平均路径距离.Si取值介于-1和1之间,若Si接近1则表示聚落内平均路径距离ai远小于最小的簇间平均路径距离bi; 反之,Si接近于-1,表示遗址划分的聚落的准确度较低.聚类的轮廓系数是内部遗址轮廓系数的加权平均值,对划分的聚落个数k,分别求取轮廓系数,最优k值对应的轮廓系数值可评估聚类的准确率.
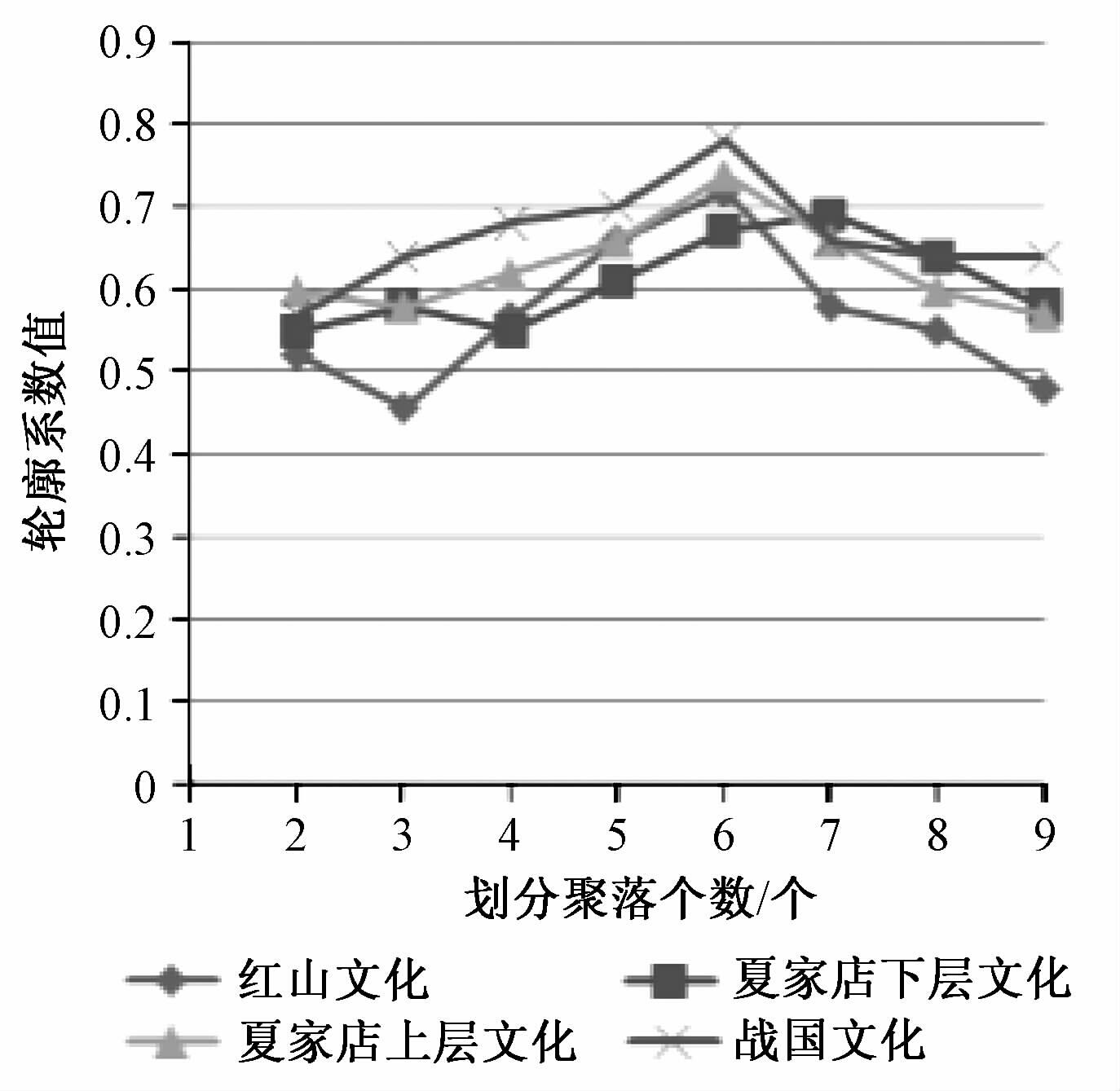
对4个文化时期,轮廓系数的计算结果见图 5.

|
Download:
|
| 图 5 聚落轮廓指数计算结果 Fig. 5 Calculated silhouette coefficients of settlement groups | |
{kind=link}
从各时期轮廓系数的计算结果来看红山文化时期、夏家店下层文化时期、夏家店上层文化时期、战国文化时期在聚类个数分别选取6、7、6、6时最大轮廓系数值分别为0.72、0.69、0.74、0.78,除夏家店下层文化接近0.7,其余各文化时期的轮廓系数均大于0.7,聚类的轮廓系数值均处于分类精确度较好的区间,聚类时选择相应的k类进行划分可以得到准确率较高的聚类结果.
4 结论本文采用决策树分类和改进的聚类分析方法,对辽宁西部区域的聚落遗址进行研究.区域聚落从低海拔地区到高海拔地区最后又迁徙到低海拔的区域,除地理环境因素外,气候事件与生产方式的变化可能对聚落的分布形式有较大影响;大凌河支流地区最适合人类居住,该区域与史料中记载的辽西郡首阳乐位置相近.随着文化更替,高等级遗址比例越来越小,聚落内部各等级遗址比例向一个稳定的值靠近,该值反映的是聚落发展至稳定状态下,各等级遗址的比例构成.这些规律能够为考古学家提供一定的参考依据.
本文用路径距离代替欧式距离,并考虑河流对可达性的影响,研究方法中还体现了高级遗址对周围遗址的影响作用,划分的聚落更加符合考古学的需求.该方法需要较多的遗址及其特征数据进行训练,可进一步用于更大区域范围的遗址聚落研究.由于现存遗址出土资料不足,无法进一步通过精确计算聚落划分的正确性来针对性地继续改进算法是该算法最大的不足之处.
| [1] | Fletcher R. Some spatial analyses of Chalcolithic settlement in Southern Israel[J]. Journal of Archaeological Science , 2008, 35 (7) :2048–2058. DOI:10.1016/j.jas.2008.01.009 |
| [2] | Mccoy M D, Ladefoged T N. New developments in the use of spatial technology in archaeology[J]. Journal of Archaeological Research , 2009, 17 (3) :263–295. DOI:10.1007/s10814-009-9030-1 |
| [3] | 郭媛媛, 莫多闻, 毛龙江, 等. 山东北部地区聚落遗址时空分布与环境演变的关系[J]. 地理学报 , 2013, 68 (4) :559–570. |
| [4] | 李中轩, 朱诚, 吴国玺, 等. 河南省史前人类遗址的时空分布及其驱动因子[J]. 地理学报 , 2013, 68 (11) :1527–1537. |
| [5] | 王树良, 丁刚毅, 钟鸣. 大数据下的空间数据挖掘思考[J]. 中国电子科学研究院学报 , 2013, 24 (1) :8–17. |
| [6] | Song J L, Luo T J, Chen S, et al. A clustering based method to solve duplicate tasks problem[J]. Journal of the Graduate School of the Chinese Academy of Sciences , 2009, 26 (1) :107–113. |
| [7] | Sayerd, Wienhold M. A GIS-investigation of four early Anglo-Saxon Cemeteries: Ripley's K-function analysis of spatial groupings amongst graves[J]. Social Science Computer Review , 2013, 31 (1) :71–89. DOI:10.1177/0894439312453276 |
| [8] | 裴安平. 史前聚落的群聚形态研究[J]. 考古 , 2007 (8) :45–58. |
| [9] | 毕硕本, 闾国年, 陈济民. 郑州—洛阳地区史前连续文化聚落的K-means聚类挖掘研究[J]. 地理与地理信息科学 , 2007, 23 (5) :48–51. |
| [10] | 毕硕本, 计晗, 杨鸿儒. 基于DBSCAN算法的郑洛地区史前聚落遗址聚类分析[J]. 科学技术与工程 , 2014, 14 (32) :266–270. |
| [11] | 张开广, 亢金轩, 孟红玲, 等. PATHCLUST在聚落遗址空间模式研究中的应用[J]. 测绘科学 , 2013, 38 (4) :160–169. |
| [12] | 闫丽洁, 石忆邵, 杨瑞霞, 等. 环嵩山地区史前聚落群划分研究[J]. 地域研究与开发 , 2015, 34 (1) :172–176. |
| [13] | 王巍. 聚落形态研究与中华文明探源[J]. 文物 , 2006 (5) :58–66. |
| [14] | 马新. 原始聚落与公共权力的生成[J]. 山东大学学报:哲学社会科学版 , 2008 (3) :91–99. |
| [15] | 郭大顺. 龙凤呈祥:从红山文化龙凤玉雕看辽河流域在中国文化起源史上的地位[J]. 文化学刊 , 2006, 1 (1) :15–24. |
| [16] | 李永化, 尹怀宁, 张小咏, 等. 5000a BP以来辽西地区环境灾害事件与人地关系演变[J]. 冰川冻土 , 2003, 25 (1) :19–26. |
| [17] | 王惠德. 西辽河流域早期青铜文明[M]. 呼和浩特: 内蒙古人民出版社, 2007 . |
| [18] | 王会青, 陈俊杰, 侯晓晶, 等. 决策树分类的属性选择方法的研究[J]. 太原理工大学学报 , 2011, 42 (4) :346–349. |
| [19] | 张琳, 陈燕, 李桃迎, 等. 决策树分类算法研究[J]. 计算机工程 , 2011, 37 (13) :66–68. |
| [20] | 严文明. 聚落考古与史前社会研究[J]. 文物 , 1997 (6) :27–36. |
| [21] | 武优西, 侯丹丹, 李建满, 等. 属性权重聚类算法的研究[J]. 小型微型计算机系统 , 2012, 33 (3) :651–654. |
| [22] | He Z, Xu X, Deng S. Attribute value weighting in k-modes clustering[J]. Expert Systems with Applications , 2011, 38 (12) :15365–15369. DOI:10.1016/j.eswa.2011.06.027 |
| [23] | 夏鲁宁, 荆继武. SA-DBSCAN:一种自适应基于密度聚类算法[J]. 中国科学院研究生院学报 , 2009, 26 (4) :530–538. |
| [24] | Chen X, Xu X, Huang J Z, et al. TW-k-means: automated two-level variable weighting clustering algorithm for multiview data[J]. IEEE Transactions on Knowledge and Data Engineering , 2013, 25 (4) :932–944. DOI:10.1109/TKDE.2011.262 |
| [25] | Ji B, Ye Y-D, Xiao Y. Mutual information evaluation: a way to predict the performance of feature weighting on clustering[J]. Intelligent Data Analysis , 2013, 17 (6) :1001–1002. |
| [26] | 王钟翰, 陈连开. 战国秦汉辽东辽西郡县考略[J]. 社会科学辑刊 , 1979 (4) :81–95. |
| [27] | 朱连江, 马炳先, 赵学泉. 基于轮廓系数的聚类有效性分析[J]. 计算机应用 , 2010, 30 (S2) :139–141. |