 2016, Vol. 33
2016, Vol. 33 



目标跟踪[1-3]是计算机视觉领域非常重要的研究课题,在人机交互、智能交通、视觉导航、视频监控等领域得到了广泛应用.但是由于跟踪视频中存在遮挡、光照变化、尺度变化、突变、角度变化等因素,使得设计一个鲁棒的目标跟踪算法仍然是一项具有挑战性的课题.
近年来,稀疏表示在人脸识别、视频跟踪等领域得到了成功应用.Wright等[4]将稀疏表示应用到人脸识别上,利用编码系数的稀疏性进行分类.在粒子滤波的框架下,Mei和Ling[5]提出基于稀疏表示的目标跟踪算法,即1算法.该算法假定每个候选样本可由目标模板和琐碎模板近似线性表示,用LASSO算法求解表示系数,且表示系数是稀疏的,但该算法存在计算量大、难以满足快速跟踪的要求,同时跟踪目标只能使用16×16像素,不用充分利用图像的特征信息.为解决1算法跟踪速度慢的问题,Bao等[6]提出加速近似梯度APG(accelerated proximal gradient)算法.为解决跟踪目标外观的剧烈变化,Zhong等[7]提出利用全局模板和局部模板的表示方法.Jia等[8]提出将目标上的局部图像块进行稀疏编码来解决遮挡问题.Wang等[9]提出基于稀疏原型的目标算法,在部分视频上取得了较好的效果.以上算法均假设重构误差服从高斯分布,但是当目标出现遮挡时,不能很好地对跟踪目标进行建模,从而出现偏移.
为解决目标跟踪过程中视频存在的遮挡、光照变化、尺度变化等影响跟踪性能的问题,本文提出基于协同表示的目标算法.在粒子滤波的框架下,采用l1范数测量表示可信度,即假定出现遮挡时重构误差服从拉普拉斯分布,同时用协同表示对编码系数进行约束,多个测试视频跟踪结果表明本文算法具有较好的鲁棒性.
1 l1算法稀疏表示在计算机视觉、模式识别和机器学习等领域得到了广泛应用,Mei和Ling[5]首先将稀疏表示应用到目标跟踪领域,提出基于1范数的目标跟踪算法.该算法将目标或候选图像块y用下式表示:
| $y=T{{c}_{t}}+e=\left[ T\text{ }I \right]\left[ \begin{align} & {{c}_{t}} \\ & e \\ \end{align} \right]=Dc$ | (1) |
式中,T∈Rd×n表示目标模板矩阵,T中每一列是跟踪图像块的灰度值.d表示每一图像块中像素的数目,n为目标模板矩阵的特征值维数,即模板的个数.单位矩阵I∈d×d为琐碎模板,用来表征跟踪目标中存在的误差项,即遮挡、光照变化等因素.e为误差项,可以看成是琐碎模板的表示系数.如果候选图像块y能够被目标模板矩阵和琐碎模板准确地线性表示,则c为对应的表示系数.为求解表示系数c,式(1)可以通过求解1约束的最小方差问题,即
| $c*=\underset{c}{\mathop{arg}}\,min(\|yDc{{\|}^{2}}_{2}+\beta \|c{{\|}_{1}}),$ | (2) |
式中,β为常数项,用来约束表示系数c的稀疏性.‖·‖1和‖·‖2分别表示1范数和2范数.
1算法虽然首次将稀疏表示运用到目标跟踪领域,但该算法存在计算量大等缺点,严重影响目标的跟踪性能.为平衡跟踪速度与跟踪性能,1算法通常采用16×16的图像块.但低分辨率的图像块不能充分利用视频目标的视觉信息,影响跟踪的准确性.同时1算法中的表示系数c是稀疏的,Zhang等[10]证明稀疏系数c对提高分辨率起到关键作用,但是可以用2范数代替1范数,分辨性能不下降,同时大大提高运算速度.
2 本文算法为解决1算法存在计算量大,不能充分利用图像信息等缺点,本文用1范数来建模重构误差,用2范数即协同表示对编码系数进行约束,因此编码系数可通过下式得到:
| $\hat{c}=\underset{c}{\mathop{arg}}\,min(\|y-Dc{{\|}_{1}}+\beta \|c{{\|}_{2}}).$ | (3) |
令e=y-Dc,上式可重写为
| $\hat{c}=\mathop{\arg \min }_{c}\left\{ \|y-Dc{{\|}_{1}}+\lambda \|c{{\|}_{2}} \right\}.$ | (4) |
上式是个约束凸优化问题,可通过增广拉格朗日乘子算法ALM(augmented lagrange multiplier)求解.对应的增广拉格朗日函数为
| ${{J}_{\mu }}\left( e,c,z \right)=\|e{{\|}_{1}}+\lambda \|c{{\|}^{2}}_{2}+\langle z,y-Dc-e\rangle +\frac{\mu }{2}\|y-Dc-e{{\|}^{2}}_{2},$ | (5) |
μ为常数,z为拉格朗日乘法向量,c,e可以通过分别固定c和e求得,即
| $\left\{ \begin{align} & {{c}_{k+1}}=argmi{{n}_{c}}{{J}_{{{\mu }_{k}}}}(c,{{e}_{k}},{{z}_{k}}) \\ & {{e}_{k+1}}=argmi{{n}_{e}}{{J}_{{{\mu }_{k}}}}(c,{{e}_{k}},{{z}_{k}}) \\ \end{align} \right.$ | (6) |
通过上式可得c和e的闭合解,
| $\left\{ \begin{align} & {{c}_{k+1}}=({{D}^{T}}D+2\lambda /{{\mu }_{k}}I){{}^{-1}}{{D}^{T}}\left( y-{{e}_{k}}+{{z}_{k}}/{{\mu }_{k}} \right) \\ & {{e}_{k+1}}={{S}_{1/{{\mu }_{k}}}}\left[ y-D{{c}_{k+1}}+{{z}_{k}}/{{\mu }_{k}} \right] \\ \end{align} \right..$ | (7) |
令Pk=(DTD+2λ/μkI)-1DT为投影矩阵,当新的视频流来临时,可以直接计算Pky,加快计算速度.
算法流程:
输入:观测向量y,目标模板矩阵D,正则化常数λ.
1) 初始化系数项c0,噪声e0,循环变量k=0;
2) 开始迭代:
3)计算ck+1:
| $~{{c}_{k+1}}=({{D}^{T}}D+2\lambda /{{\mu }_{k}}I){{}^{-1}}{{D}^{T}}y-{{e}_{k}}+{{z}_{k}}/{{\mu }_{k}};$ |
4) 计算ek+1:ek+1=S1/μk[y-Dck+1+zk/μk];
5) 计算zk+1:zk+1=zk+μk(y-Dck+1-ek+1);
6) 循环变量更新:k←k+1;
7) 当满足迭代终止条件时,跳出循环,否则重新开始第3)步.
输出:
本文提出的目标跟踪算法可以看成是基于贝叶斯推论的隐式马尔科夫模型.假设从第1帧到第t帧的跟踪目标图像集Y1:t={y1,…,yt},则跟踪目标的最优状态yt可由贝叶斯理论得到,
| $\begin{align} & p\left( {{x}_{t}}{{Y}_{1:t}} \right)\propto p\left( {{y}_{t}}{{x}_{t}} \right)\int p\left( {{x}_{t}}{{x}_{t1}} \right) \\ & p({{x}_{t1}}{{Y}_{1:t1}})d{{x}_{t1}}, \\ \end{align}$ | (8) |
式中,(xt|xt-1)表示2个连续状态的动态运动模型,(yt|xt)表示在状态xt下观测向量yt的似然估计.则第t帧跟踪目标的最优状态估计可通过对在时刻t对N个样本的最大后验估计得到,
用仿射变换来建模连续2帧的运动模型,即用6个仿射参数来描述跟踪目标的动态模型(xt|xt-1).设ot={xt,yt,θt,st,αt,φt},这里xt,yt,θt,st,αt,φt分别代表x,y坐标位置、旋转角度、尺度变换和斜拉程度等.不同帧之间的变换服从高斯分布,即(xt|xt-1)=N(xt;xt-1,ψ),ψ代表协方差矩阵,是对角矩阵,其对角元素分别为σ2x,σ2y,σ2θ,σ2s,σ2α,σ2φ,代表仿射参数的方差的大小.利用仿射变换可以很好地表征跟踪目标出现的位置变化、尺度变化、目标旋转等现象.
3.2 观测模型传统的跟踪方法中,观测模型采用p(y|x)=exp(-‖y-Dc‖22).该模型没有考虑跟踪目标出现遮挡或异常噪声的情况,所以当跟踪目标被遮挡时,容易出现跟丢现象.为解决这个问题,本文采用文献[9]中的算法,观测模型采用
| $~p\left( yx \right)=exp[-(\|w\Theta \left( yDc \right){{\|}^{2}}_{2})+\beta \sum \left( 1w \right)]$ | (9) |
式中,w=[w1,w2,…,wd]T用来指示误差项e中的零元素,当e中第i个元素为零时,则wi为1,否则wi为0.Θ为Hadamard乘积,表示对应元素的乘积.β为常数项.
3.3 更新观测模型
跟踪过程中,由于跟踪目标会出现遮挡、光照、尺度及旋转等因素的变化,所以需要对观测模型进行更新,否则跟踪方框会出现漂移而跟丢目标物体.本文采用2个阈值thr1=0.1和thr2=0.8对观测模型进行更新.同时定义遮挡率
本文算法在Window7操作系统,MATLAB平台下进行实验仿真,在电脑配置为Pentium(R) Dua-Core CPU E5800@3.2 GHz,内存2 GB平台下运行速度为1.4 fps.为验证本文算法的优越性,选取10个具有遮挡、光照变化、尺度变化、运动模糊性、背景混乱等挑战性因素的视频进行跟踪,与7种当前比较流行的跟踪算法进行对比,包括PCA算法[11],1算法[5],PN算法[12],VTD算法[13],MIL算法[14]及Frag算法[15],IOPNMF[1]算法.
4.1 定性对比图 1(a)Occulsion1视频存在严重遮挡,虽然视频目标人物的中心位置基本没变,但是目标人物存在书本从左、右及下方位置来的遮挡.l1算法、Frag算法、PCA算法及本文算法都能准确地跟踪目标人物.Frag算法采用分块直方图表示方法,能够处理遮挡问题.l1算法采用琐碎模板,较好地处理跟踪目标出现的遮挡问题.本文方法采用协同表示对出现遮挡时的重构误差进行建模以及采用新颖的更新模板,能够准确地处理遮挡问题.

|
Download:
|
| 图 1 不同算法的跟踪结果对比 Fig. 1 Comparison of tracking results among different algorithms | |
{kind=link}
图 1(b)、图 1(c)分别为Caviar1和Caviar2视频.这2个视频中,目标人物不仅存在严重的遮挡,而且目标人物的位置不断地发生变化,同时存在尺度变化和光照变化.当目标人物周围出现相似人物遮挡时,MIL算法出现漂移,跟丢目标人物.MIL算法采用Haar-like特征表征目标物体,该特征难以区分存在相似特征的目标物体和干扰物体.虽然目标人物受到相似人物的多次遮挡,本文算法采用协同表示处理遮挡问题及仿射变换模型,能够准确地对目标人物进行跟踪,同时目标框能随目标人物的变化而变化.
图 1(d)—图 1(f)分别为Car4、Car11及DavidIndoor视频.这3个视频存在严重的光照干扰及尺度变化.Car4视频中,汽车要经过桥洞及草地,同时道路两旁存在树木,目标汽车与周围环境的对比度较低.MIL算法及Frag算法难以区分相似物体,所以出现偏移.Car11视频中,夜晚对面汽车灯光存在严重的灯光污染,其他算法都跟丢目标汽车,只有本文算法和PCA算法,比较准确地一直紧跟目标汽车.DavidIndoor视频中,David从黑暗的屋子走出,不仅存在光照变化,而且存在目标旋转及尺度变化,尽管大多数算法都成功跟踪目标人物,但只有本文算法和IOPNMF算法更加准确和鲁棒,能够适应光照变化和尺度变化.
图 1(g)、图 1(h)分别为存在严重模糊的Deer、Jumping视频.Deer视频中,小鹿视频存在快速剧烈的运动,同时周围存在其他相似小鹿的干扰,很难在连续的视频中去除运动模糊及建模.本文算法及VTD算法在整个视频序列中都进行了稳健的跟踪.在Jumping视频中,目标人物在上下快速跳绳过程中,脸部存在严重模糊.本文算法能够在整个视频序列中进行准确的跟踪,其他算法都存在跟丢现象.
图 1(i)、图 1(j)分别为DavidOutdoor及Girl视频.DavidOutdoor视频存在背景混乱、树木遮挡及人物旋转.其他算法都跟丢了目标人物,如140帧,只有本文算法和IOPNMF算法在整个视频序列都准确地进行了跟踪.Girl视频存在人物旋转、严重遮挡及尺度变化.PN算法、VTD算法及1算法在Girl旋转的时候不能准确地进行跟踪,如90帧.而本文算法在整个视频序列过程中都成功地进行了鲁棒准确地跟踪.
4.2 定量对比
我们用2种方法来定量评价跟踪算法的性能.首先采用覆盖率,即跟踪结果方框覆盖真实目标的比例.用PASCAL VOC中提出的目标检测准则,
|
|
表 1 平均覆盖率对比 Table 1 Comparison of average overlap rates |

|
Download:
|
| 图 2 不同算法的重叠率对比 Fig. 2 Comparison of overlap rates among different algorithms | |
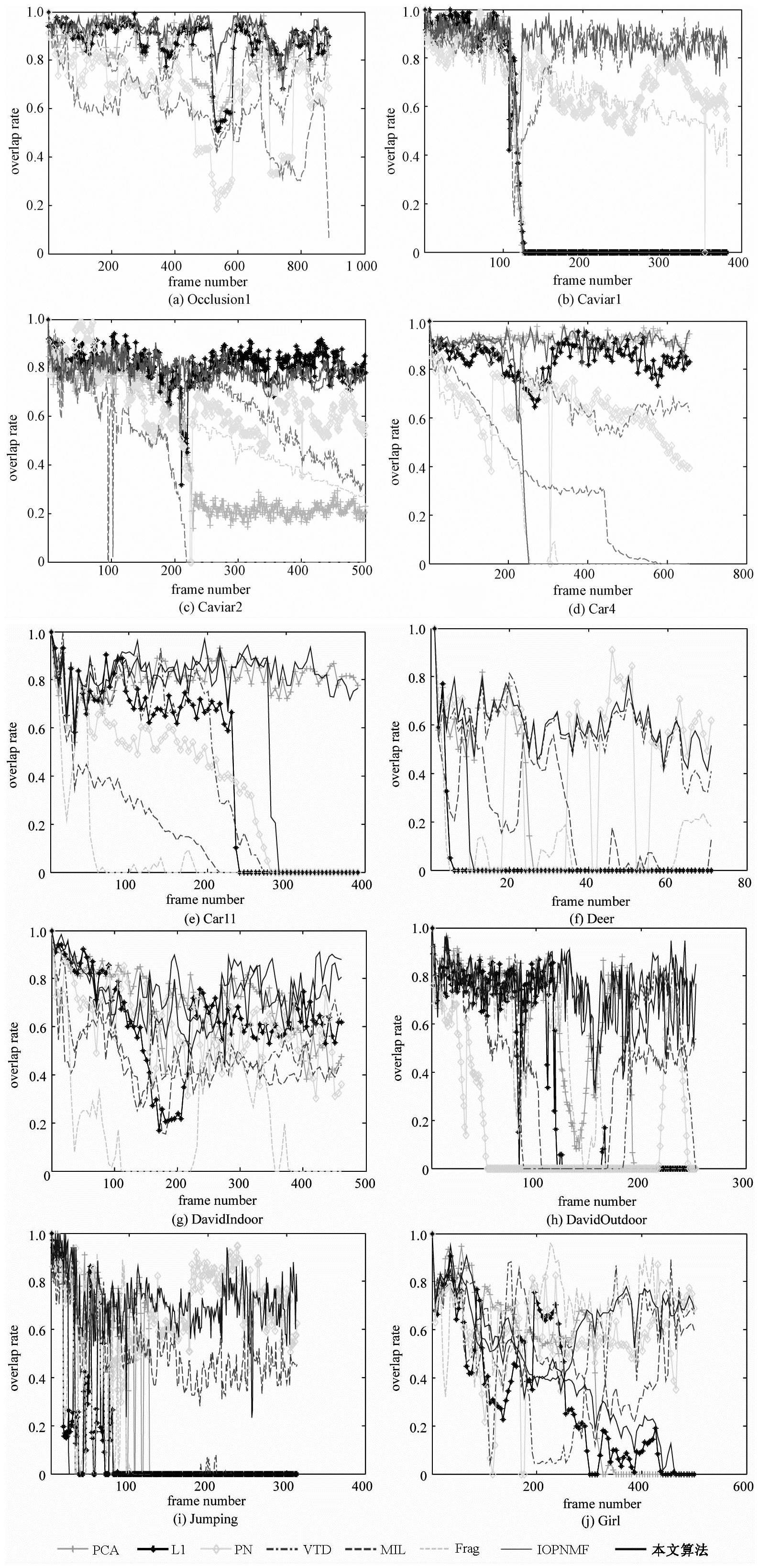{kind=link}
图 3给出不同算法在不同视频下跟踪结果的中心位置误差曲线图,横坐标为帧号,纵坐标为中心位置误差像素的个数,单位为像素.表 2为不同算法中心位置误差的平均值.图 3及表 2表明本文算法在文中所用测试视频中跟踪效果是最好的.

|
Download:
|
| 图 3 不同算法的中心点误差对比(单位:像素) Fig. 3 Comparison of center location errors among different algorithms | |
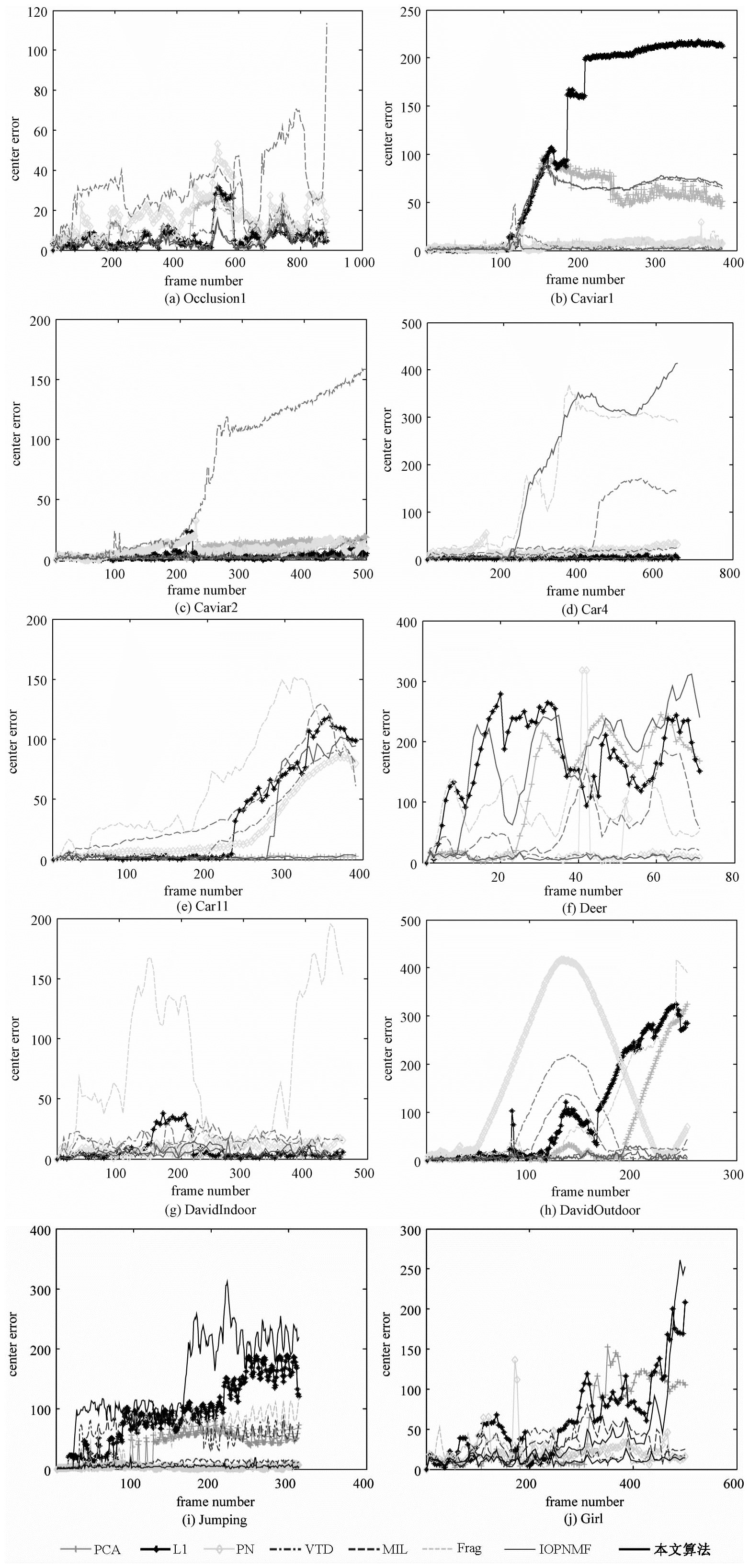{kind=link}
|
|
表 2 平均中心点误差对比(单位:像素) Table 2 Comparision of average center location errors |
本文提出一种基于协同表示的目标跟踪算法,用1范数对重构误差进行建模,用协同表示对编码系数进行约束,同时采用新颖的目标观测似然函数及更新模型.在多个测试视频的仿真结果表明,本文算法具有较高的重叠率及较低的中心位置误差,与当前比较流行的算法相比,具有较高的准确度及较强的鲁棒性.
| [1] | Wang D, Lu H C. On-line learning parts-based representation via incremental orthogonal projective non-negative matrix factorization[J]. Signal Processing , 2013, 93 :1608–1623. DOI:10.1016/j.sigpro.2012.07.015 |
| [2] | Wang D, Lu H C. Incremental orthogonal projective non-negative matrix factorization and its applications[C]// IEEE International Conference on Image Processing. Brussels, Belgium. 2011: 2117-2120. |
| [3] | Zhang K, Zhang L, Yang M. Fast compressive tracking[J]. IEEE Trans on Pattern Analysis and Machine Intelligence , 2014, 36 (10) :2002–2015. DOI:10.1109/TPAMI.2014.2315808 |
| [4] | Wright J, Yang A Y, Ganesh A. Robust representation for face recognition via sparse representation[J]. IEEE Trans Pattern and Machine Intell , 2009, 31 (2) :210–227. DOI:10.1109/TPAMI.2008.79 |
| [5] | Mei X, Ling H B. Robust visual tracking using L1 minimization[C]// IEEE international Conference on Computer Vision. Kyoto, Japan. 2009: 1436-1443. http://cn.bing.com/academic/profile?id=291172784&encoded=0&v=paper_preview&mkt=zh-cn |
| [6] | Bao C, Wu Y, Ling H, et al. Real time robust L1 tracker using accelerated proximal gradient approach[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Providenc, RI, USA. 2012:1830-1837. |
| [7] | Zhong W, Lu H C, Yang M H. Robust object tracking via sparse collaborative appearance model[J]. IEEE Transaction on Image Processing , 2014, 23 (5) :2356–2368. DOI:10.1109/TIP.2014.2313227 |
| [8] | Jia X, Lu H C, Yang M H. Visual tracking via adaptive structural local sparse appearance model[C]// International Conference on Computer Visioan and Pattern Recognition, Providenc, Ri, USA. 2012:1822-1829. |
| [9] | Wang D, Lu H C, Yang M H. Least Soft-threshold Squares Tracking[C]// International Conference on Computer Vision and Pattern Recognition. Portland, Orego, 2013:2371-2378. |
| [10] | Zhang L, Yang M, Feng X, et al. Collaborative representation based classification for face recognition[R]. arXiv: 1204.2358. http://cn.bing.com/academic/profile?id=1672851775&encoded=0&v=paper_preview&mkt=zh-cn |
| [11] | Ross D, Lim J, Lin R S, et al. Incremental learning for robust visual tracking[J]. International Journal of Computer Vision , 2008, 77 (3) :125–141. |
| [12] | Kalal J, Matas J, Mikolajczyk K. P-N learning:bootstrapping binary classifiers by structural constraints[C]//IEEE Conference on Computer Vision and Pattern Recognition. San Francisco, California, 2010:49-56. http://cn.bing.com/academic/profile?id=291172784&encoded=0&v=paper_preview&mkt=zh-cn |
| [13] | Kwon J, Lee K M. Visual tracking decomposition[C]// IEEE Conference on Computer Vision and Pattern Recognition. Francisco, California, 2010:1269-1276. http://cn.bing.com/academic/profile?id=2041574670&encoded=0&v=paper_preview&mkt=zh-cn |
| [14] | Babenko B, Yang M H, Belongle S. Visual tracking with online multiple instance learning[C]//IEEE Conference on Computer Vision and Pattern Recognition. Florida, 2009: 983-990. http://journal.ucas.ac.cn/CN/abstract/abstract12323.shtml |
| [15] | Adam A, Riviin E, Shimshoni I. Robust fragments-based tracking using the integral histogram[C]// IEEE Conference on Computer Vision and Pattern Recognition. New York. 2006: 798-805. http://journal.ucas.ac.cn/CN/abstract/abstract12323.shtml |