


放射流行病学调查用以研究电离辐射作用与人类健康的关系。它具有一般流行病学调查的特点,统计分析是其极为重要的一个环节。对于这方面的研究,目前人们最感兴趣的是电离辐射致癌效应和遗传效应。由于其发生几率很低,因此和其他罕见病研究(如通常的癌研究)具有相同的统计分析方法。
(一) 流行病学研究的任务流行病学研究的任务之一是研究暴露因素与疾病之间的关系。需要用一些参数定量地量度它们之间的统计学关联程度。常用参数有:
1.相对危险度(RR)或危险度比(γ):系指特定时期内,暴露人群组的发病率P1与非暴露人群组的发病率P0之比,即RR=P1/P0。
2.归因危险度(AR)、危险度差(δ)或过量危险度:系指特定时期内暴露人群组与非暴露人群组的发病率之差,即AR=P1-P0。
3.比数比例(OR)或相对比数(ψ):暴露人群组和非暴露人群组的发病率分别为P1和P0,相应的不发病的概率为Q1=1-P1和Q0=1-P1,则发病与不发病的概率之比P1/Q1和P0/Q0称为相应人群组的发病比数或比数;两个人群组的比数之比称为疾病的比数比例,或简称为比数比例。可以下式表示:
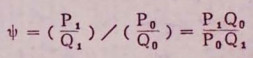
|
对于同一个人群,可以不按暴露与否分组,而按发病与否分为病例组与对照组,类似地计算两组的暴露率、非暴露率及其比值即暴露比。病例组与对照组的暴露比之比,称为暴露的比数比例。不难证明,同一个人群只有一个比数比例ψ,即暴露的比数比例等于上述疾病的比数比例。
(二) 流行病学研究方法流行病学研究暴露因素与疾病的关系时,有两种基本研究方法,其本质区别在于取样方法的不同。
为便于说明,人群及其分组取样情况可归纳成四格表形式。假定人群的分布如表 1所示,显然有
|
|
表 1 人群的分布情况 |

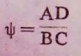
|
对于罕见病,由于发病率低,M1≃C,M0≃D,因而可以证明:
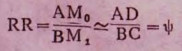
|
1.队列研究,有时称为前瞻性调查。首先根据某个可疑致病因子的暴露与否在人群中选定暴露组与非暴露组,对他们同样地追踪观察,然后比较两组的发病情况与有关参数。假定人群的取样分布如表 2所示,其中暴露组与非暴露组的取样比例f1、f2是未知参数。通过表 2中给予f1、f2的假想值,可以证明:即使f1≠f2,并不影响对发病率、RR和ψ值的估计。
|
|
表 2 队列研究的取样分布(f1=0.25,f2=0.1) |

2.病例对照研究,有时称为回顾性调查。首先根据现在是否患有所研究疾病在人群中选定病例组与对照组,然后就可疑致病因子对他们进行有无暴露史的回顾调查,比较他们受暴露的相对频数,并计算有关参数。假定人群的取样分布如表 3所示,其中病例组与对照组的取样比例f3、f4是未知参数。
|
|
表 3 病例对照研究的取样分布(f3=1.0,f4=0.003) |

根据表 3给予f3、f4的假想值可知,仅当f3=f4时发病率和RR值的估计才不受它们的影响,但这几乎是不可能的。因为对于罕见病来说,更常见的是f3→1,f4→0,使f3/f4是个很大的比值。然面,尽管f3≠f4,ψ却很少受其影响,因此可以用它来近似整个人群的RR值。这正是病例对照研究的价值所在。
(三) 发病率的两种表示方式由前述可知,根据队列研究可以直接估计发病率和相应的RR值。队列研究资料有两种,由此计算得到的发病率有着不同的表示方式。
1.发病密度,又称瞬时发生率,系指观察人群在限定期间内的新发病例数除以在这期间观察的人-时间总数,即单位观察时间内人群的发病率。
2.累计发病率,系指观察人群在限定期间内的新发病例数除以该人群在观察起点时的人口总数,即观察期间人群的平均发病比例。
需要注意的是:累计发病率是个比例,取值0~1,无量纲,因为分子与分母均以人数表示;发病密度的分母是人时单位,因此它的量纲是[时间]-1,其值随所用时间单位而异。从理论上讲,发病密度更可取,但累计发病率比较简单,易于理解与接受。两者可以用公式相联系。
(四) 混杂作用1.所谓混杂,系指外部因素的存在,使暴露因素与疾病之间的关系受到歪曲,或被夸大,或被掩盖。这些外部因素就称为混杂因素。最常见的混杂因素如年龄、性别等。表 4给出了心肌梗塞MI与新近口服避孕药(OC)之间的关系受年龄混杂的例子,对年龄调整前得到的比数比例粗值ψc=1.68,按年龄分层调整后得到的比数比例调整值ψa=3.97,且各年龄层的ψi也普遍高于ψc,说明由于年龄的混杂使得服用OC而导致发生MI的危险度受到掩盖。
|
|
表 4 MI与OC之间关联受年龄的混杂 |

2.对表 4的进一步分析表明:病例随年龄增高而显著增加,说明年龄本身是一个独立的致病因子;而服用OC的比例,无论是病例组还是对照组都随年龄增高而降低,说明年龄与暴露因素也密切相关。这就是作为外部因素的年龄能够成为混杂因素的两个必要条件。
作为混杂的结果是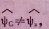
3.混杂按方向可以分为两类:①正混杂:它夸大了暴露因素与疾病之间的关系,使ψc比ψa更偏离1。②负混杂:它掩盖了暴露因素与疾病之间的关系,使ψc比ψa更接近于1。
混杂的程度可以定量表示,这就是混杂危险度比W=ψc/ψa。
4.研究混杂是为了控制混杂,以得到暴露因素与疾病之间的真实关系。控制外部因素混杂一般有以下几种方法,分别用于实验设计阶段和统计分析阶段。
(1)限制:实验设计时根据若干限制条件,严格选择符合条件的病例和对照作为研究对象。
(2)配对:强制地选择对照,使他们在若干限制条件上与病例保持一致,是一种特殊的限制。
(3)分层分析:按照混杂因子的水平分层调整,使每一层次内混杂因子的水平比较恒定,排除其影响,然后将各层结果按照某种特定的法则结合成概括性的量度作为调整后的结果。最常用的是Mantel-Haenszel分层分析法。
(4)模式化分析:是最近10多年里随着计算机技术一起发展起来的分析方法,适合于同时分析许多因素。最常用的是Logistic回归模式分析。
(五) 交互作用1.交互是在讨论两个(或两个以上)暴露因子对同一疾病的关系时遇到的一种现象。当这些因子同时存在时的联合效应和根据他们各自的单独效应所预期的结果不相同时,称之谓有交互。换言之,一个暴露因素的单独效应将随着另一暴露因素的不同水平(或存在与否)而有所改变。如果联合效应使发病危险增加,亦即一个暴露因子的单独效应随另一暴露因子的水平增高而变大,称为正交互;反之,则为负交互。流行病学研究中有时称这种交互为效应修正作用;而生物学上称类似作用为协同或拮抗,分别对应于正交互或负交互。
2.交互不同于混杂。混杂并不真的改变暴露因素与疾病之间的关联,只是由于混杂因素在暴露组与非暴露组中的分布比例不同而使这种关联不能得到正确的量度,属于偏倚范畴。研究混杂的目的是要设法控制它,消除它。而交互则是效应修正因子(相对于暴露因子而言)直接作用于暴露因子与疾病之间的关联上,使之发生事实上的变化,因此不属于偏倚范畴,也不能控制或消除。研究交互只是为了识别它。
识别交互作用的方法不外乎分层分析和模式化分析两种方法。除了识别交互以外,有时还需要进一步了解交互的性质,即利用模式分析判断两个(或两个以上)因素的联合效应与它们各自的单独效应之间的关系。最常见的关系是疾病危险的加法模式和乘法模式。
设两个因素为X、Y。所谓加法模式,系指X和Y的联合效应等于他们的单独效应之和,用归因危险度表示就是:ARx, y= ARx+ARy。所谓乘法模式,系指X和Y的联合效应等于他们的单独效应之积,用相对危险度表示就是:RRx, y=RRx·RRy。加法模式或乘法模式的偏离与否,可用作判断两因素之间有无交互作用。