 2019, Vol. 54
2019, Vol. 54



2. 西藏藏医药大学, 西藏 拉萨 850000
 ),来源为龙胆科龙胆属Gentiana秦艽组(Sect.Cruciata)多种高山植物;可分为解吉那保(具蓝紫色花的)与解吉嘎保(具白色花的)两个品种。首次以解吉那保基原植物之一——长梗秦艽Gentiana waltonii Burk.与解吉嘎保基原植物之一——粗壮秦艽Gentiana robusta King ex Hook.f.为模式植物,分别构建其根、茎、叶、花转录组数据库。对原始数据进行除杂,将质控后得到的所有高质量序列进行de novo拼接,分别得到长梗秦艽79 455条、粗壮秦艽78 466条unigene,平均长度分别为834 bp和862 bp。根据GO功能分类,可将unigene分为3大类65分支;根据KOG功能可将unigene分为25类;KEGG代谢通路分析分别发现长梗秦艽和粗壮秦艽中315条、340条unigene参与到20个次生代谢标准通路中。环烯醚萜苷类为藏药解吉及中药秦艽类、龙胆类、当药及青叶胆等药材的指标性成分及活性成分之一,分析结果显示:分别有80条、57条unigene参与编码环烯醚萜苷类合成途径中的24个关键酶,且在不同部位中的表达存在差异;还发现多个SSR和SNP、InDel位点。本工作可为藏药材基原植物遗传图谱构建,分子标记开发,功能基因掌握,有效成分累积规律、道地性形成机制、藏药材品种科学内涵的探讨,分子育种及濒危藏药高山植物就地保护等提供基础科学资料。
),来源为龙胆科龙胆属Gentiana秦艽组(Sect.Cruciata)多种高山植物;可分为解吉那保(具蓝紫色花的)与解吉嘎保(具白色花的)两个品种。首次以解吉那保基原植物之一——长梗秦艽Gentiana waltonii Burk.与解吉嘎保基原植物之一——粗壮秦艽Gentiana robusta King ex Hook.f.为模式植物,分别构建其根、茎、叶、花转录组数据库。对原始数据进行除杂,将质控后得到的所有高质量序列进行de novo拼接,分别得到长梗秦艽79 455条、粗壮秦艽78 466条unigene,平均长度分别为834 bp和862 bp。根据GO功能分类,可将unigene分为3大类65分支;根据KOG功能可将unigene分为25类;KEGG代谢通路分析分别发现长梗秦艽和粗壮秦艽中315条、340条unigene参与到20个次生代谢标准通路中。环烯醚萜苷类为藏药解吉及中药秦艽类、龙胆类、当药及青叶胆等药材的指标性成分及活性成分之一,分析结果显示:分别有80条、57条unigene参与编码环烯醚萜苷类合成途径中的24个关键酶,且在不同部位中的表达存在差异;还发现多个SSR和SNP、InDel位点。本工作可为藏药材基原植物遗传图谱构建,分子标记开发,功能基因掌握,有效成分累积规律、道地性形成机制、藏药材品种科学内涵的探讨,分子育种及濒危藏药高山植物就地保护等提供基础科学资料。2. Tibetan Traditional Medical College, Lhasa 850000, China
解吉(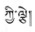


课题组前期开展了秦艽组药用植物的分类学鉴定及遗传背景分析等基础性工作[4-7], 确定了藏药解吉基原植物之一的粗壮秦艽Gentiana robusta King ex Hook. f.为一自然杂交物种; 基于相关分析, 推断其母系来源可能为另一高山药用植物麻花秦艽Gentiana straminea Maxim.[8]。还注意到一些物种ITS区及叶绿体片段在基因组内存在丰富的多样性(多种基因型), 构建物种DNA条形码需要更为丰富的遗传背景资料及个性化的物种鉴定策略[9]。同时, 复杂的遗传背景及其所含化学成分的丰富多样, 为寻找安全、高效的临床药物提供了可能性。
藏医药学具有悠久的发展历史及丰富的科学与藏族文化内涵, 根据药物外观颜色或基原植物花色不同可再分为不同品种是其鲜明特色之一。如藏药“巴莴”有“巴莴色保” (

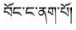
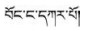
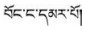
环烯醚萜苷类(iridoids)广泛分布于龙胆科(Gentianaceae)、玄参科(Scrophulariaceae)及茜草科(Rubiaceae)等双子叶植物中, 具有抗病毒、抗炎、抗氧化、抗肿瘤、抗菌及保肝利胆等多种药理作用[11], 为中药秦艽类、龙胆类、当药及青叶胆等药材的指标性成分及活性成分之一。如2015版《中华人民共和国药典》秦艽项下“龙胆苦苷和马钱苷酸”, 龙胆项下“龙胆苦苷”, 当药项下“当药苷和獐牙菜苦苷”及青叶胆项下“獐牙菜苦苷”的含量测定等[12]。
植物转录组是特定组织或细胞在某一功能状态下转录出来的所有RNA的总和, 狭义上的转录组一般指所有mRNA的集合[13]。高通量转录组测序技术现已广泛应用于药用植物转录组分析, 可全面快速地获取研究对象在某一状态下基因转录信息, 从中挖掘重要功能基因, 揭示不同生物学性状的分子机制, 为研究中药生长发育及次生代谢的分子机制提供重要的基因资源[14]。
为此, 在前期藏药解吉品种整理等工作基础上, 分别以解吉那保基原植物之一——长梗秦艽Gentiana waltonii Burk.与解吉嘎保基原植物之一——粗壮秦艽G. robusta King ex Hook. f.为模式植物, 应用Illumina HiseqXTen测序技术构建其转录组数据库, 揭示各自转录组的整体表达特征, 比较分析异同, 寻找分子标记, 并挖掘环烯醚萜苷类生物合成通路关键酶基因; 以期为藏药材基原植物遗传图谱构建, 分子标记开发, 功能基因掌握, 有效成分累积规律、道地性形成机制、藏药材品种科学内涵的探讨, 分子育种及濒危藏药高山植物就地保护等提供基础科学资料。
材料与方法民族植物学考察及分类学鉴定 与西藏藏医药大学藏族同行合作开展藏药“解吉”的考察工作。凭证标本及实验样品采集信息:粗壮秦艽, 西藏墨竹工卡县, 采集号:赵志礼, 倪梁红Z2018XZ002, 地理坐标N 29°41.315', E 92°06.798', 海拔4 315 m。长梗秦艽, 西藏墨竹工卡县, 采集号:赵志礼, 倪梁红Z2018XZ001, 地理坐标N 29°43.808', E 91°59.067', 海拔4 050 m (图 1)。取正常生长无病害植株, 连土采挖后鲜活状态下运至实验室, 纯水清洗, 无菌吸水纸吸干表面水分, 迅速将根、茎、叶、花各部位分别切成小块, 液氮速冻, 备用。

|
Figure 1 A: Habit of G. robusta; B: White flowers of G. robusta; C: A dark blue flower of G. waltonii; D: Habit of G. waltonii |
植物经上海中医药大学赵志礼教授鉴定为龙胆科龙胆属Gentiana秦艽组(Sect. Cruciata)粗壮秦艽Gentiana robusta King ex Hook. f.及长梗秦艽Gentiana waltonii Burk.; 凭证标本存放于上海中医药大学中药学院药用植物标本室。
RNA的提取分离、文库构建和转录组测序 使用Total RNA Extractor (Trizol)试剂盒(上海生工)分别提取长梗秦艽和粗壮秦艽样品根、茎、叶和花的总RNA, 检测RNA浓度及完整性。使用磁力架(上海生工生物工程股份有限公司)以磁珠法分离mRNA, 将mRNA片段化, 完成双链cDNA合成、末端修复、末端dA-Tailing、接头连接、连接产物纯化和片段大小分选、文库扩增(15个循环), 回收DNA后精确定量, 按数据比例混合上机。在Illumina HiseqXTen测序平台进行2×150 bp测序。
测序数据处理及生物信息学分析 原始图像数据文件经碱基识别(base calling)分析转化为原始测序序列(sequenced reads), 以fastq文件格式存储。对原始数据质量值等信息进行统计, 并使用FastQC对样本的测序数据质量进行可视化评估, 过滤除去含有带接头的、低质量的序列, 得到clean数据。使用Trinity软件将clean数据de novo组装成转录本(transcript)[15], 对转录本去冗余, 取每个转录本聚类中最长的转录本作为非重复序列基因(unigene)。
对转录数据使用BlastX软件(E值< 1×10-5)将unigene序列与CDD、NR、NT、Swissprot、KOG (cluster of orthologous groups of proteins)等数据库比对, 进行功能注释和分类; 再对unigene序列进行GO (gene ontology)功能注释和分类, 并与KEGG (kyoto encyclopedia of genes and genomes)数据进行比对, 分析相关的代谢通路。
使用MISA[16]对unigene序列进行SSR (simple sequence repeat)检测, 参数设置如下:单核苷酸、二核苷酸、三核苷酸、四核苷酸、五核苷酸和六核苷酸SSR的重复次数分别至少为10、6、5、5、5、5, 间隔不超过100 bp的复合型SSR。使用BCFtools[17]进行SNP/InDel calling, 抽提各样本中的SNP和InDel, 并对其根据以下条件进行过滤: ①质量值大于20; ②覆盖度大于8。
环烯醚萜苷类生物合成基因筛选 根据文献中环烯醚萜苷类化合物的生物合成途径[18-20], 结合NR和KEGG数据库注释结果和已有基因信息, 挖掘本转录组中与环烯醚萜苷类合成相关的unigene, 以TPM (transcripts per million)值, 进行表达量的统计, TPM值同时考虑了测序深度和基因长度以及样本对reads计数的影响, 是常用的基因表达水平估算方法[21]。
结果与分析 1 转录组数据组装对长梗秦艽和粗壮秦艽转录组测序及raw reads片段除杂后, 长梗秦艽根、茎、叶和花4个部位分别获得46 701 370、42 514 714、44 696 544及45 408 678个高质量reads片段; 粗壮秦艽根、茎、叶和花4个部位分别获得46 749 340、43 927 220、48 944 798及43 556 026个高质量reads片段。序列上传SRA数据库, 登录号:长梗秦艽(SRR8185390-SRR8185393), 粗壮秦艽(SRR8381079-SRR8381082)。将质控后得到的所有高质量序列进行de novo拼接。共拼接得到长梗秦艽unigene 79 455条, 平均长度为834 bp; 拼接得到粗壮秦艽unigene 78 466条, 平均长度为862 bp (表 1)。
| Table 1 Summary of the transcript statistics generated from G. waltonii and G. robusta |
将unigene与NR、NT、GO、KEGG、Swissprot及KOG等数据库通过BLAXT进行比对与注释, 长梗秦艽与粗壮秦艽分别有51.97%和52%的unigene在至少一种数据库中得到注释(表 2)。
| Table 2 Statistics of unigene functional annotation |
长梗秦艽与粗壮秦艽的unigene在NR数据库比对时, 相似序列匹配度最高的前10个物种中, 有9个一致, 其中占比最高的前4个物种分别为咖啡Coffea canephora (28.95%和29.50%)、苹果Malus domestica (8.24%和4.72%)、芝麻Sesamun indicum (4.97%和5.16%)和葡萄Vitis vinifera (4.86%和5.65%), 其余物种均小于3% (图 2)

|
Figure 2 Species distribution of transcriptomic unigenes against NR database |
长梗秦艽和粗壮秦艽转录组中, 分别有33 294条及33 159条unigene在GO数据库中成功注释, 根据GO功能分为生物过程(biological process)、细胞组分(cellular component)和分子功能(molecular function) 3个大类共65个分支(图 3)。对各类基因数量统计结果显示:长梗秦艽、粗壮秦艽聚集的大类相一致。在生物过程大类中, 主要聚集于细胞过程(cellular process, 分别为20 272条、20 326条)和代谢过程(metabolic process, 分别为17 920条、17 972条); 在细胞组分大类中, 主要聚集于细胞(cell, 分别为21 827条、21 275条)和细胞组分(cell part, 分别为21 790条、21 234条); 在分子功能大类中, 主要聚集于结合蛋白(binding, 分别为20 048条、20 523条)和催化活性(catalytic activity, 分别为16 646条、16 782条)。

|
Figure 3 GO classification of transcriptomic unigenes |
应用KOG数据库进行功能预测和分类统计, 长梗秦艽、粗壮秦艽分别共有15 790条、15 395条unigene得到注释。根据功能可分为25类, 涉及大部分生命活动(图 4)。其中, 翻译后修饰(posttranslational modification)、蛋白质周转(protein turnover)、分子伴侣(chaperones)是最大类别, 长梗秦艽、粗壮秦艽分别包含有2 114条、2 107条unigene; 其次是信号传导机制(signal transduction mechanisms, 分别为2 010条、2 046条)和一般功能预测(general function prediction only, 分别为1 989条、1 871条); 最少的是细胞外结构(extracellular structures, 分别为52条、58条)和细胞运动性(cell motility, 分别为4条、5条)。

|
Figure 4 KOG annotation distribution of transcriptomic unigenes |
长梗秦艽和粗壮秦艽unigene参与的KEGG代谢通路可分为4个分支:细胞过程(cellular processes)、环境信息处理(environmental information processing)、遗传信息处理(genetic information processing)及代谢(metabolism) (图 5), 包括23个中类、212条代谢通路。长梗秦艽、粗壮秦艽获得注释量前5的通路分别是:核糖体途径, 分别有307条(4.49%)、261条(3.91%); 碳代谢, 分别有175条(2.56%)、174条(2.61%); 剪接体, 分别有161条(2.35%)、148条(2.22%); 内质网蛋白加工, 分别有159条(2.32%)、157条(2.35%); 氨基酸生物合成, 分别有156条(2.28%)、152条(2.28%)。其余主要富集于淀粉蔗糖代谢、植物激素信号、转导RNA转运、氧化磷酸化等代谢途径。

|
Figure 5 KEGG classification of assembled unigenes |
高等植物含有多种次生代谢产物, 与其药用等功效密切相关。在长梗秦艽和粗壮秦艽转录组中分别发现315条和340条unigene参与到20个KEGG次生代谢标准通路中。其中, 苯丙素的生物合成(phenylpropanoid biosynthesis)最多, 分别有68条、73条; 其次为萜类化合物骨架合成(terpenoid backbone biosynthesis), 分别有36条、38条。各种萜类化合物的合成(monoterpenoid, diterpenoid, sesquiterpenoid and triterpenoid biosynthesis)分别有26条、34条; 黄酮类成分的合成(flavonoid, isoflavonoid, flavone and flavonol biosynthesis)分别有22条、25条; 此外, 分别还有28条、27条unigene注释到多种生物碱类合成(indoleisoquinoline, tropane, piperidine and pyridine alkaloid biosynthesis)(表 3)。
| Table 3 Secondary metabolism KEGG pathway analysis of transcriptomic unigenes |
环烯醚萜苷类化合物的生物合成途径可通过中间体的生成、环烯醚萜类骨架构成及修饰等步骤完成[18-20] (图 6)。分析结果显示:长梗秦艽和粗壮秦艽转录组中分别有80条、57条unigene参与编码其中24个关键酶(表 4)。

|
Figure 6 Putative pathways for gentiopicroside biosynthesis. Genes found in this study are shown between the reactions. The expression of unigenes in the root (R), stem (S), leaf (L) and flower (F) is shown by heatmap, mapped using TPM values |
| Table 4 Unigenes involved in iridoid biosynthesis |
公认的环烯醚萜苷中间体生成途径有两条, 一条为甲羟戊酸(mevalonic acid, MVA)途径, 该途径在胞质中进行, 关键酶有乙酰-CoA乙酰转移酶(AACT)、HMG-CoA合酶(HMGS)、HMG-CoA还原酶(HMGR)、MVA激酶(MK)、MVP激酶(PMK)及MVPP脱羧酶(MVD); 另一条为2-C-甲基-D-赤藓醇4-磷酸(2-methyl-D-erythritol-4-phosphate, MEP)途径, 在质体中进行, 关键酶包括1-脱氧-D-葡萄糖-5-磷酶合成酶(DXS)、1-脱氧-D-葡萄糖-5-磷酶还原异构酶(DXR)、2-甲基-D-赤藓糖醇-4-磷酸胞苷酰基转移酶(CMS)、4-二磷酸胞苷-2-甲基-D-赤藓糖醇激酶(CMK)、2-C-甲基-赤藓糖醇-2, 4-环焦磷酸合成酶(MCS)、4-羟基-3-甲基丁烯-2-烯基-1-二磷酸合酶(HDS)及4-羟基-3-甲基丁烯-2-烯基-1-二磷酸还原酶(HDR); 两条途径的产物异戊烯焦磷酸(isopentenyl pyrophosphate, IPP)和二甲基丙烯基焦磷酸(dimethylallyl pyrophosphate, DMAPP)之间的转换由IPP异构酶(IDI)来完成。在长梗秦艽和粗壮秦艽转录组中, 除了粗壮秦艽的CMK基因未被注释到外, 其他以上相关基因均有注释。基于TPM值统计, 这些基因表达量存在较明显的差异, 其中MVA途径中的AACT、MVD, MEP途径中的HDR及IDI基因表达量相对较高。
IPP和DMAPP在香叶基焦磷酸合酶(GPPS)催化下缩合成香叶基焦磷酸(geranyl diphosphate, GPP), GPP通过不同的代谢方向流向单萜、二萜、三萜等合成途径。对于环烯醚萜苷的合成, 后续已知的酶基因主要有香叶醇合成酶(geraniol synthase, GES)、香叶醇-10-羟化酶(G10H)、细胞色素P450还原酶(CPR)、10-羟基香叶醇氧化还原酶(10-HGO)、环烯醚萜合酶(IS)、7-去氧番木鳖酸合成酶(7-deoxyloganetic acid synthase, 7-DLS)、7-去氧番木鳖酸葡萄糖转移酶(7-DLGT)、7-去氧番木鳖酸羟化酶(7-DLH)、番木鳖酸甲基转移酶(loganic acid methyltransferase, LAMT)、裂环马钱子苷合成酶(SLS)和异胡豆苷合成酶(STR)。在长梗秦艽和粗壮秦艽转录组中, GES、7-DLS和LAMT 3个基因没有被注释到, 以及长梗秦艽中的10-HGO, 粗壮秦艽中的G10H和7-DLH未有注释, 其他相关基因均有不同数量的unigene成功注释。基于TPM值统计, 在这两个物种中表达量最高的均为根和花中SLS基因, 达345.94~633.93, 而该基因在茎和叶中的表达较低。
4 转录组序列中SSR分析应用MISA软件在长梗秦艽、粗壮秦艽unigene中分别检测到20 257及21 809个SSR (表 5)。SSR密度分布频率比较显示, 两个物种中出现频率最高的均是单碱基SSR, 每百万碱基中出现该类型SSR的个数在200以上(图 7)。单碱基SSR数量占56%以上, 其中所占比例最高是A/T; 三碱基、二碱基SSR数量次之, 分别约占18%和15%;四碱基、五碱基、六碱基SSR均相对较少, 其中最少的是五碱基SSR。
| Table 5 SSR analysis of transcriptomic unigene. c*: Compound SSR |

|
Figure 7 SSR density of transcriptomic unigene |
值得注意的是, 两个物种中均检测到约8.5%的复合型SSR。使用Primer3批量设计SSR引物, 参数:引物长度18~27 bp, 退火温度(Tm) 56~63 ℃, 前后引物Tm值相差4 ℃, 产物大小为100~300 bp; 分别成功设计长梗秦艽15 809对及粗壮秦艽16 842对SSR引物。
5 转录组序列中SNP分析以最终拼接得到的长梗秦艽unigene为reference, 分别在根、茎、叶和花的数据中检测到113 663、94 012、105 820和109 941个突变位点(包括SNP和InDel)。以最终拼接得到的粗壮秦艽unigene为reference, 分别在根、茎、叶和花的数据中检测到116 570、119 655、125 684和119 580个突变位点(包括SNP和InDel)。不同部位数据中, SNP均多于InDel, 两者数目比: 4.3:1~4.6:1 (图 8)。

|
Figure 8 SNP and InDel numbers of transcriptomic unigene |
与reference比较, SNP单核苷酸变异种类有12种。各部位数据中, 转换(transition)类型的SNP数目均明显多于颠换(transversion)类型(图 9); 长梗秦艽4组中数量最多的变异类型均为G- > A; 粗壮秦艽各组中数量最多的变异类型主要为C- > T和G- > A。

|
Figure 9 SNP types of transcriptomic unigene |
以藏药解吉那保基原植物之一——长梗秦艽G. waltonii Burk.与解吉嘎保基原植物之一——粗壮秦艽G. robusta King ex Hook. f.为模式植物, 首次测定转录组序列; 并分别将其根、茎、叶和花部位进行建库。测序数据经Trinity软件拼接分别得到79 455条、78 466条unigene。应用生物信息学方法对拼接所得的unigene进行注释和功能分类, 52%的unigene得到注释。尚未得到注释的部分, 是否为长度较短未得到有效注释, 非编码序列或为新的功能未知基因[22], 有待进一步研究。
根据KEGG数据库, 对长梗秦艽、粗壮秦艽转录组数据进行代谢途径分析, 注释到萜类、黄酮类、苯丙素类和生物碱类等20个次生代谢通路基因共315条和340条。作为秦艽组药用植物指标性成分及活性成分之一, 环烯醚萜苷类代谢过程主要经过中间体生成、萜类的合成和修饰等步骤。长梗秦艽、粗壮秦艽转录组中分别有80条、57条unigene参与编码环烯醚萜苷类合成途径中的24个关键酶, 包括MVA和MEP途径中所有的基因(除了粗壮秦艽的CMK基因)及大部分已知的环烯醚萜苷骨架合成与修饰基因。未注释到的基因其原因可能为: ①与其生长发育状态有关[22]; ②居群生存环境胁迫; ③物种间差异等。就不同器官的表达情况来看, 各基因在根、茎、叶、花等不同部位的表达量具有较明显的差异。综合所有24个关键酶相关unigene的平均TPM值, 在两个物种中, 均为根最高, 其次为花, 而茎和叶部位的值相对较低。值得注意的是裂环马钱子苷合成酶(SLS)基因, 两物种根和花中基于TPM值的表达量均最高, 达345.94~633.93。
中药秦艽及龙胆, 基原植物多分布于青藏高原, 生存环境严酷。由于种种原因, 资源状况不容乐观, 坚龙胆Gentiana rigescens Franch. ex Hemsl.、粗茎秦艽Gentiana crassicaulis Duthie ex Burk.等相关8种龙胆属植物均已被列入《国家重点保护野生药材物种名录》之中[23]。其药用根部, 药材采挖过程中地上茎、叶及花部则弃之不用。如何结合不同部位次生产物合成及积累特点进行新药用部位的开发研究, 就地保护资源, 合理利用资源, 值得深入探讨。下一步将选择相关关键酶基因, 基于qRT-PCR (quantitative real-time PCR)进行系统的定量表达分析, 并开展不同部位环烯醚萜苷类合成和积累等相关基础性研究工作。
基于转录组测序的SSR和SNP等分子标记已广泛应用于药用植物物种鉴定、遗传多样性分析等方面[24, 25]。本研究结果显示:长梗秦艽和粗壮秦艽转录组中具有丰度较高的SSR, 其中单核苷酸占大多数, 其次主要为三核苷酸和二核苷酸, 式样与麻花秦艽及川西獐牙菜等龙胆科植物相似[26, 27]。同时, 以各物种最终拼接的unigene为reference, 分别在长梗秦艽和粗壮秦艽的根、茎、叶和花的数据中检测得到大量的SNP和InDel位点信息, 可为新分子标记的开发提供丰富的数据资料。
| [1] | Yutok Yonten Gonpo. The Four Medical Tantras (四部医典)[M]. Shanghai: Shanghai Science & Technology Press, 1987: 66. |
| [2] | Dimaer Danzeng Pengcuo. Jing Zhu Ben Cao (晶珠本草)[M]. Shanghai: Shanghai Science & Technology Press, 1986: 105-106, 119. |
| [3] | Yang YC. Tibetan Medicine (藏药志)[M]. Xining: Qinghai People Press, 1991: 9-12, 213-218. |
| [4] | Zhao ZL, Dorje Gaawe, Wang ZT. Identification of medicinal plants used as Tibetan traditional medicine Jie-Ji[J]. J Ethno pharmacol, 2010, 132: 122–126. DOI:10.1016/j.jep.2010.07.051 |
| [5] | Ni LH, Zhao ZL. A morphometric comparison of three closely related species of Gentiana (Gentianaceae), endemic to the region of the Qinghai-Tibet Plateau[J]. Botany, 2018, 96: 209–215. DOI:10.1139/cjb-2017-0166 |
| [6] | Ni LH, Zhao ZL, Xu HX, et al. Chloroplast genome structures in Gentiana (Gentianaceae), based on three medicinal alpine plants used in Tibetan herbal medicine[J]. Curr Genet, 2017, 63: 241–252. DOI:10.1007/s00294-016-0631-1 |
| [7] | Ni LH, Zhao ZL, Xu HX, et al. The complete chloroplast genome of Gentiana straminea, (Gentianaceae), an endemic species to the Sino-Himalayan subregion[J]. Gene, 2016, 577: 281–288. DOI:10.1016/j.gene.2015.12.005 |
| [8] | Xiong B, Zhao ZL, Ni LH, et al. DNA-based identification of Gentiana robusta and related species[J]. China J Chin Mater Med (中国中药杂志), 2015, 40: 4680–4685. |
| [9] | Ni LH, Zhao ZL, Xiong B, et al. A strategy for identifying six species of Sect. Cruciata (Gentiana) in Gansu using DNA barcode sequences[J]. Acta Pharm Sin (药学学报), 2016, 51: 821–827. |
| [10] | Wei SJ, Zhao ZL, Ni LH, et al. Taxonomic identification of Tibetan herb Bawo Sebo and its chloroplast genome structure[J]. Acta Pharm Sin (药学学报), 2018, 53: 1009–1015. |
| [11] | Zheng LS, Lu XQ. Advances in the research of iridoids[J]. Nat Prod Res Dev (天然产物研究与开发), 2009, 21: 702–711, 725. |
| [12] | Chinese Pharmacopoeia Committee. Pharmacopoeia of the People's Republic of China. Part 1(中华人民共和国药典)[S]. Beijing: China Medical Science Press, 2015: 96, 134-135, 196-197, 270-271. |
| [13] | Ozsolak F, Milos PM. RNA sequencing:advances, challenges and opportunities[J]. Nat Rev Genet, 2011, 12: 87–98. DOI:10.1038/nrg2934 |
| [14] | Wang YL, Huang LQ, Yuan Y, et al. Research advances on analysis of medicinal plants transcriptome[J]. China J Chin Mater Med (中国中药杂志), 2015, 40: 2055–2061. |
| [15] | Grabherr MG, Haas BJ, Yassour M, et al. Full-length transcrip tome assembly from RNA-Seq data without a reference genome[J]. Nat Biotechnol, 2011, 29: 644–652. DOI:10.1038/nbt.1883 |
| [16] | Thiel T, Michalek W, Varshney RK, et al. Exploiting EST data bases for the development and characterization of gene-derived SSR-markers in barley (Hordeum vulgare L.)[J]. Theor Appl Genet, 2003, 106: 411–422. DOI:10.1007/s00122-002-1031-0 |
| [17] | Li H. A statistical framework for SNP calling, mutation discovery, association mapping and population genetical parameter estima tion from sequencing data[J]. Bioinformatics, 2011, 27: 2987–2993. DOI:10.1093/bioinformatics/btr509 |
| [18] | Contin A, Heijden RVD, Lefeber AWM, et al. The iridoid glucoside secologanin is derived from the novel triose phosphate/pyruvate pathway in a Catharanthus roseus cell culture[J]. Febs Lett, 1998, 434: 413–416. DOI:10.1016/S0014-5793(98)01022-9 |
| [19] | Yang R, Fang L, Li J, et al. Research progress on biosynthetic pathways and related enzymes of iridoid glycosides[J]. Chin Tradit Herb Drugs (中草药), 2018, 49: 2482–2488. |
| [20] | Wu XY, Liu XL. Progress of biosynthetic pathway and the key enzyme genes of iridoids[J]. Chin J Ethnomed Ethnopharm (中国民族民间医药), 2017, 26: 44–48. |
| [21] | Wagner GP, Kin K, Lynch VJ. Measurement of mRNA abundance using RNA-seq data:RPKM measure is inconsistent among samples[J]. Theory Biosci, 2012, 131: 281–285. DOI:10.1007/s12064-012-0162-3 |
| [22] | Li H, Zhang N, Li YM, et al. High-throughput transcriptomic sequencing of Rheum palmatum L. seedlings and elucidation of genes in anthraquinone biosynthesis[J]. Acta Pharm Sin (药学学报), 2018, 53: 1908–1917. |
| [23] | Zhou XJ, Xu HF, Shun QS. Resource Science of Chinese Medicinal Materials (中药资源学)[M]. Shanghai: Shanghai Scientific and Technological Literature Publishing House, 2007: 370. |
| [24] | Jiang C, Yuan Y, Liu GM, et al. EST-SSR identification of Lonicera japonica Thunb[J]. Acta Pharm Sin (药学学报), 2012, 47: 803–810. |
| [25] | Kim HJ, Jung J, Kim MS, et al. Molecular marker development and genetic diversity exploration by RNA-Seq in Platycodon Grandiflorum[J]. Genome, 2015, 58: 1–11. DOI:10.1139/gen-2014-0166 |
| [26] | Zhou D, Gao S, Wang H, et al. De novo sequencing transcrip tome of endemic Gentiana straminea (Gentianaceae) to identify genes involved in the biosynthesis of active ingredients[J]. Gene, 2015, 575: 160–170. |
| [27] | Liu Y, Yue CJ, Wang Y, et al. Data mining of simple sequence repeats in transcriptome sequences of Tibetan medicinal plant Zangyinchen Swertia mussotii[J]. China J Chin Mater Med (中国中药杂志), 2015, 40: 2068–2076. |