 2017, Vol. 47
2017, Vol. 47
2. 北京师范大学 信息科学与技术学院, 北京 100875
2. College of information Science and Technology, Beijing Normal University, Beijing, 100875, China
大数据时代带来了海量文献, 促使知识挖掘的应用研究迫在眉睫, 如何在最短时间内获取目标资源的内容并快速捕获主题思想,简单有效的方法就是提炼出文献资源的摘要, 也就是实现信息资源的挖掘和浓缩。这种摘要的获取可以是基于概括性的理解型摘要, 也可以是依赖算法的抽取型摘要。前者重在语义分析模型的建立和研究, 尤其是在中文信息处理领域, 目前遇到一定的瓶颈, 后者主要基于文献特征分析的方法来获取, 可以结合人工智能的算法抽取摘要, 取得了一定的效果[1]。自动摘要技术可以挖掘潜在的知识模型, 从海量文本资源中提取有用信息, 促进自然语言的理解, 尤其是在信息抽取、主题挖掘、文本挖掘等方面[2]。本文在采用句子、段落和篇章结构特征分析法的基础上, 结合基于特征优先权过滤的进化算法, 抽取得分较高的句子作为摘要句, 实现自动摘要抽取。
1 相关研究成果自动摘要技术诞生于20世纪50年代, 源于统计学, 依据文档中的词频、句子位置等信息生成摘要, 适合处理格式较为规范的一类文档。Luhn[3]最早提出统计词频来给句子打分, 将一个句子中所有词条的权值加起来就是该句子的得分。1969年Baxendale[4]提出采用句子在文章中的位置和词频作为打分标准, 同年Edmundsun[5]提出用标题相似度和线索词这两个新特征来计算句子的得分, 并且取得了不错的效果。S.Lamprier[6]提出了一种基因算法, 就是按照某些主题特征把文本分成不同的部分, 运用自适应度函数, 保证句子的连贯性, 同时采用一系列特征并运用不同的操作来保证适应度函数的值最大。2010年, Prasad和Kulakarni[7]又增加段落间的词相似度、句间词相似度、迭代查询打分、基于文档格式这些特征来给句子打分。当然也产生了很多针对文本摘要的进化算法, 模糊理论已被运用到基于句子在文本的位置和属性来过滤句子的方法中。差分进化算法用来优化数据聚类过程并且提高了文本摘要的质量。国内李阜提出了基于滑窗取词的单文档自动摘要技术[8], 随后, 罗文娟等将权衡熵和相关度应用到自动摘要技术研究中[9], 取得了一定的效果。2014年, 李然等进行了基于主题模型与信息熵的中文文档自动摘要技术研究, 采用人工打分的方式, 基本上能准确反映主题[10]。Mendoza采用句子位置、标题相似度、句子长度、凝聚力和覆盖率来作为目标函数的特征, 他们使用进化算法及优化技术来生成自动摘要, 效果良好[11]。基于文本特征给句子打分, 大多时候都是给每一个特征同样的权重, 然后Rafael尝试运用所有的文本特征来给句子打分[12], 但没有结合特征优先权过滤算法, 算法性能一般, 且中英文有着较大的差异, 此算法并不适合中文文献的自动摘要抽取, 例如:中文不需要区分大小写, 句子中没有空格, 中英文的线索词也存在很大差异。
在文献自动摘要抽取过程中, 如何选择摘要句, 可以类似成一个优化问题。进化算法(又称基因算法)通过模拟生物自然进化过程达到随机搜索优化的目的, 操作简单, 可以实现全局优化的目标, 同时具有广泛的适应性和并行性。因此, 该算法适合应用到中文摘要的自动抽取选择工作中[13]。目前在中文文献处理领域, 运用基于特征优先权过滤算法进行摘要抽取的相关工作较少,未见到将进化算法调节权重因子与句子特征优先权过滤算法结合使用来进行中文摘要抽取的相关研究。本实验主要针对网络上的文本(比如新闻、文献、博客等), 结合中文文档或文献的特点选择句子的特征,并进行特征优先权过滤, 减少非主旨句的干扰, 缩短运行迭代的时间。由于句子的各特征权值不同, 句子得分情况各异, 运用进化算法, 由计算机根据权重因子公式自动打分, 生成摘要。一方面可以避免人工的费时费力, 另一方面也减少人为因素的主观性造成的干扰。在新闻类的报道中, 时间、数值、地名、人名等实体信息都是十分重要的信息, 另外,标题也有丰富的内涵, 需要引起关注, 字体的大小、样式、加黑、下划线等属性也是重要的句子特征。
2 实验步骤本实验尝试提高单文档自动摘要抽取的效率及准确率, 同时还要保证摘要的可读性。根据句子的位置特征可知, 摘要的首末句一般选择文章的首尾句, 对于中间句子的选择, 结合进化算法,使用TF-ISF、命名实体识别、专有名词识别、线索词搜索、句子的位置标定、词共现统计、句子间的相似度计算等多个显著特征来抽取主题句。本实验主要分为3步:预处理、句子打分、摘要生成, 实验流程如图 1所示。

|
图 1 自动摘要过程 Fig. 1 Extractive summarization process |
针对目标文档进行统一格式编排, 消除文献中的图表以提高文献处理效率, 接着进行分段、断句、分词处理, 统计该文档词频TF, 判断句子的类型, 一般像疑问句、引用句、对话句不适合作为主旨句, 可以提前过滤掉。根据文献的章节标题序号或者线索词划分段落章节, 每一节选取首尾两段, 文档缩减为30%到50%, 删除句子长度小于8或者超过180字的句子, 因为句子太长或者太短都不适合作主题句。排除这些非主旨句的干扰之后, 剩下的句子留作候选句子集。
2.2 句子打分利用进化算法对以下8个关键文本特征进行权重因子的迭代优化:①线索词:顾名思义, 能够对文章的主旨起到提示作用的词语, 比如“得出结论”、“本次实验表明”、“主要介绍”等, 如果某一句子中出现线索词, 则该句子应该增加权值, 实验中将这些线索词存储在cuedic.txt文件中, 便于检索和收录。②句子位置:句子出现在文档中的位置不同, 权重也不同, 文档中首尾段落的句子应该被赋予较高的权值。段落中首句一般权重较大, 段落末尾的句子次之, 段落开头和结尾的第2句再次之。③TF/ISF计算:词频(Term Frequency,TF)表示词条t在文档中出现的频率, TF计算如式(1)所示,N表示文档中所有词条出现次数的总和,Nti表示词条ti在文档中出现的次数。TF-IDF理论假设某个词或短语在一篇文章中出现的频率高, 并且在其他文章中很少出现, 则认为此词或者短语具有很好的类别区分能力, 适合用来分类。所以TF-IDF倾向于过滤掉常见的词语, 保留重要的词语。类似地, ISF(Inverse Sentence Frequency)表示逆向句子频率, 如果句子中的某个词条在整个文档中出现频率越低, 则对于该句子来说越重要,如式(2)所示,其中,Nsi表示词条tk在句子Si中出现的次数。可用来移除那些在自动摘要中没有出现的高频词。④命名实体识别和专有名词识别:借助于HanLP开源工具包, 实现中文人名、地名、机构名的识别,短语和关键字提取, 并保存在coredic.txt文件中, 也可人工添加一些特殊的专有名词[14]。专有名词对于句子而言是最重要的, 并且涵盖最大的信息量, 从而赋予更大的权重, 尤其是在新闻领域; 若是针对英文文献可采用斯坦福开源的自然语言处理开发包来提取线索词和排除干扰词。⑤词共现:有一些词条会多次出现在一句话里起强调作用, 该词条应增加权重。⑥数值型词条:如果句子中含有数字或者汉语表示的数字, 该句子应该被增加权重。⑦主题特征:如果句子中含有主题词、标题中出现的词、章节小标题中出现的词、文档中的前n个高频词之一, 句子按主题特征词相应加权。⑧句子间的相似度:如果两个句子间的词汇有覆盖, 设置一个阈值, 超过阈值的就选择位置靠前的句子, 同时赋予相应的权重, 并删除后一个句子,两个句子Si和Sj间的相似度sim计算如式(3)所示, 运用向量空间模型表示句子的特征向量, 相似度通过两向量间夹角余弦值来表示, Wk表示特征词tk在句子Si中的权重, 采用TFtk*ISFtk计算。
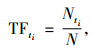
|
(1) |
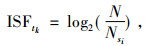
|
(2) |
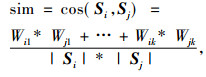
|
(3) |
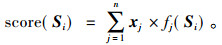
|
(4) |
进化算法的实现过程如图 2所示, 算法操作的效果与3个遗传算子(选择、交叉、变异)所取的操作概率密切相关, 同时与算法所选取的编码方法、群体大小、初始群体以及自适应度函数的设定也有很大关联。随机产生初始种群数为100, 种群规模为8, 一般最大迭代数为500, 最低为100, 本次实验交叉概率为0.9, 变异概率取0.05。算法中的自适应度函数(又称评估函数)是在搜索优化时用来判断群体中个体或解的优劣, 并作为后代遗传操作的依据。自适应度函数需要比较、排序和计算出选择概率, 直接影响到文档自动摘要的优化性能, 所以其目标值一般取正值。本实验的自适应度函数由8个句子特征函数组成, 如式(4)所示, Si代表文档中的第i个句子, j代表特征序号, n代表特征选取函数个数, f为特征函数, fj(Si)表示给第i个句子的第j个特征打分, x代表特征权重向量。采用十进制浮点数编码(又称实数编码)方案[15], 随机生成0~10之间的8个整数构成种群个体, 为保证8个特征权重之和为1, 最后分别除以这8个函数得分的总和, 得到各因子的权重。在进行句子特征权值选择操作时, 采用轮盘赌的方式进行选择操作, 主要目的是提高收敛速度, 具有最高评估值的染色体(句子)应当选择到摘要句候选列表中。若某一特征没有出现, 则采用均匀变异的方法进行自适应调整操作(比如变异、交叉、繁殖), 权重调节因子分别如下:α=0.5, β=0.3, γ=0.2。在进行交叉操作时,采用一致交叉的方式, 实现个体间的“信息交换”, 有利于找到全局极值。算法终止条件是目标函数的优化值达到最大, 即句子的得分最高。最后按句子的得分从高到低排列, 一般选择得分靠前的6个句子作为自动生成的摘要, 按照ROUGE[16]方法, 根据与标准摘要之间文本相似度来评估, 找出最接近标准摘要的一组权值, 并输出最优权重因子向量x(句子各特征的权重比例)。

|
图 2 进化算法的实现步骤 Fig. 2 Genetic Algorithm Implementation |
采用特征优先权过滤算法, ①根据第1步对原始文档进行预处理, 排除干扰句子。②计算出句子中所有词条TF得分, 计算每个句子的ISF分数, 根据TF-ISF得分选择排名前50%的句子留作主旨句的候选集。③采用命名实体识别特征函数给句子打分并排序, 选择排名前50%作为下一次过滤的主旨句候选集。④根据第2步进化算法算出的特征因子组合, 并采用打分函数(如式(3)所示)计算候选集中的每个句子的得分, 放在L列表里暂存。⑤将句子按分数降序排列, 选择源文档的第一句作为摘要的第一句, 从L列表里选出除了首尾句的n-2个句子按照出现在源文档中的顺序加到摘要中来, 然后再从源文档中选择最后一句作为摘要的最后一句, 其中n为一般标准摘要的句子长度, 一般n取值为6~8。
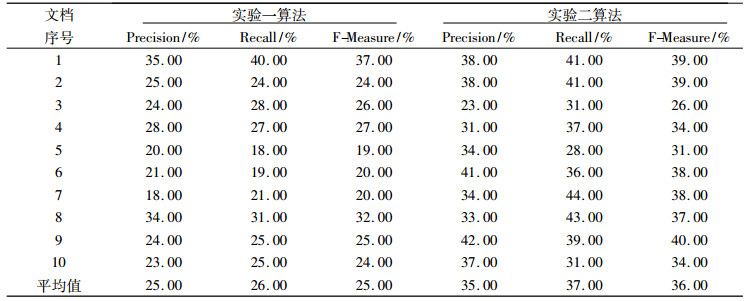
3 实验结果对比与分析本次实验采用DUC2002数据集中的10篇英文新闻语料进行测试,实验一将句子各特征的权重都赋值为1, 计算每个句子的得分以及最后生成摘要中每个词出现在标准摘要中的次数。实验二运用进化算法迭代得到的特征权值向量x≈[0.17 0.26 0.20 0.14 0.03 0.08 0.10 0.02], 按照打分函数自动给每个句子打分, 并结合特征优先过滤算法生成摘要。采用ROUGE-1矩阵方法来评价两次实验结果, 如表 1所示, 通过对比发现, 采用进化算法并结合特征优先权过滤句子, 显著提升了自动摘要的质量, 除了文档3, 其余所有文档的精确率(Precision)、召回率(Recall)和F值(F-Measure)都提高了, 平均值分别达到35%, 37%, 36%。对于文档3的异常情况, 主要和该文档的内容特征相关, 该文档比较简短, 主题词不明显并且专有名词较少。
|
|
表 1 英文文档实验结果 Tab. 1 English documents experimental results |
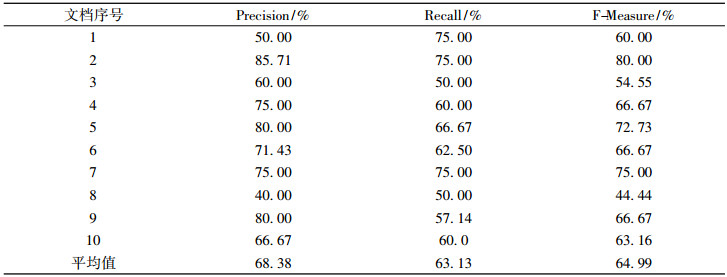
为了验证该方法对中文期刊自动摘要抽取的性能, 随机从CNKI下载了10篇自然语言处理领域的文章进行实验,运用上文的进化算法求得权值因子组合, 结合特征优先权过滤算法, 将自动生成的摘要与源期刊的摘要进行比对。本次实验采用基于句子准确率和召回率的方法来评价摘要抽取效果, 最后得到这10篇期刊的准确率、召回率、F值如表 2所示, 平均准确率为68.38%, 召回率为63.13%, F值为64.99%, 选取其中1篇文档的摘要对比结果如表 3所示。相对而言, 本文提出的算法对中文文档的摘要抽取效果较好, 基本上保证原文的主要内容。在新闻学领域, 句子的一些特征比如专有名字、字体样式、实体名词可能信息量较大, 应该赋予较大的权重。而在IT领域, 数值型数字、句子位置、词频可能对于摘要的影响较大。利用进化算法的良好的自适应性, 对于不同领域文献的文本特征, 可以较快求得最优特征权值组合。当然,本文算法对于主题模型挖掘、信息抽取、文本挖掘等应用也同样适用。
|
|
表 2 中文文档实验结果(MS-Word 2007文档) Tab. 2 Chinese documents experimental results |
|
|
表 3 实验文档摘要对比 Tab. 3 Summarization comparison example of the test document |

利用进化算法求出特征因子的最优权值组合, 并根据句子特征采用特征优先权过滤算法, 显著提升了摘要自动抽取效果。该方法也可应用到其他领域的文献摘要抽取中。实验不足之处在于, 本次试验采用的文本句子特征有限, 这都是今后可以改进的地方。针对不同类型的期刊(比如会议论文、学位论文、报纸类、演讲稿等)和不同领域的文献, 相应的特征参数不一样, 相应的权重因子也不一样。对文献进行自动分类, 根据不同的类标签调用不同的过滤算法, 并按照相应的摘要格式抽取摘要, 是下一步研究工作的重点, 这将有助于大数据时代下信息抽取和知识模型的获取, 促进人工智能的进一步发展。
| [1] |
葛加银.文本自动摘要技术的研究[D].上海: 复旦大学, 2004. http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y651808
|
| [2] |
谭翀, 陈跃新. 自动摘要方法综述[J]. 情报学报, 2008, 27(1): 62-68. DOI:10.3969/j.issn.1000-0135.2008.01.010 |
| [3] |
LUHN H P. The automatic creation of literature abstracts[J]. IBM Journal of Research and Development, 1958, 2(2): 159-165. DOI:10.1147/rd.22.0159 |
| [4] |
BAXENDALE P B. Machine-made index for technical literature:An experiment[J]. IBM Journal of Research and Development, 1958, 2(4): 354-361. DOI:10.1147/rd.24.0354 |
| [5] |
EDMUNDSON H P. New methods in automatic extracting[J]. Journal of the ACM, 1969, 16(2): 264-285. DOI:10.1145/321510.321519 |
| [6] |
LAMPRIER S, AMGHAR T, LEVRAT B, et al.Sengen: A genetic algorithm for linear text segmentation[C]//Proceeding of The International Joint Conference on Artificial Intelligence, 2007: 1647-1652.
|
| [7] |
SHARDANAND P R, KULKARNI U. Implementation and evaluation of evolutionary connectionist approaches to automated text summarization[J]. Journal of Computer Science, 2010, 6(11): 1366-1376. DOI:10.3844/jcssp.2010.1366.1376 |
| [8] |
李阜.基于滑窗取词的单文档自动摘要技术研究[D].长沙: 国防科学技术大学, 2010. http://cdmd.cnki.com.cn/Article/CDMD-90002-2010165414.htm
|
| [9] |
罗文娟, 马慧芳, 何清, 等. 权衡熵和相关度的自动摘要技术研究[J]. 中文信息学报, 2011, 25(5): 9-16. DOI:10.3969/j.issn.1003-0077.2011.05.002 |
| [10] |
李然, 张华平, 赵燕平, 等. 基于主题模型与信息熵的中文文档自动摘要技术研究[J]. 计算机科学, 2014, 41(增Ⅱ): 298-300. |
| [11] |
MENDOZA M, BONILLA S, NOGUERA C, et al. Extractive single-document summarization based on genetic operators and guided local search[J]. Expert System with Applications, 2014, 41(9): 4158-4169. DOI:10.1016/j.eswa.2013.12.042 |
| [12] |
FERREIRA R, FREITAS F, CABRAL L D S, et al. A context based text summarization system[C]//2014 11th IAPR International Workshop on Document Analysis Systems (DAS).IEEE, 2014: 66-70. https://www.researchgate.net/publication/286602623_A_Context_Based_Text_Summarization_System
|
| [13] |
刘德喜, 何焱祥, 姬东鸿, 等. 一种基于演化算法进行句子抽取的多文档自动摘要系统SBGA[J]. 中文信息学报, 2006, 20(6): 46-53. DOI:10.3969/j.issn.1003-0077.2006.06.007 |
| [14] |
上海林原信息科技有限公司.HanLP-汉语言处理包[DB/OL].[2016-03-20].http://hanlp.linrunsoft.com/.
|
| [15] |
张彤, 张华, 王子才. 浮点数编码的遗传算法及其应用[J]. 哈尔滨工业大学学报, 2000, 32(4): 59-61. DOI:10.3321/j.issn:0367-6234.2000.04.018 |
| [16] |
LIN C Y. ROUGE: A package for automatic evaluation of summaries[C]//Proceedings of the Workshop on Text Summarization Branches Out (WAS), 2004: 25-26. https://wenku.baidu.com/view/2ce89ee86294dd88d0d26b3b.html
|
| [17] |
樊兴华, 孙茂松. 一种高性能的两类中文文本分类方法[J]. 计算机学报, 2006(1): 124-131. DOI:10.3321/j.issn:0254-4164.2006.01.013 |