 2017, Vol. 47
2017, Vol. 47
 , 赵继东2, 邵玉斌1, 杜庆治1
, 赵继东2, 邵玉斌1, 杜庆治1 2. 大理州洱海流域保护局, 云南 大理 671000
2. Erhai Lake Basin Protection Bureau of Dali, Dali 671000, China
地理信息是地理数据中蕴含和说明的地理含义, 是与地理要素相关的物品的数量、品质、性质、散布特性、联系以及规律的数字、汉字、图像和图案的统称[1]。近几年来, 随着地图学应用的扩大, 时, 其数据的不统一也带来了困惑, 地理信息的数据融合成为需要研究的问题[2]。
地图中的经纬度信息对于邻近区域的查询具有很大的便利, 能提高地理信息匹配的准确率。文献[3]提出地理信息语义表达及相似性度量模型, 涉及地理信息的语义相似度, 但没有涉及到经纬度距离的判断。文献[4-5]提出基于本体属性的语义相似性计算模型以及描述逻辑的地理本体融合方法, 对地理信息语义的概念及描述内容没有明确说明。文献[6]提出基于字面相似度的地理信息分类体系自动转换方法, 忽略了它的符号和语义特征, 很难达到高准确率。快速并高质量的融合算法可以将大量地理信息进行分类处理, 找出匹配的信息点, 从而通过这种算法来减轻工作量, 方便人们对地理信息的充分利用[7]。
本文在地理信息的匹配效率与准确匹配的误差值研究的基础上, 提出了基于地图地理信息点的数据融合算法(Data fusion algorithm based on map geographic information point,DFGI), 该算法通过定义语义相似度, 根据地理信息分词后的相似度和命名实体识别(Named entity recognition,NER)后的相似度的融合以及地理信息点的经纬度距离,来判断两个地理信息数据之间是否匹配, 提高了单纯相似度匹配不准确的问题。本文以云南省大理市洱海周边所有餐馆的地理信息为实例, 基于百度和高德两种地图, 分析了其具体地理信息的情况, 通过实验结果验证了DFGI算法提高了地理信息的匹配效率, 减少了误差值。
1 地理名称预处理本文假设有两类地图, h为地图 1中的地理名称, g为地图 2中的地理名称, 地理名称、地理名称地址、经纬度坐标的地理信息已经被提取, 并进行分类[8]。

|
图 1 DFGI算法的匹配效率U Fig. 1 Matching efficiency of DFGI algorithm |

|
图 2 DFGI算法的误差值D Fig. 2 Error values of DFGI algorithm |
分类后对地理名称进行预处理[9], 即按照地理名称中的首部(通常为地名)、内容(通常为类型)、尾部(通常为场所), 将原地理名称简化成由不同短文本构成的长字符串, 然后进行文本匹配。
一个地理名称的短文本集合表示为地理名称首部、地理名称内容和地理名称尾部的集合:
短文本集合={首部,内容,尾部}。
定义1 地理名称h经过预处理后得到首部、内容、尾部3个短文本, 短文本集合表示为H0={h1, h2, …, hf, hf+1, …, hi, hi+1, hi+2, …, hn}, f+1≤i≤n-1。其中, 元素h1, h2, …, hf表示地理名称首部短文本, 元素hf+1, hf+2, …, hi表示地理名称内容短文本, 元素hi+1, hi+2, …, hn表示地理名称尾部短文本。地理名称g预处理后得到首部、内容、尾部3个短文本, 其短文本集合表示为G0={g1, g2, …, ge, ge+1, …, gj, gj+1, gi+2, …, gm}, e≤j≤m-1。其中元素g1, g2, …, ge表示地理名称首部短文本, 元素ge+1, ge+2, …, gj表示地理名称内容短文本, 元素gj+1, gj+2, …, gm表示地理名称尾部短文本。
定义2 对于h地理名称中集合H0的某一部分(短文本首部或内容或尾部)与g地理名称中的集合G0, 对于任何文本, 分别满足下面5种映射, 则分别说明两者之间的关系是相等、包含、包含于、相交与相离:
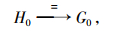
|
(1) |
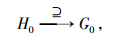
|
(2) |
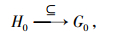
|
(3) |
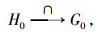
|
(4) |
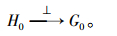
|
(5) |
其中, 式(1)等价于短文本首部(或内容或尾部)与短文本集合相互包含或包含于(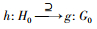
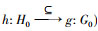
利用DFGI算法实现地理信息数据匹配过程, 首先,要使用语义相似度算法对分词后和NER后的地理名称及地理名称地址分别进行相似度计算; 其次, 借助经纬度坐标进行地理名称之间的距离计算; 最后,根据匹配原则, 匹配出相同的地理信息。
2.1 语义相似度算法 2.1.1 语义相似度计算本文语义相似度算法[10]主要是通过词语上下文的信息, 运用统计的算法进行求解。地理名称和地理名称地址经过预处理后, 要分别进行两次相似度计算, 第一次为分词后的相似度计算, 第二次为NER后的相似度计算, 两次相似度计算原理均相同。
对地理名称h和g, 经过汉语分词系统分词后, 将其表示为如下词向量:
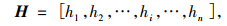
|
(6) |
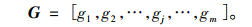
|
(7) |
式(6)中hi表示地理名称分词以后的第i个词, i=1, 2, …, n; 用Len(H)表示向量H的长度, 即h分词之后所有词的数量为Len(H)=n。式(7)中gj表示该地理名称分词以后的第j个词, j=1, 2, …, m; 用Len(G)表示向量G的长度, 即g分词之后所有词的数量为Len(G)=m。
将地理名称h和g分词后的所有词进行合并, 对于再次出现的词, 只能保留一个, 从而获得两个向量的总和X, 名为H和G的并集。
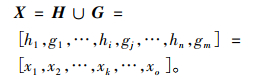
|
(8) |
式(8)中, X表示地理名称h的向量H和地理名称g的向量G两者之间的向量之和, xk表示合并后的两个向量的第k个词, k=1, 2, …, o;i, j∈k。其中, 该并集X的长度Len(X)=o应满足
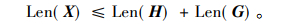
|
(9) |
即:o≤n+m, 式(9)中, Len(X)表示X的向量长度, 即地理名称h和g合并后的所有词的个数。
X中的每一个词xk在地理名称h和g中是否存在的情况, 称为h和g中的语义分数, 分别用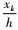

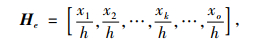
|
(10) |
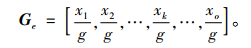
|
(11) |
式(10)中, He表示h基于X的语义向量; 式(11)中, Ge表示g基于X的语义向量; 
由此, 引出语义向量计算语义相似度的计算公式为
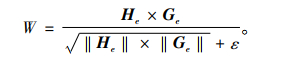
|
(12) |
式(12)中, W∈(0, 1]为He和Ge的语义相似度值, He为h的语义向量,Ge为g的语义向量, ‖He‖为向量He的模, ‖Ge‖为向量Ge的模, ε为无穷小量, 仅用于控制分母不是零的情况[3]。
当两个地理名称h和g完全相似时, W=1;当两个地理名称h和g完全不同时, W=0;其他情况下,两个地理名称h和g其余的相似度W∈(0, 1)。
同理, 第二次NER后, 得到的所有词构成该句子的另一个向量表示, 经过语义相似度计算[11], 得出两个地理名称NER后的相似度值。地理名称地址同样进行以上两次相似度计算, 分别得出两个地理名称地址分词后的相似度值和NER后的相似度值。
2.1.2 加权平均值地理名称h和g分词后的相似度值和NER后的相似度值与地理名称h和g的地址分词后的相似度值和NER后的相似度值通过一个排列组合, 全部排列起来; 对排列的4个相似度值进行加权平均值计算,

|
最后, 加权平均值Y用一个门限M来控制。如果Y小于M, 表示两个地理名称不相同或不相似, 匹配结束; 如果Y大于M或在M附近, 则分为两种情况, 相似或不确定, 接着进行两个地理信息点经纬度距离之间的计算。
2.2 经纬度信息处理经纬度是经度与纬度的总和, 它是一个球面坐标系统, 通过使用三度空间的球面来定义地球上的空间, 可以代表地球上的一个位置。WGS-84是国际经纬度坐标的标准, 而高德地图使用的是火星坐标, 也叫GCJ-02。百度地图[12]是在火星坐标的基础上, 采用BD-09二次加密措施, 形成了百度地图坐标。由于高德地图使用的坐标和百度地图使用的坐标不在同一个坐标系中, 因此, 在计算地理信息点之间的经纬度距离时会存在很大的误差。为了减小误差, 需要进行误差偏移校验。首先统一坐标系为GCJ-02, 即将百度地图经纬度(BD-09坐标系)转为高德地图经纬度(GCJ-02坐标系)后, 再作相应的经纬度距离计算。
在地图中, 用E1表示地理名称h的纬度, N1表示地理名称h的经度, E2表示地理名称g的纬度, N2表示地理名称g的经度。经纬度均用弧度表示, 则有下列转换,
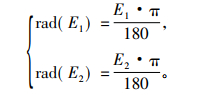
|
(13) |

|
(14) |
式(13)中, rad(E1)为地理名称h纬度的弧度, rad(E2)为地理名称g纬度的弧度; 式(14)中, rad(N1)为地理名称h经度的弧度, rad(N2)为地理名称g经度的弧度。
另外, 两个地理信息点之间的纬度之差用a表示, 两个地理信息点之间的经度之差用b表示,
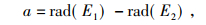
|
(15) |
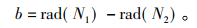
|
(16) |
通过式(17)和式(18)计算两个地理信息点之间的经纬度距离(单位为m):
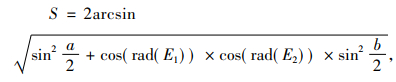
|
(17) |
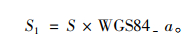
|
(18) |
式(18)中, WGS84_a为赤道上到地球中心的地球半径距离, 数值为6 378 137.0,单位为m; S1为两个地理信息点之间的经纬度距离[13]。
通过计算两个地理信息点之间的经纬度距离来判断, 如果两者之间的距离差值大于某一个门限T, 则这两个地理信息点不匹配; 如果两者之间的距离差值小于某一个门限T, 则这两个地理信息点匹配。
3 实验过程及结果 3.1 实验数据基于前述算法, 本实验使用的数据是从百度地图和高德地图上选取云南省大理市西北的洱海周边的所有餐馆数据为实例。其中, 高德地图上抓取到了2 291条餐馆数据, 百度地图[14]上抓取到了3 911条餐馆数据(由于高德地图上的数据不够全面, 故两个地图之间的餐馆数据不对等)。通过算法计算两个地图的加权平均值Y后, 得到13 820条Y≥0.6的数据(该算法在Y<0.6时全部忽略不计)。由于后续需要人工对比两个地图的数据来验证算法的准确性, 工作量较大, 所以随机提取了3 328条餐馆数据作为餐馆样本进行实验。
3.2 实验过程地理名称和地理名称地址在进行相似度计算以前需要进行一个分词处理, 分词是使用IKAnalyzer一个开源的代码, 它是根据Java语言而开发的一种中文分词包,主要应用是在一个开源的项目Luence中,是结合汉语分词和语法分析算法的中文分词组件[15]。
另外, 还要进行NER处理, 使用的是HanLP自然语言处理包开源, 是由一系列模型与算法组成的Java工具包。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点[16]。
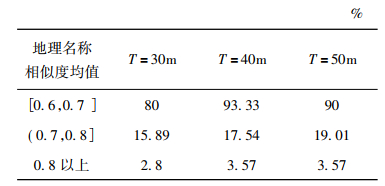
3.3 实验结果及分析本实验在MySQL数据库中进行数据预处理工作, 使用SQL语言和Java语言编写分词相似度、NER相似度与经纬度距离计算的程序, 完成在两个地图数据中同一地理信息点的一致性匹配处理。DFGI算法中存在漏匹配的目标和错误匹配的目标, 故用匹配效率U和误差值D来进行评价, 其中匹配效率U指通过DFGI算法判断相似度匹配的数量Ur与样本总数Us之间的比率; 误差值D指通过人工对比地图判断不相似不匹配的数量Tr与通过DFGI算法判断相似度匹配的数量Ur之间的比率[6],计算公式如式(19)和式(20)所示。通过实验, 在D≤30m时, 加权平均值Y∈[0.6, 0.7]范围内的样本总数Us=2 500, 匹配数量Ur=86, 人工判断不匹配的数量Tr=64;加权平均值Y∈[0.7, 0.8]范围内的样本总数Us=695, 匹配数量Ur=506, 人工判断不匹配的数量Tr=17;加权平均值Y∈[0.8, 1]范围内的样本总数Us=133, 匹配数量Ur=120, 人工判断不匹配的数量Tr=2。
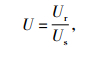
|
(19) |
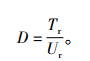
|
(20) |
图 1显示了对大理洱海周边餐馆数据利用DFGI算法得到的匹配效率U, 图 2则显示了大理洱海周边餐馆数据匹配的误差值D, 可见DFGI算法具有较好的匹配效率和较高的准确性。
在实验中, 加权平均值Y固定不变的情况下, 门限T分别取值小于等于30m, 40m和50m, 观察不同经纬度距离下的匹配效率变化和误差值变化; 同样的, 在门限T固定不变的情况下, 加权平均值Y分别取介于0.6~0.7之间,0.7~0.8之间以及大于0.8的3组数据,观察不同加权平均值下的匹配效率变化和误差值变化。
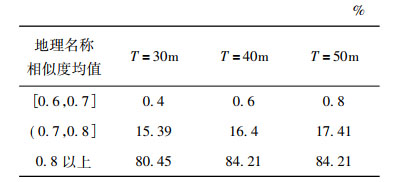
地理名称相似度均值为地理名称h和g分词后的相似度值和地理名称h和g命名实体识别后的相似度值之间的平均值。由表 1和表 2可知, 单纯使用以地理名称相似度均值为核心的融合算法, 仅适用于地理名称的相似度匹配, 匹配效率相对较低, 误差值较大; 在相似的地理名称、相近的经纬度距离下, 无法准确判断两个地理信息点是否匹配。而以加权平均值Y为核心的融合算法, 适用于地图地理信息点的相似度匹配, 这种算法的匹配效率得到极大的改善, 误差值减小; 在相似的地理名称、相近的经纬度距离下, 通过地理名称地址的进一步筛选, 能够快速准确地判断两个地理信息点是否匹配。经实践验证, DFGI算法的匹配效率最高可达到95.49%左右, 由于算法使用程序自动计算来确定, 工作效率和准确性都有所提高。然而, 由于矢量数据库丰富的语义信息以及复杂的拓扑关系, 矢量数据本身的匹配就很复杂, 地理信息数据之间的错误匹配和遗漏匹配是不可避免的。因此, 在实验过程中依然需要程序判断和人工判断相融合的算法。
|
|
表 1 地理名称相似度均值的匹配效率 Tab. 1 Matching efficiency of geographical name′s similarity mean |
|
|
表 2 地理名称相似度均值的误差值 Tab. 2 Deviation of geographical name′s similarity mean |
根据实际需求, 本文以大理洱海周边所有餐馆的地理信息为例, 分析了其具体地理信息的情况, 提出基于地图地理信息点的数据融合算法。从地理信息数据着手, 研究了不同地图之间的地理信息数据的融合算法, 并引入了分词后的相似度和命名实体识别后的相似度, 以及经纬度距离计算, 为数据的快速、准确匹配提供了一种解决方案。DFGI算法在匹配效率和误差值两个方面优于其他算法, 下一步将对更加精确匹配的问题进行进一步研究。
| [1] |
朱乔利, 李学锋, 李永刚, 等. 基于MindNet的地理信息概念语义关系分析[J]. 数字技术与应用, 2016(8): 66-68. |
| [2] |
王家耀. 地图制图学与地理信息工程学科发展趋势[J]. 测绘学报, 2010, 39(2): 115-119. |
| [3] |
贾小斌, 艾延华, 彭子凤, 等. 地理信息语义的LOD表达与相似性度量[J]. 武汉大学学报(信息科学版), 2016, 41(10): 1299-1306. |
| [4] |
谭永滨, 李霖, 王伟, 等. 本地属性的基础地理信息概念语义相似性计算模型[J]. 测绘学报, 2013, 42(5): 782-789. |
| [5] |
李军利, 何宗宜, 柯栋梁, 等. 一种描述逻辑的地理本体融合方法[J]. 武汉大学学报(信息科学版), 2014, 39(3): 317-321. |
| [6] |
张雪英, 闾国年. 基于字面相似度的地理信息分类体系自动转换方法[J]. 遥感学报, 2008, 12(3): 433-441. |
| [7] |
MA Zhaoting, LI Zhigang, SUN Wei, et al. An automatic geo-coding algorithm based on address segmentation[J]. Bulletin of Surveying and Mapping, 2011(2): 59-62. |
| [8] |
杨瑾, 崔蓉, 刘苗, 等. 旅游者地理空间认知模型与知识研究[J]. 西北大学学报(自然科学版), 2012, 42(6): 1011-1015. DOI:10.3969/j.issn.1000-274X.2012.06.028 |
| [9] |
SU W, WANG J, LOCHOVSKY F H, et al. Combining tag and value similarity for data extraction and alignment[J]. IEEE Transactions on Knowledge and Data Engineering, 2012, 24(7): 1186-1200. DOI:10.1109/TKDE.2011.66 |
| [10] |
魏凯斌, 冉延平, 余牛. 语义相似度的计算方法研究与分析[J]. 计算机技术与发展, 2010, 20(7): 102-105. DOI:10.3969/j.issn.1673-629X.2010.07.026 |
| [11] |
MAEDCHE A, STAAB S. Ontology learning for the semantic web[J]. IEEE Intelligent Systems & Their Applications, 2001, 16(2): 72-79. |
| [12] |
潘伟洲, 陈振洲, 李兴民. 基于人工神经网络的百度地图坐标解密方法[J]. 计算机工程与应用, 2014, 50(17): 110-119. DOI:10.3778/j.issn.1002-8331.1210-0047 |
| [13] |
黎珍惜, 黎家勋. 基于经纬度快速计算两点间距离及测量误差[J]. 测绘与空间地理信息, 2013, 36(11): 235-237. DOI:10.3969/j.issn.1672-5867.2013.11.074 |
| [14] |
CAI Wenyi.Management system of wireless signal coverage based on baidu maps API[C]//2016 15th RoEduNet Conference: Networking in Education and Research.IEEE, 2016: 1-5. http://ieeexplore.ieee.org/document/7753216/
|
| [15] |
柴洁. 基于IKAnalyzer和Lucene的地理编码中文搜索引擎的研究与实现[J]. 城市勘测, 2014(6): 45-50. DOI:10.3969/j.issn.1672-8262.2014.06.012 |
| [16] |
码农场. HanLP自然语言处理包开源[CP].(2015-03-27)[2016-11-20].http://www.hankcs.com/hlp/hanlp.html.
|