



0 引言
在油气资源需求增加和油气勘探难度增大的背景下,对火山岩的研究和勘探已逐渐成为油气勘探的重要内容。其中,火山岩岩性的识别是火山岩储层研究的重要课题,它既是储层评价的前提,也是岩相及喷发期次的判断依据[1]。火山岩类大部分深埋于盆地的内部,普遍具有岩石类型复杂、分布规律变化大的特点,地质学者通常依照结构-成分-成因的三级分类原则,通过对钻井岩心的观察和描述、岩石薄片的鉴定及化学成分的分析,建立火山岩岩性的分类体系和识别标准[2]。但是有些火山岩储层的岩心获取率低,难以对火山岩储层进行完整而系统的评价。笔者鉴于测井数据纵向上连续、精度高,获取方式多样,处理和分析操作性强等诸多优点,在学习前人技术和方法的基础上,采用测井数据进行火山岩岩性识别[3-5]。
近年来,伴随测井设备的更新发展,测井数据更加丰富,测井岩性的解释方法也更加多样化。基于常规测井设备,获取常规测井9条曲线系列;基于成像测井设备,获取沿井壁的二维图像和沿井周的三维图像;基于核磁共振测井设备,获取岩性储层自由流体的渗流体积特性。由此衍生了以测井响应特征为基础的多种测井岩性解释方法,从交会图版解释法到多元统计分析法,再到随大数据应运而生的机器学习算法[6-8],逐渐提高了测井岩性解释的时效,也提高了识别的符合率。机器学习算法因高效的识别速度、良好的泛化能力等优点在众多岩性解释方法中脱颖而出。张野等[9]基于Inception-v3深度卷积神经网络模型,建立了岩石图像分析模型,实现了岩性的分类和识别;杨笑等[10]采用Ada Boost决策树算法,识别长岭气田酸性火山岩岩性,识别准确率达90%以上; 苏赋等[11]提出了一种多分类孪生SVM (support vector machine)的测井岩性识别方法,识别美国Hogoton油田测井数据9种岩性,并将识别结果与传统支持向量机、深度神经网络等方法进行对比与分析;笔者[12]也曾采用常规5种测井曲线数据,构造“一对一”、“一对多”和有向无环图3种支持向量机岩性识别模型,识别辽河盆地东部坳陷火山岩岩性。在前人研究的基础上,笔者发现基于不同机器学习算法的岩性识别模型存在着各自的优缺点,因此总结了3种比较经典的机器学习算法,以某油田测井数据为依托,建立火山岩岩性识别模型,并作对比分析,为火山岩岩性识别提供更开阔的思路。
1 机器学习算法原理 1.1 K近邻KNN(K nearest neighbor) 算法是一种原理简单,易于实现,分类性能稳定的机器学习算法。“物以类聚”是对KNN算法思想最好的诠释,KNN算法在测试数据附近找到k个与它距离最近的训练数据,测试数据点的类别由这k个训练数据类别中最受欢迎的类别决定[13-14]。KNN算法尤其适用于重叠较多的海量数据分类,k值选取策略和距离函数的选择会影响模型的复杂性和分类准确性(图 1)。

|
| 图 1 KNN算法流程图 Fig. 1 Flowchart of the KNN algorithm |
|
|
SVM本质上是一个两分类模型。在完全线性可分的情况下,通过对训练数据集的训练,求解使得几何间隔最大的最优分离超平面,从而对测试数据集进行分类;实际上,海量数据集很少有完全线性可分的情况,SVM通过引入损失函数,允许某些点不满足约束条件,这就出现了惩罚因子;在线性不可分的情况下,通过选取适当的核函数,将它转化为某个特征空间中的线性可分问题。因此,在SVM算法实践的过程中,惩罚因子和核函数的选择对获得最优决策函数至关重要(图 2)。

|
| αi为拉格朗日乘子;yi为标签;b为结果偏差;i=1, 2, …, n。 图 2 SVM算法原理示意图 Fig. 2 Schematic illustration of the SVM algorithm |
|
|
Ada Boosting(adaptive boosting)是一种集成学习方法,被评为十大数据挖掘算法之一。Ada Boosting最初是为了提高两分类问题的预测符合率而提出的,此算法的基本思想是通过迭代的方式从弱分类算法的误差中学习,并将其转变为强分类算法。即事先给定训练样本x、初始样本权重W和弱分类器迭代总次数m,训练样本在第i个弱学习器中的样本权重为Win, i=1, 2, …, m;n为训练样本个数。然后通过多次调用弱学习算法,生成一系列基分类器gi (x), 每次迭代后加强错分样本的权重。最后通过加权的方式将弱分类器集成为强分类器, 构建最终分类器g(x)。训练样本权重Win和基分类器权重βi是决定算法预测符合率的2个关键因素[15](图 3)。

|
| 图 3 Ada Boosting算法原理示意图 Fig. 3 Schematic illustration of the Ada Boosting algorithm |
|
|
从研究区内5口有岩心样品或薄片鉴定资料的目标层中选取测井数据点1 440个,其中960个作为训练样本,其余480个作为测试样本,训练样本和测试样本中各岩性的比例相同。从常规测井系列中优选对研究区岩性敏感的自然伽马(GR)、声波时差(AC)、补偿中子(CNL)、深侧向电阻率(RLLD)和补偿密度(DEN)等5种测井参数作为岩性识别模型的输入向量,将研究区内的粗面岩、非致密粗面岩、辉绿岩、辉长岩、玄武岩和非致密玄武岩等6类火山岩岩性作为岩性识别模型的输出结果。
由于5种测井参数的数量级和量纲存在差别,因此需要先对原始测井数据进行归一化处理。其计算公式如下:
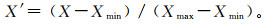
式中:X′为归一化后的数据;X为原始测井数据;Xmax, Xmin分别为某测井参数的最大值和最小值。经过归一化的无量纲测井数据有利于提高模型的识别符合率。
2.2 岩性识别模型建立KNN岩性识别模型的符合率主要取决于同一类岩性数据特征值的相似程度,而KNN中相似度用距离来刻画,也就是需要计算某测试数据点与所有训练数据点的距离,本文采用欧式距离。在选取与测试数据最近的k个训练数据的过程中,k值是影响KNN识别效果的一个重要参数。通常建议k值取测试样本的算术平方根,若k取值过大,则会增加计算量。基于本实验同类岩性测井数据的相关性很高,因此在保证识别符合率的前提下,k取值尽量小。本实验将k值在4~8间做尝试,当k=5时,识别效果最佳。
SVM岩性识别模型的训练过程中,核函数和惩罚因子在很大程度上影响SVM的性能。本文选用高斯函数作为核函数。高斯核函数k(x, xi) 的公式如下:
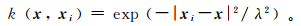
式中:x为空间中任意一点;xi为核函数的中心点;λ为核参数。而核函数中核参数的变化,会改变特征映射,进而改变特征空间的复杂程度,从而影响SVM识别符合率。惩罚因子(c)通过调节模型经验风险和置信区间的比例,提高SVM的推广能力。以160个粗面岩和160个玄武岩测井数据为例,进行SVM参数(c, λ) 优化。实验表明,当设置c = [2-10,210]、λ = [2-10,210]、搜索步长d为0.5、交叉验证的次数为5折时,准确率为100% (图 4),最优的参数组合为(c, λ)=(2, 16)。

|
| 图 4 SVM参数寻优过程图 Fig. 4 Parameter optimization process of SVM |
|
|
Ada Boosting算法是一个两分类算法,而本文要解决的是6类岩性的多分类问题,因此需要构造6类岩性两两组合的15个Ada Boosting两分类器。例如,采用160个玄武岩和160个辉绿岩测井数据集作为训练样本构造Ada Boosting两分类器,简称此分类器为X-H Ada Boosting,采用80个玄武岩和80个辉绿岩测井数据集作为测试样本,预测X-H Ada Boosting的符合率。由此实验发现,分类误差随迭代次数和交叉验证的次数变化。本次调用X-H Ada Boosting算法对玄武岩和辉绿岩测试样本测试,迭代初始值为200,进行交叉验证的次数为5折和10折时的测试错误率对比(图 5)。从图 5中可以看出,当迭代次数到达147时,采用10折交叉验证的准确率最高。调用Ada Boosting算法其他两两分类器时,发现交叉验证的次数为10折时测试准确率均比5折时高。

|
| 图 5 X-H Ada Boosting 5折和10折交叉验证时错误率对比图 Fig. 5 Comparison of 5-fold and 10-fold cross-validation of error rate |
|
|
本文以识别符合率和时间作为评价指标,对KNN算法、SVM算法和Ada Boosting算法的识别结果进行对比分析。对比分析结果如表 1所示。
| 岩石类型 | KNN | SVM | Ada Boosting | |||||
| 识别符合率/% | 时间/s | 识别符合率/% | 时间/s | 识别符合率/% | 时间/s | |||
| 玄武岩 | 67.50 | 128 | 86.25 | 58 | 88.75 | 56 | ||
| 粗面岩 | 86.25 | 150 | 87.50 | 63 | 91.25 | 61 | ||
| 非致密玄武岩 | 83.75 | 132 | 77.50 | 62 | 76.25 | 62 | ||
| 非致密粗面岩 | 73.75 | 98 | 85.00 | 58 | 81.25 | 60 | ||
| 辉绿岩 | 66.25 | 117 | 72.50 | 57 | 72.50 | 59 | ||
| 辉长岩 | 78.75 | 94 | 77.50 | 60 | 71.25 | 62 | ||
从表 1可以看出:Ada Boosting算法的分类准确率最高,6类岩性平均识别符合率达到82.10%;SVM算法表现良好,平均识别符合率为81.04%;KNN算法平均识别符合率为76.04%,低于SVM算法5.00%,低于Ada Boosting算法6.06%。从同类岩性的识别结果来看,Ada Boosting算法对玄武岩和粗面岩的识别效果最好;SVM对非致密粗面岩和非致密玄武岩的识别效果略好于Ada Boosting算法;3种算法对辉绿岩和辉长岩的识别符合率普遍低于其他岩性。笔者认为3种算法均容易在辉绿岩和辉长岩间存在相互误判是因为辉绿岩相当于辉长岩的基性浅成岩,这2种岩石矿物成分和化学成分相近,因此测井响应特征相近。从运行时间角度来看,KNN算法耗时较多,这是因为KNN的每个测试数据在寻找最近邻样本时,需要逐个计算测试数据与每个训练数据的距离,导致识别效率降低。
3 结论本文将K近邻、支持向量机和自适应增强3种经典机器学习算法应用于某研究区内6类火山岩岩性识别问题,结论如下:
1) 3种算法均具有可行性。
2) 在3种机器学习算法的模型训练过程中,关键参数的选择能够决定识别符合率,例如:KNN中的k值,SVM中的核参数和惩罚因子等。
3) KNN算法虽然识别符合率略低于SVM和Ada Boosting,但是它的算法简单,更易于实现。
在不需要其他并行算法的情况下,如何通过在算法中引入其他算法进行样本选择、样本分类及参数优化实现多分类,从而提高识别符合率和运算效率,是笔者下一步的研究重点。
| [1] |
严伟, 刘帅, 冯明刚, 等. 四川盆地丁山区块页岩气储层关键参数测井评价方法[J]. 岩性油气藏, 2019, 31(3): 95-104. Yan Wei, Liu Shuai, Feng Minggang, et al. Well Logging Evaluation Methods of Key Parameters for Shale Gas Reservoir in Ding-Shan Block, Sichuan Basin[J]. Lithologic Reservoirs, 2019, 31(3): 95-104. |
| [2] |
王璞珺, 缴洋洋, 杨凯凯, 等. 准噶尔盆地火山岩分类研究与应用[J]. 吉林大学学报(地球科学版), 2016, 46(4): 1056-1070. Wang Pujun, Jiao Yangyang, Yang Kaikai, et al. Classification of Volcanogenic Successions and Its Application to Volcanic Reservoir Exploration in the Junggar Basin, NW China[J]. Journal of Jilin University (Earth Science Edition), 2016, 46(4): 1056-1070. |
| [3] |
Wang W H, Wang P J, Wang Z W, et al. Identifying the Lithology of Volcanic Rocks by Using the Time-Frequency Features of Array Acoustic Logging Data[J]. Interpretation, 2020, 8(3): 1-38. |
| [4] |
于洋, 王祝文, 宁琴琴, 等. 松辽盆地大庆长垣四方台组可地浸砂岩铀成矿测井评价[J]. 吉林大学学报(地球科学版), 2020, 50(3): 929-940. Yu Yang, Wang Zhuwen, Ning Qinqin, et al. Logging Evaluation of in Situ Leachable Sandstone Uranium Mineralization in Sifangtai Formation of Daqing Placantic Line, Songliao Basin[J]. Journal of Jilin University (Earth Science Edition), 2020, 50(3): 929-940. |
| [5] |
覃瑞东, 林振洲, 潘和平, 等. 木里地区水合物及岩性测井识别方法[J]. 物探与化探, 2017, 41(6): 1088-1098. Qin Ruidong, Lin Zhenzhou, Pan Heping, et al. Identification of Hydrate and Lithology Based on Well Logs in Muli Area[J]. Geophysical and Geochemical Exploration, 2017, 41(6): 1088-1098. |
| [6] |
冯冲, 王清斌, 谭忠健, 等. 富火山碎屑地层复杂岩性测井分类与识别: 以KL16油田为例[J]. 石油学报, 2019, 40(增刊2): 91-101. Feng Chong, Wang Qingbin, Tan Zhongjian, et al. Logging Classification and Identification of Complex Lithologies in Volcanic Debris-Rich Formations: An Example of KL16 Oilfield[J]. Acta Petrolei Sinica, 2019, 40(Sup.2): 91-101. |
| [7] |
徐苗苗, 印兴耀, 宗兆云, 等. 基于复合蛙跳算法的火山岩最优化测井解释方法[J]. 石油物探, 2020, 59(1): 122-130. Xu Miaomiao, Yin Xingyao, Zong Zhaoyun, et al. Logging Interpretation Optimization of Volcanic Rocks Using the Complex Frog-Leaping Algorithm[J]. Geophysical Prospecting for Petroleum, 2020, 59(1): 122-130. |
| [8] |
孙予舒, 黄芸, 梁婷, 等. 基于XG-Boost算法的复杂碳酸盐岩岩性测井识别[J]. 岩性油气藏, 2020, 32(4): 98-106. Sun Yushu, Hang Yun, Liang Ting, et al. Identification of Complex Carbonate Lithology by Logging Based on XG-Boost Algorithm[J]. Lithologic Reservoirs, 2020, 32(4): 98-106. |
| [9] |
张野, 李明超, 韩帅. 基于岩石图像深度学习的岩性自动识别与分类方法[J]. 岩石学报, 2018, 34(2): 333-342. Zhang Ye, Li Mingchao, Han Shuai. Automatic Identification and Classification in Lithology Based on Deep Learning in Rock Images[J]. Acta Petrologica Sinica, 2018, 34(2): 333-342. |
| [10] |
杨笑, 王志章, 周子勇, 等. 基于参数优化Ada Boost算法的酸性火山岩岩性分类[J]. 石油学报, 2019, 40(4): 457-467. Yang Xiao, Wang Zhizhang, Zhou Ziyong, et al. Lithology Classification of Acidic Volcanic Rocks Based on Parameter-Optimized Ada Boost Algorithm[J]. Acta Petrolei Sinica, 2019, 40(4): 457-467. |
| [11] |
苏赋, 马磊, 罗仁泽, 等. 基于改进多分类孪生支持向量机的测井岩性识别方法研究与应用[J]. 地球物理学进展, 2020, 35(1): 174-180. Su Fu, Ma Lei, Luo Renze, et al. Research and Application of Logging Lithology Identification Based on Improve Multi-Class Twin Support Vector Machine[J]. Progress in Geophysics, 2020, 35(1): 174-180. |
| [12] |
牟丹, 王祝文, 黄玉龙, 等. 基于SVM测井数据的火山岩岩性识别: 以辽河盆地东部坳陷为例[J]. 地球物理学报, 2015, 58(5): 1785-1793. Mou Dan, Wang Zhuwen, Huang Yulong, et al. Lithological Identification of Volcanic Rocks from SVM Well Logging Data: Case Study in the Eastern Depression of Liaohe Basin Chinese[J]. Journal of Geophysics, 2015, 58(5): 1785-1793. |
| [13] |
Glowacz A, Glowacz Z. Recognition of Images of Finger Skin with Application of Histogram, Image Filtration and K-NN Classifier[J]. Biocybernetics and Biomedical Engineering, 2016, 36(1): 95-101. DOI:10.1016/j.bbe.2015.12.005 |
| [14] |
Rastegarzadeh G, Nemati M. Primary Mass Discrimination of High Energy Cosmic Rays Using PNN and K-NN Methods[J]. Advances in Space Research, 2018, 61(4): 1181-1191. DOI:10.1016/j.asr.2017.11.016 |
| [15] |
曹莹, 苗启广, 刘家辰, 等. Ada Boost算法研究进展与展望[J]. 自动化学报, 2013, 39(6): 745-758. Cao Ying, Miao Qiguang, Liu Jiachen, et al. Advance and Prospects of Ada Boost Algorithm[J]. Acta Automatica Sinica, 2013, 39(6): 745-758. |