 2020, Vol. 37
2020, Vol. 37扩展功能
文章信息
- 汪雯琦, 高广阔, 王子鉴, 梁易鑫
- WANG Wen-qi, GAO Guang-kuo, WANG Zi-jian, LIANG Yi-xin
- 汽车运行工况的构建方法
- A Method for Constructing Automobile Operation Condition
- 公路交通科技, 2020, 37(9): 128-138
- Journal of Highway and Transportation Research and Denelopment, 2020, 37(9): 128-138
- 10.3969/j.issn.1002-0268.2020.09.017
-
文章历史
- 收稿日期: 2020-01-03


目前,我国汽车运行工况的相关标准主要是在上个世纪引进的德国和欧洲标准。这些标准与我国汽车运行工况的差异很大。近年来,随着汽车保有量的快速增长和城市化率的不断增加,我国道路交通状况变化很大, 且不同地区汽车运行工况差异很大,目前缺乏统一适用的标准。当前,制订出适合我国各地国情的油耗标准和排放规范是当务之急。
运动学片段是指汽车从怠速状态开始至相邻的下一个怠速状态开始之间的车速变化状况的连续过程,如图 1所示。本研究设计了一种合理的方法,将预处理后的数据划分为多个运动学片段,并给出通过数据文件处理计算得到的运动学片段的最终数量[1]。

|
| 图 1 运动学片段的定义 Fig. 1 Definition of kinematic segment |
| |
为了在国际市场上占据新一代能源汽车性能的领先地位,欧洲、日本、美国加快了汽车运行工况的研发[2-7]。近年来,国内学者也开始对车辆的运行状况进行深入研究[8-9]。多数学者采用结合主成分分析(PCA)和K-means聚类法来进行汽车运行工况的拟合,但传统K-means聚类算法的初始聚类中心会导致聚类结果下降,陷入局部最大值。胡宸等[10]、胡志远等[11]使用PCA、K-means聚类分别构建了哈尔滨和上海的车辆运行工况,但均未在初始聚类中心的基础上寻优。石琴等[12]改进了初始聚类中心,并使用神经网络算法构建了汽车运行工况,但神经网络需要设置初始权值,导致聚类质量下降。
本研究将在公共交通系统、城市发展及汽车排放标准方面起到推动作用,其意义主要体现在:
(1) 有助于公共交通系统的建设与发展,减少汽车怠速时间和缓解城市拥堵,从而提高出行效率。
(2) 能规范城市汽车市场准入标准,解决汽车采购中的乱象,有助于有关部门掌握车辆的实际使用情况,提升政府决策能力。(3)车辆运行工况的变化对汽车燃料消耗和污染物排放有重要影响,在节能减排和环境保护以及在国际市场上抢占新能源汽车性能的领先地位有重要作用。
1 模型 1.1 原始数据用行车记录仪采集记录上海市某辆轻型汽车在实际普通道路上行驶的数据,采集3次包括3个不同时间段的信息,采样频率为1 Hz。先判断各个指标所代表的含义。“速度”提供了车辆的速度信息,由于采样时间的间隔为1 s,因此也可计算出车辆行驶加速度。“三轴加速度”提供了车辆3个轴向的加速度信息,对后续速度与加速度的计算与分析意义不大。“经纬度信息”提供了计算行驶距离的可能性,可根据具体公式计算汽车行驶距离。“发动机转速”和“节气门开度”[13]有助于判断汽车是否处于熄火状态。其他变量也会为研究汽车运行状况提供帮助。车辆主要结构、配置和性能参数情况见表 1。
| 序号 | 名称 | 描述和值 |
| 1 | 车辆名称 | 轻型汽车 |
| 2 | 品牌名称 | 五十铃牌 |
| 3 | 发动机型号 | 4KH1-TC1 |
| 4 | 发动机功率/W | 89 |
| 5 | 发动机排量/L | 2.99 |
| 6 | 外型尺寸/mm | 4 978×1 686×1 575 |
| 7 | 核定载荷/kg | 600 |
| 8 | 整备质量/kg | 1 570 |
| 9 | 总质量/kg | 2 495 |
| 10 | 轴距/mm | 3 025 |
| 11 | 燃烧种类 | 柴油 |
| 12 | 货厢栏板尺寸/mm | 1 496×1 470×447 |
| 13 | 最高车速/(km·h-1) | 135 |
| 14 | 轮胎规格 | LT215/75R15 P215/75R15 LT235/75R15 P235/75R15 |
| 15 | 轮胎数 | 4 |
| 16 | 前轮距/mm | 1 460 |
| 17 | 后轮距/mm | 1 435 |
| 18 | 轴荷/kg | 995(前), 1 500(后) |
| 19 | 转向形式 | 方向盘 |
| 20 | 轴数 | 2 |
1.2 数据预处理 1.2.1 缺失数据填充
由于高层建筑遮挡或经过隧道等,行车记录仪所记录的信息会出现GPS信号过弱或丢失,造成数据记录不连续。首先判断数据丢失时汽车可能的行驶状态,以便采用不同方法对缺失数据进行填充。数据丢失时汽车可能处于以下3类行驶状态。
第1类:缺失数据时间前后的行驶速度均大于10 km/h,认为在信号丢失的这段时间内汽车处于正常行驶状态,可能由于高层建筑覆盖或过隧道等原因造成了信号丢失。根据信号丢失前后的GPS速度,利用线性插值法对丢失的速度进行填充。
第2类:缺失数据时间前一个状态GPS速度为0且油门踏板开度也为0,则认为发动机未处于运行状态,故车辆处于熄火状态,GPS可能也处于待机状态,未检测到数据信息,视为汽车怠速进行处理,将速度填充为0。对于间隔时长超过180 s的数据,按照怠速长度180 s进行处理。
第3类:缺失数据时间前一个状态GPS车速为0或小于10 km/h,而加速踏板位移不为0,可能由于进隧道长时间堵车等原因造成,认为这一阶段处于怠速,按照车速为0进行数据填充。
对于时间不连续问题的处理,将后一个数据的秒数减去前一个数据的秒数,若差值等于1,则继续进行;若差值不等于1,需要将其标记为0并返回该值所在的位置,进而提取缺失时间数据前后的速度和加速踏板位移值,以判断车辆在信号丢失时间段的可能行驶状态。对于不同的行驶状态,采用上述方法进行相应处理。
利用Matlab进行计算,发现724处时间不连续的情况,符合上述第1类情况的时间间隔有429处,符合第2类的有189处,符合第3类的有106处,分别进行相应的处理与填充。
1.2.2 平滑速度异常状态数据行车记录仪记录的速度单位为km/h,加速度的单位为m/s2,所以先对速度进行单位转化,使其单位变为m/s,计算公式为:
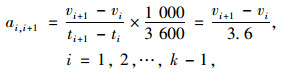
|
(1) |
式中,ai, i+1为第i s到第(i+1)s的加速度;vi+1,vi分别为第i s和第(i+1)s的速度;ti+1,ti分别为第i s和第(i+1)s的时刻;k为运动学片段的总时间,也是总速度的个数。
根据式(1)算出各个时间点上的加速度值。通常认为,一般情况下,普通轿车0~100 km/h的加速时间大于7 s,紧急制动最大减速度为7.5~8 m/s2。所以可认为当加速度大于3.97 m/s2或减速度小于-8 m/s2时为异常值。采用移动平均滤波器Smooth函数进行平滑处理以消除这些异常值,默认窗宽为5。
1.2.3 长期停车数据处理对长期停车(如停车不熄火等候人、停车熄火但采集设备仍在工作等)所采集的异常数据,首先明确长时间停车的类型,分为是/否熄火两种情况进行考虑。如果发动机转速为0,表示发动机已处于熄火状态,将该数据做删除处理;如果发动机转速不为0,但车速为0,按怠速处理。
1.2.4 怠速情况分析将长时间堵车、断续低速行驶状况(车速小于10 km/h)按照怠速工况处理。首先找出车辆行驶速度长时间小于10 km/h的连续时段,选择车速小于10 km/h的时间点进行划分。根据其连续性的判断与选择,合并连续的时间点,划分为若干个连续片段。如果某片段的持续时间长度大于180 s,则将这段时间视为怠速工况状态;如果持续长度未达到180 s,为了保证数据的准确性,则不作处理而保留原始速度信息。
1.2.5 怠速数据处理找到怠速时长超过180 s的片段,利用滑动窗口法进行解决。首先定义一个长度为180 s的窗口,并用这一窗口按照从上到下的顺序去截取速度为0的数据。当截取的这段数据中车速均为0时,需删除1个数据再继续截取,直至遍及所有数据。为了提高滑动速度,若截取到的1段数据的最后一个车速值不为0,就直接跳过这一片段,继续进行滑动。最后保证数据集中没有出现超过180 s的怠速工况。
数据的预处理均利用Matlab软件编程解决。在补齐缺失数据、处理或剔除异常值数据后,行车记录仪在3个不同时间段采集的数据最终记录数分别为205 990,173 368,180 786。预处理前后的数据对比如图 2所示。

|
| 图 2 三个片段运动学数据预处理前后对比 Fig. 2 Comparison of kinematic data of 3 segments before and after preprocessing |
| |
2 运动学片段的提取 2.1 运动学片段相关理论
在构建道路运动工况的过程中存在着多种方法,其中应用最为广泛的是将全部试验数据按照某种既定原则划分为若干个片段,并对所有小片段进行研究。选择适当的方法构建运行工况,而其中这些片段即为运动学片段(从怠速状态开始至相邻的下一个怠速状态开始之间车速变化状况的连续过程)。用此方法构建的运行工况更符合实际。
将上述运动学片段中的几种运动学状态进行划分如下。
(1) 怠速工况:发动机工作,且车辆速度V为0的状态。
(2) 匀速工况:车辆加速度a小于0.10 m/s2并大于-0.10 m/s2,且V不为0的状态。
(3) 加速工况:车辆加速度a大于0.10 m/s2,且V不为0的状态。
(4) 减速工况:车辆减速度a小于-0.10 m/s2,且V不为0的状态。
2.2 运动学片段的划分为构建运行工况,需要对运动片段进行划分。划分标准是:从怠速状态开始至相邻的下一个怠速状态开始之间车速变化状况的连续过程。由于汽车行驶状况数据的试验数据量较大,且城市道路行驶过程中启停较为频繁,需要进行行程划分的数据数量较大,必须利用软件进行处理,选用Matlab软件辅助处理,分别对3个行驶数据文件的数据进行切分,形成若干运动学片段,分别划分成1 716,2 184,1 681个运动学片段。
2.3 运动学片段的特征提取与计算汽车行驶是一个很复杂的过程,所以需要选取适当数量的特征参数来评价这些运动学片段,因此进行运动学片段的分类有助于进行特征参数的有效性判定。选取一些常用的参数及一些可能有助于描述行驶情况的参数提取其特征。除了常用的9个特征参数,结合实际增加运动学片段提取的4个参数:Pc,amax,amin,Vmax。最终,定义了13个特征参数,即:P0,Pa,Pd,Pc,amax,amin,aa,ad、astd,Vmax,V,Vm,Vstd,以描述全部的运动学片段,具体见表 2。
| 序号 | 参数 | 特征参数意义 |
| 1 | P0/% | 怠速时间百分比 |
| 2 | Pa/% | 加速时间百分比 |
| 3 | Pd/% | 减速时间百分比 |
| 4 | Pc/% | 匀速时间百分比 |
| 5 | amax/(m·s-2) | 最大加速度 |
| 6 | amin/(m·s-2) | 最大减速度 |
| 7 | aa/(m·s-2) | 平均加速度 |
| 8 | ad/(m·s-2) | 平均减速度 |
| 9 | astd/(m·s-2) | 加速度标准差 |
| 10 | Vmax/(m·s-1) | 最大速度 |
| 11 | V/(m·s-1) | 平均速度 |
| 12 | Vm/(m·s-1) | 平均行驶速度 |
| 13 | Vstd/(m·s-1) | 速度标准差 |
由上述选取的特征参数中,发现加速度值较多为5个,因其不能直接通过观测得到,故需要根据GPS速度,使用相关公式进行计算。
13个特征值的计算公式如下。
加速时间百分比:
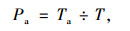
|
(2) |
式中,Ta为运动学片段中加速度大于0.1 m/s2的时间数;T为运动学片段的总时间数。
减速时间百分比:
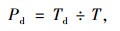
|
(3) |
式中,Td为运动学片段中加速度小于-0.1 m/s2的时间数。
怠速时间百分比:
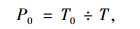
|
(4) |
式中T0为运动学片段中的怠速的时间数。
匀速时间百分比:
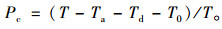
|
(5) |
最大速度:
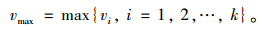
|
(6) |
平均速度:
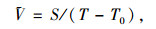
|
(7) |
式中, S为每个运动学片段所代表的汽车行驶距离。由于该试验的采样频数设置为1 Hz,即每两个点的时间间隔为1 s,所以S为该片段的速度之和,计算式为:
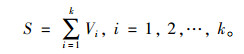
|
(8) |
平均行驶速度:
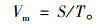
|
(9) |
速度标准差:
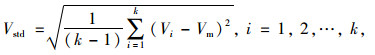
|
(10) |
式中, Vi为汽车行驶数据中按时间顺序的第i个速度; k为行驶数据的总条数。
加速度相关特征值:

|
(11) |
通过编程对上述特征参数进行了计算,并为后续运动学片段的筛选及汽车运行工况的构建提供了重要信息。分别对3个文件中的数据进行了特征值的提取与计算,每份汽车行驶数据文件中分别选取了1张运动学片段进行前后对比。
由图 3可明确地识别该车在特定时间段的行驶状态。接下来对上述所有分割出来的运动学片段进行有效筛选,最终选取最具代表性且符合真实道路行驶的片段以构建较为准确的汽车运行工况。

|
| 图 3 三个行驶数据文件中预处理前后的汽车行驶工况对比 Fig. 3 Comparison of vehicle driving conditions in 3 driving data files before and after preprocessing |
| |
3 汽车运行工况的构建 3.1 构建流程
因特征参数较多,选用主成分分析模型对特征参数进行降维处理。将13个特征参数变量转化为数量较少的几个主成分,接着以这几个主成分作为变量,运用K-means聚类模型对运动学片段进行分类,主要构建流程如图 4所示。

|
| 图 4 汽车运行工况构建流程 Fig. 4 Flowchart of constructing vehicle operation condition |
| |
3.2 基于主成分分析的数据降维
按照主成分分析步骤[14],对标准化后的特征值进行分析。计算13个特征参数的方差贡献率和累积贡献率,得到结果列在表 3中。
| 成分 | 初始特征值 | 提取平方和 | 循环平方和 | ||||||||
| 总计 | 方差/% | 累积/% | 总计 | 方差/% | 累积/% | 总计 | 方差/% | 累积/% | |||
| 1 | 6.00 | 46.18 | 46.18 | 6.00 | 46.18 | 46.18 | 4.69 | 36.04 | 36.04 | ||
| 2 | 2.70 | 20.77 | 66.95 | 2.70 | 20.77 | 66.95 | 2.94 | 22.60 | 58.64 | ||
| 3 | 1.20 | 9.25 | 76.20 | 1.20 | 9.25 | 76.20 | 1.81 | 13.93 | 72.58 | ||
| 4 | 1.03 | 7.89 | 84.09 | 1.03 | 7.89 | 84.09 | 1.50 | 11.52 | 84.09 | ||
| 5 | 0.79 | 6.09 | 90.18 | — | — | — | — | — | — | ||
| 6 | 0.49 | 3.78 | 93.96 | — | — | — | — | — | — | ||
| 7 | 0.33 | 2.52 | 96.48 | — | — | — | — | — | — | ||
| 8 | 0.21 | 1.65 | 98.13 | — | — | — | — | — | — | ||
| 9 | 0.12 | 0.93 | 99.05 | — | — | — | — | — | — | ||
| 10 | 0.09 | 0.68 | 99.73 | — | — | — | — | — | — | ||
| 11 | 0.02 | 0.16 | 99.89 | — | — | — | — | — | — | ||
| 12 | 0.01 | 0.11 | 100.00 | — | — | — | — | — | — | ||
| 13 | -1.824e-18 | -1.403e-18 | 100.00 | — | — | — | — | — | — | ||
选取累积贡献率达到80%作为基准,达到的为第4项的84.09%,且前4项主成分的特征值均大于1,基本涵盖全部信息,所以提取前4项主成分表征原始特征参数。计算因子载荷矩阵,如表 4所示。
| 特征参数 | 成分 | |||
| 1 | 2 | 3 | 4 | |
| 平均速度 | 0.895 | -0.028 | -0.094 | 0.153 |
| 最大速度 | 0.878 | -0.221 | 0.165 | 0.105 |
| 平均行驶速度 | 0.853 | -0.12 | -0.074 | 0.048 |
| 速度标准差 | 0.834 | 0.422 | -0.101 | 0.179 |
| 最大加速度 | 0.759 | 0.51 | -0.151 | -0.001 |
| 怠速时间百分比 | 0.723 | 0.489 | -0.111 | 0.334 |
| 等速时间百分比 | 0.7 | 0.559 | -0.243 | 0.153 |
| 平均减速度 | 0.031 | 0.846 | -0.089 | -0.144 |
| 平均加速度 | -0.06 | 0.741 | -0.351 | 0.034 |
| 加速度标准差 | -0.151 | -0.729 | 0.191 | -0.577 |
| 最大减速度 | -0.092 | -0.137 | 0.876 | 0.091 |
| 减速时间百分比 | -0.071 | -0.258 | 0.855 | -0.132 |
| 加速时间百分比 | 0.248 | -0.057 | 0.027 | 0.955 |
主成分1描述了平均速度、最大速度、平均行驶速度、速度标准差、最大加速度、怠速时间百分比和等速时间百分比。主成分2描述了平均减速度、平均加速度和加速度标准差。主成分3描述了最大减速度和减速时间百分比。主成分4描述了加速时间百分比。所以主成分1~4就是降维后的主成分。
根据:
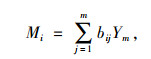
|
(12) |
式中,Mi为主成分得分序列;bij为对应的成分系数;Ym为标准化后的特征值。
从而得到第1~第4主成分的得分。经计算后式(12)变为:
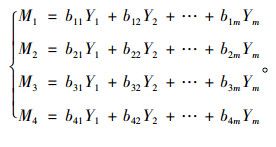
|
(13) |
主成分载荷(无量纲)见表 5。
| 特征参数 | 成分 | |||
| 1 | 2 | 3 | 4 | |
| 平均速度 | 0.37 | -0.02 | -0.09 | 0.15 |
| 最大速度 | 0.36 | -0.13 | 0.15 | 0.1 |
| 平均行驶速度 | 0.35 | -0.07 | -0.07 | 0.05 |
| 速度标准差 | 0.34 | 0.26 | -0.09 | 0.18 |
| 最大加速度 | 0.31 | 0.31 | -0.14 | 0 |
| 怠速时间百分比 | 0.3 | 0.3 | -0.1 | 0.33 |
| 匀速时间百分比 | 0.29 | 0.34 | -0.22 | 0.15 |
| 平均减速度 | 0.01 | 0.51 | -0.08 | -0.14 |
| 平均加速度 | -0.02 | 0.45 | -0.32 | 0.03 |
| 加速度标准差 | -0.06 | -0.44 | 0.17 | -0.57 |
| 最大减速度 | -0.04 | -0.08 | 0.8 | 0.09 |
| 减速时间百分比 | -0.03 | -0.16 | 0.78 | -0.13 |
| 加速时间百分比 | 0.1 | -0.03 | 0.02 | 0.94 |
所以可得4个主成分为:

|
(14) |

|
(15) |
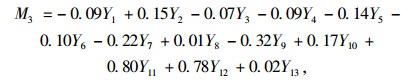
|
(16) |

|
(17) |
由上列4个表达式,通过计算变量Y1到Y13得到M1, M2, M3, M4的值。
然后进入SPSS的标准化处理,其中Y1为怠速
时间百分比,Y2为加速时间百分比,Y3为减速时间百分比,以此类推计算出主成分M1, M2, M3, M4的结果。
3.3 K-means聚类模型降维处理后,运用SPSS软件以及Jupyter Notebook工具进行降维得到4个主成分分别进行分类处理。具体通过聚类分析,即经降维处理,对运动学片段数据按各自特性和一定的规则分成3类,找到了运动学片段样本数据中的相似和区别,大量减少了研究的数量,在车辆研究领域有重要意义。
3.3.1 分类数量的确定(1) 初步设定
据文献[15-16],汽车运动状态通常被分为3种:走走停停、低速行驶、高速行驶。因此,在SPSS运行时将分类数初步设定为3。
(2) 轮廓系数法
在具体决定分类法个数时,采用了轮廓系数进行聚类评估。其计算公式为:
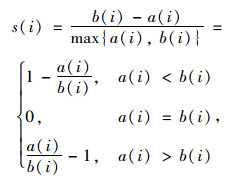
|
(18) |
式中,a(i)为点i到所有它所属的簇中其他点距离的平均值; b(i)为点i到与它相邻最近的一簇内所有点平均距离的最小值。
通过Jupyter Notebook编程,得出了图 5所示的初始化群集数折线图。

|
| 图 5 初始化群集数折线图 Fig. 5 Line chart of initialization cluster number |
| |
由图 5可知,当分类数为3时,s(i)更接近1,此时的聚类合理。这再次验证了分类为3是正确合理的。
3.3.2 直观验证根据Jupyter Notebook动态编程进行2类、3类分类尝试。经比较,分为3类合理。
3.3.3 运动学片段的聚类分析结合以上3种方法,最终确定分类数为3时最为合适。经过100次迭代,主成分被成功地分成3类,聚类中心[17]见表 6。
| 类别 | 主成分1 | 主成分2 | 主成分3 | 主成分4 |
| 1 | -1.38 | 9.24 | -3.51 | 4.92 |
| 2 | 4.45 | -0.57 | 8.05 | 1.44 |
| 3 | -1.12 | -14.05 | 5.70 | 1.08 |
运动学片段聚类结果见图 6。由于数据众多,为方便观测,作随机失活处理。第1类三角形图标含有3 112个运动学片段数,占总时间比例的55.76%。第2类正方形图标含有2 282个运动学片段数,占总时间比例的40.89%。第3类圆形图标含有187个运动学片段数,占总时间比例的3.35%。如图 6所示,从左至右图标设置不同,分别为正方形图标、三角形图标、圆形图标。

|
| 图 6 该辆车所有数据运动学片段的聚类 Fig. 6 Clustering of all data kinematic segments of vehicle |
| |
根据Jupyter Notebook编程将3类数据进行分析。
分析发现,第3类圆形图标:走走停停;第2类正方形图标:高速行驶;第1类三角形图标:低速行驶。这与现实情况基本吻合,再次验证了选择3种分类情况是正确的。综上所述,对于此辆汽车的运行工况数据进行分析,得出了车辆运行被分为3类,且相互之间具有明显的差异。
| 片段号 | 主成分1 | 主成分2 | 主成分3 | 主成分4 | 分类 | 图标 |
| 1 | 0.19 | -0.65 | -0.19 | -0.35 | 1 | 三角形 |
| 10 | -0.87 | 0.34 | -1.41 | -1.07 | 1 | 三角形 |
| 16 | -0.11 | -0.63 | -0.07 | -0.31 | 1 | 三角形 |
| 18 | -0.61 | 0.08 | -1.17 | -0.81 | 1 | 三角形 |
| 19 | -0.78 | 0.3 | -1.44 | -0.99 | 1 | 三角形 |
| 2 | 0.04 | -0.03 | 1.69 | 1.25 | 2 | 正方形 |
| 3 | 0.21 | -0.43 | 1.23 | 0.66 | 2 | 正方形 |
| 4 | -0.22 | 0.31 | 1.89 | 1.6 | 2 | 正方形 |
| 5 | 0.05 | 0.25 | 2.68 | 1.93 | 2 | 正方形 |
| 6 | 0.34 | -0.49 | 2.23 | 1.38 | 2 | 正方形 |
| 152 | 2.43 | 4.35 | 0.98 | 4.26 | 3 | 圆形 |
| 153 | 4.12 | 1.99 | 2.48 | 4.14 | 3 | 圆形 |
| 154 | 3.86 | 3.18 | 1.79 | 2.54 | 3 | 圆形 |
| 155 | 3.97 | 2.65 | 2.15 | 3.32 | 3 | 圆形 |
| 156 | 3.81 | 3.38 | 1.63 | 2.22 | 3 | 圆形 |
3.4 构建汽车运行工况
与数据预处理后的原始数据进行匹配,得到分类后的数据特征值,然后对第1类~第3类的数据进行总体描述,得到分类后的总体数据的特征值,见表 8。
| 序号 | 类别 | 特征值 | ||
| 第1类 | 第2类 | 第3类 | ||
| 1 | 怠速时间百分比 | 0.556 1 | 0.194 2 | 0.189 2 |
| 2 | 加速时间百分比 | 0.169 0 | 0.324 5 | 0.146 4 |
| 3 | 减速时间百分比 | 0.101 4 | 0.263 8 | 0.073 8 |
| 4 | 匀速时间百分比 | 0.173 3 | 0.217 6 | 0.590 6 |
| 5 | 最大加速度 | 3.138 9 | 3.333 3 | 3.333 3 |
| 6 | 最大减速度 | -4.194 4 | -2.219 0 | -2.058 3 |
| 7 | 平均加速度 | 0.865 9 | 0.913 0 | 1.744 6 |
| 8 | 平均减速度 | -0.241 3 | -0.676 2 | -0.129 8 |
| 9 | 加速度标准差 | 0.368 9 | 0.816 6 | 6.466 4 |
| 10 | 最大速度 | 1.430 6 | 3.333 3 | 3.333 3 |
| 11 | 平均速度 | 1.482 4 | 8.298 9 | 21.672 6 |
| 12 | 平均行驶速度 | 0.743 5 | 6.783 5 | 17.704 4 |
| 13 | 速度标准差 | 0.736 1 | 3.957 0 | 7.594 0 |
接着,运用Matlab软件编程计算出与总体特征矩阵的相关系数,汇总后得出表 9。
| 第1类 | ||||||
| 片段号 | 923 | 1 581 | 2 739 | 3 142 | 4 203 | 4 749 |
| 相关性 | 0.992 1 | 0.982 7 | 0.990 2 | 0.948 5 | 0.971 0 | 0.949 1 |
| 第2类 | ||||||
| 片段号 | 11 | 1 807 | 4 276 | 5 109 | — | — |
| 相关性 | 0.999 3 | 0.999 4 | 0.998 9 | 0.999 2 | — | — |
| 第3类 | ||||||
| 片段号 | 1 454 | 3 800 | 4 988 | 2 505 | 4 806 | — |
| 相关性 | 0.999 2 | 0.999 2 | 0.999 4 | 0.999 5 | 0.999 5 | — |
表 9表示随机选出的每类与总数特征值相关性较高的计算结果,没有按照降序排列,且在生成的结果中所有的相关性系数均大于0.5,这说明聚类分析较为正确,再次验证了分为3类是合理正确的。
3.5 绘制汽车运行工况由于第1类~第3类运动学片段的占比分别为55.76%,40.89%,3.35%。故选取了15个运动学片段,其中第1类情况中选取了6个运动学片段,第2类情况中选取了4个运动学片段,第3类情况中选取了5个运动学片段[18]。之所以选择较多片段,是因为这些运动学片段时间较短。选取的15个汽车运动学片段的情况见表 10。
| 运动学片段号 | 相关性系数 | 归属类别 |
| 923 | 0.992 123 | 1 |
| 1 581 | 0.982 749 | 1 |
| 2 739 | 0.990 217 | 1 |
| 3 142 | 0.948 562 | 1 |
| 4 203 | 0.971 025 | 1 |
| 4 749 | 0.949 083 | 1 |
| 11 | 0.999 301 | 2 |
| 1 807 | 0.999 407 | 2 |
| 4 276 | 0.998 913 | 2 |
| 5 109 | 0.999 238 | 2 |
| 1 454 | 0.999 234 | 3 |
| 3 800 | 0.999 191 | 3 |
| 4 988 | 0.999 362 | 3 |
| 2 505 | 0.999 477 | 3 |
| 4 806 | 0.999 450 | 3 |
选取的片段与总数特征值矩阵的相关性系数均为0.9以上,可以代表总体特征,相关性很强,以此绘制汽车运行工况可以起到很好的说明效果。
使用SPSS软件进行散点图的绘制,由于时间的间隔为1 s,将各个散点用直线连接起来就是车辆运行工况。图 13很好地反映了汽车走走停停、加速、减速、匀速、怠速的过程,可以有效地反映车辆运行工况。
通过计算误差率,形成拟合误差分析表(表 11),拟合运行工况的绝大多数特征参数都与原始数据的参数十分接近,在10%以内,只有个别参数的误差大于10%,但都小于20%。总体说明,构建出的汽车运行工况与实际工况很相近。

|
| 图 7 车辆运行工况 Fig. 7 vehicle operation condition |
| |
| 特征参数 | 原始样本数据 | 拟合样本数据 | 误差率/% |
| P0 | 0.313 2 | 0.288 3 | 7.95 |
| Pa | 0.213 3 | 0.223 4 | 4.74 |
| Pd | 0.146 3 | 0.157 5 | 7.66 |
| Pc | 0.327 2 | 0.330 8 | 1.10 |
| amax | 3.333 3 | 3.333 3 | 0 |
| amin | -2.194 4 | -2.194 4 | 0 |
| aa | 0.362 1 | 0.381 2 | 5.27 |
| ad | -0.471 3 | -0.513 0 | 8.85 |
| astd | 0.383 9 | 0.428 1 | 11.51 |
| Vmax | 3.333 3 | 3.333 3 | 0 |
| V | 8.593 2 | 8.823 4 | 2.68 |
| Vm | 8.112 0 | 7.149 3 | 11.87 |
| Vstd | 3.760 8 | 4.508 7 | 19.89 |
4 结论
本研究选取不同的方法对采集到的车辆的3段行驶数据进行预处理并进行运动学片段划分,从中选取13个特征参数以代表运动学片段的信息,并建立PCA和K-means模型对特征参数进行降维,将数据进行分组聚类。不断提取离聚类中心最近的(即相似度最高的)运动学片段以实现汽车运行工况的构建。最后将拟合工况的各个特征参数值与原始数据的工况参数值进行对比,误差较小,工况拟合效果很好。进而得到以下结论:
(1) 本研究的汽车运行工况构建方法可以有效地提取汽车行驶信息,有助于构建汽车运行工况,得到的汽车工况误差很小,优于学界大部分方法,对建立我国符合特定城市的交通状况及实际运乘条件的汽车性能与燃油排放控制的研究提供了一定的参考。
(2) 从最终拟合的运行工况不难看出,我国运行工况的怠速阶段时间明显高于欧美国家的工况,欧洲工况具有较少的怠速运行时间[19]。所以若用欧美国家[20-21]的汽车油耗量与污染物排放量的标准来制订我国的污染控制策略并不符合实际国情。建议结合自身情况,建立符合我国道路的汽车运行工况。
但由于时间的关系,没有尝试使用其他模型去拟合运行工况[22],后续可以尝试马尔可夫法、小波变化法、SOM神经网络模型等方法去改进现有的算法,这样有可能更有效地构建汽车运行工况,而目前采用的方法也可较为准确地构建汽车运行工况。
| [1] |
姜平, 石琴, 陈无畏, 等. 基于小波分析的城市道路行驶工况构建的研究[J]. 汽车工程, 2011, 33(1): 70-73. JIANG Ping, SHI Qin, CHEN Wu-wei, et al. A Research on the Construction of City Road Driving Cycle Based on Wavelet Analysis[J]. Automotive Engineering, 2011, 33(1): 70-73. |
| [2] |
GALGAMUWA U, PERERA L, BANDARA S. Developing a General Methodology for Driving Cycle Construction:Comparison of Various Established Driving Cycles in the World to Propose a General Approach[J]. Journal of Transportation Technologies, 2015, 5(4): 191-203. |
| [3] |
MINGYUE M, BENEDIKT W, FERIT K, et al. A Statistical Method for Driving Cycle Construction Based on Path Geometry[C]//Proceedings of 2013 the International Conference on Remote Sensing, Environment and Transportation Engineering. Nanjing: Atlantis Press, 2013: 890-893.
|
| [4] |
GAO X, ZHANG B, XIONG X, et al. Construction and Analysis of the Dalian Driving Cycle[J]. International Journal of Control & Automation, 2015, 8(6): 363-368. |
| [5] |
DIMARATOS A, TSOKOLIS D, FONTARAS G, et al. Comparative Evaluation of the Effect of Various Technologies on Light-duty Vehicle CO2, Emissions over NEDC and WLTP[J]. Transportation Research Procedia, 2016, 14: 3169-3178. |
| [6] |
PREVEDOUROS P D, MITROPOULOS L K. Life Cycle Emissions and Cost Study of Light Duty Vehicles[J]. Transportation Research Procedia, 2016, 15: 749-760. |
| [7] |
DEMUYNCK J, BOSTEELS D, DE PAEPE M, et al. Recommendations for the New WLTP Cycle Based on an Analysis of Vehicle Emission Measurements on NEDC and CADC[J]. Energy Policy, 2012, 49: 234-242. |
| [8] |
FOTOUHI A, MONTAZERI-GH M. Tehran Driving Cycle Development Using the K-means Clustering Method[J]. Scientia Iranica, 2013, 20(2): 286-293. |
| [9] |
彭育辉, 杨辉宝, 李孟良, 等. 基于K-均值聚类分析的城市道路汽车行驶工况构建方法研究[J]. 汽车技术, 2017(11): 13-18. PENG Yu-hui, YANG Hui-bao, LI Meng-liang, et al. Research on the Construction Method of Driving Cycle for the City Car Based on K-means Cluster Analysis[J]. Automobile Technology, 2017(11): 13-18. |
| [10] |
胡宸, 吴晓刚, 李晓军, 等. 哈尔滨城市公交工况的构建[J]. 哈尔滨理工大学学报, 2014, 19(1): 85-89. HU Chen, WU Xiao-gang, LI Xiao-jun, et al. Construction of Harbin City Driving Cycle[J]. Journal of Harbin University of Science and Technology, 2014, 19(1): 85-89. |
| [11] |
胡志远, 秦艳, 谭丕强, 等. 基于大样本的上海市乘用车行驶工况构建[J]. 同济大学学报:自然科学版, 2015, 43(10): 1523-1527. HU Zhi-yuan, QIN Yan, TAN Pi-qiang, et al. Large-sample-based Car-driving Cycle in Shanghai City[J]. Journal of Tongji University:Natural Science Edition, 2015, 43(10): 1523-1527. |
| [12] |
石琴, 仇多洋, 周洁瑜. 基于组合聚类法的行驶工况构建与精度分析\[J]. 汽车工程, 2012, 34(2): 164-169. SHI Qin, QIU Duo-yang, ZHOU Jie-yu. Driving Cycle Construction and Accuracy Analysis Based on Combined Clustering Technique[J]. Automotive Engineering, 2012, 34(2): 164-169. |
| [13] |
郑殿宇, 吴晓刚, 陈汉, 等. 哈尔滨城区乘用车行驶工况的构建[J]. 公路交通科技, 2017, 34(4): 101-107. ZHENG Dian-yu, WU Xiao-gang, CHEN Han, et al. Construction of Driving Conditions of Harbin Urban Passenger Cars[J]. Journal of Highway and Transportation Research and Development, 2017, 34(4): 101-107. |
| [14] |
张广昕, 孙晋伟, 张传桢, 等. 机动车污染物排放影响因素及控制措施研究[J]. 交通节能与环保, 2013(2): 51-55. ZHANG Guang-xin, SUN Jin-wei, ZHANG Chuan-zhen, et al. Research on Motor Vehicle Emission Factors and Control Measures[J]. Energy Conservation & Environmental Protection in Transportation, 2013(2): 51-55. |
| [15] |
LIN J, NIEMEIER D A. An Exploratory Analysis Comparing a Stochastic Driving Cycle to California's Regulatory Cycle[J]. Atmospheric Environment, 2002, 36(38): 5759-5770. |
| [16] |
KARANDE S. OLSON M, SAHA B. Development of Representative Vehicle Drive Cycles for Hybrid Applications[EB/OL]. (2014-04-01)[2019-05-06]. https://www.sae.org/publications/technical-papers/content/2014-01-1900/.
|
| [17] |
李宁.城市道路车辆行驶工况的构建与研究[D].武汉: 武汉理工大学, 2005. LI Ning. Construction and Research on Driving Conditions of Urban Road Vehicles[D]. Wuhan: Wuhan University of Technology, 2005. |
| [18] |
李洋.基于聚类算法的汽车行驶工况研究[D].北京: 北京理工大学, 2016. LI Yang. Research on Vehicle Driving Conditions Based on Clustering Algorithm[D]. Beijing: Beijing University of Technology, 2016. |
| [19] |
KNEZ M, MUNEER T, JEREB B, et al. The Estimation of a Driving Cycle for Celje and a Comparison to Other European Cities[J]. Sustainable Cities and Society, 2014, 11: 56-60. |
| [20] |
HO S H, WONG Y D, CHANG V W C. Developing Singapore Driving Cycle for Passenger Cars to Estimate Fuel Consumption and Vehicular Emissions[J]. Atmospheric Environment, 2014, 97: 353-362. |
| [21] |
姜平.城市混合道路行驶工况的构建研究[D].合肥: 合肥工业大学, 2011. JIANG Ping. Research on Construction of Urban Mixed Road Driving Conditions[D]. Hefei: Hefei University of Technology, 2011. |
| [22] |
周记国, 张敏江, 薛晓锋. 基于流固耦合的行车临界风速研究[J]. 公路交通科技, 2019, 36(3): 144-151. ZHOU Ji-guo, ZHANG Min-jiang, XUE Xiao-feng. Analysis on Critical Wind Speed for Driving Based on Fluid-solid Coupling[J]. Journal of Highway and Transportation Research and Development, 2019, 36(3): 144-151. |