


遥感影像重点目标的检测和识别是遥感影像智能解译的重要研究方向,具有重要的应用价值[1]。在诸多地物目标中,飞机作为一种重要的运输载体和武器装备,其在遥感影像上的快速检测和识别具有重要的现实意义。由于遥感影像背景复杂,大范围遥感影像的飞机目标自动化检测和识别还没有得到很好的解决。
传统的飞机目标识别算法多是利用目标在影像上的不变矩特征[2-3]、颜色和纹理特征[4-5]、轮廓和结构特征[6-9]、词袋特征[10-11]等,这些特征稳健性较差,并且特征的提取通常在较为准确的影像分割或轮廓提取的前提下进行,极易受影像质量和人工建筑等地物的影响:当影像质量较差或飞机周围背景复杂时,会直接导致影像欠分割或过分割,从而难以提取有效的特征,影响后续目标检测与识别的精度。此外,这些方法通常采用滑动窗口[4, 10]、图像分割[2, 7, 9]或者视觉显著性检测[12-14]来搜索目标,滑动窗口法存在大量冗余窗口,针对性差、耗时长,而图像分割法和视觉显著性检测易受到其他地物干扰,难以适用于大范围场景下的飞机目标搜索。
近年来,深度学习特别是卷积神经网络(convolutional neural network, CNN)在计算机视觉领域取得了巨大进展,并广泛应用于人脸识别和自动驾驶等领域,将卷积神经网络应用于遥感影像目标检测和识别任务中,能够显著提高地物目标检测的实效性。目前基于卷积神经网络的遥感影像目标检测方法主要有两种思路,一种是采取滑动窗口或显著性检测先对影像进行无监督搜索,然后利用卷积神经网络对候选窗口提取特征并分类,最终实现目标的识别[15-17]。相比采用传统特征的方法,这种方法可以提高目标检测和识别的精度,但在候选目标选取过程中,同样避免不了检测耗时和泛化性差的问题。另一种是对Faster RCNN(以下均简写为FRCNN)[18]、YOLO[19]等自然场景下较为成熟的目标检测算法加以改进,应用于遥感影像目标识别[1, 20-23],这种方法速度快,精度也得到大幅提升,但要实现大范围、多尺度和复杂背景下飞机目标的高精度检测仍有一定难度。直接将自然场景下的目标检测算法应用于遥感影像目标检测任务中,必须考虑以下问题:①相对于自然场景影像,遥感影像具有一定的特殊性[15],如影像质量受成像条件影响较大、背景复杂、空间范围广、分辨率低、目标小且分散、目标呈多方向性等特点;②高精度卷积神经网络普遍具有数十层甚至上百层[24-25],巨大的存储和计算开销依赖于高性能的硬件设备,不仅难以有效处理大幅遥感影像,还严重限制了在可移动设备(如无人机等)上的应用;③深层卷积神经网络模型含有大量参数,训练需要大量的标注数据,训练过程复杂且耗时,在数据较少情况下难以达到理想的检测效果;④基于深度学习的目标检测算法针对常规自然场景影像而设计,算法的泛化性依赖于训练数据集,并且受限硬件设备的计算能力,这些算法通常是针对固定大小的图像进行训练和检测[20-23],如FRCNN等算法只能处理大小约为1000像素的图像,YOLO算法需要将待检测图像统一缩放至448×448像素,SSD300[26]需要将图像缩放至300×300像素,当输入图像较大时,必须更改网络结构或对大幅影像进行切分,这显然不能满足遥感影像目标检测的通用性以及尺度自适应性。
针对上述问题,本文提出了一种基于多尺度级联卷积神经网络的遥感影像飞机目标检测方法,利用小尺度浅层全卷积神经网络实现大幅影像的快速遍历和目标搜索,利用较深层卷积神经网络对候选目标进行级联分类和精确定位。浅层全卷积神经网络能够支持任意大小的图像输入,并且具有极强的速度优势,多个卷积神经网络的级联判断机制可以弥补单个神经网络在精度上的缺点,使得本文方法速度更快、精度更高,并且更利于在可移动设备上的移植和应用。
1 理论背景与方法遥感影像目标检测的难点在于,大幅影像上目标搜索带来的巨大计算量和多尺度目标特别是小目标难以准确检测,虽然FRCNN、SSD等算法针对多尺度目标检测问题采用了融合不同尺度的特征以及预设先验框等方式,但这远远不能有效应对大范围多尺度的遥感影像。深层卷积神经网络在大幅影像上的计算量较大,并且小目标经过多层卷积与池化,难以提取到有效特征,漏检率较高,这种漏检在后处理很难得到弥补。采取级联分类思想在一定程度上可以提高大幅影像目标搜索的效率和目标检测的精度:先利用小型卷积神经网络在影像上进行初步目标检测,快速获取所有可能的区域作为候选目标,再将候选区域映射到高分辨率影像上,利用更高精度的卷积神经网络进行目标类别和位置级联确定,从而最大程度降低虚警率,保留真正目标。级联分类的思想最早应用于人脸检测和识别[27]。文献[28]设计了级联卷积神经网络用于人脸识别,文献[29]设计多任务级联卷积神经网络模型(multi-task cascaded convolutional neural networks, MTCNN)用于人脸检测和关键点定位。MTCNN模型摒弃了常规依靠增加卷积神经网络深度来提高人脸检测精度的做法,而采用多个小尺度卷积神经网络以级联的方式实现人脸检测,模型具有稳健性强、轻量化、可实时等特点。此外,MTCNN采用浅层全卷积神经网络对影像进行目标搜索,能够支持输入任意大小的图像,这为大幅遥感影像的目标搜索和检测问题提供了一个快速高效的解决方案。由于遥感影像上的飞机目标具有多方向性且背景复杂多样等特点,本文以MTCNN模型为基础,通过对其网络结构进行优化,并设计了相应的样本选取和模型训练方法,可有效降低模型的虚警率,提升检测效果。
1.1 级联卷积神经网络MTCNN模型由3个不同尺度的小型卷积神经网络组成,如图 1所示,分别为PNet、RNet和ONet。PNet为区域建议网络,用来生成候选目标。PNet是一个浅层的全卷积网络,包含3个卷积层和1个池化层,输入图像大小为12×12像素。由于全卷积神经网络不含全连接层,可以满足任意大小的图像输入,因此可以实现大范围遥感影像的目标搜索。PNet本质上是一种利用GPU加速的滑动窗口法,在选取候选窗口的同时对每个候选窗口进行分类判断。相对于传统滑动窗口法,可以极大减少耗时。与PNet结构相似,RNet和ONet输入图像大小分别为24×24像素、48×48像素,网络结构更深,用于对PNet输出的候选目标进行级联判断,能够实现更为精确的目标分类和定位。

|
| 图 1 MTCNN模型结构 Fig. 1 The structure of MTCNN |
通过试验发现,直接利用MTCNN模型检测飞机目标,存在的大量误检目标。误检目标主要为长条形车辆、人工建筑物等,笔者将这类与飞机目标在形状、纹理、颜色等方面具有极大相似性、易被误识别的地物称难分负样本(hard negative example)。检测过程中出现误检测的主要原因有:①地物种类复杂多样,而训练样本不均衡,负样本种类和数量远远大于正样本,但大多数的负样本为易分样本,如空地、草地等。大量易分样本的存在将会在训练过程中稀释反向传播的梯度,导致模型无法有效排除建筑物、车辆等更复杂的人工地物。②小型化卷积神经网络结构在较少参数和不均衡训练数据的情况下必然导致难以有效区分难分负样本。③不同于自然场景下的人脸,遥感影像为俯视图,飞机呈多方向旋转,其表观特征变化较大,浅层网络难以准确识别。
原始的MTCNN模型采用小型、浅层的常规卷积神经网络结构,虽然计算速度较快,但其网络结构简单,卷积层所提取的特征信息表达能力不够。此外,RNet和ONet在卷积层之后用于分类的全连接层参数多,模型易过拟合,导致泛化能力降低。加深网络虽然可以在一定程度上提高其性能,但其参数将大大增加,同时其模型检测速度也将显著降低,而对网络结构上的优化将有助于提升模型的整体性能。传统卷积操作是对数据的广义线性变换,对数据特征的抽象化水平较低。文献[30]提出了一种更高效的卷积方式,即在卷积神经网络结构中大量使用大小为1×1的卷积,如图 2所示,不仅能够得到抽象性更高、泛化能力更强的特征,还能起到数据降维的作用,这种卷积方式已广泛应用于各种主流的卷积神经网络结构之中。此外,采用全局池化替代传统CNN中的全连接层,可以减少网络参数并降低过拟合的可能。

|
| 图 2 改进的卷积层结构 Fig. 2 Improved convolutional layer |
因此,本文在原始MTCNN模型的部分卷积层之后加入非线性多层感知器,并去除全连接层,以提高模型的性能,改进后的级联卷积神经网络模型如图 3所示。由于PNet是用于兴趣区域的生成,网络输入的图像较小(12×12像素),即使增加网络的复杂度也难以提高精度,反而会降低整个模型的速度和效率,因此保留原始PNet结构,而在对RNet和ONet的每个卷积层之后加入一个1×1卷积层,并除去最后的全连接层。

|
| 图 3 改进的级联卷积神经网络结构 Fig. 3 Improve MTCNN |
每个子网络同时包含目标分类和边界回归两个任务,其多任务损失函数为
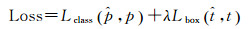 (1)
(1)
式中,λ取值5;pi∈{0, 1}表示样本i的真实类别,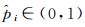
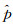
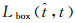
 (2)
(2)
 (3)
(3)
式中, ti=(xi, yi, wi, hi)用来描述目标在图像中的真实位置(边界框的左上角点坐标、宽度和高度); 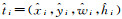
为了增加训练数据的数量和多样性,将训练样本划分为4种类别:正样本、负样本、部分正样本及难分负样本。正样本和负样本用于优化模型的分类损失函数,正样本和部分正样本用于优化模型的边界回归损失函数。正样本、负样本和部分正样本的划分根据交并比(intersection-over-union,IOU)的大小来确定。IOU是目标检测任务中用来衡量定位精度的概念,采用所预测的候选框与真实标注框面积的交集与并集的比值,计算公式为
 (4)
(4)
式中,gt、dt分别为目标真实的边界框和预测边界框。训练样本的选取采取滑动窗口法,即对训练影像建立金字塔,采用一定大小的滑动窗口选取影像上的区域, 如图 4所示,并计算选择的区域与标注边界框的IOU,IOU大于0.7的区域标记为正样本, 小于0.3的区域标记为负样本,介于0.5和0.7之间的区域作为部分正样本。由于卷积神经网络提取的特征具有抽象性,难分负样本的判断和选取难以采用人工选取的方式,而由MTCNN模型检测结果中的误检目标组成, 见1.3节。

|
| 图 4 训练样本的选取 Fig. 4 Samples for training |
1.3 训练与检测
为了尽可能利用有限的标注数据提高模型的泛化性能,将训练过程分为预训练和离线难分样本训练两个步骤,如图 5所示。在预训练阶段,采用在线难分样本挖掘[31](online hard example mining, OHEM)的策略,即在训练过程中,对每一个批量的数据计算得到的前向传播损失排序,将损失最大的一定比例的样本作为难分样本;在反向传播的过程中,只利用难分样本的损失对神经网络模型的权重进行更新。由于遥感影像背景范围广、种类多样,选取的样本中真正的难分负样本数量较少,因此在预训练阶段,将在线难分样本的比例设置为40%。利用预训练好的MTCNN模型对不同尺度的训练影像进行检测,此时模型能够有效区分简单背景与飞机目标,将获得的检测结果结合标注信息,除去真正的飞机目标,即可获得大量的误检目标,这些误检的目标即为难分负样本。OHEM策略的依据是训练样本包含了数量充足、种类丰富的负样本和正样本,在卷积神经网络的反向传播过程中忽略部分易分样本的梯度。在没有人工干预的情况下,选取的样本绝大多数为简单易分样本,大量易分样本的存在导致模型在检测过程中不能有效区分难分负样本,这是导致虚警和误检的主要原因,将难分负样本加入到训练数据中可以降低检测的虚警率和误检率。因此,在离线难分样本训练阶段,针对不同尺度的网络模型,对选取的正样本、负样本和部分正样本均分别缩放至12×12像素和24×24像素,分别训练PNet和改进的RNet;将获得的难分负样本与正样本、部分正样本缩放至48×48像素重新训练改进的ONet。

|
| 图 5 训练过程 Fig. 5 Flowchart of training |
检测过程采取级联检测,如图 6所示,对影像建立金字塔,利用PNet对每一级影像检测来获取候选窗口。PNet本质上是一种GPU加速的滑动窗口法,PNet在每一级影像上滑动的同时,并判断该窗口属于飞机目标的概率,从而形成该级影像的概率图;以概率大于0.5的像素为中心,选取大小为12×12像素的区域作为候选窗口。将每一级影像获取的候选窗口映射到原始影像上,获得目标切片,并利用RNet进行分类和边界回归;此后,再将满足一定阈值的窗口再次利用ONet进行分类和边界回归,从而得到最终的检测结果。候选窗口选取过程中将产生大量重叠窗口,因此检测过程中采取非极大值抑制(non-maximum suppression, NMS)的策略减少窗口冗余。

|
| 图 6 检测流程 Fig. 6 Flowchart of detection on test image |
2 试验与分析 2.1 试验数据与环境
本文采用4个不同数据集中的影像进行试验:UCAS-AOD[32]、RSOD[15]、DOTA[33]和自建数据集,分别记为数据集A-D,不同数据集的基本信息和示例分别如表 1和图 7所示。UCAS-AOD和RSOD数据集的影像均为小范围机场区域切片,其中UCAS-AOD数据集中影像重复率较大,飞机目标尺寸较大,背景及其他人工地物干扰较小;RSOD数据集影像具有一定倾角,成像质量较差,且存在大量的密集小目标;DOTA和自建数据集均选取能够覆盖整个机场的大范围遥感影像。利用数据集A中70%的影像训练,共选取正样本30 000个,部分正样本30 000个,负样本90 000个;其余影像作为测试数据,以检验模型对不同分辨率、大小、质量影像的泛化性和实用性。计算机配置i7-6900K, 3.2 GHz, 64 GB内存,NVIDIA GTX1080TI,11 GB显存,试验环境为Ubuntu16.04和TensorFlow。
| 数据集 | 数据来源 | 影像分辨率 | 影像大小/像素 | 影像数量 | 飞机数量 | 用途 |
| A | UCAS-AOD | 不详 | 1280×659-1372×940 | 1000 | 7482 | 70%训练,30%测试 |
| B | RSOD | 0.5-2.0 m | 1024×768-1044×915 | 446 | 5374 | 测试 |
| C | DOTA | 0.2-0.6 m | 2000×2000-8000×8000 | 18 | 1605 | 测试 |
| D | 自建数据集 | 1.2-2.4 m | 1500×1500-4000×4000 | 10 | 643 | 测试 |

|
| 图 7 不同数据集下的影像示例 Fig. 7 Samples of four datasets |
采用精确率(precision)和召回率(recall)作为评价指标,计算公式为
 (5)
(5)
 (6)
(6)
式中,TP为正确识别飞机目标数量;FP为影像中误检目标数量;FN为漏检目标数量。
2.2 结果与分析为验证本文所设计的级联卷积神经网络模型与训练方式的有效性,利用相同的训练和测试数据,对比了5种基于卷积神经网络的目标检测方法:SSD300、YOLOv2[34]、FRCNN、RetinaNet[35]和未作改进的MTCNN方法。SSD300采用VGG16[24]作为骨干网络,YOLOv2、FRCNN和RetinaNet采用ResNet50[25]作为骨干网络。MTCNN和本文方法均能检测任意大小的影像,而FRCNN等算法不能直接检测很大的图像,因此利用FRCNN等算法检测数据集C和D时,分别采取512×512像素和1024×1024像素两种切分方式。
2.2.1 检测效果分析利用5种算法对4个数据中的影像进行检测,并根据检测结果中的精确率和召回率绘制PR(precision-recall)曲线,如图 8所示。综合4种数据集的检测结果来看,SSD300性能最差,其原因主要有:①训练数据来自数据集A,数据集A的影像大小为1280×659-1372×940像素,训练SSD300时,图像缩放过于剧烈,严重影响模型训练和检测效果;②本文采取数据集A中的部分影像作为训练集,去测试其余3个数据集,不同数据集的影像在大小、分辨率差异较大,导致检测结果下降;③SSD300采用的是VGG16模型作为骨干网络,VGG16本身模型泛化性较差。YOLOv2输入图像大小为448×448像素,对分辨率较低的数据集A和数据集B同样难以有较大的精度提升;对于数据集C和数据集D中的影像,切分为512×512像素大小时,能够取得80%以上的检测精度,当切分方式为1024×1024像素大小时,检测精度剧烈下降。SSD300和YOLOv2检测精度均弱于FRCNN和RetinaNet,这是其模型设计所决定的,端对端的检测方式提高了检测速度,但牺牲了精度,特别是弱化了对小目标的检测能力。在不同数据集下,FRCNN和RetinaNet算法能够取得相对不错的检测效果,且RetinaNet优于FRCNN。FRCNN和RetinaNet精度较高主要是由于采用区域建议的思想,并且采取训练图像大小为1200×600像素,当被检测影像和训练影像的分辨率相接近时(数据集C和数据集D中1024×1024像素的切分方式),可以取得不错的检测结果,当被检测影像的分辨率提高时(数据集C和数据集D中512×512像素的切分方式),精度还能进一步提升。原始的MTCNN方法在不做任何改进的情况下,在4种数据集中均能够取得高于FRCNN的精度,表明级联卷积神经网络得益于能够对整幅影像进行多尺度遍历和搜索,具有天然的精度优势。本文方法进一步提升了MTCNN方法的精度,特别是提高了对数据集B中质量较差的影像和密集小目标的检测精度,除在数据集A中精度稍弱于RetinaNet,在其余数据集上明显优于RetinaNet。

|
| 注:map表示平均精度。 图 8 不同方法在4种数据集下的PR曲线 Fig. 8 Precision-Recall of different methods on four datasets |
为对比本文方法的改进效果,选取了4幅包含大量飞机目标的测试影像,测试影像中的目标具有小而密集分布、目标与背景的区分度较差等特点,检测效果如图 9所示,其中绿色、红色、黄色方框分别代表正确检测、漏检和误检的飞机。原始的MTCNN存在较多的虚警和误检,过多的误检目标造成视觉上的干扰,几乎无法用于实际应用,而本文方法采用了更高效的卷积神经网络结构和训练方式,提高了模型对目标的特征表达和识别能力,在不同背景和影像质量下均能取得较好的检测效果。但同时也发现,不管采取哪种方法,对于小于16×16像素的目标,仍然还难以有效检测,这是所有方法在数据集B上精度较低的主要原因。图 10为大幅遥感影像的检测结果,可以看出,飞机目标相对整个影像较小,同一幅影像上的目标具有尺度、方向上的多样性,地物类型更加多样和复杂,本文方法在大幅影像上具有优异的检测性能,对目标的尺度变化、旋转等情况下具有较强的稳健性。

|
| 图 9 数据集A和B下的检测结果 Fig. 9 Aircraft detection results on dataset A and B |

|
| 图 10 本文方法在大幅影像上的飞机目标检测结果 Fig. 10 Aircraft detection results on large images |
2.2.2 模型轻量化分析
目前,高精度的目标检测和识别算法通常依赖于深层卷积神经网络,当网络加深时,模型参数和计算量将显著增加,对硬件设备的依赖程度也随之增加。虽然对卷积神经网络模型小型化和轻量化的探索已有巨大的进展,如MobileNet[36]、ShuffleNet[37]等,但轻量化模型通常难以达到深层卷积神经网络模型的精度。由不同卷积神经网络目标检测算法的模型参数大小(如表 2所示)可以看出,深层卷积神经网络模型动辄数百兆(MB),级联小型卷积神经网络有着天然的轻量化优势,这意味着更加快速高效地处理影像以及在可移动平台上的应用。由于卷积神经网络的层数极大地影响其运行速度,在不增加网络层数的情况下,单纯靠增加卷积层参数数量的方式不仅难以实现精度上的显著提升,还大大增加了模型整体的参数量。本文方法对RNet和ONet采取了更高效的卷积结构和训练方式,大大提升模型的性能,在能够提高模型精度的同时,也减小了模型的参数,从而在一定程度上大大降低了对硬件设备的依赖程度。
| MB | |
| 模型 | 模型大小 |
| FRCNN(ResNet50) | 208 |
| SSD300(VGG16) | 267 |
| RetinaNet(ResNet50) | 257 |
| YOLOv2(ResNet50) | 379 |
| MTCNN | 3.9 |
| 本文方法 | 2.7 |
| 注:模型大小为模型参数所保存的字节数,加粗数字表示本列最优值,加横线数字表示本列次优值。 | |
为比较不同方法检测单张影像的用时,采取了1280×900像素和10 000×4000像素两种大小的影像进行测试,不同方法用时统计如表 3所示。RetinaNet和YOLOv2分别是目前公认的高精度和快速的目标检测方法,在相同硬件设备的情况下,检测速度依然慢于采用级联卷积神经网络的方法。为了能够检测到未知分辨率影像上不同大小的目标,本文方法在检测过程中,采取建立影像金字塔,对不同尺度上的影像进行检测,这实际上是一种耗时的检测方式,但依然可以在1280×900像素大小的影像上实现接近实时的检测速度。对于大场景影像(10 000×4000像素)的目标检测来说,本文方法的速度优势更加明显:MTCNN每一子模型存在较多的误判,且子模型的复杂度依次增加,检测同一切片的用时也是依次递增,这大大增加了目标在级联判断的数量和用时;本文方法模型性能更加高效,虚警目标更少,大大节省了目标识别的用时,将单张大幅影像的检测时间降低了27.05%(从2.625 s降低至1.915 s)。此外,如若在获知影像分辨率的情况下,有针对性地减少影像金字塔的冗余层级,检测速度将进一步提升。
| s | ||
| 模型 | 用时 | |
| 1280×900 | 10000×4000 | |
| FRCNN(ResNet50) | 1.873 | N/A |
| RetinaNet(ResNet50) | 0.131 | N/A |
| YOLOv2(ResNet50) | 0.062 | N/A |
| MTCNN | 0.041 | 2.625 |
| 本文方法 | 0.045 | 1.915 |
| 注:N/A表示不能直接检测大幅影像,加粗数字表示本列最优值,加横线数字表示本列次优值。 | ||
2.2.3 模型迁移检测结果
为了测试本文方法对不同类型飞机目标检测的效果,选取戴蒙斯空军基地两个区域的影像进行测试,测试区域共包含1389架密集分布、形状完整的军用飞机(战斗机、轰炸机、运输机等)。由图 11可知,军用飞机形状各异,人工设计的特征往往不具有较强稳健性。本文训练数据(UCAS-AOD)均为民用客机影像,而军用飞机与客机在形状上具有一定的相似性,卷积神经网络模型具有优异的特征提取能力,因此将客机样本训练好的模型,直接用于军用飞机的检测。部分检测结果如图 12所示,其中绿色、红色、黄色方框分别代表正确检测、漏检和误检的飞机。本文方法正确检测1309个,误检14个,漏检80个,精确率为98.94%,召回率为94.24%,而其中漏检的目标大多数因为目标排列过于密集,在非极大值抑制过程中两个飞机目标被认为是同一个目标。对军用飞机的检测结果验证了本文方法具有较强的泛化性和实用性,不仅可以用于民用飞机目标检测,还可以在军用飞机类型识别任务中,用于候选目标的选取。

|
| 图 11 不同种类的飞机示例 Fig. 11 Different types of aircraft |

|
| 图 12 军用飞机检测结果 Fig. 12 Military aircraft detection results |
3 结论
针对大范围区域、复杂背景下遥感影像飞机目标检测的准确性和实时性较低的问题,本文根据常规卷积神经网络目标检测算法的局限性和遥感影像目标检测任务的特殊性,提出了一种基于级联卷积神经网络的飞机目标检测方法,显著提高了模型对复杂地物的辨识能力。通过在不同的数据集上对比分析了目前部分主流目标检测算法,可以得出以下结论:①深层卷积神经网络的目标检测能力依赖于测试影像与训练影像的一致性程度,测试数据与训练数据在影像质量、大小及分辨率等方面差异较大时,模型泛化性将显著降低;②深层卷积神经网络目标检测算法对遥感影像上密集小目标检测精度较低,处理大幅影像也必须进行切分,这种切分必然破坏目标与影像的相对大小关系,也将影响检测的精度,同时增加了后处理的复杂度;③本文采用的多尺度级联卷积神经网络不仅具有更高的精度,而且可以支持大幅影像的目标检测,检测过程中采用金字塔多级检测的方式,在一定程度上解决了大幅遥感影像、多尺度飞机目标检测的问题。需要说明的是,深层卷积神经网络是致力于解决多类目标(数十类甚至数百类)的检测问题,尽管仅从单类目标的检测精度、参数量多少和运行速度来对比深层卷积神经网络与级联浅层卷积神经网络模型有失偏颇,但仍能从一个侧面反映出针对特定任务或领域的目标识别问题,级联浅层卷积神经网络模型更简单、参数更少、速度更快,在移动平台的可移植性更强,具有不可忽视的优势。
目前,卷积神经网络模型在自动驾驶和人脸识别等领域应用虽然已经较为成熟,但由于深层卷积神经的自身局限性和遥感影像的特殊性,探索能够兼顾速度与精度、适用于遥感影像多类地物目标,特别是密集小目标的检测方法仍然任重而道远。在后续工作中,将研究更为高效的卷积神经网络结构和目标检测的新方法,提高检测器对地物目标的泛化能力,以期实现大幅遥感影像上更多类别目标的自动化检测和识别。
| [1] |
邓志鹏, 孙浩, 雷琳, 等.
基于多尺度形变特征卷积网络的高分辨率遥感影像目标检测[J]. 测绘学报, 2018, 47(9): 1216–1227.
DENG Zhipeng, SUN Hao, LEI Lin, et al. Object detection in remote sensing imagery with multi-scale deformable convolutional networks[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(9): 1216–1227. DOI:10.11947/j.AGCS.2018.20170595 |
| [2] |
曾接贤, 付俊, 符祥.
特征点和不变矩结合的遥感图像飞机目标识别[J]. 中国图象图形学报, 2014, 19(4): 592–602.
ZENG Jiexian, FU Jun, FU Xiang. Aircraft target recognition in remote sensing images based on distribution of the feature points and invariant moments[J]. Journal of Image and Graphics, 2014, 19(4): 592–602. |
| [3] | HSIEH J W, CHEN J M, CHUANG C H, et al. Aircraft type recognition in satellite images[J]. IEE Proceedings-Vision, Image and Signal Processing, 2005, 152(3): 307–315. DOI:10.1049/ip-vis:20049020 |
| [4] | ZHAO An, FU Kun, SUN Hao, et al. An effective method based on ACF for aircraft detection in remote sensing images[J]. IEEE Geoscience and Remote Sensing Letters, 2017, 14(5): 744–748. DOI:10.1109/LGRS.2017.2677954 |
| [5] | LEI Zhen, FANG Tao, HUO Hong, et al. Rotation-invariant object detection of remotely sensed images based on texton forest and Hough voting[J]. IEEE Transactions on Geoscience and Remote Sensing, 2012, 50(4): 1206–1217. DOI:10.1109/TGRS.2011.2166966 |
| [6] |
王树国, 黄勇杰, 张生.
可见光图像中飞机目标的特征选择及提取[J]. 哈尔滨工业大学学报, 2010, 42(7): 1056–1059.
WANG Shuguo, HUANG Yongjie, ZHANG Sheng. Selection and extraction of features of aircraft in optical image[J]. Journal of Harbin Institute of Technology, 2010, 42(7): 1056–1059. |
| [7] |
王文胜.宽幅光学遥感图像舰船飞机目标检测识别技术研究[D].长春: 中国科学院大学(中国科学院长春光学精密机械与物理研究所), 2018. WANG Wensheng. Research on technology of ship and aircraft targets recognition from large-field optical remote sensing image[D]. Changchun: Changchun Institute of Optics, Fine Mechanics and Physics, Chinese Academy of Sciences, 2018. |
| [8] | WANG Wensheng, NIE Ting, FU Tianjiao, et al. A novel method of aircraft detection based on high-resolution panchromatic optical remote sensing images[J]. Sensors, 2017, 17(5): 1047. DOI:10.3390/s17051047 |
| [9] | LI Yu, SUN Xian, WANG Hongqi, et al. Automatic target detection in high-resolution remote sensing images using a contour-based spatial model[J]. IEEE Geoscience and Remote Sensing Letters, 2012, 9(5): 886–890. DOI:10.1109/LGRS.2012.2183337 |
| [10] | SUN Hao, SUN Xian, WANG Hongqi, et al. Automatic target detection in high-resolution remote sensing images using spatial sparse coding bag-of-words model[J]. IEEE Geoscience and Remote Sensing Letters, 2012, 9(1): 109–113. DOI:10.1109/LGRS.2011.2161569 |
| [11] | BAI Xiao, ZHANG Huigang, ZHOU Jun. VHR object detection based on structural feature extraction and query expansion[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 52(10): 6508–6520. DOI:10.1109/TGRS.2013.2296782 |
| [12] |
岳伍军.基于光学遥感图像的飞机目标检测算法研究[D].成都: 西南交通大学, 2014. YUE Wujun. Research on airplane and target detection algorithms in optical remote sensing imagery[D]. Chengdu: Southwest Jiaotong University, 2014. http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y2576284 |
| [13] |
吴喆, 曾接贤, 高琪琪.
显著图和多特征结合的遥感图像飞机目标识别[J]. 中国图象图形学报, 2017, 22(4): 532–541.
WU Zhe, ZENG Jiexian, GAO Qiqi. Aircraft target recognition in remote sensing images based on saliency images and multi-feature combination[J]. Journal of Image and Graphics, 2017, 22(4): 532–541. |
| [14] | ZHANG Libao, ZHANG Yingying. Airport detection and aircraft recognition based on two-layer saliency model in high spatial resolution remote-sensing images[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 10(4): 1511–1524. DOI:10.1109/JSTARS.2016.2620900 |
| [15] | LONG Yang, GONG Yiping, XIAO Zhifeng, et al. Accurate object localization in remote sensing images based on convolutional neural networks[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(5): 2486–2498. DOI:10.1109/TGRS.2016.2645610 |
| [16] |
姚相坤, 万里红, 霍宏, 等.
基于多结构卷积神经网络的高分遥感影像飞机目标检测[J]. 计算机工程, 2017, 43(1): 259–267.
YAO Xiangkun, WAN Lihong, HUO Hong, et al. Airplane object detection in high resolution remote sensing imagery based on multi-structure convolutional neural network[J]. Computer Engineering, 2017, 43(1): 259–267. DOI:10.3969/j.issn.1000-3428.2017.01.045 |
| [17] |
刘欢.基于高分辨率光学遥感影像的特定目标检测算法研究[D].哈尔滨: 哈尔滨工业大学, 2017. LIU Huan. Research on detection algorithm for specific objects in high-resolution optical remote sensing images[D]. Harbin: Harbin Institute of Technology, 2017. http://cdmd.cnki.com.cn/Article/CDMD-10213-1017738880.htm |
| [18] | REN Shaoqing, HE Kaiming, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proceedings of the 28th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2015: 91-99. |
| [19] | REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 779-788. https://www.researchgate.net/publication/278049038_You_Only_Look_Once_Unified_Real-Time_Object_Detection |
| [20] |
洪韬.基于光学遥感影像的特定目标检测及识别[D].成都: 电子科技大学, 2018. HONG Tao. Specific object detection and recognition in optical remote sensing image[D]. Chengdu: University of Electronic Science and Technology of China, 2018. Www.ncbi.nlm.nih.gov/pmc/tools/stylechecker/ |
| [21] |
辛鹏, 许悦雷, 唐红, 等.
全卷积网络多层特征融合的飞机快速检测[J]. 光学学报, 2018, 38(3): 0315003.
XIN Peng, XU Yuelei, TANG Hong, et al. Fast airplane detection based on multi-layer feature fusion of fully convolutional networks[J]. Acta Optica Sinica, 2018, 38(3): 0315003. |
| [22] | HAN Xiaobing, ZHONG Yanfei, ZHANG Liangpei. An efficient and robust integrated geospatial object detection framework for high spatial resolution remote sensing imagery[J]. Remote Sensing, 2017, 9(7): 666. DOI:10.3390/rs9070666 |
| [23] | RADOVIC M, ADARKWA O, WANG Qiaosong. Object recognition in aerial images using convolutional neural networks[J]. Journal of Imaging, 2017, 3(2): 21. DOI:10.3390/jimaging3020021 |
| [24] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv: 1409.1556, 2014. http://www.oalib.com/paper/4068791 |
| [25] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 770-778. https://www.researchgate.net/publication/311609041_Deep_Residual_Learning_for_Image_Recognition |
| [26] | LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector[C]//Proceedings of the 14th European Conference on Computer Vision. Amsterdam: Springer International Publishing, 2016: 21-37. https://www.researchgate.net/publication/286513835_SSD_Single_Shot_MultiBox_Detector |
| [27] | VIOLA P, JONES M. Rapid object detection using a boosted cascade of simple features[C]//Proceedings of 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Kauai, HI: IEEE, 2001. https://www.researchgate.net/publication/3940582_Rapid_Object_Detection_using_a_Boosted_Cascade_of_Simple_Features |
| [28] | LI Haoxiang, LIN Zhe, SHEN Xiaohui, et al. A convolutional neural network cascade for face detection[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE, 2015: 5325-5334. https://www.researchgate.net/publication/308864105_A_convolutional_neural_network_cascade_for_face_detection |
| [29] | ZHANG Kaipeng, ZHANG Zhanpeng, LI Zhifeng, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499–1503. DOI:10.1109/LSP.2016.2603342 |
| [30] | LIN Ming, CHEN Qiang, YAN Shuicheng. Network in network[J]. arXiv: 1312.4400, 2013. |
| [31] | SHRIVASTAVA A, GUPTA A, GIRSHICK R. Training region-based object detectors with online hard example mining[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 761-769. |
| [32] | ZHU Haigang, CHEN Xiaogang, DAI Weiqun, et al. Orientation robust object detection in aerial images using deep convolutional neural network[C]//Proceedings of 2015 IEEE International Conference on Image Processing. Quebec City, QC: IEEE, 2015: 3735-3739. DOI: 10.1109/ICIP.2015.7351502. |
| [33] | XIA Guisong, BAI Xiang, DING Jian, et al. DOTA: a large-scale dataset for object detection in aerial images[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT: IEEE, 2018: 3974-3983. https://www.researchgate.net/publication/321347840_DOTA_A_Large-scale_Dataset_for_Object_Detection_in_Aerial_Images |
| [34] | REDMON J, FARHADI A. YOLO9000: better, faster, stronger[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI: IEEE, 2017: 6517-6525. |
| [35] | LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]//Proceedings of 2017 IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 2999-3007. https://www.researchgate.net/publication/322059369_Focal_Loss_for_Dense_Object_Detection |
| [36] | HOWARD A G, ZHU Menglong, CHEN Bo, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[J]. arXiv: 1704.04861, 2017. https://www.researchgate.net/publication/316184205_MobileNets_Efficient_Convolutional_Neural_Networks_for_Mobile_Vision_Applications |
| [37] | ZHANG Xiangyu, ZHOU Xinyu, LIN Mengxiao, et al. Shufflenet: an extremely efficient convolutional neural network for mobile devices[C]//Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT: IEEE, 2018: 6848-6856. http://www.researchgate.net/publication/318205093_ShuffleNet_An_Extremely_Efficient_Convolutional_Neural_Network_for_Mobile_Devices |