


2. 嘉兴学院数理与信息工程学院, 浙江 嘉兴 314001
2. College of Mathematics, Physics and Information Engineering, Jiaxing University, Jiaxing 314001, China
随着遥感影像技术的快速发展,高分辨率光学遥感影像数据量获得快速增长。与中低分辨率遥感影像相比,高分影像包含的信息更丰富,如空间信息、纹理信息、地物的几何结构信息等。影像中的地物目标具有同类差异大和部分类间相似度高的特点,因而如何有效地自动解译影像已吸引众多研究者的关注[1-2]。
为实现计算机视觉技术自动解译高分辨率光学遥感影的目标,很多处理方法被提出,主要可分为人工设计特征法和深度学习法。描述场景信息采用人工设计特征方法提取时,由于缺乏语义信息,导致这些方法的识别准确率与实际应用要求有较大差距。当前,由于出色的性能,深度学习方法已成为人工智能与模式识别领域的研究热点。针对图像分类问题,大量深度学习模型被构建,其中深度卷积神经网络模型的效果最好,如VGGNet[3]、GoogLeNet[4]、ResNet[5]等。在遥感影像场景分类任务中,基于深度学习方法的分类准确率获得大幅度地提高[2, 6]。与人工设计特征方法相比,深度学习方法需要更多的标注样本。在标注样本较少的应用中,迁移学习方法能有效地解决样本缺少问题[6-7]。
然而,在识别同类差异大和类间相似度高的任务时,现有的深度学习模型仍不能准确地区分各类场景。因此,深度学习模型的特征学习能力仍需进一步提高。文献[8-9]采用三元组损失的度量学习与深度学习结合的方法,提高模型的学习能力。该方法的输入由3幅图片构成,分别为主样本、同类型样本和不同类型样本,通过度量同类和异类之间的特征距离以提升模型对相似场景的分辨能力。三元组深度度量学习方法存在以下问题:训练样本量急剧增长,假定有C种类型且每种类型有N个样本,则训练样本数由C×N变为CN2×N×(C-1);训练时运行3个相同网络结构,收敛速度慢;仅对不同类型之间特征距离进行约束而同类型内部未进行约束,同类特征在空间上未聚类。
针对上述三元组方法存在的问题,本文提出均值中心度量方法以提升深度学习模型的学习能力。该方法通过增加C个均值聚类中心来改进现有深度学习模型。与现有的遥感影像场景分类方法相比,本文方法的特点如下:①单输入方式实现深度学习与度量学习相结合的遥感影像场景分类;②改进深度学习模型的损失函数,新损失函数由交叉熵损失项、权重与偏置正则项和均值中心度量损失项组成;③与现有方法相比,在3个公开遥感数据集上都取得最高的分类准确率。
1 相关工作早期遥感影像场景分类采用基于低层特征的方法,包括光谱特征、纹理特征、形状特征等。文献[10-11]分别提取光谱微分特征和脱氧核糖核酸编码光谱特征的方法进行分类。针对对象纹理信息差异的特点,文献[12]提出光谱与纹理相结合的场景特征表示。单独或融合的纹理特征可有效地表征高分遥感影像信息,如灰度共生矩阵、Gabor小波纹理等[13]。文献[14]融合像素上下文的形状结构特征与光谱特征提高了分类准确率。
若用语义信息描述能力差的低层特征来表征富含语义信息的遥感影像场景,识别性能存在局限性。视觉词袋模型(bag of visual words, BoVW)描述的特征含有中层语义信息,该方法在图像分类领域获得广泛应用。文献[15]采用该模型显著地提高了遥感影像场景的分类准确率。文献[16]采用空间金字塔模型,将分层图像的BoVW特征级联组成最终特征用于描述图像特征。文献[17]基于BoVW提出一种空间共生矩阵核来表示相对空间信息并采用同心圆的划分方式解决图像旋转敏感问题。然而,BoVW模型仅利用图像局部特征的统计信息但忽略这些信息之间关联关系。为挖掘这些关联信息,文献[18]提出主题模型实现场景的语义标注,文献[19]则利用多种低层特征分别构建主题模型来实现。基于主题模型方法使场景分类的准确率获得大幅度地提高,然而,上述方法在复杂场景上的分类准确率仍很低[1]。
随着高性能计算技术的快速发展,深度学习方法被广泛地应用于各领域的研究并取得巨大成功,其原因在于深度学习方法能从原始数据中自动地学习高层语义信息[20]。与其他图像分类任务一样,基于深度学习的高分遥感影像场景分类准确率也获得大幅提升。文献[21-23]分别构建端到端的深度学习模型用于高分遥感影像场景分类任务。VGGNet、ResNet等优秀深度学习模型直接地用于高分遥感影像场景分类可获得更好的性能[24-25]。针对遥感影像数据集标注数据量少的问题,基于迁移学习的方法有效地提高了分类准确率[6, 7, 26]。融合不同的深度特征也可有效地提高分类准确率[27-28]。
尽管深度学习方法极大地提高了高分辨率光学遥感影像场景分类的准确率,但面对相似程度较高的场景时区分能力仍不足。因此,度量学习被引入用于改进深度学习模型,其目的在于改进特征在空间上的分布,降低相似场景之间的混淆比率。文献[8-9]采用三元组深度度量学习方法提高深度学习模型的区分能力。
综上所述,现有高分辨率光学遥感影像场景分类方法中,人工设计特征方法的特点是对标注数据量要求低、模型简单、运行速度快等,但是表征能力差、知识迁移困难、分类准确率低等;而深度学习方法则正相反,特征学习能力强、迁移学习较易及分类准确率高,但需更多的计算资源。
2 深度度量学习方法 1.1 模型概述本文的深度卷积神经网络模型如图 1所示。该模型基于VGGNet-16[3]构建,虚线框部分继承原有模型,由卷积层、池化层及全连接层构成,增加全连接层(1×1×N,N为类型数)以及联合损失层构成本文模型。图 1中,“224×224×3”代表有3个通道,输入数据的尺寸为224×224。本文模型由13个卷积层、5个池化层、3个全连接层以及联合损失层组成。

|
| 图 1 基于VGGNet-16的深度卷积神经网络模型结构 Fig. 1 Structure diagram of deep convolutional neural network model based on VGGNet-16 |
1.2 均值中心度量模型
在特征空间上不同场景类型的间距越大,相似场景之间混淆的可能性就越低。因此,改进深度学习模型输出特征的空间分布,对提高总体分类准确率有积极意义。在文献[8, 29]的启发下,本文提出均值中心度量方法以改进特征的空间分布,实现提升模型场景识别能力的目标。图 2展示了本文深度度量学习方法的核心思想。“d”代表各聚类中心之间欧氏距离的平方,计算方法如式(1)所示
 (1)
(1)

|
| 图 2 均值中心度量方法 Fig. 2 The diagram of average center metric method |
式中,i和j为类型编号; N为数据样本类型数目; cik为第i类均值聚类中心向量的第k维;“margin”超参数为均值聚类中心之间的最小距离。该方法为各场景类型添加聚类中心,聚类中心的值在训练过程中按批次进行动态调整。
模型的损失函数由3部分构成,包括交叉熵损失项(Ls)、均值中心度量损失项(Lcm)和权重(W)与偏置(b)正则项。各项的作用分别是:交叉熵损失项使不相同类型样本分离;中心度量损失项使同类型聚集并扩大各类聚集中心之间的最小间距;权重与偏置正则项是为防止模型过拟合。模型的损失函数定义如式(2)所示
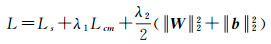 (2)
(2)
式中,λ1和λ2为权重系数。
假定数据集有N个样本{(xi, yi)xi∈ 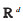
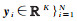
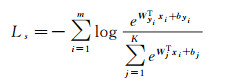 (3)
(3)
式中,m为每批次的样本数;yi为第i个样本的类型编号。根据上述均值中心度量方法的描述,Lcm定义如式(4)所示
 (4)
(4)
式中,cyi为yi类型的均值聚类中心,其值采用梯度下降方法通过训练求得;h(x)定义为max(x, 0)。
1.3 模型优化针对式(2)的优化问题,本文采用随机梯度下降(stochastic gradient descent, SGD)方法进行求解。根据SGD求解原理,Lcm项的xi偏导数及均值聚类中心的更新梯度如式(5)和式(6)所示
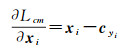 (5)
(5)
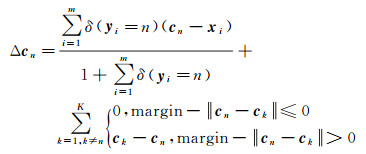 (6)
(6)
式中,δ函数在条件满足时返回1否则返回0;n为类型序号。cn值的更新方法如式(7)所示
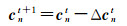 (7)
(7)
式中,t为迭代次序。
3 试验结果与分析 3.1 数据集为验证所提方法的有效性,本文选取其中3个各有特点的数据集进行试验,包括RSSCN7、UC Merced和NWPU-RESISC45数据集[1]。RSSCN7数据集共有7类场景,每类场景都有400幅400×400像素的影像并平均分为4种尺度。UC Merced数据集有21类场景且只有一个尺度,各类型有100幅256×256像素的影像。NWPU-RESISC45是当前规模最大、种类最多的公开遥感场景影像数据集共有45类场景,分别包含700幅256×256像素的影像。该数据集的特点是同类内部差异大和异类之间相似度高,对高分遥感图像场景分类方法有很高的挑战性。
为公平比较,数据集的设置与其他方法一致[1, 24],随机选取各类型的两种比例作为训练样本,剩余为测试样本,其中RSSCN7为20%和50%、UC Merced为50%和80%以及NWPU-RESISC45为10%和20%。
3.2 评价指标试验结果采用平均总体分类准确率、标准差和混淆矩阵作为分类性能的评估方法。总体分类准确率的计算方法如式(8)所示
 (8)
(8)
式中,N为测试样本的总数;T为各类型分类正确数的总和。平均总体分类准确率和标准差的计算如式(9)和式(10)所示
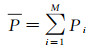 (9)
(9)
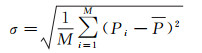 (10)
(10)
式中,M为重复试验的次数,本文M为10。
混淆矩阵能直观地展示各类型之间的混淆比率,矩阵的行为真实类型而列为预测类型。矩阵的对角线元素为各类型的分类准确率,其他任意元素xi, j代表第i类被误识为第j类场景占该类型的比率。
3.3 试验参数与环境试验中有两类参数需要配置。一类是损失函数中的超参数,包括λ1、λ2和“margin”。参考文献[8],λ2设为0.000 5;λ1和“margin”的值,本文通过在NWPU-RESISC45数据集上以10%样本测试确定。首先,设定“margin”参数为1并分别设置λ1的值为{0.01, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9}进行试验,见图 3,λ1设置为0.3。然后,将λ1设置为0.3,分别设置“margin”参数为{0.01, 0.05, 0.1, 0.5, 1, 2}进行试验,见图 4,“margin”设置为1。另一类是训练参数,设置如下:学习率(0.0005)、更新策略(“inv”)、迭代次数(20000)、批次大小(20)等。

|
| 图 3 不同λ1参数配置下的分类准确率变化对比曲线 Fig. 3 The overall accuracies of the proposed method using different λ1 settings |

|
| 图 4 不同“margin”参数配置下的分类准确率变化对比曲线 Fig. 4 The overall accuracies of the proposed method using different "margin" settings |
软硬件环境如下:Ubuntu 16.04操作系统、Caffe深度学习框架、Python2.7编程语言、Intel I5 3.4 GHz双核CPU、16 GB RAM和GTX1070显卡。
3.4 数据集试验本文下列所有试验结果都是基于迁移学习ImageNet数据集获得。
3.4.1 RSSCN7数据集试验表 1列出近期相关方法以及本文方法的准确率。在训练样本分别为20%和50%时,本文方法的准确率分别达到93.93%和96.01%,高于其他方法的结果。尽管增强数据的量比文献[24]少,本文方法的准确率仍分别提高了1.46%和0.42%。图 5显示了20%训练样本的分类结果混淆矩阵,结果表明仅有田与草地、工业区与停车场的混淆比率相对较高。

|
| 图 5 RSSCN7数据集以20%为训练样本的混淆矩阵 Fig. 5 Confusion matrix of the RSSCN7 dataset with a 20% ratio as training samples |
3.4.2 UC Merced数据集试验
表 2列出近期公开方法以及本文方法的分类结果。在训练样本为80%时,本文方法的准确率略高于目前最好结果;而在训练样本为50%时,与文献[9]相比,准确率提升了1.09%。图 6显示了50%训练样本的分类结果混淆矩阵,除密集住宅、中密度住宅和稀疏住宅之间容易混淆外,其他场景都能较好地识别。与文献[24]中的混淆矩阵相比,密集住宅和中密度住宅的混淆比率大幅地降低,从18%降至6%。
| 方法 | 年份 | 训练样本占比 | |
| 50% | 80% | ||
| VGG-VD-16[25] | 2016 | 94.14±0.69 | 95.21±1.20 |
| salM3 LBP-CLM[30] | 2017 | 94.21±0.75 | 95.75±0.80 |
| Fine-tuned VGGNet-16+SVM[8] | 2018 | - | 97.14±0.10 |
| Triplet networks[9]1 | 2018 | - | 97.99±0.53 |
| D-CNN with VGGNet-16[8]2 | 2018 | - | 98.93±0.10 |
| LOFs+GCFs[24]3 | 2018 | 97.37±0.44 | 99.00±0.35 |
| 本文方法3 | - | 98.46±0.18 | 99.15±0.29 |
| 注:1四个角上按75%和50%覆盖方式分别裁剪与中间按50%覆盖方式裁剪,实现九倍训练样本增强。 2每次迭代训练中,随机选择2(C-1)幅图像以单独生成C-1个同类和异类的影像对得到批训练样本,其中C为类型数。 3数据增强方法与表 1一致。 |
|||

|
| 图 6 UC Merced数据集以50%为训练样本的混淆矩阵 Fig. 6 Confusion matrix of the UC Merced dataset with a 50% ratio as training samples |
3.4.3 NWPU-RESISC45数据集试验
表 3列出了最新研究结果,本文方法与其他方法相比在分类准确率上有显著地提高。与文献[8]相比,分类准确率分别提高2.51%和1.58%;与文献[9]相比,分类准确率提高了1.14%。图 7为20%训练样本的分类结果混淆矩阵。

|
| 图 7 NWPU-RESISC45数据集以20%为训练样本的混淆矩阵 Fig. 7 Confusion matrix of the NWPU-RESISC45 dataset with a 20% ratio as training samples |
分析混淆矩阵发现教堂易被识为宫殿和商业区、宫殿易被识为教堂、铁路易被识为火车站。图 8列出3类误识的对比场景影像,(a)教堂、(b)宫殿和(c)铁路分别被误识为宫殿、教堂和火车站,与对应样例(d)宫殿、(e)教堂和(f)铁路非常相似。

|
| 图 8 混淆场景对比影像 Fig. 8 Thecontrast image of confused scene |
3.5 结果讨论
在3个数据集上的试验结果表明,本文方法的准确率明显高于其他方法。为进一步分析本文方法的性能,表 4列出消融试验结果。试验结果说明调优训练、数据增强及均值中心度量方法都能有效地提高分类准确率。
| (%) | ||||||||
| 方法 | RSSCN7 | UC Merced | NWPU-RESISC45 | |||||
| 20 | 50 | 50 | 80 | 10 | 20 | |||
| VGGNet-16(基准) | 83.98±0.87 | 87.18±0.94 | 94.14±0.69 | 95.21±1.20 | 76.47±0.18 | 79.79±0.15 | ||
| VGGNet-16(调优) | 92.16±0.87 | 94.80±0.51 | 97.02±0.27 | 98.15±0.24 | 87.30±0.26 | 90.16±0.29 | ||
| VGGNet-16(调优+增强) | 93.07±0.42 | 95.22±0.35 | 97.64±0.36 | 98.65±0.32 | 88.55±0.31 | 90.83±0.25 | ||
| 本文方法(调优) | 93.92±0.77 | 95.43±0.32 | 98.24±0.32 | 98.61±0.39 | 90.18±0.15 | 92.53±0.12 | ||
| 本文方法(调优+增强) | 94.30±0.53 | 96.01±0.58 | 98.46±0.18 | 99.15±0.29 | 91.73±0.21 | 93.47±0.30 | ||
为分析本文方法对特征空间分布的影响,采用LargeVis算法将第2个全链接层的4096维输出映射成二维向量。图 9是RSSCN7以50%训练样本在没有增强条件下获取的特征分布对比图,每个圈代表不同类型大概聚集范围。图 9(b)的特征聚集程度显著地提升,不同类型间的界线更清晰;图 9(a)的特征分布范围是50×60而图 9(b)为120×200,类型间距离明显地增大。表 4和图 9的结果验证了本文方法的有效性。

|
| 图 9 RSSCN7数据集的测试样本输出特征的2D映射特征可视化图 Fig. 9 2D feature visualization of image representations of the RSSCN7 dataset |
分析表 1至表 4发现在训练样本比例较低的情况下准确率获得更明显的提升,说明本文方法在少样本的应用中适用性更强。
4 总结针对高分场景图像分类存在相似场景之间容易混淆的问题,本文提出深度学习与度量学习相结合的方法来降低混淆比率。新模型的损失函数由交叉熵损失项、均值中心度量损失项以及权重与偏置正则项组成。试验结果表明,本文方法与现有其他方法相比在分类准确率上有明显的提高。在RSSCN7、UC Merced和NWPU-RESISC45数据集上以较小比例为训练样本时,分类准确率分别达到93.93%、98.46%和91.73%。尽管如此,在处理规模更大、类型更多、场景更复杂的高分遥感场景影像分类的任务中,分类准确率还有待改进。改进方法可从两个方面:一是改进模型以提升局部细节信息的学习能力,构建全局特征与局部细节特征相结合的学习模型;二是应用多特征融合方法,如多个深度模型特征或人工设计特征。
| [1] | CHENG Gong, HAN Junwei, LU Xiaoqiang. Remote sensing image scene classification:benchmark and state of the art[J]. Proceedings of the IEEE, 2017, 105(10): 1865–1883. DOI:10.1109/JPROC.2017.2675998 |
| [2] |
钱晓亮, 李佳, 程塨, 等.
特征提取策略对高分辨率遥感图像场景分类性能影响的评估[J]. 遥感学报, 2018, 22(5): 758–776.
QIAN Xiaoliang, LI Jia, CHENG Gong, et al. Evaluation of the effect of feature extraction strategy on the performance of high-resolution remote sensing image scene classification[J]. Journal of Remote Sensing, 2018, 22(5): 758–776. |
| [3] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[J]. arXiv preprint arXiv: 1409.1556, 2014. |
| [4] | SZEGEDY C, LIU Wei, JIA Yangqing, et al. Going deeper with convolutions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston: IEEE, 2015: 1-9. |
| [5] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 770-778. |
| [6] |
郑卓, 方芳, 刘袁缘, 等.
高分辨率遥感影像场景的多尺度神经网络分类法[J]. 测绘学报, 2018, 47(5): 620–630.
ZHENG Zhuo, FANG Fang, LIU Yuanyuan, et al. Joint multi-scale convolution neural network for scene classification of high resolution remote sensing imagery[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(5): 620–630. DOI:10.11947/j.AGCS.2018.20170191 |
| [7] | HU Fan, XIA Guisong, HU Jingwen, et al. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery[J]. Remote Sensing, 2015, 7(11): 14680–14707. DOI:10.3390/rs71114680 |
| [8] | CHENG Gong, YANG Ceyuan, YAO Xiwen, et al. When deep learning meets metric learning:remote sensing image scene classification via learning discriminative CNNs[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(5): 2811–2821. DOI:10.1109/TGRS.2017.2783902 |
| [9] | LIU Yishu, HUANG Chao. Scene classification via triplet networks[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2018, 11(1): 220–237. DOI:10.1109/JSTARS.2017.2761800 |
| [10] | BAO Jiangfeng, CHI Mingmin, BENEDIKTSSON J A. Spectral derivative features for classification of hyperspectral remote sensing images:experimental evaluation[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2013, 6(2): 594–601. DOI:10.1109/JSTARS.2013.2237758 |
| [11] | JIAO Hongzan, ZHONG Yanfei, ZHANG Liangpei. Artificial DNA computing-based spectral encoding and matching algorithm for hyperspectral remote sensing data[J]. IEEE Transactions on Geoscience and Remote Sensing, 2012, 50(10): 4085–4104. DOI:10.1109/TGRS.2012.2188856 |
| [12] | FRANKLIN S E, HALL R J, MOSKAL L M, et al. Incorporating texture into classification of forest species composition from airborne multispectral images[J]. International Journal of Remote Sensing, 2000, 21(1): 61–79. |
| [13] | CLAUSI D A, DENG Huang. Design-based texture feature fusion using Gabor filters and co-occurrence probabilities[J]. IEEE Transactions on Image Processing, 2005, 14(7): 925–936. DOI:10.1109/TIP.2005.849319 |
| [14] | ZHANG Liangpei, HUANG Xin, HUANG Bo, et al. A pixel shape index coupled with spectral information for classification of high spatial resolution remotely sensed imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2006, 44(10): 2950–2961. DOI:10.1109/TGRS.2006.876704 |
| [15] | YANG Yi, NEWSAM S. Bag-of-visual-words and spatial extensions for land-use classification[C]//Proceedings of the 18th SIGSPATIAL international conference on advances in geographic information systems. New York: ACM, 2010: 270-279. |
| [16] | CHEN Shizhi, TIAN Yingli. Pyramid of spatial relatons for scene-level land use classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2014, 53(4): 1947–1957. |
| [17] | ZHAO Lijun, TANG Ping, HUO Lianzhi. Land-use scene classification using a concentric circle-structured multiscale bag-of-visual-words model[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 7(12): 4620–4631. |
| [18] | LIENOU M, MAITRE H, DATCU M. Semantic annotation of satellite images using latent dirichlet allocation[J]. IEEE Geoscience and Remote Sensing Letters, 2010, 7(1): 28–32. DOI:10.1109/LGRS.2009.2023536 |
| [19] | ZHONG Yanfei, ZHU Qiqi, ZHANG Liangpei. Scene classification based on the multifeature fusion probabilistic topic model for high spatial resolution remote sensing imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2015, 53(11): 6207–6222. DOI:10.1109/TGRS.2015.2435801 |
| [20] | LECUN Y, BENGIO Y, HINTON G. Deep learning[J]. Nature, 2015, 521(7553): 436–444. DOI:10.1038/nature14539 |
| [21] | LUUS F P S, SALMON B P, VAN DEN BERGH F, et al. Multiview deep learning for land-use classification[J]. IEEE Geoscience and Remote Sensing Letters, 2015, 12(12): 2448–2452. DOI:10.1109/LGRS.2015.2483680 |
| [22] | ZHANG Fan, DU Bo, ZHANG Liangpei. Scene classification via a gradient boosting random convolutional network framework[J]. IEEE Transactions on Geoscience and Remote Sensing, 2016, 54(3): 1793–1802. DOI:10.1109/TGRS.2015.2488681 |
| [23] | WU Hang, LIU Baozhen, SU Weihua, et al. Deep filter banks for land-use scene classification[J]. IEEE Geoscience and Remote Sensing Letters, 2016, 13(12): 1895–1899. DOI:10.1109/LGRS.2016.2616440 |
| [24] | ZENG Dan, CHEN Shuaijun, CHEN Boyang, et al. Improving remote sensing scene classification by integrating global-context and local-object features[J]. Remote Sensing, 2018, 10(5): 734. DOI:10.3390/rs10050734 |
| [25] | XIA Guisong, HU Jingwen, HU Fan, et al. AID:A benchmark data set for performance evaluation of aerial scene classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(7): 3965–3981. DOI:10.1109/TGRS.2017.2685945 |
| [26] | YE Lihua, WANG Lei, SUN Yaxin, et al. Aerial scene classification via an ensemble extreme learning machine classifier based on discriminative hybrid convolutional neural networks features[J]. International Journal of Remote Sensing, 2018, 40(7): 2759–2783. |
| [27] |
许夙晖, 慕晓冬, 赵鹏, 等.
利用多尺度特征与深度网络对遥感影像进行场景分类[J]. 测绘学报, 2016, 45(7): 834–840.
XU Suhui, MU Xiaodong, ZHAO Peng, et al. Scene classification of remote sensing image based on multi-scale feature and deep neural network[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(7): 834–840. DOI:10.11947/j.AGCS.2016.20150623 |
| [28] | YE Lihua, WANG Lei, SUN Yaxin, et al. Parallel multi-stage features fusion of deep convolutional neural networks for aerial scene classification[J]. Remote Sensing Letters, 2018, 9(3): 294–303. DOI:10.1080/2150704X.2017.1415477 |
| [29] | WEN Yandong, ZHANG Kaipeng, LI Zhifeng, et al. A discriminative feature learning approach for deep face recognition[C]//Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer, 2016: 499-515. |
| [30] | BIAN Xiaoyong, CHEN Chen, TIAN Long, et al. Fusing local and global features for high-resolution scene classification[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2017, 10(6): 2889–2901. DOI:10.1109/JSTARS.2017.2683799 |