



高空间分辨率(简称高分)遥感影像建筑物提取在城市规划、变化检测、灾害救援等多方面具有重要应用价值。特征选择与特征表达是建筑物提取的重要基础。根据特征选取方式的不同将建筑物提取方法归纳为两类:一类是基于人工设计特征的,另一类是基于深度神经网络自主学习特征的。
根据建筑物所特有的光谱、纹理、结构、上下文等特性,很多学者设计出了具有针对性的建筑物提取方法。文献[1]结合结构、上下文、光谱信息3种不同类型的特征对建筑物进行提取。文献[2]基于灰度共生矩阵提出PanTex指数来提取建筑物。文献[3]基于Harris角点[4]、GMSR[5]、Gabor滤波和FAST特征点检测4种特征提出一种决策融合的建筑物提取方法。文献[6]结合双边滤波和EDLines线检测[7]探测出建筑物的边界线,然后基于线连接和闭合轮廓搜索得到完整的建筑物轮廓。文献[8]提出了一种结合方向梯度直方图和光谱与纹理特征的航空影像建筑物提取方法。另外,还有学者依据数学形态学提出相应的空间计算方法来提取建筑物,如形态学建筑物指数(MBI)[9]、增强的形态学建筑物指数(EMBI)[10]、面向对象形态学建筑物指数(OBMBI)[11]等。然而,人工设计特征的方法需要花费大量的精力来选择合适的建筑物特征。尽管这些方法在少量样本图像上表现出良好的性能,但尚未被证明可用于大型的建筑物数据集中。
近几年,由多层卷积滤波核组成的卷积神经网络(convolutional neural network, CNN)受到广泛的关注。CNN具有自动提取图像相关特征的能力,并被应用到数字识别、自然图像分类、图像分割等多个方面。目前,利用CNN从高分遥感影像中提取建筑物也取得了一定成果。文献[12]提出了一种基于块的卷积神经网络建筑物提取方法,以大图块输入小图块输出的方式学习空间上下文特征,对航空影像进行建筑物提取,并在Massachusetts建筑物数据集上表现出良好的性能。但基于块状的方法提取得到的建筑物中会产生块状不连续的现象。针对该问题,文献[13]提出了一种多通道预测方法,同时预测道路、建筑物和背景(除建筑物和道路的其他地物)3种类别,以降低预测结果中块状不连续的情况。文献[14]用全卷积神经网络(fully convolutional neural network, FCN)[15]进行建筑物提取。用FCN提取建筑物的方法消除了由于块状边界引起的不连续性;其次,由于去掉了文献[12]提出的网络中的全连接层,减少了参数的数量。同时,由于全卷积操作的GPU执行速度快,缩短了执行时间。但FCN反卷积上采样结果比较模糊和平滑。上述网络均为单输入卷积神经网络,也有学者提出双输入深度神经网络模型提取建筑物。如文献[16]将包含完整建筑物的256×256像素的大窗口影像输入到Alexnet[17]网络提取建筑物的全局特征,将仅包含建筑物局部的64×64像素的小窗口影像输入到VGG[18]网络中提取局部特征,结合全局和局部特征对1 m分辨率的Massachusetts数据集进行建筑物提取。Massachusetts数据集中多数建筑物为小建筑物,占20×20~30×30像素,而较大建筑物长占150~250像素,宽占70~150像素左右。当影像分辨率更高,影像中建筑物所占的像素数更多,文献[16]提出的双输入网络方法需要增大网络中大窗口甚至小窗口的大小,这样会造成数据量增大。受计算机硬件的限制,当网络的输入过大时,会出现内存不足的现象,网络无法训练。当仅将小窗口影像输入到VGG16网络提取大建筑物时,结果存在空洞。针对这种现象,本文在VGG16的基础上提出了一种多尺度全卷积深度网络,使得当输入影像的窗口不能很好地覆盖原建筑物时,大型建筑物也能被完整地提取。由此,本文中的大型建筑物是指建筑物所占像素数超过输入影像窗口大小的建筑物。
目前,多尺度卷积神经网络一般分为两种。一种是基于多尺度特征图的卷积神经网络模型,如目标检测任务中的SSD网络[19],通过使用多个特征图,同时进行位置回归和分类,以解决高层特征图上小物体信息少而造成检测效果不佳的问题。在语义分割任务中PSPNet[20]将基于ResNet[21]网络提取的特征图, 通过一个金字塔池化模块获得多个尺度的特征图,然后将多尺度特征图上采样并串联,从而获得图像的局部和全局特征。DeepLab-v2[22]提出了空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP),用不同空洞率的空洞卷积层并行来获得多尺度信息。另一种是基于多尺度影像的卷积神经网络模型。这类模型通常将不同尺度的影像分别输入到相同的网络模型,得到不同尺度影像的特征,并将其融合获得多尺度特征。不同学者获得多尺度影像的方式有所不同,如文献[23]将原始影像进行拉普拉斯金字塔变换,而文献[24-25]直接将原始影像进行不同尺度的缩放。但是这种基于多尺度影像的模型受GPU内存的限制,不能很好地适应更大更深的网络*。
* CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation[R/OL].(2017-12-05)[2017-12-20]. https://arxiv.org/abs/1706.05587.
本文提出了一种基于多尺度影像的全卷积神经网络,首先将原始影像依次进行1/4、1/16、1/64、1/256等4个等级的下采样,得到不同分辨率的影像,并分层级地进行建筑物多尺度特征提取和特征融合。为了减少网络参数,本文用上采样层取代全连接层。由于FCN中简单的反卷积上采样过程所得建筑物提取结果不够精细,因此本文采用SegNet[26]网络中的上采样方法。
1 VGG16网络经典的卷积神经网络由卷积层、池化层和全连接层组成。卷积神经网络通过“卷积层+池化层”得到特征图,然后将得到的特征图转换成一维向量输入到全连接层,最后一层全连接层通常被传到Sigmoid激活函数或Softmax激活函数中,用于二分类或多分类任务。VGG网络由文献[18]提出,是用于ImageNet数据集[27]分类的一种卷积神经网络。该网络取得了ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛2014年分类项目的第2名。为此,本文将该网络的样本标记模式进行调整用于建筑物提取,并针对其在大型建筑物提取存在空洞的问题对该网络模型进行改进。在ImageNet数据集分类中,输入VGG16网络的样本标记用One-hot编码表示,即以向量p=[0, 0, …, 1, …, 0, 0](第i个元素值为1,其余元素值为0)表示对应输入图片所属的类别为第i类;向量p的维度为1000,代表ImageNet数据集中的1000个类别。而本文用VGG16网络提取建筑物的数据标记为二值向量q=[0, 1, …, 0, 1, 1, 0…, 0, 0],向量q中每个元素值取0(表示非建筑物)或1(表示建筑物),表示对应输入影像上的像素是否为建筑物;向量q的维度与VGG16建筑物提取网络的输出影像大小保持一致。下面介绍建筑物提取的VGG16网络结构。
VGG16建筑物提取网络由13个卷积层、5个池化层、3个全连接层组成。网络的输入为wi×wi的影像,输出为w0×w0的影像,输入影像与输出影像的中心位置相同,输出影像中的每个像素代表其对应位置的输入像素属于建筑物的概率,取值在0~1之间。为了提供建筑物的上下文信息,设置wi > w0。VGG16特征提取结构(去掉全连接层)如表 1所示,其中,“[3×3 conv (N)]×m”表示由N个3×3卷积核构成的m个卷积层,这种相同参数的卷积层构成一个block;“pool/2”表示核大小为2×2的池化层。而后网络连接3个全连接层,输出神经元个数依次为4096、4096、w0×w0(最后一个全连接层神经元个数与输出影像大小保持一致)。
| 网络层名 | 网络层结构 | 输出特征图与输入影像大小之比 |
| block 1 | [3×3 conv (64)]×2 | |
| pool 1 | pool/2 | 1/4 |
| block 2 | [3×3 conv (128)]×2 | |
| pool 2 | pool/2 | 1/16 |
| block 3 | [3×3 conv (256)]×3 | |
| pool 3 | pool/2 | 1/64 |
| block 4 | [3×3 conv (512)]×3 | |
| pool 4 | pool/2 | 1/256 |
| block 5 | [3×3 conv (512)]×3 | |
| pool 5 | pool/2 | 1/1024 |
2 网络的改进 2.1 VPU网络结构
影像中大型建筑物的结构特征和上下文特征往往难以在较小的影像块中反映出来,因此输入CNN的影像块应尽可能大。输入CNN的影像越大,待训练的参数越多,受计算机硬件的限制,输入影像不能无限制的增大。针对输入影像中难以包含大型建筑物全局特征的问题,本文在VGG16的基础上引入金字塔结构。由于全连接层参数过多,将其用具有编码器-解码器结构的全卷积神经网络取代,构建一种新的网络。
本文采用最大池化的方式将输入影像依次进行1/4、1/16、1/64、1/256的下采样,得到4种低分辨率的影像,分别记为scale1—scale4。在现有基于多尺度影像的卷积神经网络中,通常使用相同的网络结构处理不同尺度的影像,进而得到多尺度特征图,这种方式导致计算量增加。为此,本文以VGG16为基础网络结构,称其为网络主干。网络主干对原始影像进行卷积和池化操作后得到大尺度特征图,如图 1中虚线框部分。网络主干pool l(l=1, 2, 3, 4)层的输出与scale l影像大小相同,将pool l层的输出和scale l影像分别输入到block l+1网络模块中,得到两个尺度影像的特征。这样每次仅对两个尺度的特征图进行融合,既可以得到多尺度的特征,又可以避免同一网络结构重复多次的计算。所得到的两个尺度特征图维度和大小相同,可以直接将其在相应维度上进行相加,共同输入到后续的网络模块中。

|
| 图 1 VPU网络结构 Fig. 1 VPU neural network architecture |
SegNet和FCN是两种经典的全卷积网络。编码过程图像不断缩小,解码过程图像不断上采样放大。文献[26]通过试验表明,SegNet中的上采样比FCN中所使用的反卷积上采样在语义分割中表现出更好的性能。SegNet在上采样过程中引入池化索引功能,使得在内存使用上SegNet比FCN更为有效。另一方面,FCN为了精细试验结果,上采样过程中将反卷积结果与编码过程得到的特征图结合,训练比较繁琐。因此本文使用SegNet网络中的上采样层来替代VGG16中的全连接层。
通过试验对比发现,当经过3次上采样时建筑物提取精度最高,因此本文并未将图像上采样到原始输入图像的大小。
本文所提出的网络完整结构如图 1所示,记为VGG16_Pymaid_Upsample,简称VPU。图中“红色”图层表示“卷积层+激活函数ReLU”、“黄色”图层表示“池化层”、“绿色”图层表示Segnet上采样层。不同的图层大小表示该层输入影像(或特征图)的相对大小,输入影像对应的预测输出标记为最右边红框内的影像。
2.2 VPU网络可视化分析 2.2.1 最大池化下采样在CNN中,有最大池化和平均池化两种图像下采样方式。本文对比以上两种下采样方法以及图像处理中的3种采样方法(最邻近法、双线性内插法、三次卷积内插法)的区别。将图 2所示的576×576像素的影像分别采用以上5种采样方法依次进行1/4、1/16、1/64、1/256下采样处理。

|
| 图 2 576×576像素的原始影像 Fig. 2 The original image with 576×576 pixels |
图 3(a)—(e)依次表示1/4倍最大池化、平均池化、最邻近法、双向性内插法和三次卷积内插法下采样的结果。1/4倍下采样时,从目视上难以判别不同方法下采样后影像的变化,因此用灰度直方图对下采样结果进行分析。图 4(a)—(e)分别对应图 3(a)—(e)下采样后图像红绿蓝三波段的灰度直方图。从图中可以看出,最大池化和最邻近法下采样结果中尖锐处较多,而平均池化、双线性内插法及三次卷积内插法下采样结果中相对比较平滑。

|
| 图 3 1/4倍下采样的5种结果 Fig. 3 The 5 results of downsampling to quarter of the original image |

|
| 图 4 5种下采样结果的灰度直方图 Fig. 4 Gray histogram of the 5 downsampling methods |
进一步,当下采样级数更大时(图 5(a)为以上5种下采样方式1/64倍下采样结果,图 5(b)为5种下采样方式1/256倍下采样结果),最大池化后的结果相对于其他几种方法的结果边界处信息更明显;最邻近法下采样后结果中显示出明显的椒盐噪声;而平均池化、双线性内插法和三次卷积内插法去除了图像中尖锐的变化,得到均匀平滑的图像,建筑物的边界处被模糊,细节被削弱。综合考虑,本文采用边界信息更丰富的最大池化下采样方法来得到多尺度影像。

|
| 图 5 1/64倍与1/256倍级数下采样结果比较 Fig. 5 Comparison of 1/64 and 1/256 times downsampling |
2.2.2 多尺度特征融合
为了显示多尺度特征融合的效果,将图 2所示的576×576像素的影像输入到VPU网络(3次上采样)中,并将不同尺度影像所得特征图及融合后的特征图进行可视化分析。
观察可视化的结果,可以发现scale 1—scale 3影像所得到的特征图与网络主干特征图融合起到了特征加强的作用。将pool l层输出特征图和scale l影像输入到block l+1网络模块后提取的特征图分别记为FM_pool l、FM_scale l;将特征图FM_pool l和特征图FM_scale l对应维度相加融合后所得特征图记为FM_add l。以sacle3影像特征图及特征融合的结果为例,如图 6(a)—(c)所示,分别表示FM_pool3、FM_scale3、FM_add3中前36维特征图的可视化结果。观察图 6(a)和图 6(b)中白色虚线框标示的特征图,在大尺度的高层特征图中建筑物的边缘轮廓信息已经模糊,而在小尺度的低层特征图中建筑物边界细节信息更多。这使得多尺度特征结合后所得到的特征图信息更丰富,使得建筑物边界提取更精准。

|
| 图 6 特征图可视化 Fig. 6 Feature map visualization |
而scale 4影像所得到的特征图与网络主干特征融合后的效果与之前几个尺度融合的效果存在差异。如图 6(d)—(f)所示,分别表示FM_pool 4、FM_scale 4、FM_add 4中前64维特征图的可视化结果。从图中可以看出,特征图融合后的结果FM_add4与网络主干所得到的特征图FM_pool4可视化结果相近。这表明scale 4影像所得特征图对最终结果影响较小,网络训练过程中会对不同尺度来源的特征图进行权重分配。scale 4影像所保留的建筑物信息抽象,对建筑物提取的作用相对较小,这时网络训练过程中对其分配的权重较小。
3 试验及分析本文选择中国上海市嘉定区和美国Massachusetts两个地区的数据集来验证改进网络的有效性,国内和国外建筑物在结构和复杂度方面差异很大。上海市嘉定区影像中建筑物以住宅小区、别墅区、厂房3种类型的建筑物为主。住宅小区中建筑物长占40~60像素,宽占10~30像素;别墅区建筑物一般占25×25~40×40像素;厂房所占像素大于100×100,较大的厂房可达500×400像素左右,为大型建筑物。Massachusetts数据集中建筑物以别墅区和商业中心为主,其中别墅区建筑物约占20×20~30×30像素,而商业中心中多数建筑物长占150~250像素,宽占70~150像素左右,为大型建筑物。
本文用放宽的查全率-查准率曲线(relaxed precision-recall curve)[12]进行精度评价。预测结果的二值图中1代表建筑物,0代表非建筑物。记N1为预测值为1的像素个数,N2为真实值为1的像素个数,Nr_p为预测值为1且周围3个像素范围内存在真实值为1的像素个数,Nr_r为真实值为1且周围3像素范围内存在预测值为1的像素个数。放宽的查全率(RP)和放宽的查准率(RR)的计算公式如下
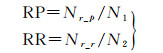 (1)
(1)
最终选择放宽的查全率-查准率曲线上查全率和查准率相差最小的平衡点为精度评价指标,记为bp,并取bp值为平衡点处的RR。
本文选用收敛较快的交叉熵损失函数[28](如式(2)所示)L来定量评价训练样本集中的真实值y(i)和预测值y′(i)(i=1,…,n;n为训练样本的个数)之间的差异,并使用小批量随机梯度下降(mini-batch stochastic gradient descent, mini-batch SGD)的方法来最优化损失函数
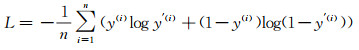 (2)
(2)
在训练网络学习参数的过程中,不同网络的超参数设置相同:初始学习率λ=0.005,学习率衰减频率τ=104,学习率衰减率μ=0.1,动量值m=0.9,权重衰减值w=0.000 5。
3.1 试验1上海市嘉定区试验数据为0.5 m分辨率的天地图影像,由RGB 3个波段组成。试验区影像大小为18 000×18 000像素,选择试验区7/9的数据作为训练样本集,1/9作为交叉验证集,1/9作为测试样本(6000×6000像素),选择其中5990×5990像素的区域进行精度评价。
参考文献[16]所提出的建筑物提取方法,当使用Massachusetts建筑物数据集时,对应的VGG16网络分支中的输入影像大小为64×64像素(简称64×64,以下影像大小的描述均使用简称),输出影像大小为16×16。对于64×64的检测窗口而言,Massachusetts数据集中别墅区建筑物为小建筑物,而商业中心建筑物为大型建筑物。同时64×64的检测窗口约是最大的小型建筑物的2倍,这样有利于获得小型建筑物的上下文语义信息。针对本文嘉定区影像数据,当检测窗口为64×64时,对于长宽为40~60像素的住宅小区,64×64的检测窗口不足以反映其上下文信息。如图 7(c)所示,当影像输入为64×64时,VGG16网络存在对大型建筑物提取不完整的现象。因此嘉定区建筑物检测时,检测窗口设定为128×128(约是最大的小型建筑物的2倍)。如图 7(d)—(e),对比VGG16和VPU(2次上采样)两种方法在128×128的网络输入时对大型建筑物提取的结果,可以看出本文提出的方法对大型建筑物的空洞现象有一定程度的改进。

|
| 图 7 预测结果 Fig. 7 The prediction results |
为了说明本文输入窗口大小选择的有效性,将本文方法以128×128的影像输入时的结果与VGG16网络在128×128和64×64两种不同输入影像大小时的结果进行精度比较,以嘉定区测试集中的5990×5990区域进行试验,结果如表 2所示。
| 卷积神经网络 | 输入窗口的大小 | 输出窗口的大小 | bp值 |
| VGG16 | 64×64 | 16×16 | 0.950 6 |
| VGG16 | 128×128 | 16×16 | 0.955 8 |
| VPU | 128×128 | 16×16 | 0.963 1 |
当VGG16网络的输入影像窗口大小为128×128时,预测精度高于64×64大小的影像输入,表明适当增加上下文信息时,可以提高建筑物的提取精度。本文提出的方法相较于VGG16精度有所提高。
上采样次数不同时,网络输出影像的大小将不同,这将影响建筑物提取效果。为了比较不同上采样次数对结果的影响,本文采用2次、3次、4次、5次等4种不同次数的上采样(每次上采样均将图像水平方向和垂直方向各放大2倍),对建筑物提取结果进行对比。多次池化后,上采样前特征图大小为输入影像的
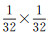
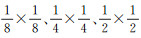
图 8为用不同的上采样次数的网络对576×576大小的影像进行预测的结果,其中,图 8(a)和(b)分别表示576×576的原始影像和对应的标记。通过目视解译,当2次上采样时,影像中大型建筑物仍存在少许空洞;当5次上采样时,试验结果中拼接处会存在明显的拼接缝隙。分析其原因,当5次上采样时,预测和训练的输入和输出图像大小均为128×128,使得边界处缺少上下文语义信息,从而导致试验结果中存在明显的拼接缝。而3次上采样和4次上采样的目视效果相对较好。

|
| 图 8 不同上采样次数的网络建筑物提取结果 Fig. 8 The results of buildings extraction with different times of upsampling |
同时,本文通过定量的方法分析了整景嘉定区测试样本的试验结果,并用表格和放宽的PR曲线图两种形式表示不同上采样次数所对应的建筑物提取精度。如表 3和图 9(a)所示,从中都可以看出,当3次上采样即网络输出影像大小为32×32时,建筑物提取精度最高。因此最终的VPU网络选择3次上采样。
| 卷积神经网络 | 上采样次数/次 | 输入窗口的大小/像素 | 输出窗口的大小/像素 | bp值 |
| VPU | 2 | 128×128 | 16×16 | 0.963 1 |
| VPU | 3 | 128×128 | 32×32 | 0.970 9 |
| VPU | 4 | 128×128 | 64×64 | 0.967 6 |
| VPU | 5 | 128×128 | 128×128 | 0.953 5 |

|
| 图 9 建筑物提取精度 Fig. 9 The accuracy of buildings extraction |
嘉定区建筑物最终提取的二值图如图 10(c)所示,提取精度为0.970 9。

|
| 图 10 嘉定区建筑物提取结果 Fig. 10 The results of buildings extraction on the Jiading dataset |
3.2 试验2
Massachusetts建筑物数据集由文献[12]提供,共有151张1500×1500的1 m分辨率的航空影像,其中137张影像训练样本、4张交叉验证样本、10张测试样本。由于文献[12-13, 16]均在Massachusetts建筑物数据集上进行各自的网络测试,因此将以上几种方法建筑物提取结果与本文方法进行对比试验,结果如表 4所示。文献[12-13]提出的单输入网络中输入影像大小为64×64,因此本文网络所选用的影像输入大小也为64×64,经过3次上采样后网络的输出为16×16。
从表 4可以看出,本文方法的精度高于其他几种方法,最终建筑物提取精度为0.966 6,对应的放宽的PR曲线如图 9(b)所示。图 11展示了一组本文方法对Massachusetts地区建筑物的提取结果,其中图 11(a)为原始影像,(b)为对应的建筑物标记,(c)为建筑物提取结果,结果中小建筑物和大建筑物均可以被很好地提取出来。

|
| 图 11 Massachusetts数据集建筑物提取结果 Fig. 11 The results of buildings extraction on Massachusetts dataset |
3.3 大型建筑物提取效果分析
本文所用的试验区中大型建筑物有两种,Massachusetts数据集中的大型商业中心和嘉定试验区的厂房。其中大型商业中心建筑物大小相近,而厂房的大小跨度相对较大(100×100~500×500之间大小不等)。本文以一个商业中心建筑物和3个不同大小的厂房样本图像为例,对比原始VGG16网络与最终的VPU(3次上采样)网络提取的效果。针对Massachusetts数据集中大型商业中心建筑物,两个网络输入的影像大小均为64×64。
针对上海市嘉定区试验,两个网络输入的影像大小均为128×128,3个样本图像的大小依次为516×357、244×211和337×386。图 12和图 13中每一行图像从左到右依次表示原始样本图像、样本标记、VGG16网络建筑物提取结果、VPU网络建筑物提取结果。从图中可以看出,本文所提出的VPU网络可以改善VGG16网络对于大型建筑物提取时存在的空洞现象。

|
| 图 12 商业中心建筑物提取时空洞现象的改进 Fig. 12 Improvement of the hole phenomenon for the business center |

|
| 图 13 厂房提取时空洞现象的改进 Fig. 13 Improvement of the hole phenomenon for the workshops |
4 结语
本文针对VGG16网络对高分影像中大型建筑物提取结果不完整的问题,提出了一种基于多尺度影像的全卷积神经网络模型。该方法有效地利用了建筑物不同尺度下的特征。通过对上海市嘉定区和Massachusetts遥感影像进行建筑物提取,验证了本文方法的有效性。
试验结果表明:①相比于平均池化、最邻近法、双线性内插法和三次卷积内插法下采样,最大池化下采样得到的多尺度影像中可以保留建筑物的边界信息,更有利于建筑物的提取;②多尺度特征的综合可以更清楚地展现目标特征;③当卷积神经网络的输入影像大小不同时,形成的上下文背景信息不同,丰富的上下文结构有利于对建筑物的提取;④本文方法不仅对建筑物类型较少、结构简单的Massachusetts地区建筑物可以很好地提取,而且对建筑物种类繁多、结构复杂的上海市建筑物有很好的提取效果。
本文的两组试验数据中,同一组数据的训练样本集和测试样本集的影像波段数、空间分辨率和时相等均相同。而实际应用中,用于建筑物提取的高分辨影像可能是不同成像传感器、不同时间、不同光照条件下获得的不同空间分辨率影像,如何设计适用于不同来源数据的建筑物提取网络模型是值得进一步研究的问题。这样既避免了网络在不同数据源上重复训练,同时增加了网络模型在工程应用中的普适性。
| [1] | JIN Xiaoying, DAVIS C H. Automated building extraction from high-resolution satellite imagery in urban areas using structural, contextual, and spectral information[J]. EURASIP Journal on Advances in Signal Processing, 2005(2005): 745309. |
| [2] | PESARESI M, GERHARDINGER A, KAYITAKIRE F. A robust built-up area presence index by anisotropic rotation-invariant textural measure[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2008, 1(3): 180–192. DOI:10.1109/JSTARS.2008.2002869 |
| [3] | SIRMACEK B, UNSALAN C. A probabilistic framework to detect buildings in aerial and satellite images[J]. IEEE Transactions on Geoscience and Remote Sensing, 2011, 49(1): 211–221. DOI:10.1109/TGRS.2010.2053713 |
| [4] | HARRIS C, STEPHENS M. A combined corner and edge detector[C]//Proceedings of the 4th Alvey Vision Conference. Manchester: BMVA, 1988: 147-151. |
| [5] | UNSALAN C. Gradient-magnitude-based support regions in structural land use classification[J]. IEEE Geoscience and Remote Sensing Letters, 2006, 3(4): 546–550. DOI:10.1109/LGRS.2006.879560 |
| [6] | WANG Jun, YANG Xiucheng, QIN Xuebin, et al. An efficient approach for automatic rectangular building extraction from very high resolution optical satellite imagery[J]. IEEE Geoscience and Remote Sensing Letters, 2015, 12(3): 487–491. DOI:10.1109/LGRS.2014.2347332 |
| [7] | AKINLAR C, TOPAL C. EDLines:A real-time line segment detector with a false detection control[J]. Pattern Recognition Letters, 2011, 32(13): 1633–1642. DOI:10.1016/j.patrec.2011.06.001 |
| [8] |
吕凤华, 舒宁, 龚龑, 等.
利用多特征进行航空影像建筑物提取[J]. 武汉大学学报(信息科学版), 2017, 42(5): 656–660.
LÜ Fenghua, SHU Ning, GONG Yan, et al. Regular building extraction from high resolution image based on multilevel-features[J]. Geomatics and Information Science of Wuhan University, 2017, 42(5): 656–660. |
| [9] | HUANG Xin, ZHANG Liangpei. A multidirectional and multiscale morphological index for automatic building extraction from multispectral GeoEye-1 imagery[J]. Photogrammetric Engineering & Remote Sensing, 2011, 77(7): 721–732. |
| [10] |
胡荣明, 黄小兵, 黄远程.
增强形态学建筑物指数应用于高分辨率遥感影像中建筑物提取[J]. 测绘学报, 2014, 43(5): 514–520.
HU Rongming, HUANG Xiaobing, HUANG Yuancheng. An enhanced morphological building index for building extraction from high-resolution image[J]. Acta Geodaetica et Cartographica Sinica, 2014, 43(5): 514–520. DOI:10.13485/j.cnki.11-2089.2014.0084 |
| [11] |
林祥国, 张继贤.
面向对象的形态学建筑物指数及其高分辨率遥感影像建筑物提取应用[J]. 测绘学报, 2017, 46(6): 724–733.
LIN Xiangguo, ZHANG Jixian. Object-based morphological building index for building extraction from high resolution remote sensing imagery[J]. Acta Geodaetica et Cartographica Sinica, 2017, 46(6): 724–733. DOI:10.11947/j.AGCS.2017.20170068 |
| [12] | MNIH V. Machine learning for aerial image labeling[D]. Toronto: University of Toronto, 2013. |
| [13] | SAITO S, YAMASHITA T, AOKI Y. Multiple object extraction from aerial imagery with convolutional neural networks[J]. Journal of Imaging Science and Technology, 2016, 60(1): 10402–1. |
| [14] | MAGGIORI E, TARABALKA Y, CHARPIAT G, et al. Convolutional neural networks for large-scale remote-sensing image classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(2): 645–657. DOI:10.1109/TGRS.2016.2612821 |
| [15] | LONG J, SHELHAMER E, DARRELL T. Fully convolutional networks for semantic segmentation[C]//Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE, 2015: 3431-3440. |
| [16] | MARCU A, LEORDEANU M. Dual local-global contextual pathways for recognition in aerial imagery[R/OL]. (2016-05-12)[2017-08-13]. https://sciencewise.info/articles/1605.05462. |
| [17] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]//Proceedings of the 25th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada: ACM, 2012: 1097-1105. |
| [18] | SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//Proceedings of International Conference on Learning Representations 2015. San Diego: ICLR, 2015: 463-476. |
| [19] | LIU Wei, ANGUELOV D, ERHAN D, et al. SSD: single shot multi box detector[C]//Proceedings of the 14th European Conference on Computer Vision. Amsterdam: Springer, 2016: 21-37. |
| [20] | ZHAO Hengshuang, SHI Jianping, QI Xiaojuan, et al. Pyramid scene parsing network[C]//Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, HI: IEEE, 2017: 6230-6239. |
| [21] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep residual learning for image recognition[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 770-778. |
| [22] | CHEN L C, PAPANDREOU G, KOKKINOS I, et al. DeepLab:semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834–848. DOI:10.1109/TPAMI.2017.2699184 |
| [23] | FARABET C, COUPRIE C, NAJMAN L, et al. Learning hierarchical features for scene labeling[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1915–1929. DOI:10.1109/TPAMI.2012.231 |
| [24] | LIN Guosheng, SHEN Chunhua, VAN DEN HENGEL A, et al. Efficient piecewise training of deep structured models for semantic segmentation[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 3194-3203. |
| [25] | CHEN L C, YANG Yi, WANG Jiang, et al. Attention to scale: scale-aware semantic image segmentation[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 3640-3649. |
| [26] | BADRINARAYANAN V, KENDALL A, CIPOLLA R. SegNet:a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2491–2495. |
| [27] | DENG Jia, DONG Wei, SOCHER R, et al. ImageNet: a large-scale hierarchical image database[C]//Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Miami Beach, FL: IEEE, 2009: 248-255. |
| [28] | BISHOP C M. Neural networks for pattern recognition[M]. Oxford: Oxford University Press, 1995. |