



2. 96911部队, 北京 100011
2. Troops 96911, Beijing 100011, China
线化简是自动制图综合中的重要内容和经典研究问题之一,目的是减少目标的表达细节而代之以总的图形特征,迄今为止,已有大量算法提出[1-2]。与此同时,如何对化简算法进行评价、合理选用以及如何实现算法的自动化成为新的需要研究的课题。针对这一研究,有学者提出利用相似性分析不同化简算法的特点和进行自动化简,如文献[3-6]分别利用多级弦长、傅里叶形状描述子、多级弦长拱高复函数及多级弯曲度半径复函数构建相似性度量模型,通过度量化简结果的相似性变化规律,分析了制图综合领域典型线化简算法的特点。这些方法主要是利用相似性对化简算法特点作出评价,没有将相似性用于约束化简过程。文献[7-9]构建了线要素相似关系度量模型,研究了线要素相似性同尺度变化的关系,构建了相似性随尺度变化的关系式,并据此反推化简算法的阈值参数。该方法为化简算法的自动执行提供了一种有效思路,但是其相似性度量模型较简单,对形状的相似性度量能力存在一定不足,更为关键的是该方法的前提条件是不同复杂度的目标在相同尺度变化情况下相似度相同,但未进行相关验证。化简是简化目标细节的一种操作,即降低目标的复杂程度,然而现阶段,缺少相关的模型对目标的复杂度进行定量描述。另外,针对不同复杂度的目标,从一个尺度通过制图综合操作变换到另一尺度,其改变的程度是否相同,即相似度是否相同,目前鲜有相关研究,而这一研究可为化简算法的自动运行提供理论依据。
针对该问题,本文对面轮廓相似性和复杂性同时展开研究。首先利用面向矢量数据的基于弦特征矩阵的相似性度量模型,对面轮廓线化简前后的相似性进行度量,然后引入复杂度的概念,建立轮廓形状复杂性度量模型,对目标的复杂度进行定量描述。在验证两类模型有效性的基础上,基于现有数据,探索不同复杂度目标在不同尺度下相似性的变化规律,并据此给出相似性约束的自动化简一般流程,使相似性约束的自动化简方法更具科学依据。
1 面向矢量数据的弦特征矩阵相似性度量模型矢量数据与栅格数据是两种基本的数据组织方式,针对两类数据模型的计算也有很大差异。弦特征矩阵形状描述子是针对栅格图像的形状描述方法,目前主要应用于植物叶片图像的分类和检索[10]。本文将这一思想应用于面状矢量数据,构造面向矢量数据的弦特征矩阵相似性度量模型。
1.1 形状的弦特征矩阵描述 1.1.1 形状弦特征矩阵一个由K个点序列构成的目标形状可表示为A={Pi=(xi, yi)|i=1, 2, …, K}。从Pi点出发,沿逆时针方向对其进行均匀采样,将轮廓按弧长等分为N个弧段,且N满足2T=N,其中T为正整数,则该目标可用采样后的点序列{Qi=(xi, yi)|i=1, 2, …, N}表达。图 1所示为用32个节点对原始43个节点的形状轮廓重采样的结果。

|
| 图 1 轮廓重采样及弦特征 Fig. 1 Resampling and chord feature of the contour |
对于重采样后的目标形状,给出以下4个定义。
定义1:弦长,指从轮廓线上的点Qi(xi, yi)出发,沿轮廓线按逆时针方向到达另一点Qi+s(xi+s, yi+s)所经过的弧段对应弦的长度,用ls, i表示,其中S为步长,弦长的计算公式为
 (1)
(1)
定义2:内弦长,指弦落在形状区域A内部的长度,用ls, i(I)表示,其长度是落入多边形内部各小段弦长的和,公式为
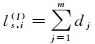 (2)
(2)
式中,m是落入多边形内部各小段弦的数量;dj是各小段弦的长度,可通过多边形裁剪算法及简单数学运算得到。
定义3:外弦长,指弦落在形状区域A外部的长度,用ls, i(O)表示,显然有
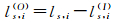 (3)
(3)
定义4:弧到弦平均投影长度,指弧段上节点到弦距离的平均值,用ls, i(P)表示,有
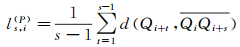 (4)
(4)
式中,

需要说明的是,特殊情况下,当Qi(xi, yi)和Qi+s(xi+s, yi+s)均在轮廓线某条边上时,即弦与边共线,此时弦既不是内弦也不是外弦,本文约定Qi(xi, yi)到Qi+s(xi+s, yi+s)直线距离长度为内弦长。
接下来,首先固定变量S,让变量i从1变化到N,可以得到N段弦,计算每条弦的内弦长、外弦长和平均投影长度,可以生成3个序列:外弦长序列{ls, 1(O), ls, 2(O), …, ls, N(O)},内外弦绝对差序列{|ls, 1(I)-ls, 1(O)|, |ls, 2(I)-ls, 2(O)|, …, |ls, N(I)-ls, N(O)|}和平均投影长度序列{ls, 1(P), ls, 2(P), …, ls, N(P)}。然后让变量S分别取21, 22, …, 2T-1,可得如下3个(T-1)×N阶矩阵:
(1) 外弦长矩阵
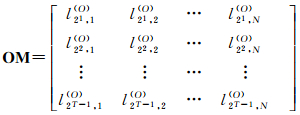 (5)
(5)
(2) 内外弦绝对差矩阵
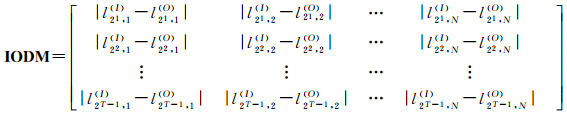 (6)
(6)
(3) 平均投影长度矩阵
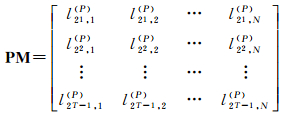 (7)
(7)
以上矩阵共同构成了一个形状描述子,记作CFM=(OM, IODM, PM),其中CFM称为弦特征矩阵描述子。
1.1.2 特征归一化处理形状特征的描述需要满足相似变换的不变性,即形状描述不会随着目标的平移、旋转和缩放变化。因此,需要对抽取的形状特征进行归一化处理。首先,当目标发生平移时,显然不会影响上述三类特征值的计算结果,因此弦特征矩阵描述子具有平移不变性。当目标发生缩放时,由于相同尺度的特征位于矩阵的同一行,可以按行进行归一化操作,保证各个尺度的特征在目标识别中具有相同的贡献。具体做法是,对矩阵的每一行的元素,用该行的最大值进行归一化处理。当目标发生旋转时,虽然三类特征值大小不会改变,但是会使起始采样点发生改变,引起矩阵元素的环形移位。为使弦特征矩阵描述子满足旋转不变性,采用傅里叶变换进行归一化操作。具体做法是:将矩阵的每一行看作一个一维的离散信号,对其进行一维离散傅里叶变换。根据傅里叶变换的原理,当一维信号发生平移时,其傅里叶变换系数的模不发生改变,这正好满足旋转不变性的要求。
以OM矩阵为例,第t行元素可表示为:{l2t, n(O)}, (n=1, 2, …, N, t=1, 2, …, T-1), 对其进行快速傅里叶变换,有
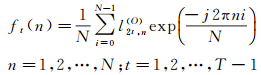 (8)
(8)
经过快速傅里叶变换后,对于每一个傅里叶系数ft(n),计算它的模|ft(n)|。由于各行独立,用各行第1个元素分别进行归一化,可使|ft(0)|=1,|ft(n)|≤1, (n>1)。用归一化后的序列替代原来的行,此时每一行向量的长度依然为N。根据傅里叶变换原理,信号的能量主要集中在低频部分,因此为了消除噪声的影响及增强描述子的紧致性[11],可取前M个低频系数(M
弦特征矩阵描述子满足平移、旋转和缩放不变性,可以通过直接比较两个形状描述子的3个矩阵来度量两个形状的差异度。设形状A、B弦特征描述子分别为αA、βA、γA和αB、βB、γB,用矩阵间的欧氏距离,即矩阵差的二范数计算形状A、B间的差异度,有
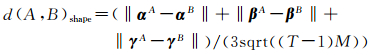 (9)
(9)
式中,‖·‖表示计算矩阵的二范数;sqrt(·)表示计算开方。由于弦特征描述子各矩阵均进行了归一化,有d(A, B)shape∈[0, 1]。从而A、B间的形状相似度可表示为
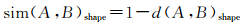 (10)
(10)
式中,sim(A, B)shape∈[0, 1]。
1.2.2 综合相似性度量模型的建立面实体的空间相似性影响因子主要包括位置、大小、方向和形状等方面,由于位置、大小和方向的相似性不是本文的研究重点,采用文献[12]中的方法并结合本文形状相似性度量模型构建综合相似性度量模型,即用目标的几何中心、面积、最小外包矩形的长轴方向度量两目标在位置、大小和方向上的相似度,用1.2.1节中方法度量形状相似性。设[σ1 σ2 σ3 σ4]T分别为描述目标A和B在位置、方向、大小和形状4个方面的相似性,wi(i=1, 2, 3, 4)为各自权重,sim(A, B)表示A和B的综合相似度,用加权平均法计算综合相似度大小,有
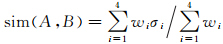 (11)
(11)
形状的复杂性是一个直观性很强却又难以定量描述的概念,现阶段学术界也没有公认的严格定义。人们直觉上通常从轮廓线长度、面积及对形状的熟悉程度来感受图形的复杂度,认为越光滑和越充实的形状越不复杂,平滑的轮廓线及较小的周长与较大的面积是光滑充实的表现[13-14]。现有的图形复杂度计算方法主要有基于多边形三角剖分[15]、基于弯曲[16-17]及基于分形[18-19]的方法等,这些方法大多不是针对地理空间数据,或者不能对凹多边形和凸多边形建立统一的度量模型[20]。本文将轮廓线弯曲看成振动的波,从波振动的频率和幅度两个方面建立复杂度描述因子,最终构建复杂性度量模型。需要说明的是,此处将轮廓线看成振动的波,只是一种类比,方便理解,与1.1.2节中傅里叶变换并无关联。
2.1 轮廓边振动频率的描述定义5:方向变化,考虑4个连续的节点,即3条连续的边,第2条边相对于第1条边的走向为向左(或右),如果下一条边的走向为向右(或左),则称这种情形为一次方向变化,也称一次振动。图 2描述了发生方向变化及不发生方向变化的情形。

|
| 图 2 方向变化举例 Fig. 2 Examples for changes of direction |
为了描述振动频率的大小,首先给出凹口的概念。
定义6:凹口,假设从轮廓的某个节点出发,沿逆时针方向运动,则每个右方向的边的起始节点处是下凹的,称该部位为轮廓形状的一个凹口。图 3展示了无凹多边形和带凹口多边形。显然,带有凹口的多边形为凹多边形,且内角大于π的节点处为凹口。对于某一多边形A,设nA为凹口数量,vA为顶点数量,用PA表示凹口的比例,有
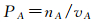 (12)
(12)

|
| 图 3 凹口举例 Fig. 3 Example of a notch |
分析发现,方向变化的数量与凹口的数量有关,如图 4所示。凹口的比例越接近于0.5,方向变化数越多,振动频率越大,形状越复杂;凹口的比例越接近于0或1,方向变化数越少,振动频率越小,形状越简单。为了使PA接近于0.5时复杂度最大、接近于0或1时复杂度最小,对PA进行非线性变换,有
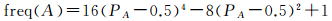 (13)
(13)

|
| 图 4 不同凹口比例的多边形 Fig. 4 Polygons with different values of vibretion frequency |
式中,freq(A)为以凹口比例为指标的复杂度描述因子。
2.2 轮廓边振动幅度的描述为定量描述振动的幅度,考察两点之间的连接,显然两点之间直线距离最短。图 5为不同复杂度多边形的凸壳。可以看出,多边形轮廓从一点到另一点的距离越长则该部位越复杂,因此可以用轮廓周长相对凸壳周长的相对增量描述振动的幅度,有
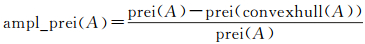 (14)
(14)

|
| 图 5 不同复杂度多边形的凸壳 Fig. 5 Convex hulls of polygon with different complexity |
式中,ampl_prei(A)为以周长为指标的复杂度描述因子;prei(·)为周长算子;convexhull(·)表示计算凸壳。
分析发现,对于凸多边形,freq(A)及ampl_prei(A)的特征值为0,不能对凸多边形复杂度进行度量。因此,利用多边形与其最小外包圆间面积的相对关系来度量不同多边形的复杂度,如图 6所示。用circle(·)表示计算最小外包圆,area(·)为面积算子,有
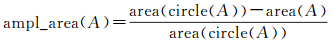 (15)
(15)

|
| 图 6 不同复杂度多边形的最小外包圆 Fig. 6 Minimum envelope of polygon with different complexity |
式中,ampl_area(A)称为以面积为指标的复杂度描述因子。
2.3 综合复杂性度量模型上述3个因子分别从轮廓的凹口比例、周长比及面积比3个方面对多边形轮廓的复杂度进行了度量。分析发现,freq(A)与ampl_prei(A)对形状复杂度描述能力较强,且当二者同时具有较大值时,复杂度较大,因此将二者相乘并分配较大权值,ampl_area(A)只用来区分凸多边形的复杂度,对其分配较小权重,从而得到能够度量凹多边形和凸多边形复杂度的计算公式
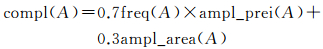 (16)
(16)
由于freq(A)、ampl_prei(A)、ampl_area(A)∈[0, 1],有compl(A)∈[0, 1]。
需要说明的是,上述权重的设置主要是依据经验设定的,本文后续会通过试验验证其合理性。当然也可根据需要,通过其他方式组合这3个因子构造综合复杂性度量模型。
3 试验验证及应用 3.1 相似性及复杂性度量模型合理性验证 3.1.1 相似性度量模型合理性验证以某面状湖泊轮廓线为原始数据,利用ArcGIS中point_remove[21]与bend_simplify[22]两种化简算法对目标以不同阈值化简,运用本文形状相似性度量模型和综合相似性度量模型分别度量化简前后的相似值,探寻相似值随化简阈值的变化情况。取参数N=128、M=10、wi=0.25(i=1, 2, 3, 4),表示化简前后在空间位置、大小、方向和形状的关注程度一致。两种化简方法初始阈值均设为1 km(实际距离),步长1 km,最大值10 km,对实心湖泊轮廓线进行化简,分别得到10个化简结果和相似值。图 7为阈值分别为4 km和5 km时,两种化简方法对应的结果。图 8显示了两种化简方法形状相似度和总相似度随化简阈值的变化规律。

|
| 图 7 两种化简方法的对比 Fig. 7 The comparison of two methods of simplification |

|
| 图 8 相似度随阈值变化图 Fig. 8 The relationships between similarity and threshold |
由于两种化简算法的参数阈值具有不同的含义,在不考虑化简程度的情况下,单纯比较同一阈值的相似度没有实际意义。但是可以看出,随着化简阈值的增加,两种化简算法所得结果的形状相似度和总相似度均逐渐减小,与人的直观感受一致,说明本文方法能够正确区分不同化简程度下目标的形状相似性和总相似性。
3.1.2 复杂性度量模型合理性验证选取中国境内某比例尺48个湖泊轮廓线为试验对象。试验前,为了减小数据自身的影响,按文献[23]方法对轮廓线中节点进行稀疏处理,删除不必要的节点。运用本文复杂性度量方法,分别计算其复杂度,按照复杂度从小到大的排序如图 9所示(未按实际大小比例绘制)。

|
| 图 9 不同湖泊轮廓线的复杂度排序 Fig. 9 Different lake contour lines according to complexity |
从图 9可以看出,复杂度越小的目标,形状越充实,轮廓线越光滑;复杂度越大的目标,形状越不规则,轮廓线越不光滑。这一结果与人们的直观感受基本一致,说明运用本文方法,能够正确区分不同目标的复杂度。
以下进一步验证复杂性度量模型的合理性,研究复杂性度量模型组成因子间的相关性。如图 10所示,(a)图为因子freq与ampl_area相对于ampl_prei的相关性曲线,(b)图为因子freq与ampl_prei相对于ampl_area的相关性曲线。可以看出,仅当ampl_prei与ampl_area值较小时(ampl_prei < 0.3, ampl_area < 0.55,即较简单的目标),其余两个因子存在一定的相关性,当数值较大时,其余两个因子不存在明显的相关性。这说明除了简单目标外,3个参数间不存在相关性。因此,运用本文3个因子进行目标复杂性度量是合理的。

|
| 图 10 复杂性度量模型组成因子的相关性 Fig. 10 Correlation of the parameters of the complexity model |
3.2 不同复杂度目标在不同尺度间的相似度探索
本文试验综合考虑目标的复杂性和相似性,探索不同复杂度的目标在不同尺度下的相似性的变化规律。试验采用浙江省舟山市某地区1:1万、1:5万、1:25万、及1:100万4种比例尺的框架数据,从中随机挑选100个面状岛屿同名实体,所有同名实体均为一一对应,如图 11所示。

|
| 图 11 试验数据(未按比例尺绘制) Fig. 11 Experimental data (not plotting by scale) |
为了直观展现不同复杂度目标在各比例尺间的相似度大小,以复杂度为横轴、相似度为纵轴绘制散点图,如图 12所示,从中可以看出,数据基本满足线性趋势。

|
| 图 12 不同复杂度目标在不同尺度间的相似度 Fig. 12 Similarity between different complexity targets at different scales |
首先利用复杂性度量方法对1:1万比例尺的100个面轮廓进行复杂度计算,按照复杂度从小到大的顺序从1到100对目标进行编号。然后分别计算1:1万比例尺与1:5万、1:25万及1:100万同名实体的相似度,部分计算结果如表 1所示。
| 样本编号 | 目标编号 | 复杂度 | 相似度 | ||
| 1:5万 | 1:25万 | 1:100万 | |||
| 1 | 5 | 0.205 5 | 0.954 5 | 0.894 9 | 0.903 6 |
| 2 | 10 | 0.221 0 | 0.971 5 | 0.9116 | 0.790 9 |
| 3 | 15 | 0.250 5 | 0.985 1 | 0.875 0 | 0.697 9 |
| 4 | 20 | 0.278 3 | 0.981 0 | 0.885 7 | 0.854 3 |
| 5 | 25 | 0.304 0 | 0.976 4 | 0.961 6 | 0.831 3 |
| 6 | 30 | 0.327 3 | 0.975 1 | 0.907 1 | 0.893 2 |
| 7 | 35 | 0.352 8 | 0.973 2 | 0.911 3 | 0.888 3 |
| 8 | 40 | 0.374 0 | 0.983 0 | 0.968 7 | 0.903 9 |
| 9 | 45 | 0.394 6 | 0.990 0 | 0.937 8 | 0.910 7 |
| 10 | 50 | 0.400 4 | 0.982 7 | 0.974 7 | 0.900 5 |
| 11 | 55 | 0.414 2 | 0.989 7 | 0.956 5 | 0.897 5 |
| 12 | 60 | 0.426 4 | 0.985 9 | 0.979 1 | 0.941 1 |
| 13 | 65 | 0.444 4 | 0.970 2 | 0.952 0 | 0.891 8 |
| 14 | 70 | 0.450 5 | 0.984 6 | 0.980 3 | 0.943 9 |
| 15 | 75 | 0.463 4 | 0.983 1 | 0.970 7 | 0.885 4 |
| 16 | 80 | 0.478 1 | 0.985 1 | 0.983 1 | 0.950 4 |
| 17 | 85 | 0.498 7 | 0.981 8 | 0.973 9 | 0.897 3 |
| 19 | 95 | 0.561 6 | 0.974 3 | 0.971 8 | 0.955 9 |
| 18 | 90 | 0.535 0 | 0.932 2 | 0.926 8 | 0.910 8 |
| 20 | 100 | 0.658 6 | 0.980 3 | 0.962 7 | 0.964 2 |
为了探索复杂度是否与相似度相关,在SPSS 20.0环境中,对1:5万、1:25万、1:100万相似度计算结果与复杂度分别进行双变量相关性分析,结果如表 2、表 3所示。其中sim(1, 5)shape、sim(1, 25)shape、sim(1, 100)shape分别为1:1万与1:5万、1:25万、1:100万比例尺间同名实体的形状相似度,compl为该实体在1:1万比例尺下的复杂度。
| 均值 | 标准差 | N | |
| compl | 0.391 9 | 0.114 1 | 100 |
| sim(1, 5)shape | 0.977 5 | 0.014 2 | 100 |
| sim(1, 25)shape | 0.942 1 | 0.037 0 | 100 |
| sim(1, 100)shape | 0.882 1 | 0.052 9 | 100 |
| sim(1, 5)shape | sim(1, 25)shape | sim(1, 100)shape | ||
| compl | Pearson相关性 | 0.271* | 0.434* | 0.515* |
| 显著性(双侧) | 0.006 | 0.000 | 0.000 | |
| N | 100 | 100 | 100 | |
| *:在0.01水平(双侧)上显著相关。 | ||||
从结果可以看出,3类相似度与复杂度之间的Pearson相关系数分别为0.271、0.434、0.515,表示二者存在不完全相关且为正相关,相关系数逐渐增大,说明随着比例尺跨度增大,相关强度逐渐增强;显著性检验P值分别为0.006、0.000、0.000,均小于0.01,表示在0.01的显著性水平上否定了二者不相关的假设,即相似度与复杂度之间存在相关关系。进一步对相似度和复杂度进行一元线性回归,得回归方程
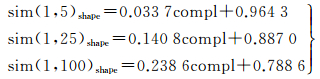 (17)
(17)
下面对回归模型进行分析,模型汇总如表 4所示。总体上看,回归模型R2均较小,拟合度较低,但是随着比例尺跨度增大,R2逐渐增大,拟合度呈现好趋势,说明随着比例尺跨度增大,相似度与复杂度的线性关系逐渐增强。D-W统计量接近于2,说明模型残差不存在自相关。
| 模型 | 因变量 | R | R2 | 调整R2 | 标准估计的误差 | Durbin- Watson |
| 1 | sim(1, 5)shape | 0.271* | 0.074 | 0.064 | 0.013 71 | 1.668 |
| 2 | sim(1, 25)shape | 0.434* | 0.188 | 0.180 | 0.033 53 | 1.941 |
| 3 | sim(1, 100)shape | 0.515* | 0.265 | 0.257 | 0.045 58 | 2.248 |
| *:预测变量(常量), compl。 | ||||||
表 5、表 6显示了方差分析和回归系数的T检验结果,回归部分的F值分别为7.786、22.706、35.306,相应的P值分别为0.006、0.000、0.000,小于显著水平0.05。可以判断复杂度对相似度解释的部分非常显著,拟合的模型具有统计学意义,回归系数的T检验结果概率值均小于0.05,回归方程的系数非常显著。另外对残差进行检验,发现残差基本服从正态分布。
| 模型 | 因变量 | 统计量 | 平方和 | df | 均方 | F | sig |
| 1 | sim(1, 5)shape | 回归 | 0.001 | 1 | 0.001 | 7.786 | 0.006* |
| 残差 | 0.018 | 98 | 0.000 | ||||
| 总计 | 0.020 | 99 | |||||
| 2 | sim(1, 25)shape | 回归 | 0.026 | 1 | 0.026 | 22.706 | 0.000* |
| 残差 | 0.110 | 98 | 0.001 | ||||
| 总计 | 0.136 | 99 | |||||
| 3 | sim(1, 100)shape | 回归 | 0.073 | 1 | 0.073 | 35.306 | 0.000* |
| 残差 | 0.204 | 98 | 0.002 | ||||
| 总计 | 0.277 | 99 | |||||
| *:预测变量(常量), compl。 | |||||||
| 模型 | 因变量 | 统计量 | 非标准化系数 | 标准系数 | t | sig | |
| B | 标准误差 | 试用版 | |||||
| 1 | sim(1, 5)shape | (常量) | 0.964 | 0.005 | 195.604 | 0.000 | |
| compl | 0.034 | 0.012 | 0.271 | 2.790 | 0.006 | ||
| 2 | sim(1, 25)shape | (常量) | 0.887 | 0.012 | 73.588 | 0.000 | |
| compl | 0.141 | 0.030 | 0.434 | 4.765 | 0.000 | ||
| 3 | sim(1, 100)shape | (常量) | 0.789 | 0.016 | 48.133 | 0.000 | |
| compl | 0.239 | 0.040 | 0.515 | 5.942 | 0.000 | ||
进一步分析回归系数发现,相邻比例尺间相似度随复杂度的回归系数较小,为0.033 7,而compl∈[0, 1],可以认为复杂度对相似度的线性影响较小。用观测值均值代替真值,有sim(1, 5)shape=0.977 5,标准差为0.014 2,说明观测数据比较接近均值,有较强的可靠性。当比例尺跨度增大时,回归系数较大,标准差随之增大,用均值代替真值会产生较大误差。同理可得其他两个相邻比例尺间相似度,有sim(5, 25)shape=0.954 9、sim(25, 100)shape=0.894 3。
综上所述,可以得出以下结论:相似度和复杂度之间存在显著的线性相关关系,且比例尺跨度越大,复杂度对相似度的影响越大。具体应用时,复杂度对相邻比例尺间相似度的影响可以忽略不计,当比例尺跨度较大时,需要考虑复杂度的影响。
3.3 利用相似性约束进行自动化简化简是制图综合的重要组成部分,在制图综合作业中占据很大比例,实现化简算法的自动化具有很强的实用意义。现阶段,针对制图综合中的化简,提出了很多算法,然而针对具体的制图综合作业过程,需要指定阈值,如Douglas-Peucker算法的最小垂距、Li-OpenShaw算法的最小圆直径等,使算法不能自动运行。本文基于上述研究结果,提出利用相似性约束进行自动化简。
3.3.1 方法流程由上文试验可知,一方面,随着化简程度的加大,相似度会逐渐减小;另一方面,相似度与比例尺变化之间存在一一对应的关系。因此,对于需要阈值参数的化简算法,可以利用相似度计算化简最佳阈值,约束化简过程。初始时,对化简算法设置一较小阈值(具体可根据目标本身的大小适当设置),然后逐渐增大化简阈值,度量不同化简阈值下的结果与原始目标之间的相似度,当相似度最接近目标相似度时,可认为取得最佳化简阈值。相似性约束的自动化简一般流程如图 13所示,其中d0为初始阈值,di为第i次阈值,s为步长,simi是阈值为di时综合结果与原始目标的相似度,sim为理论相似度。

|
| 图 13 相似性约束的自动化简一般流程 Fig. 13 General automation simplification using similarity constraint |
3.3.2 效率分析
上述方法的效率与所采用的化简算法和相似性度量算法时间复杂度及判断次数有关,各类化简算法时间复杂度不同,已有专门研究[24],此处主要分析相似性度量的时间复杂度。
相似性度量算法的时间复杂度主要与采样点数有关。设采样点数为N,计算单个内外弦长主要过程是检查弦与多边形每条边的交点,时间复杂度为O(N),则计算OM、IODM、矩阵时间复杂度为O(N(T-1)N)=O(N2log N),PM时间复杂度为O(N(21+22+…+2T-1))=O(N2T)=O(N2)。在特征归一化处理阶段,尺度归一化时间复杂度为O((T-1)N)=O(Nlog N),快速傅里叶变换时间复杂度为O(Nlog N),起点归一的时间复杂度为O((T-1)Nlog N)=O(Nlog2N),则计算CFM描述子的时间复杂度为O(2N2log N+N2+3Nlog N+3Nlog N)=O(N2log N)。相似性度量模型建立阶段时间复杂度为O(3M(T-1))=O(Mlog N),由于M
设相似性约束的化简方法需要进行R(R为自然数)次相似性判断,所采用化简算法时间复杂度为O(S),则本文方法总体时间复杂度为O(R×N2log N+R×S)=O(N2log N+S)。
从上述分析可知,相似度计算的时间复杂度主要与采样点个数N有关,且通常N在102数量级。另外,通过运用适当的搜索策略,R可以是一个不大的自然数,因此在时间效率上是可以接受的。
3.3.3 试验验证及分析以Bend_Simplify算法为例,对上述方法进行检验。试验采用前文试验地区1:5万比例尺30个面状岛屿轮廓线数据,如图 14(a)所示,现有1:25万数据如图 14(b)所示,用来对化简结果进行对比分析。采用上述方法自动综合1:25万数据,初始阈值设为50 m,步长5 m,理论相似度采用0.954 9。为了与本文方法对照,通过多次试验及专家咨询,选取150 m作为人工化简阈值。

|
| 图 14 试验数据介绍(未按实际位置和比例尺绘制) Fig. 14 Introduction of experimental data (not plotting by actual location and scale) |
按本文方法,自动计算的阈值及相似度如表 7所示。将两种方法综合结果与1:25万现有数据叠加显示,如图 15所示。采用目视比较方法[25]评价轮廓线化简结果,可以看出,两种方法综合结果与现有数据基本重合,且详细程度基本一致,说明本文方法自动设置的化简阈值是合理的。进一步分析可以发现,图 15中1、2、3、6处和4、5处(其他未一一列出),人工设置的固定阈值化简结果分别出现过度化简及化简不足的情况,而自动设置阈值化简结果情况较缓和,分析发现这是由于不同目标形态不同,传统方法对所有对象都设置相同的阈值导致的。从表 7中也可以看出,本文方法对30个目标自动计算的化简阈值各不相同(最小95 m,最大225 m),说明本文方法较好地顾及到了目标的个体差异。
| 编号 | di/m | sumi |
| 1 | 200 | 0.963 7 |
| 2 | 160 | 0.958 2 |
| 3 | 95 | 0.949 9 |
| 4 | 160 | 0.949 2 |
| 5 | 155 | 0.933 9 |
| 6 | 215 | 0.953 6 |
| 7 | 220 | 0.953 9 |
| 8 | 120 | 0.962 1 |
| 9 | 125 | 0.960 3 |
| 10 | 100 | 0.952 5 |
| 11 | 145 | 0.939 1 |
| 12 | 170 | 0.941 1 |
| 13 | 225 | 0.963 0 |
| 14 | 115 | 0.933 9 |
| 15 | 175 | 0.949 6 |
| 16 | 140 | 0.938 6 |
| 17 | 165 | 0.966 2 |
| 18 | 145 | 0.957 1 |
| 19 | 200 | 0.949 9 |
| 20 | 195 | 0.948 9 |
| 21 | 150 | 0.934 9 |
| 22 | 165 | 0.956 1 |
| 23 | 205 | 0.934 3 |
| 24 | 130 | 0.935 3 |
| 25 | 175 | 0.950 6 |
| 26 | 125 | 0.936 2 |
| 27 | 150 | 0.960 7 |
| 28 | 210 | 0.954 2 |
| 29 | 105 | 0.957 5 |
| 30 | 115 | 0.938 0 |

|
| 图 15 综合结果比较(未按实际位置和比例尺绘制) Fig. 15 Comparison of generalization results(not plotting by actual location and scale) |
3.3.4 与传统方法的比较
本文提出的利用相似性约束进行自动化简,主要是为化简算法的阈值设置提供通用的依据。优点是针对需要阈值参数的化简算法,自动计算化简阈值,降低人工参与程度,减少作业前期的阈值评估工作。本文方法与传统作业方法比较如表 8所示。
| 比较项目 | 本文方法 | 传统作业方法 |
| 阈值依据 | 相似度约束 | 制图人员经验 |
| 阈值获得方法 | 自动计算得出 | 通过多次试验,评估一个较优结果 |
| 阈值特点 | 不同对象阈值不同 | 一般同一地区采用同一阈值 |
| 优点 | 顾及个体差异,阈值自动设置 | 效率较高 |
| 缺点 | 效率相对较低 | 忽略个体差异,阈值需要事先人为评估 |
由于本文方法对每一个对象的化简结果都进行相似性判断,因此效率相对较低。针对这一问题,一方面可通过改进搜索阈值的方法,减少相似度计算的次数,提高效率;另一方面,对于某一地区,可事先选取部分要素进行试验,用计算的阈值的均值作为该地区人工选取阈值的参考,这样不仅可以降低人工评估阈值带来的不确定性,也可大大增加化简的效率。
4 结论相似性是空间数据处理的重要依据,除制图综合外,在同名实体匹配[26]、相似性查询[27]等领域均具有重要意义。复杂性作为空间对象的固有属性,是相比于面积、周长等测度更深层次的信息,其定量计算结果是目标特征的重要指标。本文将相似性和复杂性进行综合研究,可以挖掘出多尺度空间数据间潜在规律,为空间数据处理提供新的思路和方法。本文的主要工作总结如下:
(1) 针对矢量面轮廓线,通过抽取多个尺度下的内弦长、外弦长及弧到弦的平均投影长度构造弦特征矩阵,可以较好地描述形状的凹凸特性和轮廓线的弯曲程度,满足对形状的多级描述需求。通过对弦特征矩阵进行离散傅里叶变换,不仅解决了起始节点不一致问题,也增强了抗噪声干扰能力。
(2) 将轮廓线看成振动的波,从凹口比例、凸壳周长相对增量及最小外包圆面积相对增量3个方面建立复杂度描述因子,构造复杂性度量模型,可以正确区分不同复杂程度的面轮廓线,与人的主观感受一致。
(3) 将相似度模型和复杂度模型应用于化简过程,探索了不同复杂度目标在不同尺度下相似性的变化规律。从现有试验数据来看,目标本身的复杂度对邻近尺度间同名实体相似度的影响可以忽略不计,当比例尺跨度较大时,需要顾及复杂度的影响。基于这一结论,给出相似性约束的自动化简一般流程,试验表明本文方法结果合理,且增加了化简算法的自动化程度。
不同尺度目标间的相似度是否与其他因素有关,需要进一步探索;相似度约束的自动综合结果是否合理,需要进一步验证。本文利用现有综合好的数据计算不同比例尺间的相似度,并用来指导综合过程,属于基于案例的制图综合范畴,下一步可以利用本文相关模型结合深度学习等方法,研究新的自动综合方法。
| [1] |
武芳, 巩现勇, 杜佳威.
地图制图综合回顾与前望[J]. 测绘学报, 2017, 46(10): 1645–1664.
WU Fang, GONG Xianyong, DU Jiawei. Overview of the research progress in automated map generalization[J]. Acta Geodaetica et Cartographica Sinica, 2017, 46(10): 1645–1664. DOI:10.11947/j.AGCS.2017.20170287 |
| [2] |
杜佳威, 武芳, 李靖涵, 等.
采用多元弯曲组划分的线要素化简方法[J]. 计算机辅助设计与图形学学报, 2017, 29(12): 2189–2196.
DU Jiawei, WU Fang, LI Jinghan, et al. Line simplification method based on multi-bends groups division[J]. Journal of Computer-Aided Design & Computer Graphics, 2017, 29(12): 2189–2196. |
| [3] |
安晓亚, 孙群, 肖强, 等.
一种形状多级描述方法及在多尺度空间数据几何相似性度量中的应用[J]. 测绘学报, 2011, 40(4): 495–501.
AN Xiaoya, SUN Qun, XIAO Qiang, et al. A shape multilevel description method and application in measuring geometry similarity of multi-scale spatial data[J]. Acta Geodaetica et Cartographica Sinica, 2011, 40(4): 495–501. |
| [4] |
刘鹏程, 罗静, 艾廷华, 等.
基于线要素综合的形状相似性评价模型[J]. 武汉大学学报(信息科学版), 2012, 37(1): 114–117.
LIU Pengcheng, LUO Jing, AI Tinghua, et al. Evaluation model for similarity based on curve generalization[J]. Geomatics and Information Science of Wuhan University, 2012, 37(1): 114–117. |
| [5] |
马京振, 孙群, 肖强, 等.
利用多级弦长拱高复函数进行面实体综合相似性度量研究[J]. 中国图象图形学报, 2017, 22(4): 551–562.
MA Jingzhen, SUN Qun, XIAO Qiang, et al. Measurement of the comprehensive similarity of area entities using a multilevel arc-height complex function[J]. Journal of Image and Graphics, 2017, 22(4): 551–562. |
| [6] |
陈占龙, 覃梦娇, 吴亮, 等.
利用多级弦长弯曲度复函数构建复杂面实体综合形状相似度量模型[J]. 测绘学报, 2016, 45(2): 224–232.
CHEN Zhanlong, QIN Mengjiao, WU Liang, et al. Establishment of the comprehensive shape similarity model for complex polygon entity by using bending mutilevel chord complex function[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(2): 224–232. DOI:10.11947/j.AGCS.2016.20140633 |
| [7] | YAN Haowen. Quantitative relations between spatial similarity degree and map scale change of individual linear objects in multi-scale map spaces[J]. Geocarto International, 2015, 30(4): 472–482. DOI:10.1080/10106049.2014.902115 |
| [8] | YAN Haowen, LI J. Spatial similarity relations in multi-scale map spaces[M]. Geneva: Springer, 2015. |
| [9] | YAN Haowen. Theory of spatial similarity relations and its applications in automated map generalization[D]. Waterloo, Ontario, Canada: University of Waterloo, 2014. |
| [10] |
王斌, 陈良宵, 叶梦婕.
弦特征矩阵:一种有效的用于植物叶片图像分类和检索的形状描述子[J]. 计算机学报, 2017, 40(11): 2559–2574.
WANG Bin, CHEN Liangxiao, YE Mengjie. Chord-features matrices:an effective shape descriptor for plant leaf classification and retrieval[J]. Chinese Journal of Computers, 2017, 40(11): 2559–2574. DOI:10.11897/SP.J.1016.2017.02559 |
| [11] | ZHANG Dengsheng, LU Guojun. Study and evaluation of different Fourier methods for image retrieval[J]. Image and Vision Computing, 2005, 23(1): 33–49. |
| [12] |
郝燕玲, 唐文静, 赵玉新, 等.
基于空间相似性的面实体匹配算法研究[J]. 测绘学报, 2008, 37(4): 501–506.
HAO Yanling, TANG Wenjing, ZHAO Yuxin, et al. Areal feature matching algorithm based on spatial similarity[J]. Acta Geodaetica et Cartographica Sinica, 2008, 37(4): 501–506. DOI:10.3321/j.issn:1001-1595.2008.04.017 |
| [13] |
余英林.
数字图象处理与模式识别[M]. 广州: 华南理工大学出版社, 1990.
YU Yinglin. Digital image processing and pattern recognition[M]. Guangzhou: South China University of Technology, 1990. |
| [14] |
何爱玲, 王力加, 郭晶鑫, 等.
二维图形复杂度计算与叶片轮廓复杂性分析[J]. 数学计算, 2014, 3(3): 89–95.
HE Ailing, WANG Lijia, GUO Jingxin, et al. Complexity computation of two-dimensional graphics and complexity analysis of leaf contour[J]. Mathematical Computation, 2014, 3(3): 89–95. |
| [15] | TOUSSAINT G. Efficient triangulation of simple polygons[J]. The Visual Computer, 1991, 7(5-6): 280–295. DOI:10.1007/BF01905693 |
| [16] | CHAZELLE B, INCERPI J. Triangulation and shape-complexity[J]. ACM Transactions on Graphics, 1984, 3(2): 135–152. DOI:10.1145/357337.357340 |
| [17] | PAGE D L, KOSCHAN A F, SUKUMAR S R, et al. Shape analysis algorithm based on information theory[C]//Proceedings of 2003 International Conference on Image Processing. Barcelona, Spain: IEEE, 2003: I-229-32. |
| [18] | FALOUTSOS C, KAMEL I. Beyond uniformity and independence: analysis of R-trees using the concept of fractal dimension[C]//Proceedings of the 13th ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems. Minneapolis, Minnesota: ACM, 1994: 4-13. |
| [19] | PEITGEN H O, JVRGENS H, SAUPE D. Chaos and fractals:new frontiers of science[M]. New York, NY: Springer, 2004: 241-255. |
| [20] | BRINKHOFF T, KRIEGEL H P, SCHNEIDER R, et al. Measuring the complexity of polygonal objects[C]//Proceedings of the ACM-GIS. Baltimore, MD: DBLP, 1995: 109. |
| [21] | DOUGLAS D H, PEUCKER T K. Algorithms for the reduction of the number of points required to represent a digitized line or its caricature[J]. Cartographica:The International Journal for Geographic Information and Geovisualization, 1973, 10(2): 112–122. DOI:10.3138/FM57-6770-U75U-7727 |
| [22] | WANG Zeshen, MVLLER J C. Line generalization based on analysis of shape characteristics[J]. Cartography and Geographic Information Systems, 1998, 25(1): 3–15. |
| [23] |
何海威.顾及层次结构和空间冲突的道路网选取与化简方法研究[D].郑州: 信息工程大学, 2015. HE Haiwei. Research on road selection and simplification method considering hierarchical structure and spatial conflicts[D]. Zhengzhou: Information Engineering University, 2015. |
| [24] |
郭立帅, 沈婕, 朱伟.
线要素化简算法的时间复杂度分析[J]. 测绘科学技术学报, 2012, 29(3): 226–230.
GUO Lishuai, SHEN Jie, ZHU Wei. Time complexity analysis of line simplification algorithms[J]. Journal of Geomatics Science and Technology, 2012, 29(3): 226–230. DOI:10.3969/j.issn.1673-6338.2012.03.017 |
| [25] |
李成名, 殷勇, 吴伟, 等.
Stroke特征约束的树状河系层次关系构建及简化方法[J]. 测绘学报, 2018, 47(4): 537–546.
LI Chengming, YIN Yong, WU Wei, et al. Method of tree-like river networks hierarchical relation establishing and generalization considering stroke properties[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(4): 537–546. DOI:10.11947/j.AGCS.2018.20170141 |
| [26] |
孙群.
多源矢量空间数据融合处理技术研究进展[J]. 测绘学报, 2017, 46(10): 1627–1636.
SUN Qun. Research on the progress of multi-sources geospatial vector data fusion[J]. Acta Geodaetica et Cartographica Sinica, 2017, 46(10): 1627–1636. DOI:10.11947/j.AGCS.2017.20170387 |
| [27] |
艾廷华, 帅赟, 李精忠.
基于形状相似性识别的空间查询[J]. 测绘学报, 2009, 38(4): 356–362.
AI Tinghua, SHUAI Yun, LI Jingzhong. A spatial query based on shape similarity cognition[J]. Acta Geodaetica et Cartographica Sinica, 2009, 38(4): 356–362. DOI:10.3321/j.issn:1001-1595.2009.04.012 |