



2. 江苏省卫生统计信息中心, 江苏 南京 210008;
3. 南京师范大学虚拟地理环境教育部重点实验室, 江苏 南京 210023;
4. 江苏省地理信息资源开发与利用协同创新中心, 江苏 南京 210023
2. Health Statistics and Information Center of Jiangsu Province, Nanjing 210008, China;
3. Key Laboratory for Virtual Geographic Environment, Ministry of Education, Nanjing Normal University, Nanjing 210023, China;
4. Jiangsu Center for Collaborative Innovation in Geographical Information Resource Development and Application, Nanjing 210023, China
随着智能手机的普及,以及Web2.0和定位技术的发展,地理位置信息在人们的生活中发挥越来越重要的作用。位置服务(LBS)与在线社交网络(OSN)相结合的基于位置社交网络(location-based social network, LBSN)[1]迅速兴起。用户可以在访问关注点(如超市、餐馆、景点、酒店等)的同时进行签到。利用海量签到数据能够挖掘用户的访问偏好,帮助用户决策,催生了基于位置社交网络的个性化关注点推荐。关注点推荐不仅可以帮助用户探索新的区域和发现新的关注点,也可以通过智能位置服务为商家增加收入,近几年来吸引了学术界和工业界越来越多的关注[2-4]。
推荐系统是缓解信息过载的重要方法,得到了广泛的研究和应用[5-8]。与传统的推荐系统相比,关注点推荐更加复杂。除了用户偏好、地点属性之外,还需要考虑距离、时间、社交、类别、流行度等多种信息[9]。相对于传统推荐系统中的用户-物品矩阵,用户签到矩阵具有更高的稀疏度[10]。位置信息是LBSN中最重要的一个特征,目前大部分推荐研究仅利用了位置信息的某个方面,位置上下文信息没有被充分利用。此外,现有关注点推荐算法对用户访问偏好的时空变化情况考虑不足。针对上述问题,本文提出一种基于霍克斯过程(Hawkes process)的上下文感知协同过滤关注点推荐算法(HWCF),通过融合空间聚类信息、空间距离信息和空间序列变换信息等多个与位置相关的因素,结合时间信息、用户偏好、关注点流行度等多种上下文信息,提高推荐性能。
1 关注点推荐概述随着基于位置社交网络的快速发展,关注点推荐受到学术界和工业界的广泛关注。相关研究方法包括协同过滤算法(collaborative filtering,CF)[11]、矩阵分解算法、空间距离分布建模、基于好友关系、基于文本信息等。不同方法适用于不同的签到数据集,如协同过滤算法的适用范围最广,它通过计算用户-用户相似度或关注点-关注点相似度进行推荐。空间距离分布建模方法适用于具有精确地理位置的数据集,根据用户和关注点之间的距离建模。基于好友关系的关注点推荐方法适用于包含用户好友列表的数据集,通过挖掘用户与好友之间的相似度进行推荐。下面对主流关注点推荐算法进行阐述。
(1) 协同过滤法。现有的关注点推荐大部分是基于协同过滤算法[11-12]。该方法认为爱好相似的用户访问的地点也大多相同。协同过滤算法分为两种:基于用户(user-based)[12-13]的协同过滤和基于物品(item-based,将关注点看作物品)[11]的协同过滤,前者计算用户之间的相似度,后者计算关注点之间的相似度。
(2) 基于地理空间关系的方法。地理位置是关注点推荐的重要影响因素,距离用户位置越近的地点被访问的概率越大[14-15]。根据用户签到地点的距离分布进行数据建模,结果表明签到位置呈现幂律分布或者高斯分布[16-17]。结合地理空间聚集现象,对用户活动区域与关注点影响区域建模,可以缓解稀疏性问题[18]。文献[19]利用核密度估计分析关注点的二维地理坐标对用户行为的影响,并结合用户社会关系提高了推荐性能。
(3) 基于历史签到记录的方法。用户签到记录呈现一定的规律性,通过分析用户历史签到记录,可以预测下一个关注点[20-24]。如基于一阶[22-23]和n阶马尔科夫链[24]来计算用户的时空序列,仅考虑用户的最后一个签到地点,来推测下一个可能被访问的关注点。
(4) 基于社会关系的方法。用户与用户之间的社交关系(好友关系)是基于位置社交网络的重要特性,好友比陌生人更有可能分享共同的偏好。如基于好友的协同过滤方法[25]利用好友的共同签到记录进行推荐。但由于用户之间较少分享关注点签到信息,单纯利用社会关系对推荐性能提高有限[26]。
(5) 基于文本挖掘的方法。在LBSN中,用户可以对关注点打分和评论。通过文本挖掘方法建模用户对商家的点评行为[27-28],能够更准确了解用户的兴趣偏好进行推荐。
(6) 多因素融合方法。考虑到关注点推荐受多种因素影响,仅使用单一因素的推荐算法,性能往往不高。大部分研究试图融合地理空间信息、时间效应、社会关系、内容信息、流行度等多种因素来提高推荐效果[28-29]。
2 基于霍克斯过程的上下文感知关注点推荐算法 2.1 用户签到行为相似度计算为进行关注点推荐,本文使用基于用户的协同过滤算法,根据用户的签到行为计算用户之间的相似度。根据用户签到关注点的地理空间聚集现象[18]分析用户行为,提取用户特征进行相似度比较。
首先,通过基于密度的空间聚类算法DBSCAN(density-based spatial clustering of applications with noise)将一定地理范围之内的关注点聚类为簇。聚类的结果除了得到簇以外,还会得到一些不属于任何簇的噪声点。然后,根据用户Ui对兴趣簇的签到频率将用户Ui的特征表示为
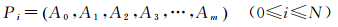 (1)
(1)
式中,A0表示用户Ui在噪声点的签到频率;Ai到Am表示用户Ui在m个簇中各自的签到频率。用户Ui在第j个簇中的签到频率被定义为
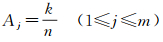 (2)
(2)
它表示用户Ui的所有n条签到记录中,有k条记录属于第j号簇。类似的,用户Ui在噪声点的活跃度定义为
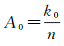 (3)
(3)
最后,根据用户的行为特征,可以计算出用户之间的相似度。如果用户i和用户j有一些签到地点属于相同的簇,例如二者在第q号簇中均有签到,则有
 (4)
(4)
式中,Sij表示用户i和用户j的相似度;Q表示用户i和用户j都访问过的簇的集合。索引q必须为正数,因此,噪声点将不会被考虑在内。根据式(4)计算的用户相似度为每个用户找出相似用户列表,从相似用户的历史访问记录中提取关注点,作为用户的候选关注点。
2.2 霍克斯过程及其适应性分析霍克斯过程是一种点过程,是1972年由Hawkes提出的一种特殊的线性自激模型[30]。该模型被广泛应用于各种领域的建模,如经济分析预测[31-32]、地震预测[33]、社交网络建模[34-35]等。霍克斯过程认为过去的事件会影响未来事件发生的概率,过去事件的激励是正的、可加的并随时间衰减的。本文将霍克斯过程引入到用户签到记录的时空序列关系分析中,公式如下
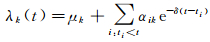 (5)
(5)
式中,λk(t)表示当前事件k(点过程)的发生强度(概率);μk≥0表示该自激过程的基础强度;αik≥0表示历史事件i对当前事件k的激励程度;δ为历史事件激励的时间衰减系数;t为当前事件k发生的时间;ti为历史事件i发生的时间。
利用霍克斯过程建模关注点推荐的适应性分析。为进行关注点推荐,可以将霍克斯过程中的事件k定义为:用户u访问了关注点lk,其发生强度为λk(t)。μk可表示为:用户u访问关注点lk的基础概率。αik可表示为:用户u访问过关注点lj这一历史事件对用户访问新关注点lk的激励程度。e-δ(t-ti)表示历史事件激励的时间衰减程度。每个用户可以根据自己的历史访问事件,建模个性化的霍克斯过程来估计访问新关注点的发生强度(概率),将发生强度λk(t)按大小排序后即可得到top-k推荐列表。下面详细描述霍克斯过程相关参数的求解过程。
2.3 自激过程的基础强度μk在关注点推荐中,用户对关注点的访问概率与用户到关注点的距离以及关注点流行度相关。本文使用改进的哈夫模型对距离和流行度进行建模,计算用户访问关注点的基础概率。
哈夫模型[36]由美国零售学者戴维哈夫提出,该模型将一个商场对顾客的吸引力归功于两个因素[37]:①商场的规模;②商场与消费者的地理距离。原始哈夫模型表示如下
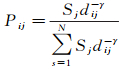 (6)
(6)
式中,Sj表示商场j的规模,可以通过营业面积算出;dij为顾客i到商场j的距离;γ为距离衰减系数。在日本通商产业省的修正哈夫模型中,把γ值确定为2[37]。这意味着,用户访问某商场的概率,与营业面积成正比,与距离的平方成反比。哈夫模型在商场选择、商业中心和零售业布局规划、购物中心市场份额预测中得到了大量应用[38-39]。本文对哈夫模型进行改进,使其适应LBSN签到数据集的特点,进而计算用户访问关注点的基础概率。
变量1:商场规模Sj。哈夫模型的原始公式需要提供商业设施的面积大小,目前所有的签到数据集都不包含这一数据,而关注点的签到次数在一定程度上反映了其规模和流行度。统计所有用户在各个关注点的签到次数vj,用签到次数的指数分布vjβ代替Sj,β为表征关注点流行度的弹性系数。
变量2:地理距离变量dij。原哈夫模型需要提供消费者和商业设施的坐标。在签到数据集中,用户的坐标是时常变化的,将用户最后一次签到记录所在的地理位置设为用户当前坐标。
用半正矢空间距离(Haversine distance)[40]来计算用户位置与候选关注点两个坐标在地平线上的距离。得到改进后的哈夫模型表示如下
 (7)
(7)
进一步对哈夫模型通过sigmod函数进行归一化处理,得到自激过程的基础强度
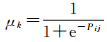 (8)
(8)
历史事件j对当前事件k的激励程度αjk可以通过关注点转移图来计算。
定义1:关注点转移图[41]。(POI to POI Transition Graph)Graph=(L, E),它包含一系列的顶点L和边E。每个顶点li(li∈L)表示一个关注点,每个关注点都有一个出度,定义为OutDegree(li),它表示从li出发访问其他关注点的频率。每条边(li, lj)∈E表示从关注点li到关注点lj的一次转移,每条边包含的转移次数的数据,定义为EdgeWeight(li, lj)。
关注点转移图描述了每个关注点转移到其他关注点及相应的数据,包括边的转移频率和顶点的出度,以及一个关注点到其他各个关注点的访问概率值。
定义2:转移概率。当关注点li的出度不为0时,即OutDegree(li)>0,则li→lj的转移概率定义为TP(li→lj),计算如下
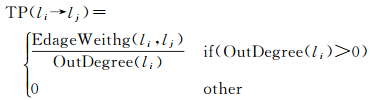 (9)
(9)
根据式(9)即可求得历史事件j对当前事件k的激励程度αik=TP(li→lk)。历史事件激励的时间衰减系数δ为自由参数,试验部分将详细介绍该参数的调整方法并对其取值进行分析。
3 试验分析 3.1 数据集描述 3.1.1 Gowalla数据集本试验使用的Gowalla数据集来自斯坦福大学公开的大型网络数据集收集网站(http://snap.stanford.edu/data/loc-gowalla.html.)。签到数据Gowalla的源数据范围覆盖了全世界,每个地方的数据密度不一,不便于数据的挖掘工作。试验选取用户签到较为密集、数据质量较高的纽约市曼哈顿区作为研究区域。地理范围为:40.60°N—40.85°N,73.89°W—75.05°W。在Gowalla数据集中,纽约市曼哈顿区共计签到75 940次,签到时间跨度为2009年2月至2010年10月。该数据集中每个签到记录的存储形式为:用户ID、关注点ID、关注点坐标位置、签到时间。过滤掉签到少于5次的用户,并保证每个关注点至少被访问过10次。过滤后的试验数据集中包含59 336条签到记录,有1612个用户共访问了2299个关注点。
3.1.2 Foursquare数据集Foursquare是基于用户地理位置信息的手机服务网站,鼓励手机用户同他人分享自己当前所在地理位置等信息。试验使用文献[42]所提供的Foursquare数据集中的日本东京签到数据集,签到时间跨度为2012年4月至2013年2月,包含573 703条签到记录。该数据集的每条签到记录存储形式为:用户ID、关注点ID、关注点类别ID、关注点类别名称、关注点坐标位置、签到时间,试验没有使用关注点类别相关信息。过滤掉签到少于10次的用户,并要求每个关注点被至少访问过10次。过滤后的试验数据集中包含357 147条签到记录,有2293个用户共访问了7866个关注点。两个数据集的统计情况如表 1所示。
| 数据集 | 用户数量 | 关注点数量 | 签到记录数量 | 平均签到次数 | 签到矩阵密度/(%) |
| Gowalla | 1612 | 2299 | 59 336 | 36.81 | 1.60 |
| Foursquare | 2293 | 7866 | 357 147 | 155.75 | 1.98 |
3.2 评价指标
在试验中,根据每个用户签到记录的时间顺序选择前80%的签到数据作为训练数据集,其余20%的签到数据作为测试数据集。根据算法计算用户到候选关注点的访问概率,并按概率大小排序后得到top-k个关注点推荐给用户。为评价推荐效果,采用推荐算法中常用的两个标准[43]:准确率(precision)和召回率(recall)作为评价指标。
准确率(precision)定义了推荐算法得出的关注点与用户实际访问的关注点相符的个数在推荐结果中所占的比例。对于某个用户u,Ru代表推荐算法的结果(result)集合,Tu代表测试集中用户u所实际签到(test)的关注点集合,准确率表示如下
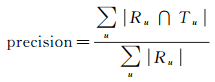 (10)
(10)
召回率定义了推荐算法得出的关注点集合Ru与用户实际访问的关注点集合Tu中相同的关注点个数在用户测试集中所占的比例,召回率表示如下
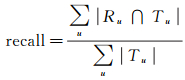 (11)
(11)
为了验证霍克斯过程模型(HWCF)的推荐效果,试验将与以下算法进行对比:
(1) HFCF。该算法对应本文所提出的霍克斯过程模型基础强度部分,利用了关注点的距离信息和流行度信息。
(2) AMC。该算法对应本文所提出的霍克斯过程模型时间影响部分,通过加和马尔可夫挖掘用户历史签到记录的时序影响。
(3) ASVD++[44]。该算法通过分解签到矩阵,挖掘用户和关注点的隐含特征,获取用户的访问偏好。计算时采用隐式评分,即将签到次数通过函数f(x)=x/K归一化到(0, 1]范围内作为评分,K是用户的最大签到次数。
(4) AOBPR[45]。该算法通过排序学习从隐式反馈中挖掘用户兴趣,并向用户推荐top-k个关注点,是比较先进的排序推荐算法。
(5) LORE[41]。该算法融合了社会关系、空间距离、流行度、用户偏好、时间信息等多种上下文信息,并取得了比其他模型更好的效果。如CoRe[19]、USG[46]等。Foursquare数据集不包含社会关系信息,将使用2.1节计算的相似用户代替朋友关系。
3.4 参数调整DBSCAN聚类算法的两个参数邻域半径和密度阈值,试验中取值分别为100和2。求解霍克斯过程模型自激强度的哈夫模型有两个参数:距离衰减系数γ和关注点流行度的弹性系数β。γ根据日本通商产业省的修正哈夫模型,取值为2,自由参数β在Gowalla数据集中设为3.5,在Foursquare中设为5。霍克斯过程模型中历史事件i对事件k的激励程度αik根据2.2节的方法计算得出。历史事件激励的时间衰减系数δ是自由参数,在Gowalla数据集中设为-0.5,在Foursquare中设为-0.001,δ越小说明衰减越低,历史事件与当前事件的时间差按小时计算。
对于霍克斯过程模型(HWCF)的两个自由参数β和δ,采用交替调参的方法来求取最佳参数:首先固定β,调整δ使推荐准确率达到最好,然后固定δ,调整β使推荐准确率达到最好,一般迭代上述过程3至5次即可达到较好的效果。
3.5 试验结果 3.5.1 方法对比各推荐算法在Gowalla数据集和Foursquare数据集上的推荐准确率和召回率分别如图 1和图 2所示。可以发现,准确率随k值的增加而下降,召回率随k值的增加而上升。如果为用户返回更多的关注点(即k值较大),就可以从中发现更多用户可能访问的关注点,但由于推荐的其余关注点的访问概率会随k值的增加而逐渐降低,导致这些关注点被用户访问的可能性也会减小,并且由于Foursquare数据集的测试数据更多,召回率会更低,从而导致算法差别不明显。

|
| 图 1 Gowalla数据集上的top-k推荐性能对比 Fig. 1 The performance comparison of top-k recommendation on Gowalla data set |

|
| 图 2 Foursquare数据集上的top-k推荐性能对比 Fig. 2 The performance comparison of top-k recommendation on Foursquare data set |
从图 1和图 2可以看出,霍克斯过程模型(HWCF)在两个试验数据集上的推荐效果远远优于基于矩阵分解的算法ASVD++和基于排序学习的算法AOBPR。这两种算法仅考虑了签到次数,没有利用空间和时间信息。虽然在Gowalla数据集中本文算法的top-1推荐性能略低于HFCF算法,但总体来看,霍克斯过程模型(HWCF)明显优于仅考虑距离和流行度信息的HFCF算法和仅考虑时序相关信息的AMC算法。尽管LORE算法利用了距离、流行度、时间、社会关系等信息,但本文算法取得了更好的效果,尤其在Gowalla数据集上的优势更为明显。
3.5.2 参数影响本文算法有两个自由参数:流行度弹7图 3和图 4分别显示了Gowalla与Foursquare数据集上两个参数的取值对推荐性能的影响,试验对比了参数取值不同时top-k(k=1,2,3,4,5)推荐的平均准确率和召回率。
当参数β≤2时两个数据集的效果都较差,这是因为距离衰减系数γ被固定为2。在Gowalla数据集中,当2.5≤β≤4时效果最好,此后平均准确率和召回率略有下降;在Foursquare数据集中,当5≤β≤6时,效果最好,此后变化并不明显。因此,一般情况下流行度弹性系数β可选取范围为3至5,表明用户签到概率与关注点流行度成指数关系,这也反映了一些实际现象,比如知名度高的景点游客数量可能达到普通景点游客数量的几十倍。

|
| 图 3 Gowalla数据集上的参数β(a)和参数δ(b)的影响 Fig. 3 The influence of β and δ on Gowalla data set |

|
| 图 4 Foursquare数据集上的参数β(a)和参数δ(b)的影响 Fig. 4 The influence of β and δ on Foursquare data set |
参数δ在两个数据集中差异较大。在Gowalla数据集中,当δ>-0.1时,推荐效果下降明显,当δ=0(无衰减)时效果最差,当δ≤-0.3时差别不大。而在Foursquare数据集中,当δ=-0.001时取得最大值,当δ=0(无衰减)时,效果略低于最大值,当δ值减小时推荐效果变化不明显。这是因为Foursquare数据集中历史签到影响的时间衰减程度远远低于Gowalla数据集。因此,在时间衰减越小的数据集中,|δ|取值应越小。
4 总结针对关注点推荐本文提出了基于霍克斯过程模型的上下文感知协同过滤推荐算法HWCF,综合利用了空间聚类信息、空间距离信息、空间序列变换信息、时间信息、用户个性化历史偏好、全体用户偏好、关注点流行度信息等多个上下文信息,在一定程度上缓解了数据稀疏的问题,并在真实的LBSN数据集中进行了试验验证。与其他关注点推荐方法相比,HWCF算法的推荐质量有显著提高。
HWCF算法仍有很大改进空间,在未来工作中,将进一步融合其他上下文信息,如关注点类别信息、用户文本评论信息、评分信息、时间周期规律等进一步提高推荐质量。本文提出的霍克斯模型的参数本质上是基于马尔可夫决策过程计算得出的,在线上推荐时,可以尝试引入深度强化学习建模用户的动态转移概率对该参数进行优化。
| [1] | GAO Huji, LIU Huan. Mobile Social Networking: Data Analysis on Location-based Social Networks[M]. New York, NY: Springer, 2014. |
| [2] |
王勇, 刘纪平, 郭庆胜, 等.
顾及位置关系的网络POI地址信息标准化处理方法[J]. 测绘学报, 2016, 45(5): 623–630.
WANG Yong, LIU Jiping, GUO Qingsheng, et al. The Standardization Method of Address Information for POIs from Internet Based on Positional Relation[J]. Acta Geodaetica et Cartographica Sinica, 2016, 45(5): 623–630. DOI:10.11947/j.AGCS.2016.20150618 |
| [3] |
杨敏, 艾廷华, 卢威, 等.
自发地理信息兴趣点数据在线综合与多尺度可视化方法[J]. 测绘学报, 2015, 44(2): 228–234.
YANG Min, AI Tinghua, LU Wei, et al. A Real-time Generalization and Multi-scale Visualization Method for POI Data in Volunteered Geographic Information[J]. Acta Geodaetica et Cartographica Sinica, 2015, 44(2): 228–234. |
| [4] | KEFALAS P, MANOLOPOULOS Y. A Time-aware Spatio-textual Recommender System[J]. Expert Systems with Applications, 2017, 78: 396–406. DOI:10.1016/j.eswa.2017.01.060 |
| [5] | XU Hongsheng, ZHANG Ruiling, LIN Chunjie, et al. Construction of E-commerce Recommendation System Based on Semantic Annotation of Ontology and User Preference[J]. Indonesian Journal of Electrical Engineering and Computer Science, 2014, 12(3): 2028–2035. |
| [6] | GUPTA Y, SAINI A, SAXENA A K. A New Fuzzy Logic Based Ranking Function for Efficient Information Retrieval System[J]. Expert Systems with Applications, 2015, 42(3): 1223–1234. DOI:10.1016/j.eswa.2014.09.009 |
| [7] | COVINGTON P, ADAMS J, SARGIN E. Deep Neural Networks for YouTube Recommendations[C]//Proceedings of the 10th ACM Conference on Recommender Systems. Boston, MA: ACM, 2016: 191-198. |
| [8] |
徐志明, 李栋, 刘挺, 等.
微博用户的相似性度量及其应用[J]. 计算机学报, 2014, 37(1): 207–218.
XU Zhiming, LI Dong, LIU Ting, et al. Measuring Similarity between Microblog Users and Its Application[J]. Chinese Journal of Computers, 2014, 37(1): 207–218. |
| [9] |
任星怡, 宋美娜, 宋俊德.
基于位置社交网络的上下文感知的兴趣点推荐[J]. 计算机学报, 2017, 40(4): 824–841.
REN Xingyi, SONG Meina, SONG Junde. Context-aware Point-of-interest Recommendation in Location-Based Social Networks[J]. Chinese Journal of Computers, 2017, 40(4): 824–841. |
| [10] | YU Yonghong, CHEN Xingguo. A Survey of Point-of-Interest Recommendation in Location-Based Social Networks[C]//Workshops at the Twenty-ninth AAAI Conference on Artificial Intelligence. Washington, DC: AAAI, 2015. |
| [11] | BAO Jie, ZHENG Yu, MOKBEL M F. Location-Based and Preference-aware Recommendation Using Sparse Geo-social Networking Data[C]//Proceedings of the 20th International Conference on Advances in Geographic Information Systems. Redondo Beach, CA: ACM, 2012: 199-208. |
| [12] | CHENG Chen, YANG Haiqin, LYU M R, et al. Where You Like to go Next: Successive Point-of-interest Recommendation[C]//Proceedings of the Twenty-third International Joint Conference on Artificial Intelligence. Beijing: AAAI Press, 2013. |
| [13] | LEVANDOSKI J J, SARWAT M, ELDAWY A, et al. LARS: A Location-aware Recommender System[C]//Proceedings of the 28th International Conference on Data Engineering. Washington, DC: IEEE, 2012: 450-461. |
| [14] | JAMALI M, ESTER M. Trustwalker: A Random Walk Model for Combining Trust-based and Item-based Recommendation[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Paris: ACM, 2009: 397-406. |
| [15] | KONSTAS I, STATHOPOULOS V, JOSE J M. On Social Networks and Collaborative Recommendation[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. Boston, MA: ACM, 2009: 195-202. |
| [16] | YIN Hongzhi, CUI Bin, SUN Yizhou, et al. LCARS:A Spatial Item Recommender System[J]. ACM Transactions on Information Systems, 2014, 32(3): Article No. 11. |
| [17] | HU Bo, ESTER M. Spatial Topic Modeling in Online Social Media for Location Recommendation[C]//Proceedings of the 7th ACM Conference on Recommender Systems. Hong Kong, China: ACM, 2013. |
| [18] | LIAN Defu, ZHAO Cong, XIE Xing, et al. GeoMF: Joint Geographical Modeling and Matrix Factorization for Point-of-interest Recommendation[C]//Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY: ACM, 2014: 831-840. |
| [19] | ZHANG Jiadong, CHOW C Y. CoRe:Exploiting the Personalized Influence of Two-dimensional Geographic Coordinates for Location Recommendations[J]. Information Sciences, 2015, 293: 163–181. DOI:10.1016/j.ins.2014.09.014 |
| [20] | LIU Yong, WEI Wei, SUN Aixin, et al. Exploiting Geographical Neighborhood Characteristics for Location Recommendation[C]//Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management. Shanghai: ACM, 2014: 739-748. |
| [21] | LIAN Defu, XIE Xing, ZHENG V W, et al. CEPR:A Collaborative Exploration and Periodically Returning Model for Location Prediction[J]. ACM Transactions on Intelligent Systems and Technology, 2015, 6(1): Article No. 8. |
| [22] | YING J J C, LEE W C, TSENG V S. Mining Geographic-temporal-semantic Patterns In Trajectories for Location Prediction[J]. ACM Transactions on Intelligent Systems and Technology, 2013, 5(1): Article No. 2. |
| [23] | ZHENG V W, ZHENG Yu, XIE Xing, et al. Towards Mobile Intelligence:Learning from GPS History Data for Collaborative Recommendation[J]. Artificial Intelligence, 2012, 184-185: 17–37. DOI:10.1016/j.artint.2012.02.002 |
| [24] | KURASHIMA T, IWATA T, HOSHIDE T, et al. Geo Topic Model: Joint Modeling of User's Activity Area and Interests for Location Recommendation[C]//Proceedings of the Sixth ACM International Conference on Web Search and Data Mining. Rome, Italy: ACM, 2013: 375-384. |
| [25] | YE Mao, YIN Peifeng, LEE W C. Location Recommendation for Location-based Social Networks[C]//Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems. San Jose, CA: ACM, 2010: 458-461. |
| [26] | CHENG Cheng, YANG Haiqin, KING I, et al. Fused Matrix Factorization with Geographical and Social Influence in Location-based Social Networks[C]//Proceedings of the 26th AAAI Conference on Artificial Intelligence. Toronto, Ontario: AAAI, 2012. |
| [27] | YANG Dingqi, ZHANG Daqing, YU Zhiyong, et al. A Sentiment-enhanced Personalized Location Recommendation System[C]//Proceedings of the 24th ACM Conference on Hypertext and Social Media. Paris: ACM, 2013: 119-128. |
| [28] | LIU Bin, FU Yanjie, YAO Zijun, et al. Learning Geographical Preferences for Point-of-interest Recommendation[C]//Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Chicago, IL: ACM, 2013: 1043-1051. |
| [29] |
任星怡, 宋美娜, 宋俊德.
基于用户签到行为的兴趣点推荐[J]. 计算机学报, 2017, 40(1): 28–51.
REN Xingyi, SONG Meina, SONG Junde. Point-of-Interest Recommendation Based on the User Check-in Behavior[J]. Chinese Journal of Computers, 2017, 40(1): 28–51. |
| [30] | LINIGER T J. Multivariate Hawkes Processes[J]. Zürich:Eidgenössische Technische Hochschule, 2009, 1: 367–378. |
| [31] | FILIMONOV V, BICCHETTI D, MAYSTRE N, et al. Quantification of the High Level of Endogeneity and of Structural Regime Shifts in Commodity Markets[J]. Journal of International Money and Finance, 2014, 42: 174–192. DOI:10.1016/j.jimonfin.2013.08.010 |
| [32] | BOWSHER C G. Modelling Security Market Events in Continuous Time:Intensity Based, Multivariate Point Process Models[J]. Journal of Econometrics, 2007, 141(2): 876–912. DOI:10.1016/j.jeconom.2006.11.007 |
| [33] | ADAMOPOULOS L. Cluster Models for Earthquakes:Regional Comparisons[J]. Journal of the International Association for Mathematical Geology, 1976, 8(4): 463–475. DOI:10.1007/BF01028982 |
| [34] | LI Juncen, GAO Sheng, ZHAO Yu, et al. Inferring Links in Cascade Through Hawkes Process Based Diffusion Model[C]//Proceedings of the 4th IEEE International Conference on Network Infrastructure and Digital Content. Beijing: IEEE, 2014. |
| [35] |
于岩, 陈鸿昶, 于洪涛.
基于霍克斯过程的社交网络用户关系强度模型[J]. 电子学报, 2016, 44(6): 1362–1368.
YU Yan, CHEN Hongchang, YU Hongtao. A Social Networks User Relationship Strength Model Based on Hawkes Process[J]. Acta Electronica Sinica, 2016, 44(6): 1362–1368. DOI:10.3969/j.issn.0372-2112.2016.06.015 |
| [36] | ACHABAL D D, GORR W, MAHAJAN V. MULTILOC:A Multiple Store Location Decision Model[J]. Journal of Retailing, 1982, 58(2): 5–25. |
| [37] |
李永浮, 潘浩之, 田莉, 等.
哈夫模型的修正及其在城市商业网点规划中应用——以江苏省常州市为例[J]. 干旱区地理, 2014, 37(4): 802–811.
LI Yongfu, PAN Haozhi, TIAN Li, et al. Modification of Huff Model and Its Application in Urban Commercial Network Planning:A Case of Changzhou City, Jiangsu Province[J]. Arid Land Geography, 2014, 37(4): 802–811. |
| [38] | HUFF D L. Parameter Estimation in the Huff Model[J]. ArcUser, 2003: 34–36. |
| [39] | BERRY B J L, PARR J B, EPSTEIN B J, et al. Market Centers and Retail Location:Theory and Applications[M]. Prentice: Prentice Hall, 1988: 497-499. |
| [40] | RENFREE J. Distance Calculation Using Haversine Formula[DB/OL]. (2014-08-26)[2017-01-02].https://www.mathworks.com/matlabcentral/fileexchange/27785-distance-calculation-using-haversine-Eormula. |
| [41] | ZHANG Jiadong, CHOW C Y. Spatiotemporal Sequential Influence Modeling for Location Recommendations:A Gravity-based Approach[J]. ACM Transactions on Intelligent Systems and Technology, 2015, 7(1): Article No. 11. |
| [42] | YANG Dingqi, ZHANG Daqing, ZHENG V W, et al. Modeling User Activity Preference by Leveraging User Spatial Temporal Characteristics in LBSNs[J]. IEEE Transactions on Systems, Man, and Cybernetics:Systems, 2015, 45(1): 129–142. DOI:10.1109/TSMC.2014.2327053 |
| [43] | KARYPIS G. Evaluation of Item-Based Top-N Recommendation Algorithms[C]//Proceedings of the Tenth International Conference on Information and Knowledge Management. Atlanta, GA: ACM, 2001: 247-254. |
| [44] | KOREN Y. Factorization Meets the Neighborhood: A Multifaceted Collaborative Filtering Model[C]//Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Las Vegas, NV: ACM, 2008: 426-434. |
| [45] | RENDLE S, FREUDENTHALER C. Improving Pairwise Learning for Item Recommendation from Implicit Feedback[C]//Proceedings of the 7th ACM International Conference on Web Search and Data Mining. New York, NY: ACM, 2014: 273-282. |
| [46] | YE Mao, YIN Peifeng, LEE W C, et al. Exploiting Geographical Influence for Collaborative Point-of-interest Recommendation[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval. Beijing: ACM, 2011: 325-334. |