



2. 俄亥俄州立大学土木与环境工程系, 美国 俄亥俄 43210
2. Department of Civil, Environment and Geodetic Engineering, Ohio State University, Ohio 43210, USA
基于影像的三维重建是摄影测量学、机器人、同步定位和构图及文物保护等领域的研究热点。基于二维影像的三维重建主要包含两个主要步骤,如图 1所示。第一个步骤是从运动恢复结构(structure from motion, SfM)。通过特征提取算法提取影像上的特征点,计算影像上同名像点对,计算相机间的相对运动从而获取到相机的外方位元素和重建稀疏点云。第二个步骤是影像的多视角立体匹配。基于第一个步骤后获取到的图像内外方位元素,采用立体匹配算法获取稠密的三维点云。本文不展开讨论这部分内容。

|
| 图 1 标准的三维重建流程 Fig. 1 The standard 3D reconstruction pipeline |
SfM的主要过程如下。首先通过特征提取算法在影像上提取兴趣点,通过不同的特征描述符算法对以兴趣点为中心的图像块进行描述,比如SIFT[1]、SURF[2]、ORB[3]和BRISK[4]。然后通过比较兴趣点的描述符,从而获取到影像上的初始同名像点对。这些初始的同名像点对中包含了一部分错误的同名像点对。根据影像间的单应矩阵或基础矩阵表征的像点间的对应关系,通过RANSAC算法剔除影像间的错点,保留正确的同名像点对。通过相对定向,依据同名像点对获取相机间的相对位置和朝向。最后,光束法平差被用来优化相机的位置和姿态。这整个过程被称为SfM。SfM可分为增量SfM和全局SfM。其中,前者是指逐一计算相机的姿态,后者是同时计算所有相机的姿态[5]。
图像匹配是整个SfM阶段中最耗时的部分。主要原因是特征和描述符的提取以及描述符的匹配本身就是非常耗时,比如摄影测量中常用的经典SIFT算子。为了提高特征提取匹配的效率,文献[6]提出了基于GPU的SIFT算子。但是图像匹配耗时的另外一个原因是通常情况下图像间匹配是穷举匹配,比如常见的开源软件Bundler[7]、VisualSFM[8]和MVE[9]等。当二维影像是高分辨率影像时,直接使用图像的特征来逐一进行所有图像对的特征匹配的效率非常低。在摄影测量中,许多工程在获取影像的同时也会获取GPS数据。这种情况下图像间的关系表可以通过GPS数据来估计,从而避免穷举匹配。
但是,大多数情况下获取的数据并没有预先规划好航迹,没有GPS信息,仅仅只有影像信息,即图像间的重叠信息是确定的。在这种情况下,需要把一张影像和其余所有的影像进行匹配。假定总共有N张影像,那么需要匹配
随着计算机性能的不断提升及大数据时代的到来,深度学习技术已经在计算机视觉、自然语言处理和语音识别等领域取得了巨大的成功[10]。深度学习是由多层神经网络构成。神经网络中的一层,就是一个线性变换加上一个简单的非线性操作,而多层神经网络就是多个简单的非线性函数的组合。卷积神经网络(convolutional neural networks, CNN)是深度学习中神经网络的一种,已大量用于检测、分割、物体识别及图像处理的各个领域。Fischer(arXiv Preprint arXin:1405.5769, 2014)通过比较CNN特征和SIFT特征,发现通过AlexNet[11]提取的特征描述符远远超过SIFT。AlexNet神经网络是在包含有超过1400万张影像的数据集上训练而成。在没有大量的数据集时,需要采用迁移学习。迁移学习是指把在特定的数据集上训练好的模型运用到新的领域中,它可以解决训练样本不足的问题[12]。本文提出了基于迁移学习的深度卷积特征的影像关系表创建方法。
2 研究现状图像匹配是SfM过程中非常耗时的阶段。如果采用穷举匹配,那么整个过程的计算复杂度约为O(n2),其中n为影像数。为解决影像对匹配耗时的问题,文献[13]在2011年提出了基于SIFT特征的词汇树算法。该算法通过层次K均值树来量化每张影像上提取到的特征描述符,通过TD-IDF对特征进行加权,用于描述每张影像。通过影像检索的方式避免穷举匹配。文献[14]通过一个包含1600万视觉单词的视觉字典把所有的影像转化到一个逆文件上,进而区分出有连接关系的图像像对。为了提高词汇书构建的效率,文献[15]提出了基于GPU的多层词汇树构建影像关系表方法。最近开源的COLMAP[16]上为避免穷举匹配,提出一种在图像检索时,构建词汇树,并使用Vote-and-Verify策略[17]。这类方法本质上均属于通过构建视觉字典,然后通过图像检索来避免无效匹配的方法。
回环检测是同步定位和构图领域的研究问题,其是解决移动机器人的闭环重定位,提高系统稳定性的必要步骤。虽然,构建影像关系表和回环检测是两个不同领域的问题,但二者有一定的相似性,均可以计算影像的相似度。因此,了解回环检测的研究现状有助于研究影像关系表的构建。其中大量的方法是通过提取影像上的特征,构建视觉字典,然后通过概率模型来实现回环检测。该类方法可以统称为词袋法(bag-of-visual-words, BoVW)[18-20]。其中,DBoW2[20]是目前最先进的SLAM系统之一,ORB-SLAM2[21]上所采用的回环检测方法。随着深度学习的涌现,有研究人员利用深度学习的方法来解决回环检测的问题。文献[22]提出利用多层的自编码器来表征影像特征,然后通过自编码器提取的特征计算影像间的相似度。文献[23]提出利用已经训练好的深度学习模型OverFeat的全链接层的信息表征影像特征,进而计算影像的相似度。通过设置阈值来计算回环检测。
受深度学习及SLAM回环检测领域的研究启发,本文提出基于迁移学习的深度卷积层特征的影像关系表创建方法。
3 基于迁移学习的深度卷积层特征的影像关系表创建方法目前主流的开源SfM和SLAM系统均采用基于视觉字典的方法来创建影像关系,本文则提出基于VGG网络的卷积层特征来创建影像关系表方法。本文算法的流程如图 2所示。首先用已经在ImageNet上训练好的神经网络VGG提取给定影像的三维特征图,然后对特征图进行操作,提取其卷积层特征,根据提取的特征,计算影像间的相似度。通过计算每一张影像和其余所有影像的相似度,这样可以获取数据集的相似性矩阵,通过设置阈值,获取影像的关系表。

|
| 图 2 基于迁移学习的深度卷积层特征的影像相似度计算流程 Fig. 2 Flowchart of image similarity calculation based on deep convolutional features through transfer learning |
3.1 VGG-16模型简介
VGG网络是牛津大学的Simonyan在2014年提出的卷积神经网络,并在该年ImageNet的定位和分类比赛中分别排名第一和第二。与之前的模型相比,该模型加宽和加深了网络结构,它的核心是5组卷积操作,每二组之间采用2×2最大池化(max pooling)空间降维。同一组内采用多层次连续的3×3卷积,卷积核的数目由开始的64层变为最后的512层卷积核, 同一组内的卷积核的数目是一样的。卷积层之后是两个结点数为4096的全连接层,最后一层为结点数为1000的分类层。由于每组内卷积层的不同,因此,VGG模型有11、13、16和19层等多种模型结构。16层和19层网络的VGG模型的性能明显优于11层和13层网络的模型,但二者的性能区别不大(arXiv preprint arXiv:1409.1556, 2014)。对于一张分辨率为224的3通道图像,其总参数超过138万个。本文在这里选用VGG-16的网络模型,其模型结构如下图 3所示。

|
| 图 3 VGG-16网络的模型结构 Fig. 3 The structure of VGG-16 network model |
3.2 基于VGG-16模型的卷积层特征的图像表达
VGG-16网络的每一层均可以用来表达图像。最初研究人员利用第一层全连接层特征表达图像[24-25]。卷积神经网络全连接层特征在各种图像分类和检索的领域中都比传统的手工设计的SIFT和SURF等算子提取的特征要好。随后,研究人员发现在图像检索领域,最后一层卷积层后的池化层表达的特征比全连接层的特征效果要好,因为卷积层仍然保留了图像原始的空间语义信息[26](arXiv preprint arXiv:1511.05879, 2015)。因此,本文选用了VGG网络中第13层后的池化层后的特征作为图像的特征表达,具体计算方法如下。
假定ζ∈R(K×W×H)是从第l层网络中提取的三维特征张量。其中,K是卷积核的数目,W和H分别是特征张量的空间维度。显然,W和H的值依赖于原始影像的大小。如果定义ζkij为在第k个卷积核上空间位置(i, j)的特征。
(1) 和池化。首先,采用和池化作为该卷积核的深度特征。第l层网络上的第k个卷积核表征的图像特征则可以定义为
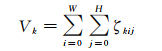
(2) 基于和池化特征的图像表达。包含有K个卷积核网络的第l层网络中的图像特征则可以表达为
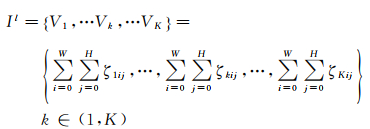
然后,把图像特征归一化,则可以得到归一化图像特征:

其中,V′k表示归一化后的第k个卷积核表征的图像特征。
3.3 影像关系表的构建假定两张影像i、j的深度特征分别为Ii和Ij,本文采用两个向量间的夹角的余弦来衡量两个特征的相似度S(i, j)
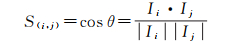
式中,θ为两向量间的夹角。计算每张影像和其余所有影像的相似度,这样就获取了整个数据集的相似性矩阵。因为每张影像不可能与其余所有影像都有重叠关系,通过设置阈值,即设置每张影像和剩余多少张影像有重叠区域。本文把阈值设置为10,即每张影像和其相似度最大的10张影像构成影像关系表。
4 试验过程 4.1 试验数据本文选取了两组数据来验证本文提出的方法的有效性。两组数据的基本情况如下表 1所示。第1组数据Urban来自武汉某公司,该数据集包含387张分辨率为4608×2592像素的DMC-GH4影像。该影像集均为俯视图。该次飞行试验共包括9条航带。数据的航向重叠度和旁向重叠度分别约为75%和65%。该试验的无人机的轨迹符合摄影测量中的作业规范,相邻摄站的间距较为一致。该试验场地主要包含裸地、草地、道路、房屋和湖泊等。第2组数据来自苏黎世理工大学的South Building数据集[15]。该数据集为128张高分辨率的DMC-TZ3影像。相机围绕着北卡罗纳大学教堂山分校的South Building建筑进行拍摄,该影像集均为侧视图。摄站间没有很强的规律性。该试验场地主要包含房屋和植被。
| 数据名称 | 数据来源 | 影像数 | 分辨率/像素 | 相机参数 | 焦距/mm | 是否规划轨迹 |
| Urban | 武汉某公司 | 387 | 4608×2592 | DMC-GH4 | 14 | 是 |
| South Building | 苏黎世理工大学 | 128 | 3072×2304 | DMC-TZ3 | 5 | 否 |
利用商业软件Agisoft LLC公司发布的软件Photoscan生成的两组数据的轨迹和相机的位置信息如图 4所示。可以发现Urban数据集相机的分布呈现明显的规律性,相机拍摄地点均匀地分布在9条轨迹上。而South Building数据集的相机分布则没有明显的规律,整个数据集由两次分布叠合而成。

|
| 图 4 试验中两组数据 Fig. 4 The top view of camera distributions in the experiments (圆点表示相机的相对位置,线段表示无人机的轨迹。) |
4.2 试验结果
本文将利用基于深度卷积特征创建的影像关系表(为方便表述,将本文提出的方法简称为DCF)同目前最先进的SLAM系统ORB-SLAM2中的DBoW3算法的结果进行了对比。为进一步验证关系表能够适用于SfM,本文使用开源软件MicMac[27]比较了穷举匹配(exhaustive matching, EM),利用本文提出的基于用深度特征创建的影像关系表和利用DBoW3创建的关系表后的SfM重建结果。
4.2.1 数据集Urban本文提出的DCF和DBoW算法生成的关系表如下图 5所示。总体上看,两种方法建立的关系表较为一致,都能够较好地鉴别出在航向和旁向上有重叠的影像对。但是,DBoW3方法建立的影像关系表存在大量的噪点,即两张影像明显不是相邻关系,但该方法却将两张影像检测成相邻关系。

|
| 图 5 基于(a)本文提出DCF和(b)DBoW3方法计算的Urban数据集的影像关系表。浅色的像素块表示两张影像有重叠关系,而深色的像素块表示影像无重叠关系 Fig. 5 The correlation graph of the Urban dataset determined by (a) the proposed DCF and (b) DBoW3 approaches. The light color squares denote that two images are connected, and the dark are not |
MicMac软件提供了多种重建模式,其中包括穷举匹配模式和提供影像关系表的重建模式。图 6展示了(a)EM穷举匹配,(b)基于本文提出的DCF关系表的匹配和(c)基于DBoW3关系表的匹配的Urban数据集SfM重建的点云图。从中可以看出,这3种方法都能够较好地重建场景,目视效果差别不大。

|
| 图 6 SfM重建Urban数据集的三维点云 Fig. 6 SfM reconstruction results for the Urban dataset |
本文也比较了3种不同模式的SfM重建后的相机相对位置和姿态。图 7和图 8分别表示3种方法重建后获取的角元素(Phi, Omega和Kappa)和线元素(X, Y和Z)的对比图。从中可以看出3种方法获取的相机姿态较为接近,差别不大。可以发现,3种方法都能够较好地重建Urban场景, 且差别不大。

|
| 图 7 3种不同模式SfM重建后的相机的角元素 Fig. 7 SfM Camera orientations for the Urban dataset |

|
| 图 8 3种不同模式SfM重建后的相机的线元素 Fig. 8 SfM Camera positions for the Urban dataset |
4.2.2 数据集South Building
本文提出的DCF和DBoW算法生成的关系表如图 9所示。总体上看,两种方法建立的关系表有一定的相似性,大致轮廓比较接近。但两种方法建立的关系表有明显的不同,DBoW3方法建立的影像关系表存在大量的噪点,即两张影像明显不是相邻关系,但该方法却将两张影像检测成相邻关系。

|
| 图 9 基于(a)本文提出DCF和(b)DBoW3方法计算的South Building数据集的影像关系表,浅色的像素块表示两张影像有重叠关系,而深色的像素块表示影像无重叠关系 Fig. 9 The correlation graph of the South Building dataset determined by (a) the proposed DCF and (b) DBoW3 approaches. The light color squares denote that two images are connected, and dark blues are not |
图 10展示了(a)EM穷举匹配,(b)基于本文提出的DCF关系表的匹配和(c)基于DBoW3关系表的匹配的Urban数据集SfM重建的点云图。从中可以看出,这3种方法都能够较好地重建场景。但DBoW3的方法重建的建筑右侧的树木的位置明显偏离了原有位置,同其余两种方法存在一定的差异。本文提出的DCF方法重建结果和EM穷举匹配的结果则非常接近。

|
| 图 10 SfM重建South Building数据集的三维点云 Fig. 10 SfM reconstruction results for the South Building dataset |
本文也比较了3种不同模式的SfM重建后的相机相对位置和姿态。图 11和图 12分别表示3种方法重建后获取的角元素(Phi, Omega和Kappa)和线元素(X, Y和Z)的对比图。从中可以看出3种方法获取的相机角元素较为接近,差别不大,但DBoW3获取的相机的线元素同其余两种方法的差异非常大,而本文提出的DCF方法则同穷举匹配的方法获取的相机位置和姿态基本一致。

|
| 图 11 Building数据集SfM重建后的相机的角元素 Fig. 11 SfM camera orientations for the South Building dataset 3种不同模式对South |

|
| 图 12 3种不同模式对South Building数据集SfM重建后的相机的线元素 Fig. 12 SfM Camera positions for the South Building dataset |
4.2.3 讨论
从上文的试验中,可以看出3种匹配模式,包括EM穷举匹配、基于DCF与DBoW3关系表匹配下的Urban场景重建的结果比较接近,没有明显差别。在South Building场景下,基于DCF关系表匹配与EM穷举匹配的结果比较接近,而DBoW3重建的结果和前二者差别较大。
表 2对比了3种匹配模式包括EM穷举匹配、基于DCF和DBoW3关系表匹配下的匹配次数和三维点云个数。可见,EM穷举匹配的次数远远超过了基于DCF和DBoW3关系表匹配次数。假定数据集包含N张影像,那么EM穷举匹配则需要匹配N×(N-1)次,而基于DCF关系表匹配则需要N×n(n为每张影像需要匹配的次数,在本文中为10。可见,基于关系表的匹配能明显减少匹配次数,提高重建效率。但是,基于穷举匹配的场景重建的点云数量最多,基于DCF关系表重建的数量次之,基于DBow3关系表重建的点云数量最少。这也从侧面反映出基于DCF重建的关系表比DBoW3方法效果更好,因为该方法能够找出更多的匹配像对,而DBoW3方法则丢失了相对更多的潜在影像对。另外,基于DCF和DBoW3关系表的匹配,均丢失了一定数量的潜在匹配相对,因此,重建出的点云个数比穷举匹配要少。
| 方法 | 匹配次数/(次) | 三维点云数/(个) | |||
| Urban | South Building | Urban | South Building | ||
| EM | 149 382 | 16 256 | 5 530 165 | 4 249 623 | |
| DCF | 3870 | 1280 | 4 963 505 | 4 003 618 | |
| DBoW3 | 3870 | 1280 | 4 644 228 | 3 528 917 | |
5 结论
本文提出了一种适用于从运动恢复结构的基于深度卷积层特征的影像关系表构建方法。该方法能够高效快速地从大量无序的数据集中构建影像关系表,找出潜在的匹配像对。相比于传统的基于人工设计特征的词袋法,本文提出的基于深度卷积层特征能更好地表达影像特征。同穷举匹配相比,本文算法在Urban和South Building数据集上都能够明显地减少匹配次数,加快重建效率,而且保持重建的效果基本一致。同主流的ORB-SLAM2系统中的DBoW3算法相比,本文提出的基于深度卷积特征的DCF算法构建的影像关系表明显优于DBoW3算法,能够更好地找出潜在的匹配像对,这一优势在South Building数据集上得到了明显的体现。综上,本文提出的基于深度卷积特征DCF算法能够在包含大量影像的数据集上快速创建影像关系表,减少影像匹配次数,在提高SfM重建的效率的基础上同时保持了SfM重建的精度。
致谢: 感谢晏磊教授对本文的试验提供的指导,感谢俄亥俄州立大学的Photogrammetric Computer Vision提供的试验设备。
| [1] | LOWE D G. Object Recognition from Local Scale-invariant Features[C]//Proceedings of the Seventh IEEE International Conference on Computer Vision. Kerkyra, Greece: IEEE, 1999. http://dl.acm.org/citation.cfm?id=851523 |
| [2] | BAY H, ESS A, TUYTELAARS T, et al. Speeded-up Robust Features (SURF)[J]. Computer Vision and Image Understanding, 2008, 110(3): 346–359. |
| [3] | RUBLEE E, RABAUD V, KONOLIGE K, et al. ORB: An Efficient Alternative to SIFT or SURF[C]//IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6126544 |
| [4] | LEUTENEGGER S, CHLI M, SIEGWART R Y. BRISK: Binary Robust Invariant Scalable Keypoints[C]//IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011. http://dl.acm.org/citation.cfm?id=2356277 |
| [5] | CRANDALL D, OWENS A, SNAVELY N, et al. Discrete-continuous Optimization for Large-scale Structure from Motion[C]//IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI: IEEE, 2011. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5995626 |
| [6] | WU Changchang. SiftGPU: A GPU Implementation of Scale Invariant Feature Transform (SIFT). (2007). URL http://cs.unc.edu/~ccwu/siftgpu. |
| [7] | SNAVELY N, SEITZ S M, SZELISKI R. Modeling the World from Internet Photo Collections[J]. International Journal of Computer Vision, 2008, 80(2): 189–210. |
| [8] | Wu Changchang. VisualSFM: A Visual Structure from Motion System[EB/OL]. [2017-12-12]. http://www.cs.washington.edu/homes/ccwu/vsfm. |
| [9] | FUHRMANN S, LANGGUTH F, MOEHRLE N, et al. MVE:An Image-based Reconstruction Environment[J]. Computers & Graphics, 2015, 53: 44–53. |
| [10] | LECUN Y, BENGIO Y, HINTON G. Deep Learning[J]. Nature, 2015, 521(7553): 436–444. |
| [11] | KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet Classification with Deep Convolutional Neural Networks[J]. Communications of the ACM, 2017, 60(6): 84–90. DOI:10.1145/3098997 |
| [12] | BENGIO Y. Deep Learning of Representations for Unsupervised and Transfer Learning[C]//Proceedings of 2011 International Conference on Unsupervised and Transfer Learning workshop. Washington, USA: JMLR, 2012. https://www.researchgate.net/publication/319770277_Deep_Learning_of_Representations_for_Unsupervised_and_Transfer_Learning |
| [13] | AGARWAL S, FURUKAWA Y, SNAVELY N, et al. Building Rome in a Day[J]. Communications of the ACM, 2011, 54(10): 105–112. |
| [14] | HAVLENA M, SCHINDLER K. VocMatch: Efficient Multiview Correspondence for Structure from Motion[M]//FLEET D, PAJDLA T, SCHIELE B, et al. Computer Vision-ECCV 2014. Cham: Springer, 2014. |
| [15] | ZHAN Zongqian, WANG Xin, WEI Minglu. Fast Method of Constructing Image Correlations to Build a Free Network Based on Image Multivocabulary Trees[J]. Journal of Electronic Imaging, 2015, 24(3): 033029. |
| [16] | SCHÖNBERGER J L, FRAHM J M. Structure-from-Motion Revisited[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016. http://ieeexplore.ieee.org/document/7780814/ |
| [17] | SCHÖNBERGER J L, PRICE T, SATTLER T, et al. A Vote-and-verify Strategy for Fast Spatial Verification in Image Retrieval[M]//LAI S H, LEPETIT V, NISHINO K, et al. Computer Vision-ACCV 2016. Cham: Springer, 2016. |
| [18] | ANGELI A, FILLIAT D, DONCIEUX S, et al. Fast and Incremental Method for Loop-closure Detection Using Bags of Visual Words[J]. IEEE Transactions on Robotics, 2008, 24(5): 1027–1037. |
| [19] | CUMMINS M, NEWMAN P. Appearance-only SLAM at Large Scale with FAB-MAP 2.0[J]. The International Journal of Robotics Research, 2011, 30(9): 1100–1123. |
| [20] | GALVEZ-LÓPE D, TARDOS J D. Bags of Binary Words for Fast Place Recognition in Image Sequences[J]. IEEE Transactions on Robotics, 2012, 28(5): 1188–1197. |
| [21] | MUR-ARTAL R, TARDÓS J D. ORB-SLAM2:An Open-source SLAM System for Monocular, Stereo, and RGB-D Cameras[J]. IEEE Transactions on Robotics, 2017, 33(5): 1255–1262. DOI:10.1109/TRO.2017.2705103 |
| [22] | GAO Xiang, ZHANG Tao. Unsupervised Learning to Detect Loops Using Deep Neural Networks for Visual Slam System[J]. Autonomous Robots, 2017, 41(1): 1–18. DOI:10.1007/s10514-015-9516-2 |
| [23] | ZHANG Xiwu, SU Yan, ZHU Xinhua. Loop Closure Detection for Visual SLAM Systems Using Convolutional Neural Network[C]//The 23rd International Conference on Automation and Computing. Huddersfield, UK: IEEE, 2017. http://ieeexplore.ieee.org/document/8082072/ |
| [24] | BABENKO A, SLESAREV A, CHIGORIN A, et al. Neural Codes for Image Retrieval[M]//FLEET D, PAJDLA T, SCHIELE B, et al. Computer Vision-ECCV 2014. Cham: Springer, 2014. |
| [25] | RAZAVIAN A S, AZIZPOUR H, SULLIVAN J, et al. CNN Features Off-the-shelf: An Astounding Baseline for Recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition Workshops. Columbus, OH: IEEE, 2014. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6910029 |
| [26] | YANDE A B, LEMPITSKY V. Aggregating Local Deep Features for Image Retrieval[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015. http://ieeexplore.ieee.org/document/7410507 |
| [27] | DESEILLIGNY M P, CLÉRY I. Apero, An Open Source Bundle Adjusment Software for Automatic Calibration and Orientation of Set of Images[C]//Proceedings of the ISPRS Symposium. [S. l. ]: ISPRS, 2011: 269-276. http://www.researchgate.net/publication/228808857_APERO_AN_OPEN_SOURCE_BUNDLE_ADJUSMENT_SOFTWARE_FOR_AUTOMATIC_CALIBRATION_AND_ORIENTATION_OF_SET_OF_IMAGES |