



2. 澳大利亚国立大学工程研究院, 澳大利亚 堪培拉 2601
2. Research School of Engineering, Australian National University, Canberra 2601, Australia
在航空航天等方面,数字摄影测量与机器视觉的融合发展成为近来备受关注的高性能对地观测手段,同时以深度学习为代表的智能化处理方法不断发展,如何有效结合深度学习方法实现更加智能的摄影测量成为一个关键的研究问题。本文侧重于介绍智能化摄影测量深度学习的深度残差方法,研究基于深度残差网络的遥感图像显著目标检测方法。图像显著目标检测致力于自动检测和定位图像中对人所最感兴趣的目标区域。该项技术已经被成功应用到多项计算机视觉与模式识别任务中,包括交互式图像分割[1]、图像剪裁[2]、基于上下文的图像编辑[3]、图像识别[4]和动作识别[5]等。传统的显著目标检测方法通过手工设计特征,计算图像各像素或者超像素与邻域像素或者超像素之间的对比度实现显著目标检测(1代表显著性前景;0代表非显著性背景)。对于简单场景,传统算法可以取得不错的结果。然而基于手工设计特征的传统显著目标检测方法难以应对复杂场景,如包含多个显著目标或者显著目标在场景中所占比例较低等复杂情形。
随着深度学习的巨大进展,特别是全卷积神经网络[6](fully convolutional networks,FCN)的引入,基于深度卷积网络(convolutional neural network,CNN)的显著目标检测算法取得巨大进步。近两年来出现了众多基于CNN的显著目标检测方法。由于深度网络可以有效提取显著目标更抽象且更加高维的特征,相比于传统方法,基于深度学习的显著目标检测性方法取得的巨大的性能提升,特别是在复杂场景的显著目标检测方面。
然而,由于图像数据获取和标记的困难性,多光谱遥感图像显著目标检测的研究依然以人工定义特征检测为主。同时,传统的多光谱数据显著目标检测算法并没有充分挖掘波段信息,只是在不同波段按照自然图像的处理方式来提取颜色对比度信息和纹理信息等。为了有效利用多光谱各谱段信息,本文提出一个基于自上而下深度残差网络的多光谱遥感图像显著目标检测模型。考虑到多光谱遥感图像显著目标数据的有限性和获取的困难性,本文首先提出一种多光谱超分辨率网络模型,用于从已有的RGB图像,产生多光谱遥感图像(本文从RGB图像产生近红外波段图像)。然后,使用已有的RGB图像,产生足够多的多光谱图像。最后,使用上述模型产生的多光谱图像来训练一个基于残差网络的自上而下的深度学习模型。本文基于残差网络的显著目标检测模型结构如图 1所示。

|
| 图 1 基于自上而下的深度残差网络多光谱遥感图像显著目标检测模型 Fig. 1 Our deep residual network based top-down multispectral image salient object detection model 注:本文深度网络模型输入包括两部分,即原始RGB图像和通过本文提出的多光谱超分辨率模型产生的近红外波段图像。网络最后一部分的输出被逐步反馈到网络浅层部分,有效实现保留高层语义信息和底层细节信息的目的。 |
1 相关研究 1.1 传统显著目标检测算法
传统显著目标检测算法依赖于人工定义的特征。文献[7]提出一种边界连接性指标(background connectivity),通过计算图像中每个超像素区域与图像边界的连接程度来计算显著性值。文献[8]定义对比度、聚集度和物体度(一个像素或者超像素属于一个物体的概率)实现显著目标检测。文献[9]将显著目标检测问题描述为一个低秩矩阵分解问题,在矩阵分解框架下实现显著目标检测。感兴趣的读者可以阅读文献(arXiv.eprint:1411.5878, 2017)和文献[10],这些文献系统总结并比较了深度学习时代之前的传统显著目标检测方法。
1.2 基于深度学习的显著目标检测算法与基于人工计算特征的传统显著目标检测算法不同,深度网络能够自适应训练一个深度模型以提取显著目标更加高维更加抽象的特征,从而实现更好的显著目标检测。同时深度卷积网络可以充分挖掘显著目标检测与图像语义分割之间的联系,学习并表达刻画显著目标的高层语义信息。文献[11]提出使用深度特征取代传统的手工特征,然后通过一个分类器确定区域的显著性值。作为文献[11]的扩展版本,文献[12]提出结合深度特征和手工特征的显著性方法,即在深度特征基础上,添加手工特征,实现更加精确的显著目标检测。区别于文献[12],文献[13]提出一种端到端的多模型融合的深度显著性模型,将手工特征显著性图和原始图像同时输入深度网络,从而更好地利用手工特征和深度特征的互补信息。文献[14]提出一个多任务深度网络,同时实现显著目标检测和图像语义分割,充分挖掘两项任务之间的关联性,以便充分利用深度网络中浅层和深层信息。文献[15-18]研究多尺度信息融合的深度显著性检测网络。由于深度网络存在池化操作以获得更大的感受野,导致输出的显著性图分辨率较低,文献[19]提出一种网状结构的编解码模型,以提高输出显著性图的分辨率。文献[20]提出基于注意力模型的自上而下的深度显著性模型实现高分辨率显著性图输出。上述深度网络显著性模型均依赖与大规模训练数据,文献[21-22]提出无监督深度显著性检测模型,其中文献[21]通过逐步更新和优化一个基于先验信息的测度来迭代更新显著性图,文献[22]则通过同时优化一个显著性模型和噪声模型实现无监督深度显著性检测。
1.3 多光谱图像显著目标检测算法常规显著目标检测算法一般针对图像波段范围在380~780 nm,即可见光范围,也就是所说的RGB图像。与常规可见光图像显著目标检测不同,对与多光谱图像,由于其数据获取的困难性,导致多光谱显著性检测的研究比较少。文献[23]和文献[24]提出综合考虑RGB和近红外波段上的对比度信息和纹理信息来进行多光谱显著性检测。文献[25]采用随机森林回归机器学习算法检测图像中的显著建筑物。文献[26]系统研究了通过引入目标先验信息以获取与目标更相关的感兴趣区域。
与现有应用于RGB图像的显著目标检测算法不同,本文研究多光谱遥感图像显著目标检测,本文方法包括多光谱显著目标检测训练数据产生网络;使用RGB数据作为上述网络的输入,从而产生足够多的多光谱显著性检测训练数据;使用深度网络产生的多光谱数据训练显著目标检测深度网络模型。图 1为基于深度残差网络自上而下的显著性检测模型,采用已有的多光谱数据进行了性能验证。试验结果证明了本文算法的有效性。
2 遥感图像光谱超分辨率由于多光谱数据的有限性,为了训练一个多光谱显著目标检测深度网络,本文首先训练多光谱超分辨率模型,从RGB图像生成多光谱(多波段)遥感图像,用于产生多光谱显著目标检测训练数据。
2.1 网络结构目前的深度网络一般都是基于VGG(arXiv:1409.1556, 2014)框架或者ResNet[27]框架。针对目标,即最终产生的多光谱数据与输入图像尺度应该一致,尝试通过添加对称的反卷积层实现分辨率不变的目标。然而试验结果表明,上述框架对于本文目的无法有效的收敛。进一步考虑本文目的是实现细节保留的同分辨率数据输出,于是直接设计一个浅层神经网络,如图 2所示。

|
| 图 2 光谱超分辨率模型 Fig. 2 The proposed multispectral super-resolution model 前3个卷积层后面都添加ReLU激活函数.前两个卷积层使用卷积核大小为5×5,后两个卷积卷积核大小为3×3。 |
本文使用的多光谱数据集[28]包含RGB和近红外波段,为了产生足够多的多光谱显著目标检测训练数据,本文构造图 2浅层网络,用于从已有RGB图像,产生近红外数据。考虑产生的近红外数据应该和原始图像具有相同的空间分辨率,本文浅层网络中没有使用池化操作(pooling),并保证所有卷积层输入尺寸相同。
训练细节:使用caffe框架训练网络,并设置最大迭代次数为150 000次。每幅训练图像的RGB部分作为网络输入,近红外波段作为网络输出。对于每幅RGB图像,均匀剪裁出32×32大小的图像片送入网络,并保持相邻图像片有4个像素的重叠。使用“xavier”策略初始化网络参数,设置偏置为常数。使用随机梯度下降法更新权值,并设置动量为0.9。基础学习率设置为0.000 001, 并固定。使用欧氏距离损失函数。本文浅层多光谱超分辨率网络训练时间是17 h,使用NVIDIA Quadro M4000 GPU。
2.2 网络分析与试验结果由于多光谱近红外数据和原始RGB数据相似性较高,特别是在细节边缘上,如果使用较深的网络结构(如VGG或者ResNet),过多的非线性操作将导致原始图像很多细节丢失。通过图 2描述的一个浅层网络可以有效根据RGB图像估计近红外波段,同时保留尽可能多的细节信息。图 3是多光谱数据集上部分数据及通过本文多光谱超分辨率网络产生的近红外数据与原始近红外波段数据对比。从图 3可见,由本文多光谱超分辨率模型产生的近红外波段与原始近红外波段比较相似,从而验证了本文网络模型的有效性。

|
| 图 3 遥感图像光谱超分辨率模型结果 Fig. 3 Results from our spectral super-resolution model 从左到右:输入遥感RGB图像,其对应的近红外波段,本文遥感图像光谱超分辨率模型(从RGB图像生成近红外图像)产生的近红外波段。 |
3 深度残差网络的多光谱遥感图像显著目标检测 3.1 深度残差网络
相较于浅层神经网络,深度网络由于其高维的非线性操作,从而可以实现更抽象的图像特征提取与表示。然而,随着网络层数的加深,一方面网络优化变得更加困难,另一方面,“梯度消失”现象导致在网络高层更新的权重信息无法有效地传递到网络底层。为了应对上述问题,文献[27]提出了一个基于短连接的残差深层网络结构(ResNet)。设深度网络中某隐含层的非线性操作函数H,对于没有短连接的深度网络,给定该层输入为x,则输出为H(x)。添加短连接之后,相同的隐层函数H,最后网络的输出变为H(x)+x,这样一来,就可以得到一种全新的残差结构单元,如图 4所示,其中(a)是一般的深度网络模型数据传递过程,(b)是残差网络模型的数据传递过程。残差单元的输出由多个卷积层级联的输出与输入元素间相加(保证卷积层输出与输入元素维度相同),再经过ReLU激活后得到。与一般深度网络结构相比,ResNet更容易优化,同时较好地防止了梯度消失现象的发生。

|
| 图 4 深度残差网络模型与一般深度网络模型数据传递过程对比 Fig. 4 Data pass in conventional deep network and in ResNet |
3.2 自上而下的高分辨率多光谱显著目标检测
原始ResNet网络中使用5次池化操作,使得最后全连接层之前数据分辨率下降为原始分辨率的1/32。为了提高输出特征图的分辨率,本文首先去掉最后一个池化操作以及ResNet最后的全连接层,同时使用膨胀卷积层(Dilated Convolution)[27, 29],最后改造后的全卷积ResNet网络输出分辨率是原始输入的1/8。为了产生更高的特征图分辨率,本文提出一种自上而下的残差网络结构,如图 1所示。将残差网络分成5个部分,conv1、conv2、conv3、conv4和conv5部分。经过conv1之后,特征图分辨率是原始的1/2, 经过conv2之后,分辨率降到1/4,conv3之后,分辨率保持不变,为1/8。为了进一步提高特征图分辨率,将高层输出作为语义信息去优化浅层信息。具体是,对于网络每部分的输出,首先通过一个3×3的卷积层将其维度降低到M,然后与网络前一个部分的输出叠加,其中M设置为网络上一部分输出的维度。
训练细节:使用caffe框架训练网络,并设置最大迭代次数为10 000次。每幅训练图像包括4个波段,分别为原始的RGB图像,以及由以上多光谱超分辨率网络产生的近红外波段。对于每幅输入图像,将其尺寸固定为281×281。使用“xavier”策略初始化网络参数,设置偏置为常数。使用随机梯度下降法更新权值,并设置动量为0.9。基础学习率设置为0.000 8,学习率更新策略为“poly”,用“SoftmaxWithLoss”作为损失函数。整个网络训练时间为12 h,使用NVIDIA Quadro M4000 GPU。
4 试验结果与分析本文多光谱显著目标检测模型分为两部分,即多光谱超分辨率模型和多光谱显著目标检测模型。前者用于根据RGB图像产生多光谱图像,后者为本文的显著目标检测模型。
4.1 试验数据本文多光谱超分辨率模型数据来自文献[28]。这个数据集包括477幅来自9个类别的图像,包括RGB图像和对应的近红外波段图像。这些图像是从一个改进的单反相机,通过独立曝光,分别获取可见光波段和近红外波段图像。每一个图像对包括可见光图像和对应区域的近红外图像。大部分图像中只包括一个显著目标,比较适合多光谱显著目标检测任务。本文选择15幅图像作为遥感多光谱图像显著目标检测测试图像,其余462幅多光谱图像用于训练多光谱超分辨率模型,即根据RGB图像,预测对应的近红外波段。
本文的多光谱遥感图像显著检测数据集来自文献[30]。该数据集包括5000幅按像素标注的显著目标检测图像。从中选择2500幅作为训练数据,500幅作为验证数据,剩余2000幅为测试数据,与文献[17, 31]保持一致。
4.2 性能测度本文使用4种性能测度,包括平均绝对误差(MAE)、最大Fβ度量、平均Fβ度量和准确率/召回率曲线。MAE描述了检测的显著性图与原始真值图的相似程度,定义如下
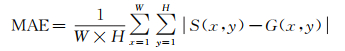 (1)
(1)
式中,W和H是检测到的显著性图S的宽和高,G是真值图。Fβ度量定义如下
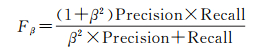 (2)
(2)
式中,Precision为准确率,Recall为召回率。和文献[17]等一样,鉴于在显著性检测中,准确率比召回率更重要,使用β2=0.3来更加强调准确率。最大Fβ度量描述了一个显著检测模型可以达到的最优性能,平均Fβ度量则描述当前模型的整体性能。
4.3 对比算法由于多光谱显著性检测算法比较少,而且都没有现成的代码或者显著性图,针对RGB图像的显著性检测算法进行对比。本文选择4个传统显著性检测算法(包括DRFI[31],DSR[32],MC[33]和RBD[7])和4个近期的基于深度网络的显著性检测算法(包括DSS[17],LEGS[34],MDF[11],RFCN[35])。由于上述算法只接收3通道RGB图像的输入,对于本文4通道测试数据集,选择所有3通道图像的组合送入对比算法,并选择最优的一组结果作为该算法最终结果。
4.4 遥感多光谱图像显著目标检测结果比较计算上述对比算法在本文标注的15幅多光谱显著目标检测测试数据集上的Fβ度量和MAE,结果如表 1所示。
| DRFI | DSR | MC | RBD | DSS | LEGS | MDF | RFCN | 本文算法 | |
| maxF | 0.797 8 | 0.819 4 | 0.787 5 | 0.783 6 | 0.829 3 | 0.835 8 | 0.803 9 | 0.809 0 | 0.906 8 |
| meanF | 0.573 8 | 0.718 4 | 0.645 3 | 0.707 5 | 0.823 4 | 0.782 6 | 0.769 3 | 0.767 7 | 0.864 2 |
| MAE | 0.156 9 | 0.149 5 | 0.174 3 | 0.151 1 | 0.064 0 | 0.116 2 | 0.084 6 | 0.099 7 | 0.056 9 |
从表 1可以得到如下结论:首先,从MAE上考虑,基于深度网路的显著目标检测算法优于传统算法,特别是DSS[17]算法,其MAE是上述4个最好传统算法的0.43倍;其次,本文算法,以图像4个通道同时输入,取得了最好的结果,特别是最大Fβ度量,比最好的深度网络算法提高10%。
同时,比较准确率/召回率曲线(PR曲线),结果如图 5(a)所示,其中“OUR”表示本文算法。

|
| 图 5 数据 Fig. 5 Dataset |
由于使用的测试数据有限,导致曲线比较不平滑。但还是可以看出,本文算法在准确率/召回率曲线上也明显优于对比算法。图 6显示了本文算法显著性和几个对比算法的显著性。由于施加了自上而下的策略,本文算法结果在细节上处理得更合理。

4.5 在生成多光谱显著目标检测数据集上的性能
由于多光谱数据的稀有性和获取的困难性,本文使用了常规RGB图像生成近红外波段,以增加多光谱数据量,从而训练一个基于自上而下残差网络的深度模型。为了验证本文算法在生成遥感多光谱图像上的有效性,在MSRA-B测试数据集上,进行了显著目标检测试验。首先通过光谱超分辨率生成多光谱图像,然后采用本文提出的多光谱遥感图像显著目标检测算法进行目标检测,试验结果如图 5(b)和图 7所示。图 5(b)描述的是本文算法与对比算法在2000幅MSRA-B生成多光谱测试数据集上的PR曲线对比,其中“OUR”表示本文算法。图 5(b)结果显示本文算法在PR曲线上优于对比算法。图 7展示了生成MSRA-B数据集上的测试图像及本文算法结果,其中近红外波段是由本文光谱超分辨率模型产生。试验结果显示本文算法可以充分应对不同类型的多光谱多波段图像,同时通过网络学习生成的多光谱图像具有更加丰富的物理属性信息,更加有利于显著目标的表示与提取,从而取得比传统方法更好的结果。

|
| 图 7 本文算法在RGB图像上的结果 Fig. 7 Results of our method on MSRA-B testing dataset 从左到右:输入RGB图像,通过光谱超分辨率模型产生的近红外波段,像素级别真值,以及本文算法显著性。 |
5 总结
以航空航天领域摄影测量与机器视觉的不断深入融合和以深度学习为代表的智能化处理方法的巨大进展为背景,本文侧重于研究智能化摄影测量深度学习中的深度残差方法,提出基于深度残差网络的多光谱遥感图像显著目标检测模型。考虑到多光谱遥感图像数据获取的困难性,为了应对多波段遥感图像数据量有限、无法训练深度残差网络的问题,本文首先提出通过浅层神经网络从RGB图像直接生成多波段遥感图像,实现光谱方向的超分辨率。其次,提出一种基于深度残差网络的自上而下的多光波段遥感图像显著目标检测网络,该网络可以有效挖掘深度残差网络不同层次上的显著性特征,以端对端方式实现显著目标检测。在现有多波段遥感图像和可见光图像显著目标检测数据集上的试验结果超过当前最好方法10%以上,表明了本文提出方法的有效性。进一步的研究工作将聚焦于通过多维卷积的形式进一步挖掘多光谱遥感图像空间-谱间联合信息,同时构建更大规模的多光谱遥感图像显著目标检测数据集以促进本领域的进一步发展。
| [1] | LI Junxia, MA Runing, DING Jundi. Saliency-seeded Region Merging: Automatic Object Segmentation[C]//First Asian Conference on Pattern Recognition. Beijing, China: IEEE, 2011: 691-695. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6166633 |
| [2] | MARCHESOTTI L, CIFARELLI C, CSURKA G. A Framework for Visual Saliency Detection with Applications to Image Thumbnailing[C]//IEEE 12th International Conference on Computer Vision. Kyoto, Japan: IEEE, 2009: 2232-2239. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=5459467 |
| [3] | ZHANG Guoxin, CHENG Mingming, HU Shimin, et al. A Shape Preserving Approach to Image Resizing[J]. Computer Graphics Forum, 2009, 28(7): 1897–1906. DOI:10.1111/cgf.2009.28.issue-7 |
| [4] | NAVALPAKKAM V, ITTI L. An Integrated Model of Top-down and Bottom-up Attention for Optimizing Detection Speed[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York, NY: IEEE, 2006: 2049-2056. http://dl.acm.org/citation.cfm?id=1153702 |
| [5] | SHARMA S, KIROS R, SALAKHUTDINOV R. Action Recognition Using Visual Attention[C]//NIPS Time Series Workshop, 2015. http://www.researchgate.net/publication/283986652_Action_Recognition_using_Visual_Attention |
| [6] | SHELHAMER E, LONG J, DARRELL T. Fully Convolutional Networks for Semantic Segmentation[C]//IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE, 2015: 3431-3440. |
| [7] | ZHU Wangjiang, LIANG Shuang, WEI Yichen, et al. Saliency Optimization from Robust Background Detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH: IEEE, 2014: 2814-2821. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6909756 |
| [8] | JIANG Peng, LING Haibin, YU Jingyi, et al. Salient Region Detection by UFO: Uniqueness, Focusness and Objectness[C]//IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013: 1976-1983. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6751356 |
| [9] | SHEN Xiaohui, WU Ying. A Unified Approach to Salient Object Detection via Low Rank Matrix Recovery[C]//IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI: IEEE, 2012: 853-860. https://www.computer.org/csdl/proceedings/cvpr/2012/1226/00/108O1D04-abs.html |
| [10] | BORJI A, CHENG Mingming, JIANG Huaizu, et al. Salient Object Detection:A Benchmark[J]. IEEE Transactions on Image Processing, 2015, 24(12): 5706–5722. DOI:10.1109/TIP.2015.2487833 |
| [11] | LI Guanbin, YU Yizhou. Visual Saliency Based on Multiscale Deep Features[C]//IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE, 2015: 5455-5463. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=7299184 |
| [12] | LI Guanbin, YU Yizhou. Visual Saliency Detection Based on Multiscale Deep CNN Features[J]. IEEE Transactions on Image Processing, 2016, 25(11): 5012–5024. DOI:10.1109/TIP.2016.2602079 |
| [13] | ZHANG Jing, LI Bo, DAI Yuchao, et al. Integrated Deep and Shallow Networks for Salient Object Detection[C]//IEEE International Conference on Image Processing. Beijing, China: IEEE, 2017: 1537-1541. http://www.researchgate.net/publication/317344118_Integrated_Deep_and_Shallow_Networks_for_Salient_Object_Detection |
| [14] | LI Xi, ZHAO Liming, WEI Lina, et al. Deepsaliency:Multi-task Deep Neural Network Model for Salient Object Detection[J]. IEEE Transactions on Image Processing, 2016, 25(8): 3919–3930. DOI:10.1109/TIP.2016.2579306 |
| [15] | LI Guanbin, YU Yizhou. Deep Contrast Learning for Salient Object Detection[C]//IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 478-487. https://www.computer.org/csdl/proceedings/cvpr/2016/8851/00/8851a478-abs.html |
| [16] | ZHANG Jing, DAI Yuchao, PORIKLI F. Deep Salient Object Detection by Integrating Multi-level Cues[C]//IEEE Winter Conference on Application of Computer Vision. Santa Rosa, CA: IEEE, 2017: 1-10. http://ieeexplore.ieee.org/document/7926591/ |
| [17] | HOU Qibin, CHENG Mingming, HU Xiaowei, et al. Deeply Supervised Salient Object Detection with Short Connections[C]//IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, Hawaii: IEEE, 2017: 5300-5309. https://www.computer.org/csdl/proceedings/cvpr/2017/0457/00/0457f300-abs.html |
| [18] | ZHANG Jing, DAI Yuchao, PORIKLI F, et al. Multi-Scale Salient Object Detection with Pyramid Spatial Pooling[C]//Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Kuala Lumpur, Malaysia: IEEE, 2017: 1286-1291. http://ieeexplore.ieee.org/document/8282222/ |
| [19] | ZHANG Ping, WANG Dong, LU Huchuan, et al. Amulet: Aggregating Multi-level Convolutional Features for Salient Object Detection[C]//IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 202-211. https://www.computer.org/csdl/proceedings/iccv/2017/1032/00/1032a202-abs.html |
| [20] | ZHANG Jing, DAI Yuchao, LI Bo, et al. Attention to the Scale: Deep Multi-scale Salient Object Detection[C]//International Conference on Digital Image Computing: Techniques and Application. Sydney, NSW, Australia: IEEE, 2017: 1-7. https://www.researchgate.net/publication/322004202_Attention_to_the_Scale_Deep_Multi-Scale_Salient_Object_Detection |
| [21] | ZHANG Dingwen, HAN Junwei, ZHANG Yu. Supervision by Fusion: Towards Unsupervised Learning of Deep Salient Object Detector[C]//IEEE International Conference on Computer Vision. Venice, Italy: IEEE, 2017: 4068-4076. https://www.researchgate.net/publication/322058175_Supervision_by_Fusion_Towards_Unsupervised_Learning_of_Deep_Salient_Object_Detector |
| [22] | ZHANG Jing, ZHANG Tong, DAI Yuchao, et al. Deep Unsupervised Saliency Detection: A Multiple Noisy Labeling Perspective[C]//IEEE International Conference on Computer Vision. [s. l. ]: IEEE, 2018. http://www.researchgate.net/publication/324104723_Deep_Unsupervised_Saliency_Detection_A_Multiple_Noisy_Labeling_Perspective |
| [23] | WANG Qi, YAN Pingkun, YUAN Yuan, et al. Multi-Spectral Saliency Detection[J]. Pattern Recognition Letters, 2013, 34(1): 34–41. DOI:10.1016/j.patrec.2012.06.002 |
| [24] | WANG Qi, ZHU Guokang, YUAN Yuan. Multi-Spectral Dataset and Its Application in Saliency Detection[J]. Computer Vision and Image Understanding, 2013, 117(12): 1748–1754. DOI:10.1016/j.cviu.2013.07.002 |
| [25] |
潘朝.
多尺度显著性引导的高分辨率遥感影像建筑物提取[J]. 科技创新与生产力, 2017(5): 106–109.
PAN Zhao. Building Extraction from High Resolution Remote Sensing Image Based on Visual Saliency Detection[J]. Technology Innovation and Productivity, 2017(5): 106–109. |
| [26] |
崔晓光. 融合目标信息的遥感图像显著性检测方法研究[D]. 北京: 中国科学院大学, 2013. CUI Xiaoguang. Saliency Detection Methods via Fusing Target Information[D]. Beijing: University of Chinese Academy of Sciences, 2013. http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y2609334 |
| [27] | HE Kaiming, ZHANG Xiangyu, REN Shaoqing, et al. Deep Residual Learning for Image Recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 770-778. https://ieeexplore.ieee.org/document/7780459/ |
| [28] | BROWN M, SUSSTRUNK S. Multi-spectral SIFT for Scene Category Recognition[C]//IEEE Conference on Computer Vision and Pattern Recognition. Providence, RI: IEEE, 2011: 177-184. http://dl.acm.org/citation.cfm?id=2191901 |
| [29] | YU F, KOLTUN V. Multi-Scale Context Aggregation by Dilated Convolutions[C]//International Conference on Learning Representations. [s. l. ]: IEEE, 2016. http://www.oalib.com/paper/4055078 |
| [30] | LIU Tie, SUN Jian, ZHENG Nanning, et al. Learning to Detect a Salient Object[C]//IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis, MN: IEEE, 2007: 1-8. http://dl.acm.org/citation.cfm?id=1936580 |
| [31] | JIANG Huaizu, WANG Jingdong, YUAN Zejiang, et al. Salient Object Detection: A Discriminative Regional Feature Integration Approach[C]//IEEE Conference on Computer Vision and Pattern Recognition. Portland, OR: IEEE, 2013: 2083-2090. http://dl.acm.org/citation.cfm?id=3095356 |
| [32] | LI Xiaohui, LU Huchuan, ZHANG Lihe, et al. Saliency Detection via Dense and Sparse Reconstruction[C]//IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013: 2976-2983. http://ieeexplore.ieee.org/xpls/icp.jsp?arnumber=6751481 |
| [33] | JIANG Bowen, ZHANG Lihe, LU Huchuan, et al. Saliency Detection via Absorbing Markov Chain[C]//IEEE International Conference on Computer Vision. Sydney, NSW, Australia: IEEE, 2013: 1665-1672. https://www.computer.org/csdl/proceedings/iccv/2013/2840/00/2840b665-abs.html |
| [34] | WANG Lijun, LU Huchuan, RUAN Xiang, et al. Deep Networks for Saliency Detection via Local Estimation and Global Search[C]//IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE, 2015: 3183-3192. https://www.computer.org/csdl/proceedings/cvpr/2015/6964/00/07298938-abs.html |
| [35] | WANG Linzhao, WANG Lijun, LU Huchuan, et al. Saliency Detection with Recurrent Fully Convolutional Networks[M]//LEIBE B, MATAS J, SEBE N, et al. Computer Vision-ECCV 2016. Cham: Springer, 2016: 825-841. |