



2. 中国地质大学(武汉)信息工程学院, 湖北 武汉 430074
2. Faculty of Information Engineering, China University of Geosciences, Wuhan 430074, China
从遥感影像中自动识别建筑物目标并获取其精确边缘轮廓信息,一直是数字测图实现自动化和智能化的重要努力方向。在深度学习技术的复兴热潮到来之前,绝大部分面向遥感影像的建筑物检测方法可归类为一种从人工设计特征出发的分类方法,其特征建模依赖于人类对建筑物的观察、理解和归纳。在此基础上形成的方法可区分为知识引导、模板匹配及监督分类3类:知识引导类方法主要通过建立知识约束将对象检测问题转化为假设测试问题,典型的知识约束包括建筑物的几何辐射特性、矩形约束[1]、棱形约束[2],以及建筑物与阴影的伴生关系[3-4]等;模板匹配方法基于明确的模板参数对建筑物进行描述,再通过人工设置或样本训练的方式获取这些参数,最后采用一定的搜索方法,并以相关度最大为原则来确定最佳匹配结果[5-6];监督分类方法一般针对建筑物的特点设计数据特征,然后进行特征提取并利用样本数据进行分类器训练,最后使用支持向量机[7]、Adaptive Boosting(AdaBoost)[8]、随机森林[9]、条件随机场[10]等分类器对测试数据中的特征进行分类,进而从分类结果中获取建筑物检测结果。然而,受制于建筑物结构、纹理复杂多样,以及不同数据中光照、分辨率和成像质量的变化,依赖人工设计往往很难对各种成像条件下的建筑物特征进行准确概括,从而导致基于人工设计特征的传统方法普遍缺乏对不同数据的泛化能力。
近年来,随着计算机硬件水平的发展和超大规模学习样本的出现,以卷积神经网络(convolutional neural network,CNN)[11]为代表的深度学习技术在计算机视觉领域的目标检测和分类应用中表现出强大性能[12],大幅提升了该领域的算法精度水平。由于CNN能够自动学习和生成复杂度极高的非线性特征,突破人工设计的局限性,因而迅速在建筑物检测问题上得到应用。早期的应用思路主要基于经典CNN模型,即在影像中取以单像素为中心的图像块为模型输入,并对其进行特征建模,进而确定每个像素的类别[13-14],不过当推广至大批量处理时,这种方法的内存开销将急剧增加,处理效率也将明显下降。全卷积网络(fully convolutional network,FCN)[15]的提出很大程度上改进了这个问题,该模型通过去除经典CNN中的全连接层,并对末层特征进行反卷积(上采样)操作生成与输入图像分辨率一致的输出层,可以高效地实现图像的像素级分类。目前FCN模型已经在建筑物检测方面得到较多应用[16-18]。此外,顾及CNN的前向传播过程中分辨率不断下降,仅采用末层特征生成的分割结果往往边缘精度偏低,后续许多面向图像分割的模型进一步对FCN这种端对端的思想进行了扩展,这其中有代表性的包括SegNet[19]、DeconvNet[20]以及U-Net[21]等。以本文关注的U型卷积神经网络U-Net为例,该模型不仅实现了输出层的分辨率一致性,还通过对称式的结构设计融合了CNN网络中的低维和高维特征,在医学图像上达到了更高精度的分割效果。
基于上述分析,本文以一个大覆盖范围的航空影像数据集作为研究对象,提出一种基于改进U-Net模型的建筑物检测方法。本文贡献主要体现在两点:首先,将U型卷积网络的设计思想应用于遥感影像建筑物检测处理中,设法融合卷积网络中的高维和低维特征以恢复高保真建筑物边界;其次,提出一种双重约束的改进U-Net模型,以加强网络在抽象层面识别建筑物的能力,从而进一步提升检测精度。
1 方法CNN在遥感影像建筑物检测方面的应用目前仍处在较早的阶段,本节将首先对FCN模型和U型卷积网络在图像分割中的应用思路进行简要介绍,然后介绍本文提出的双重约束的改进U型卷积网络,最后对基于改进U型卷积网络的建筑物检测流程进行阐述。
1.1 全卷积神经网络(FCN)和U型卷积网络(U-Net)文献[17]提出了一种全卷积思想的FCN模型[17],其主要目的在于改善经典CNN模型在图像语义分割问题上的应用表现。在此之前,CNN模型已经在目标分类领域取得了最先进的分类精度水平,但这种经典模型结构一般只适用于图像级的分类和回归任务,其网络通常会在若干个卷积层和池化层之后连接多个全连接层,从而将卷积层中生成的特征映射为一个N维向量,以表征输入图像属于N个类别中每一类的概率。
然而对于包括遥感影像建筑物检测在内的语义分割问题而言,需要获取的是图像中每个像素的分类结果。尽管经典CNN模型通过以单个像素为中心取图像块,然后基于图像块进行特征建模的方式可以实现像素级的图像分类,但由于相邻图像块的高度重叠将引入大量的数据冗余,这种方法往往非常耗时。此外,图像块大小的选取还将面临两难问题:窗口过大将导致内存开销剧增,增加计算负担;窗口较小则无法掌握大型目标的上下文信息,造成识别困难。
鉴于此,FCN模型对经典CNN做出了针对性改进。如图 1所示,相比经典模型的网络结构,FCN的最大区别是在末端的卷积层之后不再使用全连接层生成固定长度的特征向量,而是采用反卷积层对前端卷积层生成的高维特征图进行上采样,使之恢复至与输入图像相同的分辨率。改进后的网络模型有效保留了输入图像的空间信息,可以实现对每个像素都产生一个预测结果,同时因为省去了经典CNN应用中复杂的逐窗口计算过程,图像分割的处理效率也得到大幅提升。

|
| 图 1 FCN网络结构示意 Fig. 1 The architecture of fully convolutional networks |
尽管在FCN的网络结构中进行一次反卷积操作就可以生成原图大小的输出层,但得到的分割结果往往过于平滑,许多细节无法还原。这主要是由于在生成最后的特征图之前输入图像经历了多次池化处理,这一方面使得末端的神经元能够接收更大范围图像的信息,即更大的感受野,另一方面却也导致许多图像细节丢失,从而无法精确地提取目标轮廓。FCN模型就此提出的解决方案是尝试将特征金字塔中更低层的特征与反卷积后的上采样结果进行融合并加以运用,试验证实这种方法确实可以提高分割精度。
U-Net模型则进一步扩展了FCN模型中这种高维与低维特征融合的思想。如图 2所示,在U-Net的网络结构中,输入图像首先经过若干个卷积层和池化层得到分辨率较低的高维特征图(过程中形成一个从低维到高维的特征金字塔),随后通过一系列反卷积层逆向进行多次上采样,生成与原有特征金字塔逐级对应的特征图,最终输出与输入图像分辨率一致的像素级预测结果。在对高维特征图进行上采样的过程中,每进行一次反卷积操作,特征图的维度均会减半,而在进行下一次上采样之前,这些被降维的特征将会通过矩阵级联的方式与特征金字塔中对应层级的特征图进行融合,融合后的特征不仅包含了金字塔顶层的抽象数据,还注入了低层各级中提取的细节信息。若将金字塔倒置,这种对称式的网络结构在形态上接近一个“U”型,U-Net因此得名。

|
| 图 2 U型卷积网络结构示意 Fig. 2 The architecture of U-Net |
1.2 双重约束的改进U型卷积网络
与FCN以及大部分用于图像分割的CNN模型相同,U-Net模型的训练方式主要是通过卷积网络中的末层特征数据输出与原图分辨率相同的预测结果,然后利用预测结果与真值图构建损失函数,再通过反向传播算法对模型参数进行迭代更新。根据反向传播算法的原理,卷积网络中最靠近输出结果的参数将优先得到更新,其他参数的更新幅度随着传播距离拉长将会逐渐衰减。然而在U-Net模型中,其输出结果由金字塔底层特征(包括卷积和反卷积过程中生成的两部分特征数据)直接产生,这就导致该模型在训练整个网络结构时偏重于低层的参数更新,位于特征金字塔顶层的相关参数优化程度相对较差。据此,本文通过对顶层特征引入额外的损失约束,提出一种双重约束的改进U-Net网络结构。如图 3所示,在双重约束的U-Net模型中,损失函数由主要损失和次级损失两部分构成,前者用于约束最终输出结果与真值图的损失值,后者则首先利用顶层特征生成低分辨率的预测结果,再对其与相应低分辨率的真值图的损失值进行约束。这种网络结构能够在一定程度上平衡计算资源的分配,使得不同层级的模型参数均得到较好的优化。

|
| 图 3 双重约束的U型卷积网络结构 Fig. 3 The architecture of the improved U-Net with twofold constraints |
遥感影像建筑物检测的本质是一个二值化图像分割任务,因此相对于多类别的图像分割应用,本文在U-Net的末层无须建立Softmax回归模型,只需选用Sigmoid函数作为激活函数即可
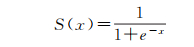 (1)
(1)
式中,x为激活函数的输入,由U-Net网络中的前向传播计算所得;S(x)为表征当前像素被识别为建筑物对象的概率值,其值域为(0,1)。
进一步地,可采用对数损失函数描述训练样本中预测值与真值的差异
 (2)
(2)
式中,L(x)为训练样本的总损失值;m为总样本个数;L(xi)为单个像素的损失值;xi和yi分别对应各个像素的输入特征和类别标签。式(2)中yi取值为0或1,当预测值S(xi)与yi接近或相同时,L(xi)趋近或等于0;反之当S(xi)与yi差值增大时,L(xi)趋近于无穷大。因此,通过最小化L(x)可以对模型参数进行训练。
而对于双重约束的U-Net模型,由于增加了一项次级损失,其最终损失函数可表示为
 (3)
(3)
式中,Lmain(x)和Lsub(x)分别为基于金字塔底层和顶层特征的输出结果构建的损失函数,α和1-α分别为赋予二者的权重。
1.3 基于改进U型卷积网络的建筑物检测图 4所示为本文基于改进U-Net模型的遥感影像建筑物检测处理流程。通过将试验数据划分为训练区域和测试区域进行分开处理,该流程可以区分为与之对应的两个阶段。

|
| 图 4 建筑物检测处理流程 Fig. 4 The workflow of building detection using the proposed method |
训练阶段:
(1) 按一定格网间距将训练区域的遥感影像划分为大小相同的子图像,并生成与之对应的真值图,同时为避免正负样本分布过于不均,将其中建筑物像素占比过低的子图像去除,余下数据按一定比例划分为训练数据集和验证数据集。
(2) 对训练数据集中的地面真值作降采样处理,分别用于建立主要约束和次要约束,采用反向传播和随机梯度下降算法对模型进行训练,得到模型参数。
(3) 基于训练后的模型对验证数据集进行测试和精度评价,根据评价反馈对模型超参数进行调试和结构优化,然后重复步骤(2),直至模型性能稳定后生成最终模型参数。
测试阶段:
(1) 取一定大小的窗口对测试区域的影像进行逐窗口扫描,将每次扫描的子图像输入模型,输出预测结果,得到建筑物与非建筑物的二值分割图像;
(2) 对二值分割图进行形态学开运算和闭运算处理,以填充建筑物内部可能形成的微小空洞,同时去除面积过小的非建筑物对象,得到最终的检测结果,并结合真值数据进行精度评价。
2 试验与分析 2.1 试验介绍大规模的学习样本是支撑深度学习模型发挥高性能的基础。本文以新西兰地区覆盖面积达30 km2的大批量航空影像作为试验数据,其中包含人工标注的建筑物对象28 915个。在用于试验之前,航空影像已经过正射纠正和无缝拼接处理,正射影像地面采样分辨率为0.075 m。如图 5所示,试验区域被划分为面积相等的训练区域和测试区域,分别包括14 510和14 405个建筑物对象。同时为了评估模型对不同类型区域的建筑物检测能力,测试区域被进一步划分为4个子区域。其中区域1建筑物占比较低,包括大面积农田和一个小型湖泊;区域2和区域3建筑物占比适中,混杂部分农田;区域4包含了较多大型工厂。

|
| 图 5 建筑物检测试验区域 Fig. 5 The study area of building detection |
通过将训练区域的影像均等划分为224×224像素的子图像,并将其中建筑物占比低于10%的去除,得到包含17 996张图片的子图像集及其对应地面真值图。该子图像集将按照7:3的比例随机分配到训练数据集和验证数据集中用于模型训练和调试。比较试验中,分别选用FCN、U-Net及本文提出的改进U-Net 3种CNN模型进行训练和测试,其中改进U-Net模型中令主要损失和次级损失的权重相等,即取α=0.5,训练阶段3种模型的迭代次数均设置为100次。此外,为了与人工设计特征驱动的传统分类方法进行对照,同时选用图像分类领域性能较强的HOG(histogram of oriented gradient)特征[22]和AdaBoost模型[23](简称HOG-Ada模型)实施对比试验。
2.2 试验结果及比较分析图 6所示为4种模型在4个试验子区域中建筑物检测的全局评价结果,其中绿色和黑色分别表示正确检出的建筑物和背景像素,红色和蓝色分别表示误检和漏检的建筑物像素。从图中可以看出,尽管HOG-Ada模型在区域1的湖泊处达到了更好的甄别效果,但是其总体识别精度明显低于其他方案,对于道路目标的误检尤为严重。与之对应的是,其他3种CNN模型则均可以正确识别出大部分建筑物对象,在建筑物密集分布的地区(区域2、3)识别效果相对更好;在有效区分建筑物和道路方面,U-Net及改进U-Net相比FCN性能更优,区域3、4的结果反映了FCN在部分主干道附近发生了较多误检,而这种情况在另二者的结果中并未出现;改进U-Net模型与经典U-Net整体上看检测效果十分接近,二者区别更多在于对建筑物边缘细节的提取精度;3种模型在区域1的大型湖泊处均出现了大面积误检,其主要原因是在目前的模型训练中缺乏足够多的湖泊类型的负样本作为输入。

|
| 图 6 建筑物检测全局评价结果比较 Fig. 6 The overall results of building detection using different methods |
图 7所示为随机选取的若干放大到接近原始分辨率的局部评价结果,从中可看出HOG-Ada模型基本不具备准确检出建筑物形态的能力,误检和漏检现象均较为突出,且存在明显的椒盐效应。而在其他CNN模型的检测结果中:对于形状较规则且无遮挡的建筑物(如(b)列和(d)列),3种模型都能实现高精度检测;(a)、(f)和(h)列中,U-Net与改进U-Net相比FCN更好地控制了建筑物边缘处的误检或漏检;(c)、(e)和(g)列中由于树木的遮挡,3种模型的检测精度均明显下降,但改进U-Net相比经典U-Net效果更好;(a)、(c)和(g)列中,U-Net的检测结果内部均形成了漏检空洞,而改进U-Net则未出现这种情况,这说明次级损失函数的约束有效加强了网络在抽象层面对建筑物的整体识别能力。

|
| 图 7 建筑物检测局部评价结果比较 Fig. 7 The local results of building detection using different methods |
定量评价方面,交并比(intersection over union,IoU)和检测准确率(pixel accuracy)[22]是图像分割领域较通用的两项指标,分别表示检测结果的整体精度水平和其中正确部分所占比例系数,其计算公式如下
 (4)
(4)
式中,TP表示正确检测(true positive);FP表示错误检测(false positive);FN表示遗漏检测(false negative)。
除了以上两项指标,本文同时采用遥感分类应用中常用的指标Kappa[23]对4种模型的测试结果进行了评价。从表 1中可以看出,HOG-Ada模型在各项指标上均全面落后于其他3种CNN模型,U-Net模型在4个测试区域和3个评价指标上均明显优于FCN模型,而本文提出的改进U-Net模型则在U-Net的基础上进一步实现了全面提升。从反映模型综合性能的关键指标IoU和Kappa的均值来看,U-Net模型相比FCN模型分别提升了7.3%和5.5%,而改进U-Net则将经典模型的水平进一步提升了2.5%和1.8%。
| (%) | ||||||||||||||
| 测试区域 | IoU | pixel accuracy | Kappa | |||||||||||
| HOG-Ada | FCN | U-Net | 改进U-Net | HOG-Ada | FCN | U-Net | 改进U-Net | HOG-Ada | FCN | U-Net | 改进U-Net | |||
| 区域1 | 41.8 | 69.6 | 76.9 | 80.7 | 89.7 | 95.6 | 96.9 | 97.6 | 53.1 | 79.6 | 85.2 | 87.9 | ||
| 区域2 | 36.7 | 76.3 | 82.6 | 84.8 | 85.0 | 95.7 | 97.1 | 97.6 | 44.8 | 84.0 | 88.7 | 90.3 | ||
| 区域3 | 34.1 | 76.5 | 83.7 | 85.6 | 82.2 | 95.6 | 97.1 | 97.6 | 39.7 | 84.0 | 89.4 | 90.7 | ||
| 区域4 | 36.4 | 73.3 | 81.4 | 83.8 | 81.3 | 94.5 | 96.3 | 96.9 | 41.4 | 81.0 | 87.4 | 89.1 | ||
| 均值 | 37.3 | 73.9 | 81.2 | 83.7 | 84.6 | 95.4 | 96.9 | 97.4 | 44.8 | 82.2 | 87.7 | 89.5 | ||
效率方面,以一台装有64位Ubuntu系统、配备NVIDIA GeForce GTX 1070 GPU的ASUS工作站为试验平台,训练阶段的耗时与模型复杂程度成正比,FCN、U-Net和改进U-Net模型分别耗费5.75 h、10.29 h和10.65 h,测试阶段3个模型在4个子区域(覆盖面积3.75 km2,含33 000×20 000像素)的平均耗时分别为207 s、208 s和250 s。总体而言,改进后的U-Net模型并未明显增加算法的时间开销,尽管模型的训练与调试相对耗时,但模型固化后,测试阶段的效率水平表现出了一定的应用潜力。
2.3 双重约束之权重分析为了进一步分析双重约束对U型卷积网络的性能影响,本文通过对主要损失和次级损失设置不同大小的权值,即分别取α为0.125、0.25、0.5、0.75和0.875进行了多组试验。如图 8所示为使用不同权值的建筑物检测结果在IoU、检测准确率和Kappa 3个指标上的性能表现。从中可以看出,3项指标反映出相似的变化趋势:①当α在区间[0.25,0.75]之间变化时各指标波动较小,且均维持在较高的水平,这说明双重约束的U-Net模型对权值的选取并不敏感;②当α取值在区间[0.25,0.75]之外时,3项指标均显著下降,这充分体现了本文提出的双重约束对于保障模型性能的必要性;③α偏低的情况相较其偏高的情况表现更差,肯定了在卷积网络中主要约束相对于次级约束的重要性。

|
| 图 8 损失函数权重变化对检测精度的影响 Fig. 8 The impact of the cost function's weights on the accuracy of building detection |
3 结论
本文将U型卷积神经网络的设计思想应用于航空影像建筑物检测,有效融合了深度卷积网络中的高维和低维特征,实现了建筑物目标的高精度提取。此外,顾及经典U-Net模型对位于特征金字塔顶层的相关参数优化程度相对不足,本文进一步提出了一种双重约束的改进U-Net模型,即通过联合主要和次级损失构建代价函数,增强了模型对低维抽象特征的学习能力。通过在一个覆盖范围达30 km2、含建筑物对象28 000余个的大规模航空影像数据集上进行比较试验,证实了本文提出的改进U-Net模型能够在IoU和Kappa两项关键评价指标的均值上分别达到83.7%和89.5%,其表现优于经典U-Net模型,显著优于全卷积网络FCN模型和基于人工设计特征HOG的AdaBoost模型。后续研究中将进一步扩大试验区域,并在模型训练中针对性地增加湖泊、雪地等负样本,以提升对此类非建筑物对象的判别能力。
| [1] | HUERTAS A, NEVATIA R. Detecting Buildings in Aerial Images[J]. Computer Vision, Graphics, and Image Processing, 1988, 41(2): 131–152. DOI:10.1016/0734-189X(88)90016-3 |
| [2] | MCGLONE C, SHUFELT J A. Projective and Object Space Geometry for Monocular Building Extraction[C]//IEEE Computer Society Conference Computer Vision and Pattern Recognition. Seattle, WA: IEEE, 1994. http://oai.dtic.mil/oai/oai?verb=getRecord&metadataPrefix=html&identifier=ADA277586 |
| [3] | PESARESI M, GERHARDINGER A, KAYITAKIRE F. A Robust Built-up Area Presence Index by Anisotropic Rotation-invariant Textural Measure[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2008, 1(3): 180–192. DOI:10.1109/JSTARS.2008.2002869 |
| [4] |
林祥国, 张继贤.
面向对象的形态学建筑物指数及其高分辨率遥感影像建筑物提取应用[J]. 测绘学报, 2017, 46(6): 724–733.
LIN Xiangguo, ZHANG Jixian. Object-based Morphological Building Index for Building Extraction from High Resolution Remote Sensing Imagery[J]. Acta Geodaetica et Cartographica Sinica, 2017, 46(6): 724–733. DOI:10.11947/j.AGCS.2017.20170068 |
| [5] | PENG J, LIU Y C. Model and Context-driven Building Extraction in Dense Urban Aerial Images[J]. International Journal of Remote Sensing, 2005, 26(7): 1289–1307. DOI:10.1080/01431160512331326675 |
| [6] | LHOMME S, HE Dongchen, WEBER C, et al. A New Approach to Building Identification from Very-high-spatial-resolution Images[J]. International Journal of Remote Sensing, 2009, 30(5): 1341–1354. DOI:10.1080/01431160802509017 |
| [7] | INGLADA J. Automatic Recognition of Man-made Objects in High Resolution Optical Remote Sensing Images by SVM Classification of Geometric Image Features[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2007, 62(3): 236–248. DOI:10.1016/j.isprsjprs.2007.05.011 |
| [8] | AYTEKIN Ö, ZÖNGVR U, HALICI U. Texture-based Airport Runway Detection[J]. IEEE Geoscience and Remote Sensing Letters, 2013, 10(3): 471–475. DOI:10.1109/LGRS.2012.2210189 |
| [9] | DONG Yanni, DU Bo, ZHANG Liangpei. Target Detection Based on Random Forest Metric Learning[J]. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2015, 8(4): 1830–1838. DOI:10.1109/JSTARS.2015.2416255 |
| [10] | LI Er, FEMIANI J, XU Shibiao, et al. Robust Rooftop Extraction from Visible Band Images Using Higher Order CRF[J]. IEEE Transactions on Geoscience and Remote Sensing, 2015, 53(8): 4483–4495. DOI:10.1109/TGRS.2015.2400462 |
| [11] | LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-Based Learning Applied to Document Recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278–2324. DOI:10.1109/5.726791 |
| [12] | RUSSAKOVSKY O, DENG Jia, SU Hao, et al. Imagenet Large Scale Visual Recognition Challenge[J]. International Journal of Computer Vision, 2015, 115(3): 211–252. DOI:10.1007/s11263-015-0816-y |
| [13] | VAKALOPOULOU M, KARANTZALOS K, KOMODAKIS N, et al. Building Detection in very High Resolution Multispectral Data with Deep Learning Features[C]//IEEE International Geoscience and Remote Sensing Symposium. Milan, Italy: IEEE, 2015: 1873-1876. http://www.researchgate.net/publication/308828699_Building_detection_in_very_high_resolution_multispectral_data_with_deep_learning_features |
| [14] | GUO Zhiling, SHAO Xiaowei, XU Yongwei, et al. Identification of Village Building via Google Earth Images and Supervised Machine Learning Methods[J]. Remote Sensing, 2016, 8(4): 271. DOI:10.3390/rs8040271 |
| [15] | LONG J, SHELHAMER E, DARRELL T. Fully Convolutional Networks for Semantic Segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE, 2015: 3431-3440. http://www.jourlib.org/paper/4083617 |
| [16] | PIRAMANAYAGAM S, SCHWARTZKOPF W, KOEHLER F W, et al. Classification of Remote Sensed Images Using Random Forests and Deep Learning Framework[C]//Proceedings Volume 10004, Image and Signal Processing for Remote Sensing XXⅡ. Edinburgh, United Kingdom: SPIE, 2016, 10004: 100040L. http://proceedings.spiedigitallibrary.org/proceeding.aspx?articleid=2571487 |
| [17] | MARMANIS D, WEGNER J D, GALLIANI S, et al. Semantic Segmentation of Aerial Images with an Ensemble of CNNS[J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2016, Ⅲ-3: 473–480. |
| [18] | MAGGIORI E, TARABALKA Y, CHARPIAT G, et al. Convolutional Neural Networks for Large-scale Remote-Sensing Image Classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(2): 645–657. DOI:10.1109/TGRS.2016.2612821 |
| [19] | BADRINARAYANAN V, KENDALL A, CIPOLLA R. Segnet:A Deep Convolutional Encoder-decoder Architecture for Image Segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(12): 2481–2495. |
| [20] | NOH H, HONG S, HAN B. Learning Deconvolution Network for Semantic Segmentation[C]//Proceedings of the IEEE International Conference on Computer Vision. Santiago, Chile: IEEE, 2015: 1520-1528. http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=7410535 |
| [21] | RONNEBERGER O, FISCHER P, BROX T. U-net: Convolutional Networks for Biomedical Image Segmentation[M]//NAVAB N, HORNEGGER J, WELLS W, et al. Medical Image Computing and Computer-Assisted Intervention-MICCAI 2015. Cham: Springer, 2015: 234-241. |
| [22] | DALAL N, TRIGGS B. Histograms of Oriented Gradients for Human Detection[C]//IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Diego, CA: IEEE, 2005: 886-893. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=1467360 |
| [23] | FREUND Y, SCHAPIRE R E. A Desicion-theoretic Generalization of On-line Learning and an Application to Boosting[C]//VITÁNYI P. Computational Learning Theory. Berlin: Springer, 1995: 23-37. https://link.springer.com/chapter/10.1007/3-540-59119-2_166 |
| [24] | CARLETTA J. Assessing Agreement on Classification Tasks:The Kappa Statistic[J]. Computational Linguistics, 1996, 22(2): 249–254. |