



2. 立命馆大学理工学部情报学科, 日本 滋贺 520072
2. Department of Computer Science & Media Technology, Ritsumeikan University, Shiga 520072, Japan
近年来,计算机视觉技术发展迅速,利用计算机视觉技术进行三维重建已经变得快速、高效和便捷,并在逆向工程、3D打印、工业检测、文物保护等方面得到了广泛的应用[1]。在三维重建过程中,为了得到完整的三维模型,需要将不同角度获取的数据配准到统一的坐标系下[2]。在实际应用中,由于拼接误差的存在,往往会导致重叠区域出现分层的现象,而且直接拼接得到的结果无法保证数据的均匀性。因此,对拼接好的数据作进一步的融合处理具有十分重要的意义。
文献[3]中提出的融合方法,是将空间划分成固定大小的体素格,将落入同一个体素格的所有点求加权平均值作为融合后的点[4];这种方法保证了数据的均匀性,但是无法降低由于拼接误差带来的噪声。文献[5]提出了截断有向距离场(truncated signed distance field, TSDF)的方法,该方法利用有向距离提取等值面来得到表面重建结果。这种算法可以降低单帧数据的噪声、减小不同帧数据之间的拼接误差。文献[6-7]借鉴了文献[5]的方法,提出了KinectFusion算法,主要思想是在GPU显存中建立一个固定大小的立方体(volume)[8],将立方体划分为体素格,在体素格中构建TSDF;虽然算法速度较快,但是由于立方体的大小是固定的,因此无法完成大场景的三维重建。
针对KinectFusion算法的局限性,很多论文提出了改进[9-17]。文献[9-11]提出了立方体随相机移动的方法以实现空间的扩展,可是在相机移动时,移出当前视野范围的体素格被清空,如果后续还需要这部分格子,则已经无法恢复。目前最新的研究主要是通过改变数据结构来压缩立方体占用的空间,其中文献[12-15]都用到了树形数据结构,如八叉树、KD树[15]等,但是这些算法时间复杂度较高,无法满足实时性的要求。文献[16-17]提出了用Voxel Hashing[18]的方法来存储TSDF,由于哈希表查询、插入、删除的时间复杂度为常数级O(1),因此该方法不仅有效降低了内存容量的占用而且具有较高的速度优势。但该方法所用的哈希函数发生冲突的概率较高,当冲突次数较多时会严重拖慢算法的效率,同时增加了内存溢出的风险,而且Voxel Hashing[18]方法仍然需要一次性分配固定大小的内存容量,限制了三维重建的可扩展范围。
本文在借鉴Voxel Hashing的方法的基础上,提出一种采用MD5[19]编码的点云融合方法,有效降低了冲突次数,提高了数据索引、更新与插入的效率。并设计了一种新的内存分配方式,可以在实时扫描的过程中自动分配内存,有效增大了三维重建的可扩展范围。
1 三维点云数据实时管理方法 1.1 三维点云融合算法TSDF的计算方法有很多[6, 20-21],如文献[20]利用体素网格点与深度图的特殊几何关系解方程组求解有向距离,文献[21]针对获取的单帧深度数据为三维曲线的情况提出了相适应的计算方法。由于本文研究的深度相机一次可以获取一个面阵的深度图,所以采用KinectFusion[6]的方法来计算有向距离场。
首先,将三维空间划分为相等大小的体素(voxel),体素x的位置由其中心点决定。每个体素中存储了两个值[22],有向距离sdfi(x)和权重wi(x)。sdfi(x)表示沿着当前观测方向体素格中心点与最近的物体表面的有向距离。在物体表面之前(物体外部)距离被定义为正值,在物体表面之后(物体内部)为负值。wi(x)权重用来评价当前sdfi(x)值的可靠性。下标i表示第i次的观测值。
sdfi(x)的计算方法可以通过如下公式表示
 (1)
(1)
式中,pic(x)是体素中心点在深度图中的投影;因此depthi(pic(x))是相机沿着穿过x的观测光线到最近的物体表面点p的深度。相应的,camz(x)是体素与相机沿着主光轴方向的距离。所以,最终计算的sdfi(x)也是一个沿着主光轴方向的距离。
在文献[6-7]中sdf的取值在阈值±t处被截断了。这是因为距离非常远的格子对表面的重建是没有作用的,而限制取值的范围可以有效降低内存的占用。这种sdfi(x)的变体被表示为tsdfi(x)。可以由如下公式计算得到
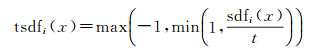 (2)
(2)
图 1表示了体素格的tsdfi(x)在物体表面的分布,tsdfi(x)的值用不同深度的颜色进行区分,在视场范围外的tsdfi(x)格子表示为白色。体素x的sdf值由物体上的点P的深度与体素x到相机的距离camz(x)相减求得。

|
| 图 1 TSDF计算原理 Fig. 1 Principle of TSDF |
将每次观测到的tsdfi(x)值整合到一个TSDF中,整合的过程是通过加权平均实现的。具体方法如下
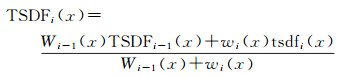 (3)
(3)
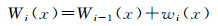 (4)
(4)
TSDFi(x)表示所有观测值tsdfj(x)(1≤j≤ i)的集合,Wi(x)是评价TSDFi(x)的可靠性的权重。体素格的初值TSDF0(x)=0和W0(x)=0。每次获得的新观测值都通过以上的公式整合到每个体素x中。每次需要更新的体素的新权重wi(x)=1,而对于超出相机视场范围的所有体素的权重wi(x)=0。通过上述方法对于每次测量的TSDF观测值进行动态的加权平均。
1.2 数据结构本文采用了与Voxel Hashing相同的结构体来存储TSDF,结构体定义如下:
struct voxel{
float tsdf;
uchar colorRGB[3];
uchar weight;}
每个结构体占用8个字节,存储了当前体素的TSDF值、颜色和权重。将固定个数的体素(默认为83个)合并到一起存储,称为一个体素块(block),存储时以左下角点的坐标定义整个体素块的坐标;体素块内所有的体素都按x-y-z的顺序连续存储,由体素块的坐标可以求出每个体素的坐标。
所有的体素块通过一个Hash table(哈希表)来管理,哈希表的底层可以被认为是一个大小为n的数组,数组的每一项指向一个被称为bucket(桶)的类似于链表的结构。哈希表中每个元素存储的结构体如下:
struct HashEntry{
short position[3];
short offset;
int pointer; }
其中,pointer一个是指向体素块的地址的标记;position存储了该体素块的坐标,offset是一个bucket偏移量标记,是为了解决哈希冲突而设计的。
在插入数据时,由哈希函数计算出哈希值,用哈希值模n获取到桶号Hi,即该数据在哈希表中的地址,将数据存入该地址;当发生数据冲突(不同的数据落入同一个桶内)时,该元素被存入桶中下一个空缺的位置。为提高寻址的效率,桶的大小是固定的,但是这样无法避免桶溢出现象的发生,通过一种类似于链表的机制可以解决这个问题。当溢出发生时,这个桶的最后一个元素被预留出来,用这个元素的offset字段来指向哈希表中一个新的桶,从该位置开始仍然按照顺序存储每个溢出的元素。链表之间的相互关系都通过offset字段来指示。在确定链表的新地址时需要对哈希表进行线性地搜索,来找到一个空的桶存储新元素。
哈希表的键值由体素中心点的坐标通过哈希函数计算得到,首先通过如下的公式将三维坐标转换为一个一维的索引
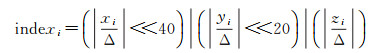 (5)
(5)
式中,Δ为当前分辨率的大小,即一个体素的大小,通过简单的移位运算将三维坐标转换为一维索引,该索引可以表示x、y、z分别在±219范围内的所有坐标值,满足大多数的应用场景。
计算好的一维索引通过MD5[19]转化为哈希值。MD5具有抗冲突的特性,可以将任意长度的数据转化为128位二进制值,转化的具体过程如下:
(1) 在数据后面添补一个1和若干0,使字节长度模512得448,数据在被添补前的长度表示在最后的64位,添补后的数据长度是512的整数倍。
(2) 以512位为分组处理添补后的数据,每个组又分为16个32位子块,使用4个32位寄存器Qt,Qt-1,Qt-2,Qt-3循环处理子块;用四个链接变量作为参数初始化MD5,这4个变量分别为:a=0x0x67452301,b=0xefcdab89,c=0x98badcfe, d=0x10325476。
(3) 进行四轮循环压缩运算,每一轮有16步,每步使用一个消息字wi,步函数为
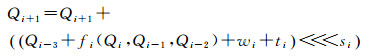 (6)
(6)
其中+是模32位加法,ti是一个常量,<<<si表示循环左移si位;每一轮的布尔函数如下
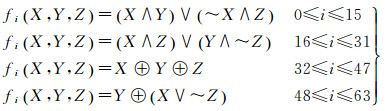 (7)
(7)
(4) 将4个32位子块级联得到一个128位值,即最终的哈希值。
1.3 内存动态管理Voxel Hashing的哈希表采用了预先分配内存的方式,这样虽然可以提高索引数据的效率,但是限制了三维重建场景的范围。本文借鉴了C++ 11的STL(standard template library)标准模板库中Hash map的内存管理方式,实现了内存的动态扩展,当预分配内存已经用满,自动对哈希表进行扩容,扩展了三维重建的场景范围。
在哈希表结构内部增设了一个整型变量,用于实时更新已经插入的元素个数,当插入元素个数接近哈希表的大小时,停止向当前哈希表插入元素,并分配一个同等大小的新哈希表,用新表的头指向旧表的尾;然后对哈希表进行重构,设旧表的大小为n,那么新表的大小为2n,对之前所有插入的元素的哈希值模2n得到新的桶号,将之前旧表中的元素全部移动到扩展后的新表中。重构之后,可以对哈希表进行插入操作。
重构哈希表的时间与哈希表的大小呈正相关,如图 2所示,元素个数增加,哈希表重构的耗时增加。当预分配的哈希表较小时,需要进行多次哈希表的扩展,每次扩展哈希表都要产生一次重构操作,因此,预分配哈希表的大小合理可以减少重构的次数,提高插入数据的效率。影响哈希表大小的主要是体素格的个数,场景越大三维重建需要的体素格的数量越多;场景大小不变,划分的体素格越小(即分辨率越高),体素格的数量也越多,因此,预分配的哈希表的大小需要根据三维重建场景的大小和分辨率来确定。

|
| 图 2 重构哈希表耗时统计 Fig. 2 Time for reconstitution of Hash table |
由于本文采用了“out-of-core[23]”方法(见2.5节)进行GPU与主机的数据交换,保存在GPU中哈希表的实际大小由当前相机的视锥体来确定,落入视锥体中的体素格被传入GPU的显存中,落在视锥体之外的格子在GPU上释放并传入主机内存中。因此,预分配的哈希表的大小如果可以满足当前视锥体中场景的需要,那么就不需要对哈希表进行重构。以kinect深度相机为例,深度识别范围为0~4 m,水平方向视场角为70°,垂直方向视场角为60°,可以计算出视锥体的体积约为34.50 m3。设体素的大小为4 mm,则填充整个视锥体需要约5.39×108个体素。由于哈希表的每个元素指向的是一个由512个体素构成的体素块,所以根据以上的测算哈希表的大小应为106。在实际中三维场景不可能填满整个视锥体,因此预分配4.0×105个元素的哈希表就可以满足大部分实际三维场景的需要。
在插入新元素时,为避免线程之间的写入冲突,需要使用“原子锁”对当前写入的数据进行保护,直到当前线程处理完毕,当前的数据不可被其他线程操作。这样既保证哈希表中没有重复的数据,又保证了桶中的数据存储的连续性。
在访问表中的元素时,如果找到的目标桶中有多个元素,则要遍历桶中的所有元素,如果桶中最后一个元素指向了一个新的元素链表,则该链表也需要遍历。虽然桶内的元素在存储时是连续存储的,但删除操作会导致元素变得碎片化,因此,当遍历出现空元素时,遍历即可停止。
删除元素跟插入元素类似,同样需要遍历桶和链表;如果删除的元素是头尾元素,则需要更新元素之间的指向关系,还需要对元素作“原子锁”操作;如果删除的是桶内部的元素,则不需要“原子锁”。
在更新TSDF时,首先用当前帧的深度数据计算得到截断区域范围内有效的体素块,再根据哈希函数求出体素块在哈希表中位置,如果数据是一个新插入的元素,则将其存入到一个实时维护的动态数组中,并将Hash entry中的pointer指向数组的对应地址;如果数据索引到了表中已经存在的元素,则更新元素指向的体素中的TSDF值。
由于噪声和拼接误差的存在,往往会存在一些格子存储了难以被重复采集到的离群点,这些点会影响表面重建的质量,因此,清理离群点是十分必要的,清理可以通过判断TSDF的绝对值和权重来完成。当采集较长时间,权重一直较小,说明该点一直没有被采集到,但是也不能完全就此断定该点为离群点,因为物体的一些缝隙、边缘往往也很难被采集。这就需要通过TSDF的绝对值来进一步判断,当TSDF绝对值较大,说明该点距离物体表面较远,为离群点。由于体素格数据在内存中是连续存储的,在清理离群点时,如果直接对数组进行删除操作,则需要大量地进行内存的移位操作,非常影响效率,所以,对离群点设定一个无效标记,使其不参与实时渲染和最终结果的生成。这样做既保证了数据质量,又不影响效率。
1.4 等值面提取在表面重建时,TSDF可以被认为是一组等值面的集合。要提取的物体表面就是TSDF值为0处的等值面。通常在实时过程中,等值面是通过“光线跟踪[24-25]”的方法来提取的。构建好的TSDF也可以运用Marching Cubes[26]方法来生成三角网表面数据。
“光线跟踪”是从当前相机位置的深度图的每个像素发出的一条光线,投射到物体的体素格上,判断沿着光线穿过的所有格子的符号,找到符号变化的位置(过零点),然后利用周围的格子内插得到过零点的坐标。
三线性插值是一种常用的插值方法,设待插值p(x, y, z)为如图 3所示的立方体中的任意一点,插值所需要的8个角点上的值可以表示为
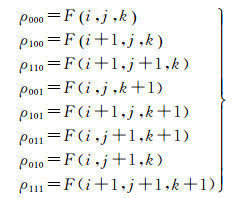 (8)
(8)

|
| 图 3 三线性插值采样点示意 Fig. 3 Sample points of trilinear interpolation |
插值权重u、v、w∈[0, 1],可以表示为
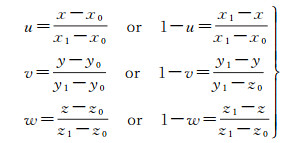 (9)
(9)
那么点p的值ρ(u, v, w)可以通过下面的方法获得
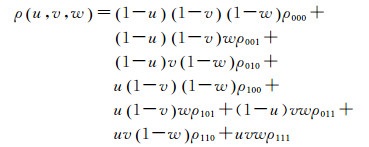 (10)
(10)
由于哈希表是在GPU上实现的,当数据量较大时,所有数据是无法都存储在显存中的,而且在重建过程中当前视图也不需要显示全部数据。“out-of-core[23]”方法是一种经常被用于海量三维数据管理的方法,本文借鉴“out-of-core”方法,建立主机与GPU之间的双向流。在相机移动时,用当前相机位置姿态确定的视锥体判断体素格,落在视锥体外的格子被释放,并将其压入一个包含2帧缓存的队列中,每当有新数据进入队列中,则把上一帧数据压出队列,将其存入主机内存;在主机端,这些格子的数据块同样以队列的形式存储,以方便查找。当数据块落入视锥体时,则将这部分数据传入缓存中,取出上一帧数据将其存入GPU的哈希表中。在哈希表中插入或删除数据的方法已经在2.3节中描述。
2 试验结果与分析为了验证本文所提出的改进方法的有效性和可行性,用Kinect2.0作为深度数据采集设备(彩色相机分辨率:1920×1080,深度相机分辨率:512×424,单帧点云数:2.11×105),测试了不同场景下,在不同配置等级的计算机设备上,本文方法的帧率。
图 4为不同场景的三维重建结果,场景1为一张办公桌及周围的环境(大致范围1.4 m×1.2 m×1.6 m),扫描时长4 min,融合的体素大小(即分辨率)为4 mm,最终获得模型数据共有3 445 256个面。从结果可以看出该分辨率下细节保留较好,植物叶片可以清晰地辨认。数据实际占用体素格2.01×107个,使用内存153 MB左右。如果按照KinectFusion的方法,按照包围整个场景大小的立方体分配内存,则需要4.2×107个体素格, 需要占用内存320 MB左右,因此,使用Voxel Hashing方法节省了约52.19%的内存。场景2为一间办公室的一侧(9.0 m×1.2 m×1.6 m),扫描时长8 min,分辨率为6 mm,得到的模型数据共有6 534 607个面,场景范围较大,占用体素格2.24×107个,使用内存170 MB左右。如果用KinectFusion的方法则需要8.0×107个体素格,约占用内存610 MB,Voxel Hashing节省了大约72.04%左右的内存。

|
| 图 4 本文算法不同场景三维重建效果 Fig. 4 Output from the proposed algorithm of different test scenes |
表 1比较了在不同计算机设备上,同一场景(图 4(b))不同分辨率,算法的执行效率。可以看出,分辨率对帧率的影响很大,这是因为分辨率提高每一帧需要处理的体素增多;同时显卡性能对帧率的影响也比较大,在性能相对较弱的GTX1050上,算法速度最慢,但是帧率都保持在了60帧/s以上,满足了实时性的要求。从本次试验选用的硬件配置可以看出,算法对硬件的要求并不高,消费级设备即可满足需求。
| 帧/s | |||
| 设备 | 分辨率/mm | ||
| 6 | 8 | 10 | |
| Inter Core i7 2.8 GHz 16 GB RAM,NVIDIA GeoForce GTX1050 | 71.4 | 90.9 | 141.5 |
| Inter Core i7 3.6 GHz 16 GB RAM,NVIDIA GeoForce GTX960 | 78.2 | 98.6 | 150.1 |
| Inter Core i7 3.6 GHz 16 GB RAM,NVIDIA GeoForce GTX1060 | 84.6 | 101.3 | 161.3 |
表 2比较了同一场景(图 4(b))不同分辨率,在同样的计算机设备(Inter Core i7 2.8 GHz 16 GB RAM NVIDIA GeoForce GTX1050)上,本文提出的改进算法与Voxel Hashing原算法的平均帧率,可以看出本文的算法对原算法平均贡献了20%左右的速率提升,改进效果比较明显。
| 帧/s | |||
| 算法 | 分辨率/mm | ||
| 6 | 8 | 10 | |
| 本文算法 | 71.4 | 90.9 | 141.5 |
| Voxel Hashing算法 | 58.8 | 71.4 | 94.3 |
3 结论
本文提出了一种基于Hash map的三维点云数据实时管理方法,详细介绍了算法使用的数据结构、数据管理和点云融合的具体实现过程。通过在不同配置的计算机上试验,证明了算法的可行性和有效性,对于单帧数据量在2.1×105左右的点云数据,算法帧率稳定在60帧/s以上,达到实时性的帧率要求,实现了高效地数据插入、更新和索引,满足了三维构像中三维点云数据高效管理的要求。
相比于Voxel Hashing,本文采用MD5方法编码哈希值,有效降低了冲突次数,从试验结果中可以看出本文的算法可以带来20%左右的速率提升。本文还设计了一种新的内存分配方式,可以在实时扫描的过程中自动分配内存,提高了算法的实用性。本文提出的内存管理方式,虽然较Voxel Hashing更为灵活更加适合实际的三维扫描过程,但缺点在于内存重新分配时需要对哈希表进行重构,在实时扫描过程中会表现为一次较长时间的卡顿,用户体验感较差。因此,未来的研究侧重于如何减少哈希表重构的耗时,以进一步提升算法的性能。
| [1] |
郑顺义, 周漾, 黄荣永, 等.
馆藏文物三维测量与重建方法研究[J]. 测绘科学, 2014, 39(7): 76–79.
ZHENG Shunyi, ZHOU Yang, HUANG Rongyong, et al. A Method of 3D Measurement and Reconstruction for Cultural Relics in Museums[J]. Science of Surveying and Mapping, 2014, 39(7): 76–79. |
| [2] |
翟瑞芳, 张剑清.
基于激光扫描仪的点云模型的自动拼接[J]. 地理空间信息, 2004, 2(6): 37–39.
ZHAI Ruifang, ZHANG Jianqing. Automatic Registration of Point Clouds Based on Laser Scanner[J]. Geospatial Information, 2004, 2(6): 37–39. |
| [3] | RUSINKIEWICZ S, HALL-HOLT O, LEVOY M. Real-time 3D Model Acquisition[J]. ACM Transactions on Graphics (TOG), 2002, 21(3): 438–446. |
| [4] | ROSSIGNAC J, BORREL P. Multi-resolution 3D Approximations for Rendering Complex Scenes[C]//FALCIDIENO B, KUNⅡ T L. Modeling in Computer Graphics. Berlin, Heidelberg: Springer, 1993: 455-465. |
| [5] | CURLESS B, LEVOY M. A Volumetric Method for Building Complex Models from Range Images[C]//Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques. [S. l. ]: ACM, 1996: 303-312. |
| [6] | NEWCOMBE R A, IZADI S, HILLIGES O, et al. Kinect-Fusion: Real-time Dense Surface Mapping and Tracking[C]//Proceedings of the 10th IEEE International Symposium on Mixed and Augmented Reality. Basel, Switzerland: IEEE, 2011: 127-136. |
| [7] | IZADI S, KIM D, HILLIGES O, et al. KinectFusion: Real-time 3D Reconstruction and Interaction Using a Moving Depth Camera[C]//Proceedings of the 24th Annual ACM Symposium on User Interface Software and Technology. Santa Barbara, California: ACM, 2011: 559-568. |
| [8] |
谭歆. KinectFusion三维重建的再优化[D]. 杭州: 浙江大学, 2015. TAN Xin. Global Optimization for 3D Reconstruction Based on KinectFusion[D]. Hangzhou: Zhejiang University, 2015. http://www.wanfangdata.com.cn/details/detail.do?_type=degree&id=Y2882252 |
| [9] | WHELAN T, MCDONALD J, KAESS M, et al. Kintinuous: Spatially Extended Kinectfusion[R]. Cambridge: MIT, 2012. http://www.cs.nuim.ie/research/vision/data/rgbd2012/ |
| [10] | WHELAN T, JOHANNSSON H, KAESS M, et al. Robust Real-time Visual Odometry for Dense RGB-D Mapping[C]//Proceedings of 2013 IEEE International Conference on Robotics and Automation. Karlsruhe, Germany: IEEE, 2013: 5724-5731. |
| [11] | ROTH H, VONA M. Moving Volume KinectFusion[C]//Proceedings of the British Machine Vision Conference. Boston, MA: BMVA Press, 2012: 1-11. |
| [12] | ZENG Ming, ZHAO Fukai, ZHENG Jiaxiang, et al. Octree-based Fusion for Realtime 3D Reconstruction[J]. Graphical Models, 2013, 75(3): 126–136. DOI:10.1016/j.gmod.2012.09.002 |
| [13] | ZENG Ming, ZHAO Fukai, ZHENG Jiaxiang, et al. A Memory-efficient Kinectfusion Using Octree[M]//Proceedings of the 1st International Conference on Computational Visual Media. Beijing, China: Springer, 2012: 234-241. |
| [14] | CHEN Jiawen, BAUTEMBACH D, IZADI S. Scalable Real-time Volumetric Surface Reconstruction[J]. ACM Transactions on Graphics (TOG), 2013, 32(4): 113. |
| [15] | KÄMPE V, SINTORN E, ASSARSSON U. High Resolution Sparse Voxel Dags[J]. ACM Transactions on Graphics (TOG), 2013, 32(4): 101. |
| [16] | NIEβNER M, ZOLLHÖFER M, IZADI S, et al. Real-time 3D Reconstruction at Scale Using Voxel Hashing[J]. ACM Transactions on Graphics (TOG), 2013, 32(6): 169. |
| [17] | KLINGENSMITH M, DRYANOVSKI I, SRINIVASA S, et al. Chisel: Real Time Large Scale 3D Reconstruction Onboard a Mobile Device Using Spatially-Hashed Signed Distance Fields[C]//Proceedings of Robotics: Science and Systems. Rome, Italy: [s. n. ], 2015: 4. |
| [18] | TESCHNER M, HEIDELBERGER B, MVLLER M, et al. Optimized Spatial Hashing for Collision Detection of Deformable Objects[C]//Proceedings of the 8th Workshop on Vision, Modeling, and Visualization. Munich, Germany: AKA, 2003: 47-54. |
| [19] | RIVEST R. The MD5 Message-digest Algorithm[R]. Request for Comments 1321 Cambridge: MIT Laboratory for Computer Science and RSA Data Security, Inc, 1992. http://dl.acm.org/citation.cfm?id=RFC1321 |
| [20] | TUBIC D, HÉBERT P, LAURENDEAU D. A Volumetric Approach for Interactive 3D Modeling[J]. Computer Vision and Image Understanding, 2003, 92(1): 56–77. DOI:10.1016/j.cviu.2003.07.001 |
| [21] | TUBIC' D, HÉBERT P, LAURENDEAU D. 3D Surface Modeling from Curves[J]. Image and Vision Computing, 2004, 22(9): 719–734. DOI:10.1016/j.imavis.2004.03.006 |
| [22] | WERNER D, AL-HAMADI A, WERNER P. Truncated Signed Distance Function: Experiments on Voxel Size[C]//Proceedings of the 11th International Conference Image Analysis and Recognition. Cham: Springer, 2014: 357-364. |
| [23] |
王攀. 基于Out-of-Core的海量数据等值面绘制技术研究与实现[D]. 长沙: 国防科学技术大学, 2008. WANG Pan. Research on Isosurface Extraction of Large Scale Datasets With Out-of-core Method[D]. Changsha: National University of Defense Technology, 2008. http://cdmd.cnki.com.cn/article/cdmd-90002-2009213380.htm |
| [24] | DESCHÊNES J D, HÉBERT P, LAMBERT P, et al. Multiresolution Interactive Modeling with Efficient Visualization[C]//Proceedings of the 5th International Conference on 3-D Digital Imaging and Modeling. Ottawa, Ontario, Canada: IEEE, 2005: 39-46. |
| [25] | ZWICKER M, PFISTER H, VAN BAAR J, et al. Surface splatting[C]//Proceedings of the 28th Annual Conference on Computer Graphics and Interactive Techniques. Los Angeles: ACM, 2001: 371-378. |
| [26] | LORENSEN W E, CLINE H E. Marching Cubes:A High Resolution 3D Surface Construction Algorithm[J]. ACM SIGGRAPH Computer Graphics, 1987, 21(4): 163–169. DOI:10.1145/37402 |