



2. 南京大学中国南海研究协同创新中心, 江苏 南京 210023;
3. 南京大学软件新技术与产业化协同创新中心, 江苏 南京 210023;
4. 南京大学地理与海洋科学学院, 江苏 南京 210023;
5. 南京师范大学江苏省地理信息资源开发与利用协同创新中心, 江苏 南京 210023
2. Collaborative Innovation Center for the South Sea Studies, Nanjing University, Nanjing 210023, China;
3. Collaborative Innovation Center of Novel Software Technology and Industrialization, Nanjing University, Nanjing 210023, China;
4. School of Geographic and Oceanographic Sciences, Nanjing University, Nanjing 210023, China;
5. Jiangsu Center for Collaborative Innovation in Geographical Information Resource Development and Application, Nanjing Normal University, Nanjing 210023, China
随着电子产品的普及和物联网的发展,人们习惯性地将在城市里发生的生活细节用手机拍摄下来,然后上传到主流图片分享网站和社交媒体。主流图片分享网站(如Flickr和Instagram等)和社交媒体网站(如新浪微博、QQ空间和百度贴吧等)上有大量照片,这些众筹照片有着不同来源、不同分辨率和不同尺寸[1-2]。然而,其中的大部分照片都没有地理坐标或仅有模糊的位置信息,而且经过上传、发布或下载,它们的位置信息容易丢失。如果这些众筹照片能被恢复出原始的位置,它们将可以用来辅助室外定位[3]、行人探测[4]、无人驾驶[5-6]等,这些对增强现实研究[7]都很有帮助;另外,它们也可以辅助城市景观分析[8-10]和城市建设[11]。目前,照片定位的主流方法可以分为3类:基于图像、基于点云和基于语义。
1 不同定位方法 1.1 基于图像的定位方法基于图像的照片定位方法类似于计算机视觉领域中的图像检索[13-14]。思路如下:首先建立一个包含大量照片(带有位置信息)的参考库,然后从参考库中检索与待查询的众筹照片最匹配的照片,最终用该最匹配照片的位置作为待查询照片的位置[15-19]。
与激光雷达点云(LiDAR)和遥感数据相比,街景数据提供了独特的“人视角”的地图服务,这与众筹照片的视角相一致。于是街景数据常被用来建立参考库,然后使用词汇树[20]、地理信息码本[21]或数据驱动的场景识别[22]等方法,或加上局部、全局等约束条件[19],来实现照片的地理定位。其中,用来描述局部特征的SIFT(scale-invariant feature transform)描述子已被不断优化,出现了SURF(speeded-up robust features)[23]和PCA-SIFT[24]描述子等,它们在特定情况下能提供更好的匹配效果[25-26]。
同时,匹配算法研究方面也有很大进展,深度学习算法促使了遥感影像的内容检索[27]与目标识别[28-29]、无人机视频的视频内容检索[30-31]和人工智能系统的迅速发展。
1.2 基于点云的定位方法基于点云的照片定位方法建立了2D图像与3D点云之间的对应关系,与基于图像的定位方法相比,基于点云的照片定位方法从重建的3D场景中获得更多的立体信息,从而实现了更高精度的定位[14]。文献[32]建立了由数千万3D点组成的数据集,使用随机抽样一致算法(RANSAC)和双向匹配规则,将照片地理定位、地标识别和3D姿态恢复融合在一起,实现了出色的定位效果。但该方法评价精度中,所用到的已地理配准好的3D点云很难建立[33-34]。
1.3 基于语义的定位方法基于语义的照片定位方法以高级语义线索为基础,这些语义线索小到与人相关的符号,如文字、建筑风格、车辆类型或城市结构等,大到与自然相关的信息,如植被类型或者天气状况等[35]。语义定位方法目前面临的难点可以概括为以下3点:使用什么特征、如何匹配特征和如何将多样的语义线索整合。文献[36]以互联网的语义元数据为基础,使用支持向量机(SVM)建立地标模型库,并总结得到纹理标签和时间条件的约束可以明显改善定位效果。
照片的精确地理定位一直是研究难点,这涉及对图像中细小地理位置线索的挖掘,对大数据库中地理信息特征的识别、提取、索引和检索等[12]。为了解决这个难题,本文提出以街景数据作为参考数据集,使用“三步走”策略:图像检索粗定位、图像匹配细筛选和三维重建精定位,给互联网上不明来源的众筹照片附上地理标签。相比之前Zamir和Shah的方法[18],该方法使用近景摄影测量技术来优化定位,实现了更精确的地理定位效果。
2 方法图 1(b)是以一张待查询照片为示例的流程。在流程中,一张待查询照片将会经历图像检索粗定位(第一步)、图像匹配细筛选(第二步)和三维重建精定位(第三步),从而实现精确地理定位。

|
| 图 1 本文方法 Fig. 1 Method of this paper |
所有待查询照片都会先经历第一、二步,然后判断是否满足重建要求,如果无法重建,将第一步获得的最匹配街景作为定位结果;如果可以重建,就经历第三步,将三维点云估算得到的位置作为照片定位结果。
并不是每张待查询照片都会经历三维重建精定位,因为有些照片如果在第一步的定位精度不理想,那么其缓冲区内相似街景数量可能不够,这将导致不满足三维重建要求。其他一些原因类似于拍摄视角、拍摄距离和拍摄环境也会导致无法重建三维场景。在这种情况下,最匹配街景的GPS坐标将会被作为照片定位结果。
2.1 图像检索粗定位图像检索粗定位的目标是为待查询照片检索到最匹配街景。方法流程如下:
2.1.1 通过腾讯地图API爬取街景数据作为参考数据集本文以12 m为采样间隔爬取街景数据,这与街景采集车采集街景的间隔相一致;在每个采样点,从初始方位角开始的顺时针一圈上,通过腾讯地图API,每45°爬取一张街景。腾讯地图API允许用户通过HTTP协议下的一个URL地址来访问并爬取一张街景照片,参数设置如表 1所示。
| 参数 | 说明 | 示例 |
| 尺寸 | 街景照片的尺寸:长×宽 | size=960×640 |
| 位置 | 坐标 | location=39.12, 116.83 |
| 偏航角 | 偏航角与正北方向的顺时针夹角 | due north: heading=0clockwise |
| 仰角 | 街景相机的俯角后者仰角 | pitch=0: horizontal angle. |
| 密钥 | 开发者密钥 | key=OB4BZ-D4W3U-7BVVO-4PJWW-6TKDJ-WPB77 |
本文给照片设定20°的仰角来模拟人视角,并以45°为间隔切割360°全景街景。最终每个采样点上,爬取8张960×640像素分辨率的街景,这样既保证了相邻街景的重叠又占用了较小的存储空间。这些结构化、组织好的街景数据组成了参考数据集。
2.1.2 提取和描述参考数据集特征以建立特征索引(1) 本文使用SIFT描述子提取和描述局部特征,因为SIFT描述子具有良好的尺度不变性和旋转不变性,可以很好地适应照片目标的旋转、缩放和变形[13]。因此,它可以处理好下载街景时切割球形照片产生的畸变。
(2) 本文使用Kd树给提取的特征建立索引。多维索引方式可以分为特征驱动和数据驱动两种方式,特征驱动方式使用数据结构(如Kd树)将多维空间中的向量迅速划分到不同的空间[37-38],数据驱动方式则根据数据分布进行聚类[17]。本文受存储空间限制,选择计算复杂度低且响应较快的特征驱动方式建立特征索引。
2.1.3 为待查询照片的每个特征(叫作待查询特征)在特征索引中寻找最近邻特征对任意一张待查询照片,首先提取和描述特征,然后通过计算欧几里得距离,为每一个待查询特征在特征索引中寻找最近邻特征。由于每个最近邻特征都对应一张街景、每个街景又对应一个GPS坐标,所以待查询照片的每个特征都对应一个可能的GPS位置。
2.1.4 获得最匹配街景在上一步,每个待查询特征对应一个可能的GPS位置,接着待查询特征对这些可能的位置进行投票。在理想情况下,所有的待查询特征投票给同一个位置,该位置即是真正的照片位置。然而实际上投票并不集中,所以需要接下来的修剪和平滑处理[18]。
(1) 本文使用Zamir和Shah提出的动态修剪方法[18],即当最近邻特征对应的位置分散时,根据位置分布修剪不可靠位置上的投票。这个方法被证明比文献[13]提出的方法更合适,因为文献[13]的方法只设定最近邻特征距离和次近邻特征距离之间的比例阈值来去除不可靠特征,而动态修剪方法则为下一步的平滑处理保留了更多的特征。
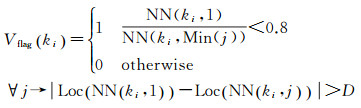 (1)
(1)
式中,Vflag(ki)是特征ki的投票标识,值为1时该特征参与投票,值为0时不参与投票。NN(ki, j)是待查询照片k的第i个特征的第j个近邻特征,Loc(NN(ki, j))是NN(ki, j)的GPS坐标,|*|是两个GPS坐标之间的空间距离,D是提前设定好的特征之间空间距离的阈值。最终,只去除了与最近邻特征空间距离较远而且比值大于0.8的特征。
(2) 本文使用高斯分布函数对修剪之后的投票进行平滑处理[18],使得正确位置对应的高投票数更明显。平滑处理放大了聚集峰、衰减了孤立峰,使得最高投票数(最有可能的拍摄位置)更加明显。
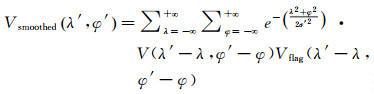 (2)
(2)
式中,λ和φ代表最近邻特征所对应街景照片的GPS坐标,V(λ, φ)与Vflag(λ, φ)分别是待查询照片特征的投票和投票标识,前面的参数是具有标准偏差σ′的二维高斯函数。
最终明显突出了正确的结果。本文将在最高投票数位置上的街景称为最匹配街景。
2.2 图像匹配细筛选本文首先通过图像检索,在参考数据集中检索到了最匹配街景;然后利用这个最匹配街景,从参考数据集中牵引出其他包含待查询照片信息的相关照片,然后将它们纳入相似街景集中,用作后续的三维重建。
2.2.1 生成所有街景采样点之间的空间距离表(1) 本文根据街景采样点已知的坐标,计算所有街景采样点之间的空间距离。
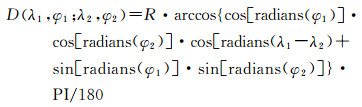 (3)
(3)
式中,(λ1, φ1)和(λ2, φ2)是两个采样点,经度分别为λ1、λ2,纬度分别是φ1、φ2。D(λ1, φ1; λ2, φ2)代表两个采样点之间的距离。R是地球半径。Radians是将度转为弧度的函数。
(2) 本文对某采样点的所有空间距离进行排序,确定在其特定范围内(叫作缓冲区范围)的采样点的编号。
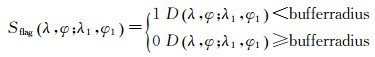 (4)
(4)
式中,λ, φ是最匹配照片的经度和纬度,λ1、φ1是另一个采样点的经度和纬度Sflagλ1, φ1是该采样点是否在最匹配照片的缓冲区范围内的标志。D(λ, φ; λ1, φ1)是两点(λ, φ)和(λ1, φ1)之间的距离。
2.2.2 将高相似度的街景加入到相似街景集本文使用具有仿射不变性的SIFT局部描述子,来计算缓冲区内街景和待查询照片的相似度,因为本文需要的照片相似度是局部相似度,而不是全局相似度。换句话说,本文希望相似内容但不同布局的两张照片,比相似布局但不同内容的两张照片,相似度更高。因此,本文将待查询照片与目标街景间特征匹配对的数量与待查询照片的特征总数的比值,作为相似度的衡量标准。特征匹配对的数量越多,比值越大,那么相似度越高。相似度计算公式如下
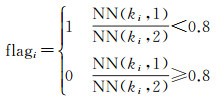 (5)
(5)
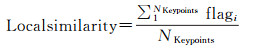 (6)
(6)
式中, NN(ki, j)是第k张待查询照片的第i个特征在目标街景中对应的第j个最近邻特征;flagi是第k张待查询照片的第i个特征是否找到其符合要求的特征匹配对的标识;NKeypoints是第k张待查询照片的特征总数。
本文根据前一步获得的最匹配街景,将其缓冲区范围内的高相似度街景归为相似街景集,将其缓冲区范围内的低相似度街景和不在其缓冲区范围内的街景归为无关街景集。由于相似街景集中的街景与待查询照片拍摄了相似的内容,但是角度和位置不一样,所以,相似街景集可以进行基于近景摄影测量的三维重建。
2.3 三维重建精定位本文使用低成本摄影测量技术SfM(structure from motion)来从2D照片中获得3D信息[39-40]。SfM技术既不需要相机参数也不需要地面控制点,它使用光束法平差对多个重叠的照片进行配准,来同时确定相机位置和地理场景。
2.3.1 提取特征和筛选特征本文使用一种抗差的仿射不变特征提取技术,综合利用当前最优的特征提取算子MSER[41]和最优的局部特征描述子SIFT,有效地提取高质量的局部不变特征。
本文使用基于信息量和空间分布均衡性双重约束的多层次特征筛选方法[42]。特征区域被检测出后、进行特征描述前,以信息量和空间分布均衡性为衡量标准,对提取出的特征进行评估,过滤掉信息量不佳、空间分布均衡性差的特征,只保留高质量特征,以提高特征的重复率以及后续的立体影像匹配的成功率,进而有利于后续的立体匹配。
2.3.2 匹配特征和筛选匹配对本文使用ANN(approximate nearest neighbors)算法[43]对已提取的特征进行匹配,得到匹配对,然后设定阈值筛选匹配对,去除较差的匹配对,进一步使用RANSAC算法对匹配对进行更精细的筛选,以提高匹配质量。
2.3.3 配准照片并生成点云试验证明,当两张照片之间存在超过5对匹配对,就可以实现2D照片到3D场景的映射[44],同时能确定照片姿态和照片中拍摄对象的相对位置。
本文使用的SfM算法是一种迭代计算[45]。首先,匹配对最多的一组照片I1和I2将被作为初始照片对来计算初始相机参数、初始坐标系统和点云。然后,以这个初始点云为参考,不断加入新照片通过SfM迭代计算来产生稀疏点云。一旦加入一张新照片,将通过光束平差法BA(bundle adjustment)[46]来估算和优化该照片的姿态和照片中拍摄对象的相对位置。光束平差法是一个用非线性最小二乘法来调整所有光束(即从2D照片上的点到3D空间上对应点的方向)和相机位置的优化模型,来最小化重投影误差。
本文为了达到更好的展示效果,结果部分展示的点云为密集点云。密集点云是在稀疏点云的基础上使用PMVS(patch-based multi-view stereo)算法生成富含纹理信息的密集点云,主要步骤包括初始匹配、区域生长、视觉条件约束和三维面片数据建立。
2.3.4 根据已知参数估计未知参数本文通过上述步骤,生成了三维稀疏点云,恢复了待查询照片和相似照片集的相对空间关系,即在自由坐标系下,待查询照片和相似照片集的空间位置。然后根据相似照片集已知的GPS坐标,推算待查询照片未知的GPS坐标,即在大地坐标系下,待查询照片的空间位置。
3 结果与分析 3.1 研究区与数据集图 2展示了本文研究区南京市建邺区。建邺区是南京的主城区之一,位于南京市区西南部,东、南紧邻外秦淮河和秦淮新河,西临长江,北止汉中门大街。建邺区中既有老城区,也有新城区,既包含历史,又展现现代,是南京市发展中最具代表的缩影,其街道景观很大程度上能够反映南京市的街道景观特点。研究区覆盖面积约为76.4 km2,长约10 km,宽约8 km。

|
| 图 2 研究区和数据集 Fig. 2 Study area and dataset |
本文为实现众筹照片的地理定位,使用12万张街景数据作为数据集,所使用的街景数据覆盖了180 km的城市道路。试验以12 m为采样间隔爬取街景数据,这与街景采集车采集街景的间隔相一致;在每个采样点,从初始方位角开始的顺时针一圈上,每45°爬取一张街景。本文选用腾讯街景地图,它是我国国内首个高清街景地图商,目前已覆盖国内所有地级市。
试验数据包含了227张众筹照片,均匀分布在试验区内,这些众筹照片是通过带有GPS定位功能的智能手机拍摄而得。试验先去除了无关和涉及隐私的照片,最终保留227张照片。这些照片有着不同的视角、分辨率、尺寸和场景,这与互联网上众筹照片的存在形式类似。
3.2 精度评价标准在进行试验之前,每张照片的EXIF标签都已被去除;在进行试验之后,照片的原始GPS信息将被用来验证地理定位精度。
本文通过照片的真实位置和估算位置之间的距离,来评价照片定位方法的精度,距离越小,定位精度越高。
3.3 试验结果本文使用227张待查询照片(已去除EXIF标签)来进行照片定位试验,平均重建时间是457 s。图 3展示了试验结果。定位结果分为两种,一种是第三步中根据相似街景集建立起的三维点云,估算得到的待查询照片的GPS位置,另一种是第一步中根据参考数据集检索得到的最匹配街景的GPS位置。

|
| 图 3 待查询照片分布图和局部区域照片定位结果示意 Fig. 3 Query pictures distribution map and geo-localization results in two local areas |
3.4 讨论分析 3.4.1 总误差分析
定义从真实位置到估算位置的方向为误差方向,从真实位置到估算位置的距离为误差距离。误差等级是根据研究区内道路的分布进行确定的,其中小路之间的距离约为200 m,主干路之间的距离约为800 m,平均为500 m;另外约有一半的待查询照片的定位误差集中在50 m以内。

|
| 图 4 总误差结果和总误差分布统计图 Fig. 4 Total error and its distribution statistics 注:用箭头方向表达总误差方向,用5个等级的灰度表达总误差距离。 |
(1) 本文方法的误差距离分布高度集中在“ < 200 m”范围(68.7%)、极少分布在“>800 m”范围(3.1%);
(2) 误差距离小的待查询照片通常包含清晰且有针对性的目标(图 4(b), 1-8)。误差距离大的待查询照片有的包含大量植被(图 4(b),9-11)或有相似外墙的居民楼(图 4(b),15-16)造成有辨识度的目标较少(图 4(b),17-19),有的则包含能从更大视角和更远范围看到的高大建筑(图 4(b),20-22),从而造成干扰。
3.4.2 误差成因分析本文所使用的待查询照片中,共有192张(占总数的84.6%)照片成功经历了第三步的三维重建,下面分析这些待查询照片重建误差的成因。
(1) 待查询照片的拍摄相机和其主拍摄目标之间的距离,与总误差可能存在相关性。对于一张待查询照片,其主拍摄目标是后期通过人工观察确定得到的,并在地图上标注以便来计算其到拍摄相机的距离。
在图 5中,拍摄相机与主拍摄目标之间的距离,与总误差呈正相关(R2=0.6141)。意味着拍摄相机距离目标越近,总误差越小,反之,总误差越大。

|
| 图 5 待查询照片的拍摄相机与主拍摄目标之间的距离,与总误差的相关性 Fig. 5 Correlation between distance from the query camera to the main object of query pictures and their total error |
(2) 总误差被分解为平行于和垂直于道路的两个分量,其中平行于道路的误差分量被定义为X轴误差(ΔX),垂直于道路的误差分量被定义为Y轴误差(ΔY),如图 6所示。分析结果展示在图 7和表 2,并分析得到以下结论。

|
| 图 6 X轴误差和Y轴误差示意图 Fig. 6 Diagram of X-axis error and Y-axis error |

|
| 图 7 总误差的两个分量:X轴误差和Y轴误差分析图 Fig. 7 Real GPS location, total error direction, and quantitative relationship between X-axis error and Y-axis error |
| m | |||||
| 参数 | 中位数 | 平均值 | 标准差 | 最大值 | 最小值 |
| X轴误差 | 40.0 | 117.3 | 164.5 | 858.5 | 0.3 |
| Y轴误差 | 24.9 | 79.8 | 122.7 | 654.5 | 0.1 |
从图 7中可以发现,ΔX>ΔY的待查询照片被标为黑色(128个),ΔX < ΔY被标为灰色(64个)。ΔX较大的点数量上是ΔY较大的两倍。从表 2中可以发现,ΔX的平均值、标准差、最大值、最小值和中值均超过ΔY。因此可以推测,ΔX对总误差的贡献更大。
3.4.3 缓冲区半径分析变换缓冲区半径,并统计不同缓冲区半径下,满足不同精度要求的待查询照片比例。统计结果如图 8所示,可以得到以下结论:

|
| 图 8 不同缓冲区半径下满足不同精度要求的待查询照片比例 Fig. 8 Percentage of query pictures within different error distances under a specific buffer radius |
(1) Zamir和Shah提出的定位方法[18],即本文方法的第一步:图像检索粗定位,相当于设缓冲区半径=0即不进行第二、三步。统计结果表明,本文方法(缓冲区半径>0)的定位效果明显优于Zamir和Shah的方法,因为同一个精度要求下,本文方法可以定位到更多的照片。
(2) 缓冲区半径影响定位结果。本文选取200 m作为最佳缓冲区半径,这可能与试验区街道长度有关。较大的取值(紫色线)将引入很多不相关的照片,破坏了高度重叠照片进行近景三维重建的优势,而较小的取值(蓝色和绿色线)将限制相似街景集的查找范围,导致不能爬取出足够的照片用于三维重建。
(3) 在0~50 m的误差距离内,蓝线(缓冲区半径=50 m)和绿线(缓冲区半径=100 m)均超过了黑线(缓冲区半径=0 m)和红线(缓冲区半径=200 m)。这意味着当待查询照片已经获得较好的粗定位效果时,较小的缓冲区半径也许更加有效。
3.4.4 方法比较Zamir和Shah的定位方法,即本文方法的第一步:图像检索粗定位。为了探讨第二步和第三步能否提升定位精度,计算了对Zamir和Shah的方法的精度提升值。精度提升值计算公式如下:
 (7)
(7)

|
| 图 9 方法比较 Fig. 9 Methods comparison |
| 参数 | 本文方法(缓冲区半径=200m) | Zamir和Shah的方法 | |
| 误差距离/m | 中位数 | 69.0 | 256.7 |
| 平均值 | 206.0 | 350.4 | |
| 标准差 | 309.7 | 361.8 | |
| 等级1:误差 < 50m | 43.2% | 17.2% | |
| 等级2:50m < 误差 < 200m | 25.5% | 25.5% | |
| 等级3:200m < 误差 < 500m | 17.2% | 32.6% | |
| 等级4:500m < 误差 < 800m | 11.0% | 17.2% | |
| 等级5:误差 > 800m | 3.1% | 7.5% | |
(1) 本文方法在Zamir和Shah的方法基础上,提升75.3%待查询照片的定位精度(精度提升值>0),未改变15.4%待查询照片的定位精度(精度提升值=0)和降低了9.3%待查询照片的定位精度(精度提升值< 0)。
(2) 对于所有的待查询照片,本文方法的定位误差平均距离为206.0 m,Zamir和Shah的方法平均距离为350.4 m。在50 m精度要求下,本文方法实现了对43.2%照片的定位,而Zamir和Shah的方法只实现了17.2%;在800 m精度要求下,本文方法实现了对96.9%照片的定位,而Zamir和Shah的方法只实现了92.5%(表 2)。
(3) 被本文方法降低了定位精度的待查询照片通常包含有相似外墙的建筑(图 9(b),1-3)或者能从更大视角更远范围看到的摩天大楼(图 9(b),4-6)。这些目标导致三维重建无法获得更好的定位效果。
未被本文方法改变定位精度的待查询照片没有经历第三步的三维重建。有些照片包含了大量的干扰目标如植被(图 9(b),7-9)导致三维重建失败,有些照片虽然包含了针对性的目标但其周围不能提供足够的三维信息用于重建(图 9(b),10-12)。
被本文方法提升了定位精度的照片包含清晰且有针对性的目标(图 9(b),13-18)。其中拍摄了摩天大楼的待查询照片的定位精度明显被提升了(图 9(b),19-24),这表明本文方法对拍摄大城市中密集高楼大厦的照片可以获得较好的定位效果。
4 结论本文提出了一种互联网众筹照片的三维重建定位技术,该方法以结构化组织的街景数据为参考数据集,使用三步策略:图像检索粗定位、图像匹配细筛选和三维重建精定位,给不明来源的照片附上精确的地理标签。本文的主要贡献是使用了新兴的街景数据,并巧妙综合了检索、匹配和重建3种算法,实现了更精确的照片定位,特别是拍摄大城市里密集高楼的照片。本文通过摄影测量原理恢复待查询照片周围的三维空间信息,较之前Zamir和Shah的方法,定位精度中值从256.7 m提升到69.0 m,平均值从350.4 m提升到206.0 m,在50 m精度要求下的照片数量占比从17.2%提升到43.2%。本文的另一个发现是重建误差成因方面,待查询照片的拍摄相机距离主拍摄目标越近,总误差越小;平行于街道的误差分量对总误差贡献更大。另外,本文提出的方法提供了灵活的参数,可以应用于更大尺度范围的地区。
在未来工作中,笔者将探索季节、天气和时辰对试验结果的影响,来提升方法的抗差性;同时致力于提升方法的计算效率,以便应用于更大尺度范围。
| [1] | LI Songnian, DRAGICEVIC S, CASTRO F A, et al. Geospatial Big Data Handling Theory and Methods:A Review and Research Challenges[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2016, 115: 119–133. DOI:10.1016/j.isprsjprs.2015.10.012 |
| [2] | HEIPKE C. Crowdsourcing Geospatial Data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2010, 65(6): 550–557. DOI:10.1016/j.isprsjprs.2010.06.005 |
| [3] | ARTH C, PIRCHHEIM C, VENTURA J, et al. Instant Outdoor Localization and SLAM Initialization from 2.5D Maps[J]. IEEE Transactions on Visualization and Computer Graphics, 2015, 21(22): 1309–1318. |
| [4] | YIN Li, CHENG Qimin, WANG Zhenxin, et al. 'Big Data' for Pedestrian Volume:Exploring the Use of Google Street View Images for Pedestrian Counts[J]. Applied Geography, 2015, 63: 337–345. |
| [5] | SALMEN J, HOUBEN S, SCHLIPSING M. Google Street View Images Support the Development of Vision-based Driver Assistance Systems[C]//Proceedings of 2012 IEEE Intelligent Vehicles Symposium. Alcala de Henares, Spain: IEEE, 2012: 891-895. |
| [6] | TSAI V J D. Traffic Sign Detection and Positioning from Google Street View Streamlines[C]//Proceedings of ASPRS 2015 Annual Conference. Tampa, Florida: ASPRS, 2015. |
| [7] | LIU Yue, WANG Yongtian. AR-view: An Augmented Reality Device for Digital Reconstruction of Yuangmingyuan[C]//Proceedings of 2009 IEEE International Symposium on Mixed and Augmented Reality-arts, Media and Humanities. Orlando, FL: IEEE, 2009: 3-7. |
| [8] | BADLAND H M, OPIT S, WITTEN K, et al. Can Virtual Streetscape Audits Reliably Replace Physical Streetscape Audits?[J]. Journal of Urban Health, 2010, 87(6): 1007–1016. DOI:10.1007/s11524-010-9505-x |
| [9] | LI Xiaojiang, ZHANG Chuanrong, LI Weidong, et al. Assessing Street-level Urban Greenery Using Google Street View and a Modified Green View Index[J]. Urban Forestry & Urban Greening, 2015, 14(3): 675–685. |
| [10] | YIN Li, WANG Zhenxin. Measuring Visual Enclosure for Street Walkability:Using Machine Learning Algorithms and Google Street View Imagery[J]. Applied Geography, 2016, 76: 147–153. DOI:10.1016/j.apgeog.2016.09.024 |
| [11] | HARA K, AZENKOT S, CAMPBELL M, et al. Improving Public Transit Accessibility for Blind Riders by Crowdsourcing Bus Stop Landmark Locations with Google Street View:An Extended Analysis[J]. ACM Transactions on Accessible Computing (TACCESS), 2015, 6(2): 5. |
| [12] | ZAMIR A R, HAKEEM A, VAN GOOL L, et al. Large-scale Visual Geo-localization[M]. Cham: Springer, 2016. |
| [13] | LOWE D G. Distinctive Image Features from Scale-invariant Keypoints[J]. International Journal of Computer Vision, 2004, 60(2): 91–110. |
| [14] | SATTLER T, LEIBE B, KOBBELT L. Fast Image-based Localization Using Direct 2D-to-3D Matching[C]//Proceedings of 2011 IEEE International Conference on Computer Vision. Barcelona, Spain: IEEE, 2011: 667-674. |
| [15] | CHEN D M, BAATZ G, KÖSER K, et al. City-scale Landmark Identification on Mobile Devices[C]//Proceedings of 2011 IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, CO: IEEE, 2011: 737-744. |
| [16] | KNOPP J, SIVIC J, PAJDLA T. Avoiding Confusing Features in Place Recognition[C]//Proceedings of the 11th European Conference on Computer Vision. Heraklion, Greece: Springer, 2010: 748-761. |
| [17] | NISTER D, STEWENIUS H. Scalable Recognition with a Vocabulary Tree[C]//Proceedings of 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York: IEEE, 2006: 2161-2168. |
| [18] | ZAMIR A R, SHAH M. Accurate Image Localization Based on Google Maps Street View[C]//Proceedings of the 11th European Conference on Computer Vision. Heraklion, Greece: Springer, 2010: 255-268. |
| [19] | ZAMIR A R, SHAH M. Image Geo-localization Based on Multiplenearest Neighbor Feature Matching Using Generalized Graphs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(8): 1546–1558. DOI:10.1109/TPAMI.2014.2299799 |
| [20] | SCHINDLER G, BROWN M, SZELISKI R. City-scale Location Recognition[C]//Proceedings of 2007 IEEE Conference on Computer Vision and Pattern Recognition. Minneapolis: IEEE, 2007: 1-7. |
| [21] | KNOPP J, SIVIC J, PAJDLA T. Avoiding Confusing Features in Place Recognition[C]//Proceedings of the 11th European Conference on Computer Vision. Heraklion, Greece: Springer, 2010: 748-761. |
| [22] | HAYS J, EFROS A A. IM2GPS: Estimating Geographic Information from a Single Image[C]//Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition. Anchorage: IEEE, 2008: 1-8. |
| [23] | YAZAWA N, UCHIYAMA H, SAITO H, et al. Image Based View Localization System Retrieving from a Panorama Database by SURF[C]//Proceedings of 2009 IAPR Conference on Machine Vision Applications. Yokohama, Japan: [s. n. ], 2009: 3632-3636. |
| [24] | KE Yan, SUKTHANKAR R. PCA-SIFT: A More Distinctive Representation for Local Image Descriptors[C]//Proceedings of 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE, 2004: 506-513. |
| [25] | PARK H, MOON K S. Fast Feature Matching by Coarse-to-fine Comparison of Rearranged SURF Descriptors[J]. IEICE Transactions on Information and Systems, 2015, E98-D(1): 210–213. |
| [26] | KAMENCAY P, BREZNAN M, JELSOVKA D, et al. Improved Face Recognition Method Based on Segmentation Algorithm Using SIFT-PCA[C]//Proceedings of the 35th International Conference on Telecommunications and Signal Processing. Prague, Czech Republic: IEEE, 2012: 758-762. |
| [27] | TANG Gefu, XIAO Zhifeng, LIU Qing, et al. A Novel Airport Detection Method via Line Segment Classification and Texture Classification[J]. IEEE Geoscience and Remote Sensing Letters, 2015, 12(12): 2408–2412. |
| [28] | XIAO Zhifeng, LIU Qing, TANG Gefu, et al. Elliptic Fourier Transformation-based Histograms of Oriented Gradients for Rotationally Invariant Object Detection in Remote-Sensing Images[J]. International Journal of Remote Sensing, 2015, 36(2): 618–644. DOI:10.1080/01431161.2014.999881 |
| [29] | BLASCHKE T. Object Based Image Analysis for Remote Sensing[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2010, 65(1): 2–16. DOI:10.1016/j.isprsjprs.2009.06.004 |
| [30] | SE S, NADEAU C, WOOD S. Automated UAV-based Video Exploitation Using Service Oriented Architecture Framework[C]//Proceedings of Volume 8020, Airborne Intelligence, Surveillance, Reconnaissance (ISR) Systems and Applications VⅢ. Orlando, FL: SPIE, 2011: 80200Y. |
| [31] | SZLÁVIK Z, SZIRÁNYI T, HAVASI L. Video Camera Registration Using Accumulated Co-motion Maps[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2007, 61(5): 298–306. DOI:10.1016/j.isprsjprs.2006.09.014 |
| [32] | LI Yunpeng, SNAVELY N, HUTTENLOCHER D, et al. Worldwide Pose Estimation Using 3D Point Clouds[C]//Proceedings of the 12th European Conference on Computer Vision. Florence, Italy: Springer, 2012: 15-29. |
| [33] | SVÄRM L, ENQVIST O, OSKARSSON M, et al. Accurate Localization and Pose Estimation for Large 3D Models[C]//Proceedings of 2014 IEEE Conference on Computer Vision and Pattern Recognition. Columbus, OH: IEEE, 2014: 532-539. |
| [34] | GERNHARDT S, AUER S, EDER K. Persistent Scatterers at Building Facades-evaluation of Appearance and Localization Accuracy[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2015, 100: 92–105. DOI:10.1016/j.isprsjprs.2014.05.014 |
| [35] | SINGH G, KOŠECKÁ J. Semantically Guided Geo-location and Modeling in Urban Environments[M]//ZAMIR A R, HAKEEM A, VAN GOOL L, et al. Large-scale Visual Geo-localization. Cham: Springer, 2016: 101-120. |
| [36] | CRANDALL D J, LI Yunpeng, LEE S, et al. Recognizing Landmarks in Large-scale Social Image Collections[M]//ZAMIR A R, HAKEEM A, VAN GOOL L, et al. Large-scale Visual Geo-localization. Cham: Springer, 2016: 121-144. |
| [37] | NIEVERGELT J, HINTERBERGER H, SEVCIK K C. The Grid File:An Adaptable, Symmetric Multikey File Structure[J]. ACM Transactions on Database Systems (TODS), 1984, 9(1): 38–71. |
| [38] | ROBINSON J T. The K-D-B-Tree: A Search Structure for Large Multidimensional Dynamic Indexes[C]//Proceedings of 1981 ACM SIGMOD International Conference on Management of Data. Ann Arbor, Michigan: ACM, 1981: 10-18. |
| [39] | SNAVELY N, SEITZ S M, SZELISKI R. Modeling the World from Internet Photo Collections[J]. International Journal of Computer Vision, 2008, 80(2): 189–210. |
| [40] | WU Changchang. Towards Linear-time Incremental Structure from Motion[C]//Proceedings of 2013 International Conference on 3D Vision-3DV 2013. Seattle: IEEE, 2013: 127-134. |
| [41] | MATAS J, CHUM O, URBAN M, et al. Robust Wide-baseline Stereo from Maximally Stable Extremal Regions[J]. Image and Vision Computing, 2004, 22(10): 761–767. |
| [42] |
程亮, 龚健雅, 宋小刚, 等.
面向宽基线立体影像匹配的高质量仿射不变特征提取方法[J]. 测绘学报, 2008, 37(1): 77–82.
CHENG Liang, GONG Jianya, SONG Xiaogang, et al. A Method for Affine Invariant Feature Extraction with High Quality for Wide Baseline Stereo Image Matching[J]. Acta Geodaetica et Cartographica Sinica, 2008, 37(1): 77–82. |
| [43] | INDYK P, MOTWANI R. Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality[C]//Proceedings of the 30th Annual ACM Symposium on Theory of Computing. Dallas, Texas: ACM, 1998: 604-613. |
| [44] | ZHANG Zhengyou, DERICHE R, FAUGERAS O, et al. A Robust Technique for Matching Two Uncalibrated Images through the Recovery of the Unknown Epipolar Geometry[J]. Artificial Intelligence, 1995, 78(1-2): 87–119. DOI:10.1016/0004-3702(95)00022-4 |
| [45] | WESTOBY M J, BRASINGTON J, GLASSER N F, et al. 'Structure-from-Motion' Photogrammetry:A Low-cost, Effective Tool for Geoscience Applications[J]. Geomorphology, 2012, 179: 300–314. DOI:10.1016/j.geomorph.2012.08.021 |
| [46] | LOURAKIS M I A, ARGYROS A A. SBA:A Software Package for Generic Sparse Bundle Adjustment[J]. ACM Transactions on Mathematical Software, 2009, 36(1): 2. |
| [47] |
刘颖真, 贾奋励, 万刚, 等.
非专业弱关联影像的地理配准及其精度评估[J]. 测绘学报, 2015, 44(9): 1014–1021, 1028.
LIU Yingzhen, JIA Fenli, WAN Gang, et al. Geo-registration of Unprofessional and Weakly-related Image and Precision Evaluation[J]. Acta Geodaetica et Cartographica Sinica, 2015, 44(9): 1014–1021, 1028. DOI:10.11947/j.AGCS.2015.20140394 |
| [48] |
陈爱军, 徐光祐, 史元春.
基于城市航空立体像对的全自动3维建筑物建模[J]. 测绘学报, 2002, 31(1): 54–59.
CHEN Aijun, XU Guangyou, SHI Yuanchun. Automated 3D Building Modeling Based on Urban Aerial Stereopair[J]. Acta Geodaetica et Cartographica Sinica, 2002, 31(1): 54–59. |